В октябре 2011 года наш интернет-сервис безвозмездного дарения
Дару-дар пригласили поучаствовать в VIII международном научно-практическом междисциплинарном симпозиуме
Рефлексивные процессы и управление, проводимом под эгидой Института Философии РАН.
Ключевым словом, по которому мы нашли пересечение с сугубо философской проблематикой, было слово «среда», а если быть более точным, то понятие
«социальная среда». Мы давно ввели это слово в повседневный язык нашей группы разработчиков, чтобы лучше понимать, чем мы занимаемся, чтобы уточнить методологию и приоритеты нашей разработки, а также и для того, чтобы обозначить место разрабатываемого нами сервиса в сложном пространстве современных интернет-стартапов.
Подготовка к философской конференции спровоцировала нас, наконец, оформить свои мысли в текст, который теперь хочется предоставить вниманию IT-сообществу. Как нам представляется, сформулированные нами концепты могут быть полезны всем тем, кто занимается разработкой социальных интернет-сервисов или кто мыслит себя как
социальный предприниматель.
В данном тексте с помощью понятия «социальная среда» на примере интернет-сервиса дарения делается попытка выделить определенный вид социальных интернет-сервисов и посмотреть на них в широком контексте человеческого общества как такового, его устройства и возможностей преобразования.


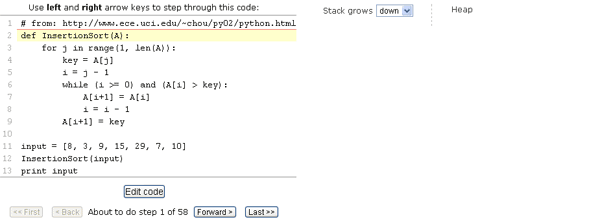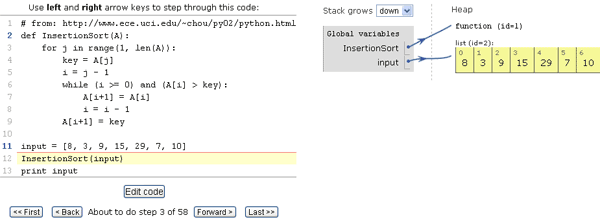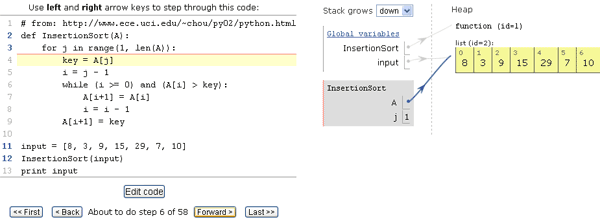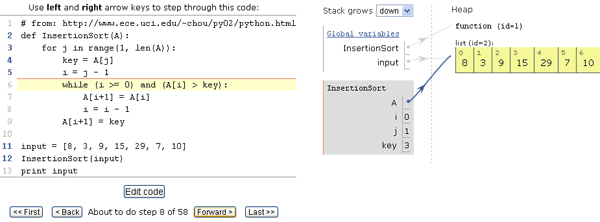
 Регулярные выражения — это арифметика для алгоритмов. Они доступны во многих языках программирования, редакторах и настройках приложений. Как и сложение с умножением они просты в использовании.
Регулярные выражения — это арифметика для алгоритмов. Они доступны во многих языках программирования, редакторах и настройках приложений. Как и сложение с умножением они просты в использовании.