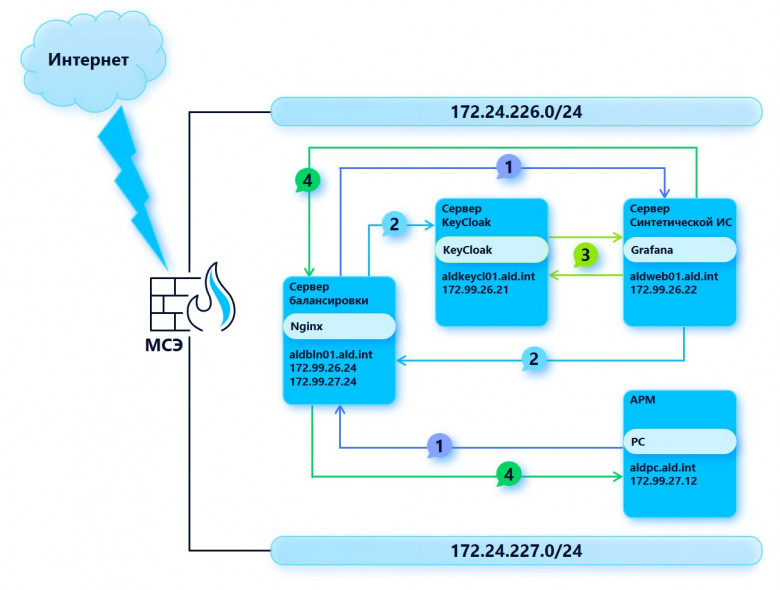
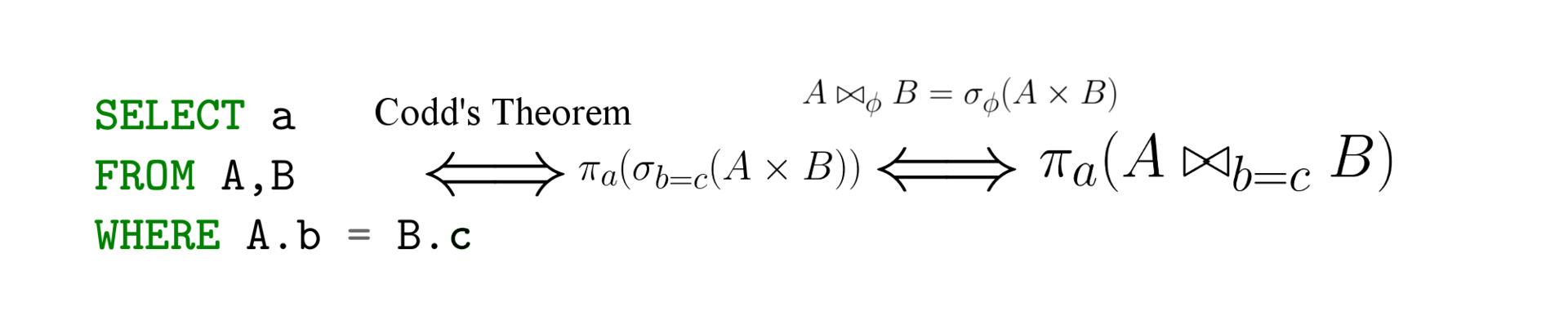За эту статью попрошу благодарить патриотично размороженных граждан в целом, и @WebPeople (регистрация 2012, разморожен с первым комментарием 8 июл 2023 в 20:47) в частности. Глобальное потепление, ничего не поделать.
В мае 2022 в комментариях @hippohood отметился не имеющим аналогов текстом:
Примерно опишу мыслительный процесс позитивно (патриотично) настроенных граждан.
Оборудование можно сделать и самим, но пока можно и просто привезти серым импортом. Оборудование выглядит примерно как большой ящик с дырками, включённый в розетку; в одну дырку складываешь кремний, в другую заливаешь фоторезистор. Под третью дырку надо подставить ведро - в него будут ссыпаться чипы. Вёдра мы делать умеем (хотя и импортируем сейчас, но чертежи-то остались), фоторезистор научатся намешивать в Зелинограде; с кремнием разберемся, не всё сразу. Надо ещё заранее заказать в Китае переходник с европейской розетки на нормальную - лучше сразу 3 или 4, они постоянно горят. Вроде все ясно.