Когда я в первый раз увидел E4X (ECMAScript for XML), я, признаться, сразу в него влюбился и сильно расстроился, что для Python нет какой-либо библиотеки, эмулирующей подобный синтаксис. Но тут вот недавно случайно наткнулся на замечательнейшую вещь — P4X.

tasman @tasman
Пользователь
CorePy: программирование на ассемблере в Python
1 мин
Перевод
CorePy является библиотекой для разработки на уровне ассемблера для процессоров x86, Cell BE и PowerPC. Простой API позволяет разрабатывать сложные высокопроизводительные приложения, использующие особенности процессора, включая многоядерность и потоковые расширения, такие как SSE, VMX и SPU, обычно недоступные из языков высокого уровня.
Основанный на передовой среде выполнения, CorePy позволяет разработчикам писать и выполнять низкоуровневые приложения непосредственно в коммандной строке или встраивать в Python приложения. За счет сокращения времени разработки низкоуровневых приложений CorePy значительно уменьшает существующий барьер при разработке низкоуровневых приложений.
CorePy является инструментом общего назначения, который можно применять при разработке широкого спектра приложений, включая разработку игр, мультимедийных систем, научных и высокопроизводительных приложений а также встраиваемых приложений. Эта библиотека использовалась для оптимизации приложений под процессоры x86, систем на PowerPC 970 и Cell BE и регулярно являлась более производительнее компилируемых языков для вычислительных задач (как обычное кодирование на asm :))
Один комментарий пользователя после нескольких часов работы с CorePy подытожил мнение большинства людей:
«CorePy опять сделал программирование на ассемблере интересным занятием!» (Alex Breuer)
CorePy был разработан Крисом Мюллером (Chris Mueller), Эндрю Фридли (Andrew Friedley) и Беном Мартином (Ben Martin). Значительный вклад внес Эндрю Ламсдейн (Andrew Lumsdaine) из Open Systems Lab университета Индианы.
CorePy это open source проект, доступный по лицензии BSD.
Основанный на передовой среде выполнения, CorePy позволяет разработчикам писать и выполнять низкоуровневые приложения непосредственно в коммандной строке или встраивать в Python приложения. За счет сокращения времени разработки низкоуровневых приложений CorePy значительно уменьшает существующий барьер при разработке низкоуровневых приложений.
CorePy является инструментом общего назначения, который можно применять при разработке широкого спектра приложений, включая разработку игр, мультимедийных систем, научных и высокопроизводительных приложений а также встраиваемых приложений. Эта библиотека использовалась для оптимизации приложений под процессоры x86, систем на PowerPC 970 и Cell BE и регулярно являлась более производительнее компилируемых языков для вычислительных задач (как обычное кодирование на asm :))
Один комментарий пользователя после нескольких часов работы с CorePy подытожил мнение большинства людей:
«CorePy опять сделал программирование на ассемблере интересным занятием!» (Alex Breuer)
CorePy был разработан Крисом Мюллером (Chris Mueller), Эндрю Фридли (Andrew Friedley) и Беном Мартином (Ben Martin). Значительный вклад внес Эндрю Ламсдейн (Andrew Lumsdaine) из Open Systems Lab университета Индианы.
CorePy это open source проект, доступный по лицензии BSD.
Горизонтальное масштабирование PostgreSQL с помощью PL/Proxy.
9 мин
Очень тяжело начать писать статью. Т.е очень тяжело придумать вступительное слово. Хочется рассказать обо всём и сразу :) Но нет. Будем последовательны.
Начну с того что совсем недавно проходил Highload++ 2008 на котором мне удалось побывать.
Скажу сразу — мероприятие было проведено по высшему клаcсу, докладов было много и все были очень интересными.
Одной из самых запомнившихся презентаций была лекция Аско Ойя об инфраструктуре серверов баз данных в Skype. Лекция в большей степени касалась различных средств с помощью которых достигается такая производительность серверов.
По словам Аско, база данных Skype выдержит даже если все жители Земли захотят подключится к скайп в один момент.
Приехав домой очень захотелось это всё попробовать в живую. О чём я сейчас и расскажу. Сразу оговорюсь — структура базы данных для теста, взята из примера на сайте самих разработчиков и естественно не имеет ничего общего с реальной загрузкой.
В статье будет описано что распределением нагрузки надо заниматься после того как уже припекло и база падает, но это не совсем так. С помощью данной статьи я как раз хочу подготовить начинающих и не опытных разработчиков и заодно заставить их задуматься о том, что предусматривать возможность распределения нагрузки между серверами надо ещё при проектировании системы. И это не будет считаться той самой «преждевременной оптимизацией» о которой так много пишут и которой так боятся.
UPD: Как правильно заметил хабраюзер descentspb в статье присутствует досаднейшая ошибка. В следствие своей невнимательности я подумал что PgBouncer надо устанавливать между прокси и клиентом. Но, как оказалось, та проблема которую я решал с помощью PgBouncer не решится если установить его именно так. Правильнее надо устанавливать боунсер между нодами и прокси. Мало того, именно так и рекомендуется делать в оффициальном мануале на сайте PL/Proxy.
В любом случае использование PgBouncer так как указано на моей схеме также даст прирост производительности. (Разгрузит Proxy).
Начну с того что совсем недавно проходил Highload++ 2008 на котором мне удалось побывать.
Скажу сразу — мероприятие было проведено по высшему клаcсу, докладов было много и все были очень интересными.
Одной из самых запомнившихся презентаций была лекция Аско Ойя об инфраструктуре серверов баз данных в Skype. Лекция в большей степени касалась различных средств с помощью которых достигается такая производительность серверов.
По словам Аско, база данных Skype выдержит даже если все жители Земли захотят подключится к скайп в один момент.
Приехав домой очень захотелось это всё попробовать в живую. О чём я сейчас и расскажу. Сразу оговорюсь — структура базы данных для теста, взята из примера на сайте самих разработчиков и естественно не имеет ничего общего с реальной загрузкой.
В статье будет описано что распределением нагрузки надо заниматься после того как уже припекло и база падает, но это не совсем так. С помощью данной статьи я как раз хочу подготовить начинающих и не опытных разработчиков и заодно заставить их задуматься о том, что предусматривать возможность распределения нагрузки между серверами надо ещё при проектировании системы. И это не будет считаться той самой «преждевременной оптимизацией» о которой так много пишут и которой так боятся.
UPD: Как правильно заметил хабраюзер descentspb в статье присутствует досаднейшая ошибка. В следствие своей невнимательности я подумал что PgBouncer надо устанавливать между прокси и клиентом. Но, как оказалось, та проблема которую я решал с помощью PgBouncer не решится если установить его именно так. Правильнее надо устанавливать боунсер между нодами и прокси. Мало того, именно так и рекомендуется делать в оффициальном мануале на сайте PL/Proxy.
В любом случае использование PgBouncer так как указано на моей схеме также даст прирост производительности. (Разгрузит Proxy).
MySQL и JOINы
6 мин
Поводом для написания данной статьи послужили некоторые дебаты в одной из групп linkedin, связанной с MySQL, а также общение с коллегами и хабролюдьми :-)
В данной статье хотел написать что такое вообще JOINы в MySQL и как можно оптимизировать запросы с ними.
В данной статье хотел написать что такое вообще JOINы в MySQL и как можно оптимизировать запросы с ними.
Свой SVN на виртуальном (shared) хостинге
4 мин

Решили мы как то с приятелем, запустить стартап не стартап, а так, сайт для души. Решили — значит будет запущен. Бюджет… А давай не купим ещё по 2 кружки пива, на это и запустим. В общем денег на домен да на виртуальный хостинг на валуехосте. Так люди мы «взрослые», и делать всё привыкли основательно, нам нужна система управления версиями и выкладыванием. Было решено поднять subversion репозиторий с возможностью раздачи доступа к нему нескольким разработчикам с разными логинами на valuehost. Но у нас виртуальный хостинг со всеми его ограничениями, что делать?
Постраничная навигация с MySQL при большом количестве записей
7 мин
Рано или поздно многие крупные проекты сталкиваются с проблемами производительности при постраничной навигации по записям. Некоторые из них решают эту проблему ограничением количества доступных для просмотра записей (скажем, не больше 1000). Вполне приемлемое решение. Но в этом случаем могут возникнуть проблемы с индексированием сайта сторонними поисковиками, которые и представляют наибольшую угрозу. В этой статье я хотел бы отказаться от привычной для всех панели навигации вида «1..2..3..4..» в пользу простой «вперед… назад» (будет проще объяснить), но это не проблема реализовать подобное и с первым вариантом.
Более точно определить тему, назвав, какое количество записей считать достаточно большим для появления тормозов, не получится, так как эта цифра для всех разная и сильно зависит от того, насколько быстрые у Вас жесткие диски, сколько памяти, и какая часть Ваших данных уже закеширована в ней и тд. Но если Вы и Ваши сервера ощущают, что n-ная страница при выводе даётся тяжелее первой, и при этом не знаете, что с этим делать – статья для Вас. Но для начала, я хотел бы на пальцах объяснить, почему ОНО работает медленно.
Кстати, тест происходит на виртуальной машинке, работаю я с СУБД под рутом, версия MySQL – 5.0.32.
Более точно определить тему, назвав, какое количество записей считать достаточно большим для появления тормозов, не получится, так как эта цифра для всех разная и сильно зависит от того, насколько быстрые у Вас жесткие диски, сколько памяти, и какая часть Ваших данных уже закеширована в ней и тд. Но если Вы и Ваши сервера ощущают, что n-ная страница при выводе даётся тяжелее первой, и при этом не знаете, что с этим делать – статья для Вас. Но для начала, я хотел бы на пальцах объяснить, почему ОНО работает медленно.
Кстати, тест происходит на виртуальной машинке, работаю я с СУБД под рутом, версия MySQL – 5.0.32.
Пишем модуль расширения для Питона на C
9 мин
OMFG! — может воскликнуть читатель. Зачем писать что-то на С когда есть Python, и будет во многом прав. Однако, к счастьюсожалению наш зелёный друг не всесилен.
Визуализируя закон Фиттса
6 мин
Перевод
Введение
Готовясь к редизайну и пересмотру сайта wufoo.com, я посвятил некоторое время повторному изучению основ взаимодействия человека и компьютера, в надежде вобрать что-то новое, что накопилось за десятилетия исследований в области создания простых интерфейсов. Первое, что меня удивило на этом пути — это то, что материал по данной теме был крайне сжат и явно ориентировался на математиков, поскольку был написан на языке академической элиты. Можно предположить, что если бы они хотели произвести впечатление (особенно на дизайнеров), они могли бы написать документы, более лёгкие для восприятия.
Вспоминая школу, я отметил, что лишь во время изучения физики математика приобрела для меня некий смысл. Вместо абстрактных функций мне были нужны графики. Размышляя в таком ключе я подумал, что было бы неплохо дать наглядную интерпретацию закону Фиттса — краеугольному камню проектирования человеко-машинных интерфейсов, и объяснить как его концепцию, так и то, почему эти идеи чуть более сложны, чем многим бы того хотелось
«Python 3 Patterns & Idioms». Новая книга Брюса Эккеля.
1 мин
Брюс Эккель, автор бэст-сэллеров «Thinkin in Java» и «Thinking in C++», выпустил новую книгу «Python 3 Patterns & Idioms».
Книга доступна в форматах html и Windows Help.
Распространяется по лицензии Creative Commons Attribution-Share Alike 3.0.
Линк
Книга доступна в форматах html и Windows Help.
Распространяется по лицензии Creative Commons Attribution-Share Alike 3.0.
Линк
Аппаратный XML-парсер от Intel
1 мин
Совсем скоро официально выходит процессор Intel Core i7.
Среди нововведений в нем, в частности, реализован набор инструкций SSE4.2. В этой версии они сделали упор на ускорение специфических задач. В частности, добавлено пять инструкций, предназначенных для ускорения разбора XML-файлов. Также с помощью этих инструкций возможно ускорение обработки строк в целом.
Команды SSE 4.2 позволяют параллельно оперировать 16 байтами в двух строках.
У Intel есть некая библиотека XML Software Suite, которая уже использует новые инструкции.
На эту тему у них есть статья с объяснением используемых алгоритмов. Надо сказать, очень познавательно. Я даже уже перевел половину, но не уверен, интересно ли это кому-нибудь. Они заявляют о 25-70% ускорении синтаксического разбора XML.
А в целом наблюдается интересная тенденция перехода от процессоров общего назначения на специализированные. Intel уже придумала для этого новое название — ATA (Application Targeted Accelerators).
В следующей версии будет аппаратная поддержка JavaScript?
Или дальнейшее развитие:
<instruction name=«mov»>
<param=«ax» value=...>
Среди нововведений в нем, в частности, реализован набор инструкций SSE4.2. В этой версии они сделали упор на ускорение специфических задач. В частности, добавлено пять инструкций, предназначенных для ускорения разбора XML-файлов. Также с помощью этих инструкций возможно ускорение обработки строк в целом.
Команды SSE 4.2 позволяют параллельно оперировать 16 байтами в двух строках.
У Intel есть некая библиотека XML Software Suite, которая уже использует новые инструкции.
На эту тему у них есть статья с объяснением используемых алгоритмов. Надо сказать, очень познавательно. Я даже уже перевел половину, но не уверен, интересно ли это кому-нибудь. Они заявляют о 25-70% ускорении синтаксического разбора XML.
А в целом наблюдается интересная тенденция перехода от процессоров общего назначения на специализированные. Intel уже придумала для этого новое название — ATA (Application Targeted Accelerators).
В следующей версии будет аппаратная поддержка JavaScript?
Или дальнейшее развитие:
<instruction name=«mov»>
<param=«ax» value=...>
Отдам Кармаграф в хорошие руки
1 мин
 Даром отдам Кармаграф в умелые руки питоновода. Мой интерес к Кармаграфу иссяк уже давно и полностью, интерес к Хабрахабру как к организму, в чьей жизни я принимаю участие, тоже иссяк. Между тем проект крутится на сервере, потребляет место, память, время и вообще ведёт себя как сорняк.
Даром отдам Кармаграф в умелые руки питоновода. Мой интерес к Кармаграфу иссяк уже давно и полностью, интерес к Хабрахабру как к организму, в чьей жизни я принимаю участие, тоже иссяк. Между тем проект крутится на сервере, потребляет место, память, время и вообще ведёт себя как сорняк.Как зарегистрировать домен бесплатно
2 мин

На удивление оказывается, что многие незнают о существовании зон, свободных для регистрации. Более того, многие платят за регистрацию доменов в этой зоне деньги — стандартная цена у известных регистраторов от 5 до 15 у.е. за то, что можно сделать самому бесплатно.
Вот какие домены можно зарегистрировать абсолютно бесплатно:
Украина
.net.ua, .od.ua, .org.ua, и множество вида регион.ua
Россия
.com.ru, .net.ru, org.ru, pp.ru, .msk.ru, spb.ru и множество остальных типа регион.ru
Ниже инструкция типа «домен бесплатно для чайников»
Иерархические (рекурсивные) запросы
10 мин
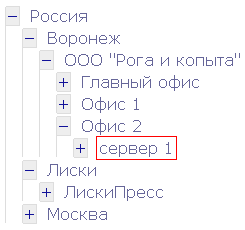
Чтобы понять рекурсию, сначала надо понять рекурсию. Возможно, поэтому рекурсивные запросы применяют так редко. Наверняка вы представляете что такое SQL-запрос, я расскажу, чем рекурсивные запросы отличаются от обычных. Тема получилась объемная, приготовьтесь к долгому чтению. В основном речь пойдет об Oracle, но упоминаются и другие СУБД.
Разработка на PC и производительность — Memory Latency
7 мин
Herb Sutter (автор Exceptional C++, бывший глава ISO C++ standards committee, мистер Free Lunch Is Over и прочая, и прочая) работает в Microsoft и иногда по средам читает атомные лекции.
Я наконец-то на одну такую попал, и очень радовался. На умных мужиков всегда радостно поглядеть и послушать.
Для отчета — кроме Херба, видел живого Олександреску и живого Walter Bright (который "D").
Лекция называлась «Machine Architecture: Things Your Programming Language Never Told You» (здесь можно скачать презентацию и видео) и была про конкретную часть abstraction penalty — Memory Latency.
Я попытаюсь коротко рассказать о ключевой мысли лекции. Она простая, очевидная и тысячу раз сказанная. Думаю, еще раз повторить азбуку — никогда не повредит.
Я наконец-то на одну такую попал, и очень радовался. На умных мужиков всегда радостно поглядеть и послушать.
Для отчета — кроме Херба, видел живого Олександреску и живого Walter Bright (который "D").
Лекция называлась «Machine Architecture: Things Your Programming Language Never Told You» (здесь можно скачать презентацию и видео) и была про конкретную часть abstraction penalty — Memory Latency.
Я попытаюсь коротко рассказать о ключевой мысли лекции. Она простая, очевидная и тысячу раз сказанная. Думаю, еще раз повторить азбуку — никогда не повредит.
Графические фильтры на основе матрицы скручивания
6 мин
UPD: Заголовок изменен, что бы более соответствовать теме статьи
В статье пойдет речь об использовании convolution matrix (матрицы скручивания или матрицы свертки), с помощью которой можно создавать и накладывать на изображения фильтры, такие как blur, sharpen и многие другие.
Cтатья будет интересна не только веб-программистам, но и всем кто так или иначе занимается программной обработкой изображений, поскольку функции для работы с матрицей скручивания имеются во многих языках (точно известно о php и flash). Так же, статья будет интересна дизайнерам, использующим Adobe Photoshop, поскольку в нем имеется соответствующий фильтр (Filter-Other-Custom).
Примеры будут на языке PHP с использованием библиотеки GD. Теория, практика, примеры (осторожно, много картинок!)
В статье пойдет речь об использовании convolution matrix (матрицы скручивания или матрицы свертки), с помощью которой можно создавать и накладывать на изображения фильтры, такие как blur, sharpen и многие другие.
Cтатья будет интересна не только веб-программистам, но и всем кто так или иначе занимается программной обработкой изображений, поскольку функции для работы с матрицей скручивания имеются во многих языках (точно известно о php и flash). Так же, статья будет интересна дизайнерам, использующим Adobe Photoshop, поскольку в нем имеется соответствующий фильтр (Filter-Other-Custom).
Примеры будут на языке PHP с использованием библиотеки GD. Теория, практика, примеры (осторожно, много картинок!)
Анти-паттерны Test Driven Development
4 мин
Перевод
Я надеюсь, что как грамотный разрабочик, вы имеете представление о unit-тестировании и сделаете себе в голове пару мысленных отметок о том, чего надо избегать при написании тестов. Знакомьтесь:
Unit-тест, который успешно выполняет все кейсы и выглядит работающим правильно, однако при более детальном рассмотрении обнаруживается, что он на самом деле не тестирует то, что должен.
Лжец (The Liar)
Unit-тест, который успешно выполняет все кейсы и выглядит работающим правильно, однако при более детальном рассмотрении обнаруживается, что он на самом деле не тестирует то, что должен.
Собственный сервер Git на базе Ubuntu или Debian/GNU Linux
2 мин
Я встречал в сети много tutorial'ов по установке своего сервера git как на gitweb, так и на webdav, но, увы, они либо были только по одному из вышеназванных пунктов, не освещая другой, либо банально не работали. Вчера возникла необходимость поднять свой сервер репозиториев. Потратил пару часов — поднял, теперь хочу поделиться опытом, потому что считаю проблему актуальной :)
Memcached: статистика, отладка и RPC
4 мин
Серия постов про “Web, кэширование и memcached” продолжается. Начало здесь: 1, 2, 3, 4 и 5.
В этих постах мы поговорили о memcached, его архитектуре, возможном применении, выборе ключа кэширования, кластеризации, атомарных операциях и реализации счетчиков в memcached, а также о проблеме одновременного перестроения кэшей и тэгировании кэшей.
Сегодняшний пост завершает эту серию, в нём обзорно мы поговорим о технических “мелочах”:
Полный текст всех разделов в виде одной большой PDF-ки можно скачать и посмотреть здесь (в разделе “Материалы”).
В этих постах мы поговорили о memcached, его архитектуре, возможном применении, выборе ключа кэширования, кластеризации, атомарных операциях и реализации счетчиков в memcached, а также о проблеме одновременного перестроения кэшей и тэгировании кэшей.
Сегодняшний пост завершает эту серию, в нём обзорно мы поговорим о технических “мелочах”:
- анализ статистики memcached;
- отладка memcached;
- “RPC” с помощью memcached.
Полный текст всех разделов в виде одной большой PDF-ки можно скачать и посмотреть здесь (в разделе “Материалы”).
Сброс группы кэшей и тэгирование в memcached
5 мин
Серия постов про “Web, кэширование и memcached” продолжается. Начало здесь: 1, 2, 3 и 4.
В этих постах мы поговорили о memcached, его архитектуре, возможном применении, выборе ключа кэширования, кластеризации, атомарных операциях и реализации счетчиков в memcached, а также о проблеме одновременного перестроения кэшей.
Сегодня мы поговорим о тэгировании кэшей и о возможности сброса сразу группы кэшей в memcached.

Последний, шестой пост, будет посвящен различным техническим вопросам работы с memcached: анализу статистике, отладке и т.п.
В этих постах мы поговорили о memcached, его архитектуре, возможном применении, выборе ключа кэширования, кластеризации, атомарных операциях и реализации счетчиков в memcached, а также о проблеме одновременного перестроения кэшей.
Сегодня мы поговорим о тэгировании кэшей и о возможности сброса сразу группы кэшей в memcached.
Последний, шестой пост, будет посвящен различным техническим вопросам работы с memcached: анализу статистике, отладке и т.п.
Проблема одновременного перестроения кэшей
4 мин
Серия постов про “Web, кэширование и memcached” продолжается. Начало здесь: 1, 2 и 3.
В этих постах мы поговорили о memcached, его архитектуре, возможном применении, выборе ключа кэширования, кластеризации, атомарных операциях и реализации счетчиков в memcached.
Сегодня мы рассмотрим проблему одновременного перестроения кэша, которая возникает при большом количестве одновременных обращений к кэшу, который был только что сброшен или потерян, что может привести к перегрузке БД.
Следующий пост будет посвящен тэгированию кэшей.
В этих постах мы поговорили о memcached, его архитектуре, возможном применении, выборе ключа кэширования, кластеризации, атомарных операциях и реализации счетчиков в memcached.
Сегодня мы рассмотрим проблему одновременного перестроения кэша, которая возникает при большом количестве одновременных обращений к кэшу, который был только что сброшен или потерян, что может привести к перегрузке БД.
Следующий пост будет посвящен тэгированию кэшей.