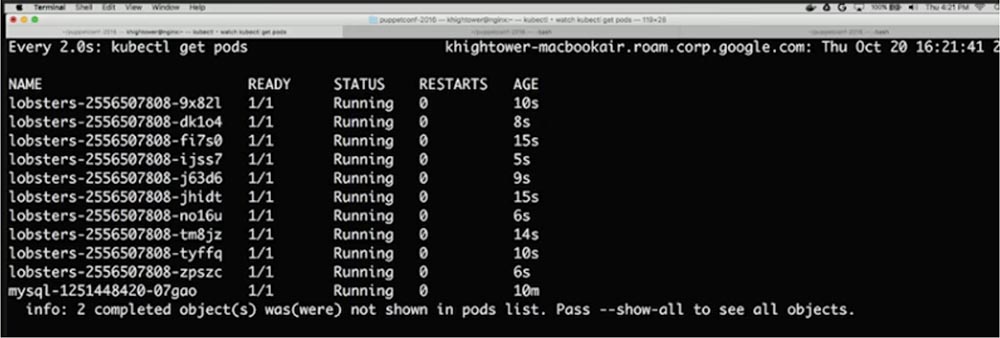
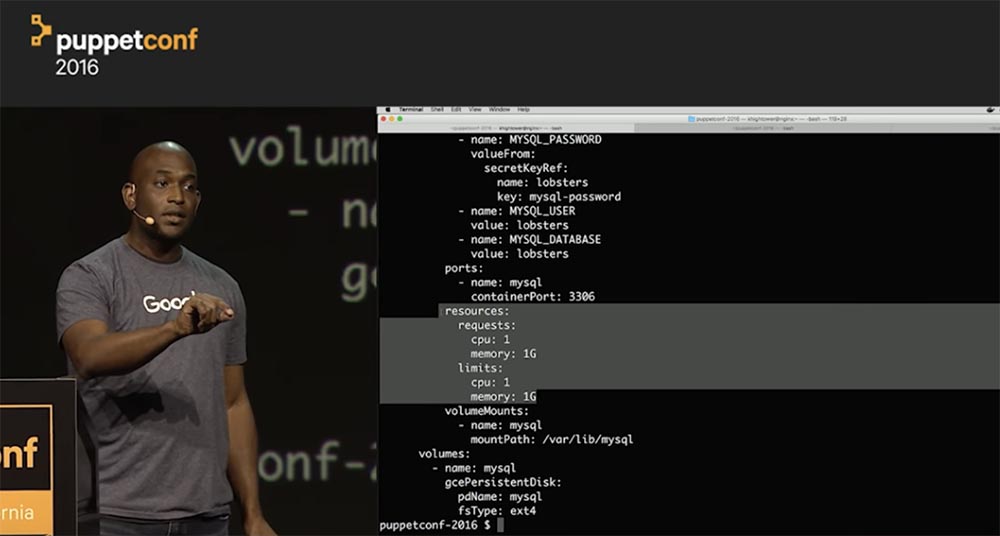
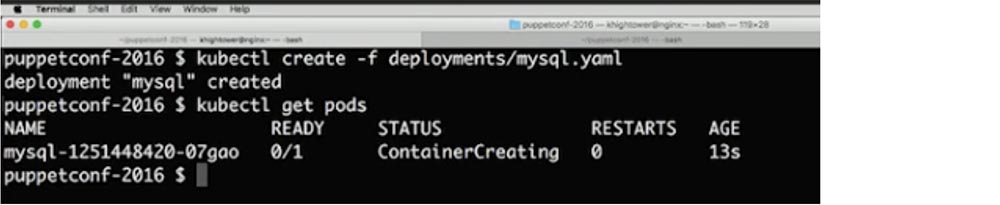
Вы потратили месяцы, переделывая свой монолит в микросервисы, и наконец, все собрались, чтобы щелкнуть выключателем. Вы переходите на первую веб-страницу… и ничего не происходит. Перезагружаете ее — и снова ничего хорошего, сайт работает так медленно, что не отвечает в течение нескольких минут. Что же случилось?
В своем выступление Джимми Богард проведет «посмертное вскрытие» реальной катастрофы микросервиса. Он покажет проблемы моделирования, разработки и производства, которые обнаружил, и расскажет, как его команда медленно трансформировала новый распределенный монолит в окончательную картину здравомыслия. Хотя полностью предотвратить ошибки проекта невозможно, можно, по крайней мере, выявить проблемы на ранней стадии проектирования, чтобы конечный продукт превратился в надежную распределенную систему.

Приветствую всех, я Джимми, и сегодня вы услышите, как можно избежать мегакатастроф при создании микросервисов. Эта история компании, в которой я проработал около полутора лет, чтобы помочь предотвратить столкновение их корабля с айсбергом. Чтобы рассказать эту историю должным образом, придется вернуться в прошлое и поговорить о том, с чего начиналась эта компания и как со временем росла ее ИТ-инфраструктура. Чтобы защитить имена невиновных в этой катастрофе, я изменил название этой компании на Bell Computers. На следующем слайде показано, как выглядела IT инфраструктура таких компаний в середине 90-х. Это типичная архитектура большого универсального отказоустойчивого сервера HP Tandem Mainframe для функционирования магазина компьютерной техники.
В своем выступление Джимми Богард проведет «посмертное вскрытие» реальной катастрофы микросервиса. Он покажет проблемы моделирования, разработки и производства, которые обнаружил, и расскажет, как его команда медленно трансформировала новый распределенный монолит в окончательную картину здравомыслия. Хотя полностью предотвратить ошибки проекта невозможно, можно, по крайней мере, выявить проблемы на ранней стадии проектирования, чтобы конечный продукт превратился в надежную распределенную систему.
Приветствую всех, я Джимми, и сегодня вы услышите, как можно избежать мегакатастроф при создании микросервисов. Эта история компании, в которой я проработал около полутора лет, чтобы помочь предотвратить столкновение их корабля с айсбергом. Чтобы рассказать эту историю должным образом, придется вернуться в прошлое и поговорить о том, с чего начиналась эта компания и как со временем росла ее ИТ-инфраструктура. Чтобы защитить имена невиновных в этой катастрофе, я изменил название этой компании на Bell Computers. На следующем слайде показано, как выглядела IT инфраструктура таких компаний в середине 90-х. Это типичная архитектура большого универсального отказоустойчивого сервера HP Tandem Mainframe для функционирования магазина компьютерной техники.