Обзор на Model Context Protocol (MCP) от Anthropic
Средний
6 мин
Перевод

На заре появления LLM пользователям приходилось просто копировать свой код в текстовое окно, чтобы ИИ могла его обработать. Естественно, такой подход быстро всех утомил, и разработчики начали искать свои способы загрузки данных в модель. У этого подхода была серьезная проблема — каждому приходилось изобретать велосипед заново.
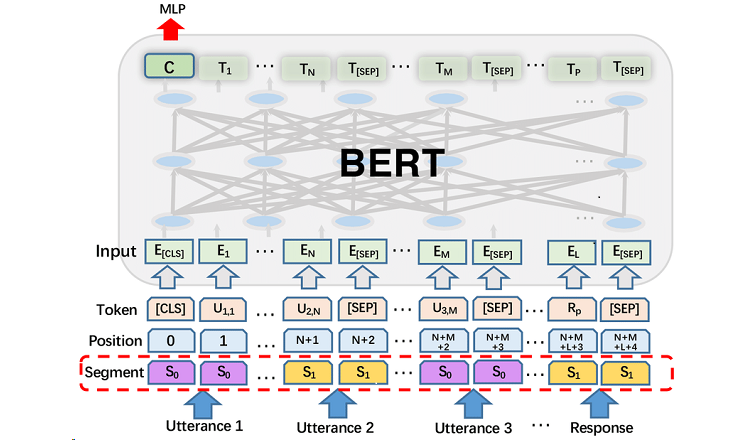
Именно поэтому появился протокол MCP (Model Context Protocol) — универсальный способ дать искусственному интеллекту доступ к нужным данным, неважно где они хранятся — на компьютере пользователя или же в интернете.