
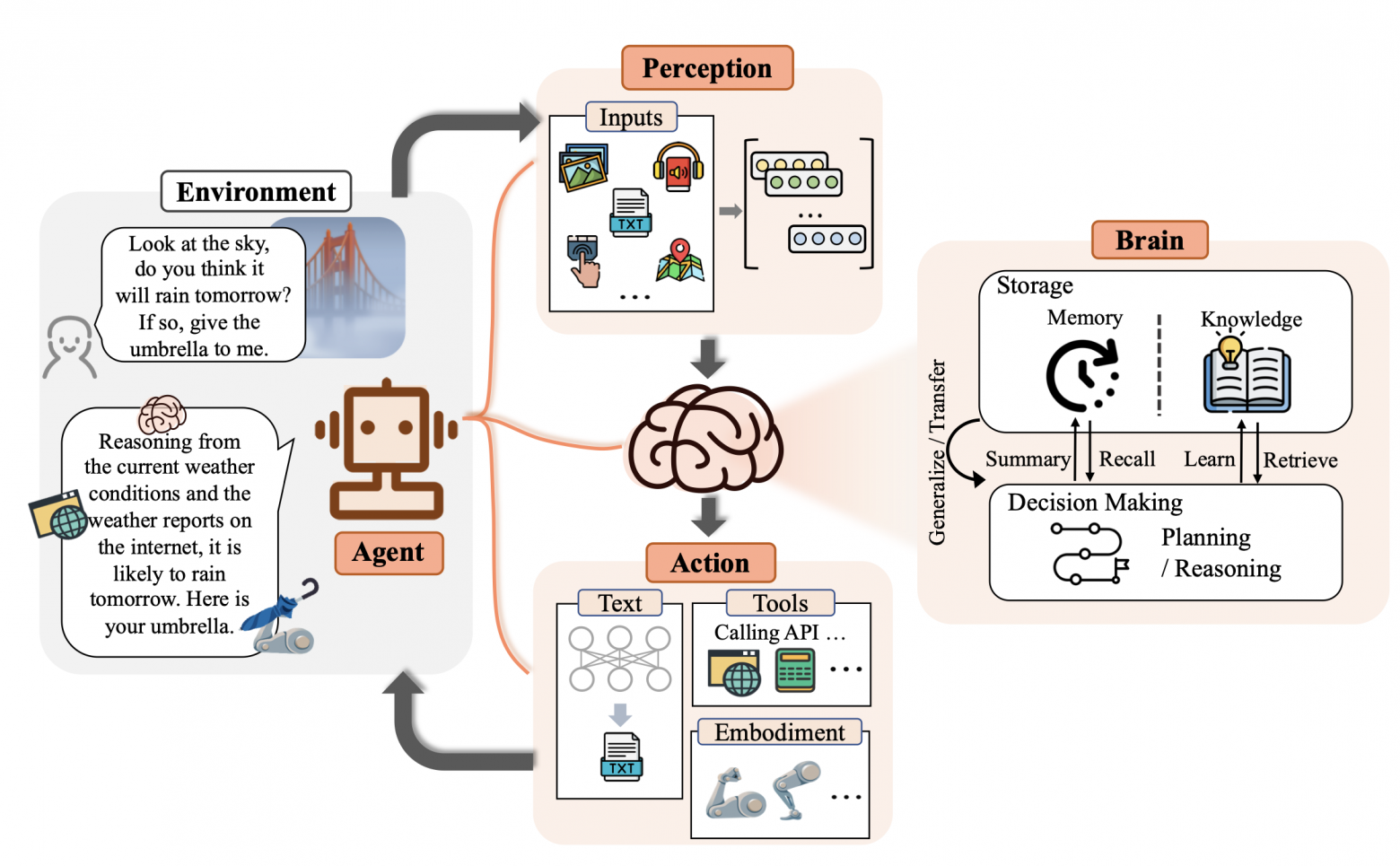
В последнее время большие языковые модели (Large Language Models, LLM) стали невероятно популярными — кажется, их обсуждают везде, от школьных коридоров до Сената США. Сфера LLM растёт бурными темпами, привлекая внимание не только специалистов в области машинного обучения, но и обычных пользователей. Кто-то высказывает массу опасений насчет их дальнейшего развития, а кто-то и вовсе предлагает бомбить дата-центры — и даже в Белом Доме обсуждают будущее моделей. Но неужели текстом можно кому-то навредить? А что если такая модель приобрела бы агентность, смогла создать себе физическую оболочку и полностью ей управлять? Ну, это какая-то фантастика из (не)далёкого будущего, а про агентов нашего времени я расскажу в этой статье. И не переживайте — знание машинного обучения вам не понадобится!

