
Как вы знаете, китайская LLM deepseek-R1 работает не хуже chatGPT-o1, но стоит в 20 раз дешевле. А знаете ли вы, что сама модель вообще бесплатная, её можно скачать себе и запустить на своём железе?
Мне стало интересно, как это делать, можно ли как-то запустить прямо на макбуке, и оказалось, что это делается буквально в два клика (конечно, полная модель на ноут не влезет, но дистиллированная - вполне).
Возможно, все уже это умеют, но расскажу для тех, кто, как и я, был в танке, так что держите инструкцию.
Для этого надо установить ollama, например так:
brew install ollama
и запустить
ollama serve
Запустить можно в отдельном окошке, чтобы смотреть логи, или в бекграунд убрать, пофиг. В общем, это некий сервис.
Дальше скачать и запустить модель. Это делается тупо одной командой.
ollama run deepseek-r1:8b
8b - это количество параметров (8 миллиардов). Другие варианты:
1.5b
7b
8b
14b
32b
70b
671b
Но понятно, что 671b на макбук не влезет, понадобилось бы больше 400 гигов видеопамяти. Зато 1.5b можно и на мобилу запихнуть.
При запуске этой команды скачивается модель (примерно 5 гигов), и собственно вы уже можете общаться с ней прямо в олламе.
Но это не очень юзер-френдли, поэтому дополнительно можно запусть web-интерфейс, например в докере одной командой
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
После чего на http://localhost:3000/ видна веб-морда, похожая на chatgpt.
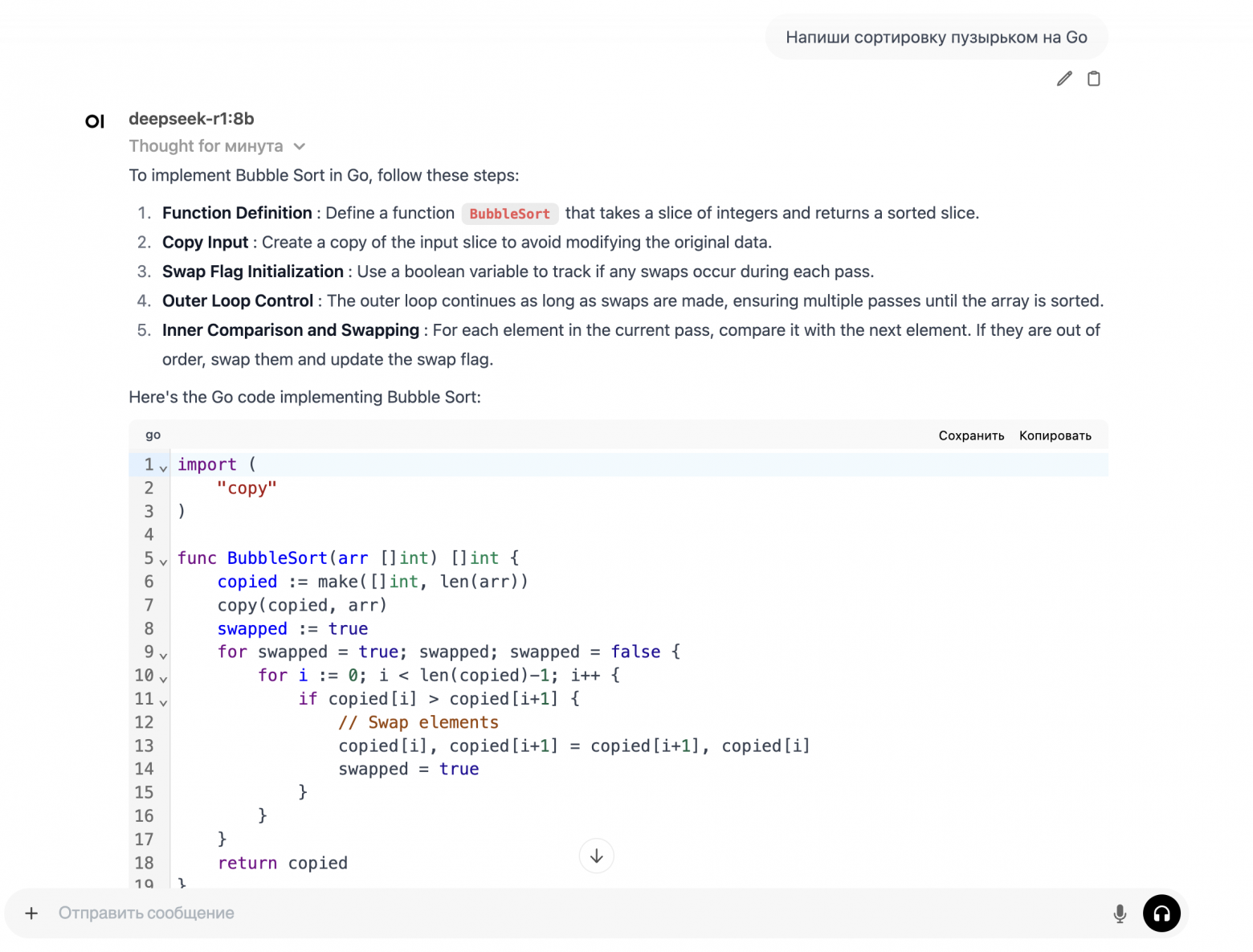
Прикол китайской модели еще в том, что там показан процесс думания. Его можно посмотреть прямо в этом веб-интерфейсе.
Понятно, что это скорее побаловаться - на ноуте влезает только дистиллированная модель и то нещадно тормозит (макбук M1 pro). Для полноценной работы нужно нормальное железо или облако.
По-моему, это очень круто: если вложиться в железо, можно очень быстро и просто поднять у себя самый топовый чат и не посылать больше свои секреты ни в OpenAI, ни в Китай.
Приглашаю вас подписаться на мой канал в telegram
