
Оглавление
- 1 часть
- 2 часть
Введение
Примечание к переводу
В Python есть такое понятие, как «code object», которое (насколько я знаю) не встречается в других языках. Привожу определение этого термина, а подробности можно узнать в этой единственной статье на русском языке.
Объект кода — это объект Python, который представляет кусок байт-кода вместе со всем, что необходимо для его исполнения: объявлением ожидаемых аргументов, их типов и количества, списком (не словарь! Об этом чуть позже) локальных переменных, информацией об источнике кода, из которого был получен байт-код (для отлаживания и вывода трассировки стека) и т.п. — ну и конечно (очевидно) сам байт-код в качестве str (или, в Python3, bytes).
Объект кода — это объект Python, который представляет кусок байт-кода вместе со всем, что необходимо для его исполнения: объявлением ожидаемых аргументов, их типов и количества, списком (не словарь! Об этом чуть позже) локальных переменных, информацией об источнике кода, из которого был получен байт-код (для отлаживания и вывода трассировки стека) и т.п. — ну и конечно (очевидно) сам байт-код в качестве str (или, в Python3, bytes).
Язык программирования Python существует уже довольно давно. Разработка первой версии была начата Гвидо Ван Россумом в 1989 году, и с тех пор язык вырос и стал один из самых популярных. Python используется в различных приложениях: начиная от графических интерфейсов и заканчивая приложениями для анализа данных.
Цель этой статьи — выйти за кулисы интерпретатора и предоставить концептуальный обзор того, как выполняется программа написанная на Python. В материале будет рассмотрен CPython, потому что на момент написания статьи он является наиболее популярной и основной реализацией Python.
Python и CPython используются в этом тексте как синонимы, но при любом упоминании Python имеется ввиду CPython (версия python, реализованная на C). К другим реализациям относится PyPy (python, реализованный в ограниченном подмножестве Python), Jython (реализация на Виртуальной машине Java) и т.д.
Мне нравится делить выполнение Python-программы на два или три основных этапах (указанных ниже), в зависимости от того, как вызывается интерпретатор. Эти этапы будут в разной степени охвачены в данной статье:
- Инициализация — этот этап включает в себя настройку различных структур данных, необходимых python-процессу. Вероятнее всего это произойдёт, когда программа будет выполняться в non-interactive режиме через оболочку интерпретатора.
- Компиляция — включает в себя такие действия, как: парсинг исходного кода для построения синтаксических деревьев, создание абстрактных синтаксических деревьев, создание таблицы символов и генерацию объектов кода.
- Интерпретация — этап фактического выполнения сгенерированных объектов кода в некотором окружении.
Механизм генерирования «парсинговых» деревьев, а также абстрактных синтаксических деревьев (АСД) не зависит от языка. Поэтому мы не будем очень сильно освещать данную тему, ведь методы используемые в Python, аналогичны методам других языков программирования. С другой стороны, процесс построения таблиц символов и объектов кода из АСД в Python более специфичны, поэтому заслуживают отдельного внимания. Также здесь рассматривается интерпретация объектов скомпилированного кода и всех остальных структур данных. Затронутые нами темы будут содержать, но не ограничиваться: процессом построения таблиц символов и созданием объектов кода, объектов-Python, объектов фреймов, объектов кода, функциональных объектов, кодов операций (opcode), циклом интерпретатора, генераторами и пользовательскими классами.
Этот материал предназначен для всех, кому интересно узнать, как работает виртуальная машина CPython. Предполагается, что пользователь уже знаком с python и понимает основы языка. При изучении строения виртуальной машины нам встретится значительное количество C-кода, поэтому пользователю, который имеет элементарное понимание языка C, будет легче разобраться в материале. И так, в основном, что потребуется для ознакомления с этим материалом: желание узнать больше о виртуальной машине CPython.
Эта статья представляет собой расширенную версию личных заметок, сделанных при исследовании внутренней работы интерпретатора. Существует много качественного материала в PyCon видео, школьных лекциях и данном блоге. Моя работа не была бы закончена без этих фантастических источников знаний.
В конце этой книги читатель будет в состоянии понять тонкости того, как интерпретатор Python выполняет вашу программу. Это включает в себя различные этапы выполнения программы и структуры данных, которые имеют решающее значение в программе. Для начала, мы рассмотрим с высоты птичьего полета то, что происходит при выполнении тривиальной программы, когда интерпретатору передаётся имя модуля в командной строке. Исполняемый код CPython может быть установлен из исходников, следуя Руководству Python разработчика.
В данной книге используется версия Python 3
Взгляд с высоты в 30 000 футов
В этой главе рассказывается о том, как интерпретатор выполняет Python программу. В последующих главах мы рассмотрим различные части этой «головоломки» и предоставим более подробное описание каждой части. Независимо от сложности программы, написанной на Python, данный процесс всегда одинаков. Прекрасное объяснение, данное Янивом Акниным в его серии статей о Python Internal, задаёт тему нашего обсуждения.
Исходный модуль test.py может быть выполнен из командной строки (при передаче его в качестве аргумента программе-интерпретатору Python в виде $python test.py). Это только один из способов вызвать исполняемый файл Python. Мы также можем запустить интерактивный интерпретатор, выполнить строки файла как код и т.д. Но этот и другие методы нас не интересуют. Именно передача модуля в качестве аргумента (внутри командной строки) исполняемому файлу (рисунок 2.1) лучше всего отражает поток различных действий, которые вовлечены в фактическое выполнение кода.
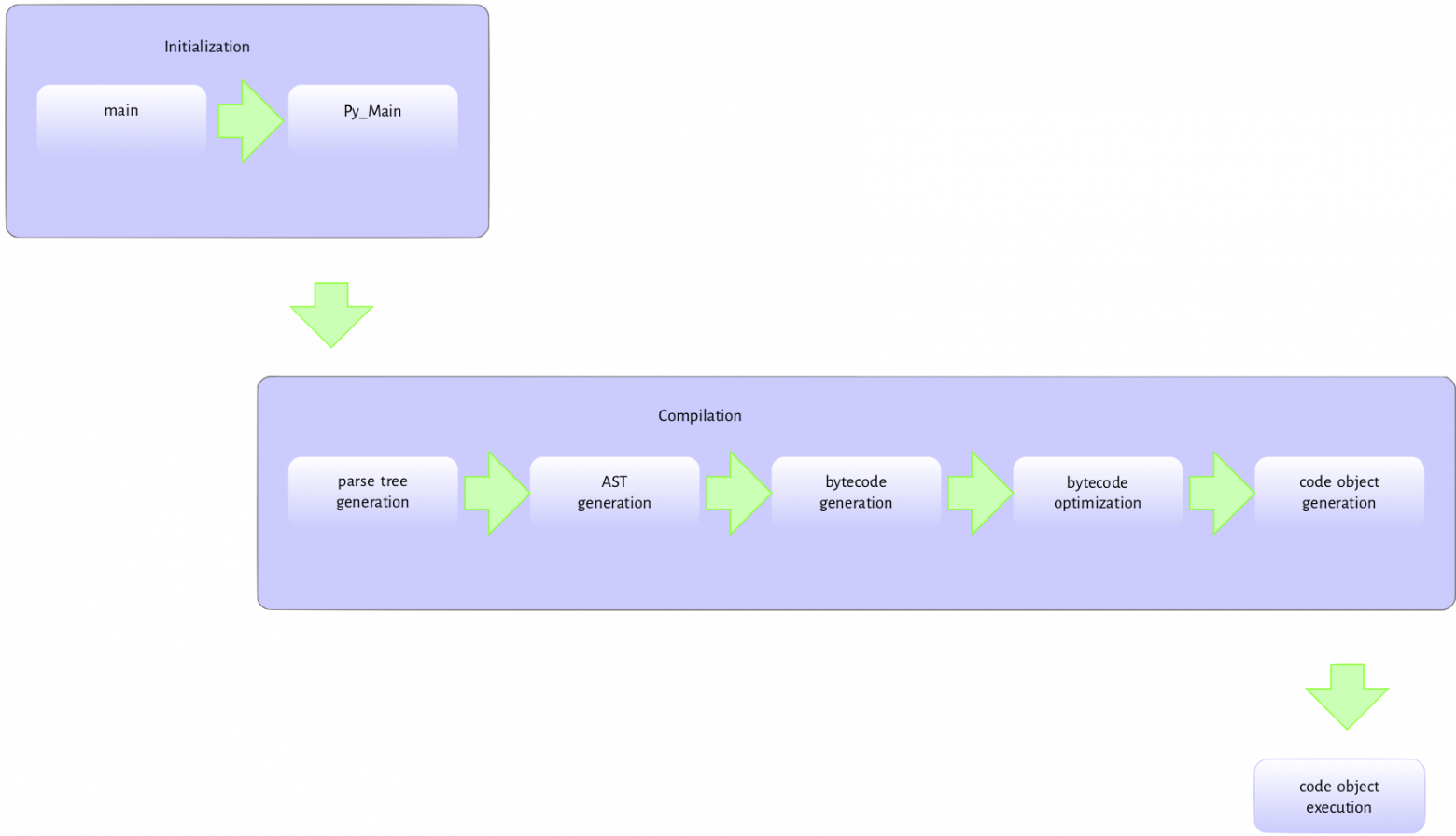
Рисунок 2.1: Поток во время выполнения исходного кода.
Исполняемый файл python — это обычная С-программа, поэтому при его вызове происходят процессы похожие на те, которые существуют, например, в ядре linux или простой программке «hello world». Потратьте минуту своего времени, чтобы понять: исполняемый файл python — это просто еще одна программа, которая запускает вашу собственную. Такие «отношения» существуют между языком Cи и ассемблером (или llvm). Стандартный процесс инициализации (который зависит от платформы, где происходит выполнение) запускается, когда вызывается исполняемый файл python с именем модуля в качестве аргумента.
Эта статье предполагает использование операционной системы на основе Unix, поэтому некоторые особенности могут отличаться на Windows.
Язык C во время запуска выполняет всю свою «магию» инициализации — загружает библиотеки, проверяет/устанавливает переменные среды, а после этого, основной метод исполняемого файла python запускается так же, как и любая другая C-программа. Пайтоновский main исполняемого файла находится в ./Programs/python.c и выполняет некоторую инициализацию (такую как создание копий аргументов командной строки программы, которые были переданы в модуль). Затем функция main вызывает функцию Py_Main, расположенную в ./Modules/main.c. Она обрабатывает процесс инициализации интерпретатора: анализирует аргументы командной строки, устанавливает флаги, читает переменные среды, выполняет хуки, занимается рандомизацией хеш-функций и т.д. Также вызывается Py_Initialize из pylifecycle.c, который обрабатывает инициализацию структур данных состояния интерпретатора и потока — это две очень важные структуры данных.
Рассмотрение объявлений структур данных интерпретатора и состояний потоков позволяет понять, зачем они нужны. Состояние интерпретатора и потока — это просто структуры с указателями на поля, которые содержат информацию, необходимую для выполнения программы. Данные состояния интерпретатора создаются через typedef (просто думайте об этом ключевом слове в C, как об определении типа, хотя это не совсем так). Код этой структуры приведён в листинге 2.1.
1 typedef struct _is { 2 3 struct _is *next; 4 struct _ts *tstate_head; 5 6 PyObject *modules; 7 PyObject *modules_by_index; 8 PyObject *sysdict; 9 PyObject *builtins; 10 PyObject *importlib; 11 12 PyObject *codec_search_path; 13 PyObject *codec_search_cache; 14 PyObject *codec_error_registry; 15 int codecs_initialized; 16 int fscodec_initialized; 17 18 PyObject *builtins_copy; 19 } PyInterpreterState;
Листинг 2.1: Структура данных состояния интерпретатора
Любой, кто достаточно долго использовал язык программирования Python, может узнать несколько полей, упомянутых в этой структуре (sysdict, builtins, codec).
- Поле *next представляет собой ссылку на другой экземпляр интерпретатора, поскольку несколько интерпретаторов Python могут существовать в рамках одного процесса.
- Поле *tstate_head указывает на главный поток выполнения (если программа многопоточная, то интерпретатор является общим для всех потоков, созданных программой). Подробнее мы обсудим это в ближайшее время.
- modules, modules_by_index, sysdict, builtins и importlib — говорят сами за себя. Все они определены как экземпляры PyObject, который является корневым типом для всех объектов в виртуальной машине Python. Объекты пайтона будут рассмотрены более подробно в следующих главах.
- В полях относящихся к codec* содержится информация, которая помогает с загрузкой кодировок. Это очень важно для декодирования байтов.
Выполнение программы должно происходить в потоке. Структура состояния потока содержит всю информацию, которая нужна потоку для выполнения некоторого объекта кода. Часть структуры данных потока показана в листинге 2.2.
1 typedef struct _ts { 2 struct _ts *prev; 3 struct _ts *next; 4 PyInterpreterState *interp; 5 6 struct _frame *frame; 7 int recursion_depth; 8 char overflowed; 9 10 char recursion_critical; 11 int tracing; 12 int use_tracing; 13 14 Py_tracefunc c_profilefunc; 15 Py_tracefunc c_tracefunc; 16 PyObject *c_profileobj; 17 PyObject *c_traceobj; 18 19 PyObject *curexc_type; 20 PyObject *curexc_value; 21 PyObject *curexc_traceback; 22 23 PyObject *exc_type; 24 PyObject *exc_value; 25 PyObject *exc_traceback; 26 27 PyObject *dict; /* Stores per-thread state */ 28 int gilstate_counter; 29 30 ... 31 } PyThreadState;
Листинг 2.2: Часть структуры данных состояния потока
Структуры данных интерпретатора и состояния потока обсуждаются более подробно в следующих главах. Процесс инициализации также устанавливает механизмы импорта, а также элементарный stdio.
После завершения всей инициализации, Py_Main вызывает функцию run_file (также расположенную в модуле main.c). Далее следует серия вызовов функций: PyRun_AnyFileExFlags -> PyRun_SimpleFileExFlags -> PyRun_FileExFlags -> PyParser_ASTFromFileObject. PyRun_SimpleFileExFlags создает пространство имен __main__, в котором будет выполняться содержимое файла. Он также проверяет, существует ли pyc-версия файла (pyc-файл представляет собой простой файл, содержащий уже скомпилированную версию исходного кода). В случае, если pyc-версия существует, будет сделана попытка прочитать её как двоичный файл, а затем запустить. Если же pyc-файл отсутствует, то вызовется PyRun_FileExFlags и т.д. Функция PyParser_ASTFromFileObject вызывает PyParser_ParseFileObject, который читает содержимое модуля и строит из него деревья парсинга (parse tree). Затем созданное дерево передается в PyParser_ASTFromNodeObject, которое создаёт из него абстрактное синтаксическое дерево.
Если вы уже просмотрели исходный код, то наверняка столкнулись с Py_INCREF и Py_DECREF. Это функции управления памятью, которые мы позже обсудим подробно. CPython управляет жизненным циклом объекта с помощью подсчета ссылок: всякий раз, когда создается новая ссылка на объект, значение увеличивается через Py_INCREF. Аналогично, когда ссылка выходит из области видимости, то счётчик уменьшается с помощью функции Py_DECREF.
АСТ генерируется при вызове run_mod. Эта функция вызывает PyAST_CompileObject, которая создает объекты кода из AST. Обратите внимание, что байт-код, сгенерированный во время вызова PyAST_CompileObject, передается через простой оптимизатор peephole, который выполняет низкую оптимизацию сгенерированного байт-кода перед созданием объектов кода. Затем функция run_mod применяет функцию PyEval_EvalCode из файла ceval.c на объекта кода. Это приводит к другой серии вызовов функций: PyEval_EvalCode -> PyEval_EvalCode -> _PyEval_EvalCodeWithName -> _PyEval_EvalFrameEx. Объект кода передаётся в качестве аргумента большинству из этих функций в той или иной форме. _PyEval_EvalFrameEx — это обычный цикл интерпретатора, который обрабатывает выполнение объектов кода. Однако, он вызывается не просто с объектом кода в качестве аргумента, а с объектом фрейма, который имеет в качестве атрибута поле, ссылающееся на объект кода. Этот фрейм обеспечивает контекст для выполнения объекта кода. Если говорить простыми словами: цикл интерпретатора непрерывно считывает следующую инструкцию, указанную счетчиком команд, из массива инструкций. Затем он выполняет эту инструкцию: добавляет или удаляет объекты из стека значений в процессе, пока в массив инструкций, которые нужно выполнить, не опустеет (ну или не произойдет что-то исключительное, что нарушит работу цикла).
Python предоставляет набор функций, которые можно использовать для изучения реальных объектов кода. Например, простая программа может быть скомпилирована в объект кода и дизассемблирована для получения opcode-ов, которые выполняются виртуальной машиной python. Это показано в листинге 2.3.
1 >>> def square(x): 2 ... return x*x 3 ... 4 5 >>> dis(square) 6 2 0 LOAD_FAST 0 (x) 7 2 LOAD_FAST 0 (x) 8 4 BINARY_MULTIPLY 9 6 RETURN_VALUE
Листинг 2.3: Дизассемблирование функции в Python
Заголовочный файл ./Include/opcodes.h содержит полный список всех инструкций/опкодов для виртуальной машины Python. Opcode-ы довольно просты. Возьмем наш пример из листинга 2.3, который имеет набор из четырех инструкций. LOAD_FAST загружает значение своего аргумента (в данном случае x) в стек значений. Виртуальная машина python основана на стеке, поэтому значения для операций опкодов «достаются» из стека, а результаты вычислений помещаются обратно в стек, для дальнейшего использования другими опкодами. Затем BINARY_MULTIPLY извлекает два элемента из стека, выполняет двоичное перемножение обоих значений и помещает результат обратно в стек. Инструкция RETURN VALUE извлекает значение из стека, устанавливает возвращаемое значение для объекта в это значение и выходит из цикла интерпретатора. Если посмотреть на листинг 2.3, то ясно, что это довольно сильное упрощение.
Текущее объяснение работы цикла интерпретатора не учитывает ряд деталей, которые будут обсуждаться в последующих главах. Например, вот вопросы на которые мы не получили ответа:
- Откуда получены значения, которые загружаются инструкцией LOAD_FAST?
- Откуда берутся аргументы, которые используются, как часть инструкций?
- Как управляются вложенные вызовы функций и методов?
- Как цикл интерпретатора обрабатывает исключения?
После выполнения всех инструкций, функция Py_Main продолжает выполнение, но на этот раз запускает процесс очистки. Если Py_Initialize вызывается для выполнения инициализации во время запуска интерпретатора, то Py_FinalizeEx вызывается для выполнения очистки. Данный процесс включает в себя ожидание выхода из потоков, вызов любых обработчиков выхода, а также освобождение все-ещё используемой памяти, выделенной интерпретатором.
И так, мы рассмотрели «на высоком уровне» описание процессов, которые происходят в исполняемом файле Python при запуске какого-то скрипта. Как отмечалось ранее, остается много вопросов, на которые еще предстоит ответить. В дальнейшем мы углубимся в изучение интерпретатора и подробно рассмотрим каждый из этапов. И начнём мы с описания процесса компиляции в следующей главе.
