Comments 122
Без этого как-то даже не верится, что это действительно результаты работы не человека.
Или это действительно нейросеть, но авторы вручную отфильтровали 99% шлака…
Давайте посмотрим на примеры, которые говорят сами за себя. Исследователи утверждают, что не использовали ручной «cherry picking». Примерами являются изображения, полученные при помощи DALL · E, в которых используются 32 лучших примера из 512-ти сгенерированных, отобранных созданным ранее (теми же openai) нейронным ранжированием CLIP.То есть, по сути, это и есть cherry picking, но не ручной, а при помощи другой модели. Я считаю, что это вполне честно. Мы же не пишем и не говорим все то, что пришло к нам в голову, а фильтруем и выбираем, что говорить и что писать.

Я конечно сам делал «cherry picking» самых плохих вариантов. В остальных случаях оно заметно лучше. А вообще, года бы 3-4 назад даже такой результат считался бы просто сногшибательным.
Но помни: гнев, страх — это всё ведет на темную сторону Силы.
Как только ты сделаешь первый шаг по темному пути,
ты уже не сможешь с него свернуть…


Также, сотрудники из openai выразили озадаченность тем, что уровень реалистичности и результаты работы современных генеративных моделей могут оказать сильное влияние на общество.
например "кресло в форме авокадо."
a snail made of harp
Поискал картинки, везде рисуют каких-то несуществующих животных или мультяшные фигуры. Как-то не очень заметна реалистичность.
На рисунке с очками лишние дужки присутствуют, на рисунке со стаканами стаканы какие-то кривые.
Забавно, что алгоритм способен к мультимодальности, и справляется с неоднозначностью слова glasses в английском языке.
А по-моему нифига не справляется, то одно рисует, то другое. Если бы справлялся, то уточнил бы, или один и тот же смысл всегда выбирал. На первом в третьем ряду вообще оба сразу присутствуют.
DALL · E выучил исторический и географический контекст
А по-моему он просто запомнил связь слов с картинками — "1920" чаще встречается с одними картинками, "1940" с другими. ОБработка морфологии слов хорошая конечно, а вот про контекст как-то сомнительно.
В целом думаю так. Это все круто, но бесполезно. Ни для какого-то серьезного практического применения, ни для развития ИИ в целом. Вот научилась нейросеть картинки рисовать, приблизило это нас к пониманию, как сделать сильный ИИ? Похоже что нет. Новых закономерностей не выявлено, все подходы к обработке информации были известны и ранее. Как у нее кстати с русским языком, надо заново тренировать? Похоже что так.
С обобщением у вас точно не получилось. Я наоборот вчера только думал а как бы по тексту чтоб фильм автоматом создавался. А тут такое. Этот шаг с генерацией изображений по тексту очень важен. И в том числе для сильного ии. Когда мы говорим чтото друг другу мы порождаем образы у собеседника.
Значит ли это, что человечеству не нужны экскаваторы?
Не значит. Но корректность аналогии данной сети с экскаватором не доказана. Поэтому вполне может быть так, что экскаваторы нужны, а эта нейросеть бесполезна.
Аналогия вполне хорошая. Экскаватор — усилитель умения копать.
Скажем, при помощи текстовой GPT-3 я могу накидать себе текст гораздо лучше, чем это получается только у меня самого. Имеем усилитель писательских талантов.
А эта сеть — позволит мне делать приемлемые иллюстрации для этого текста, когда я сам рисую почти никак. Получили усилитель умения рисовать.
Так я и написал "серьезного практического применения". Для себя поиграться-то конечно можно с любой технологией.
Аналогия вполне хорошая. Экскаватор — усилитель умения копать.
Из этого не следует, что остальные их свойства (например полезность для человечества) тоже являются аналогичными. Аналогии вообще применяются для пояснения, а не для доказательства.
Так я и написал "серьезного практического применения".
Написание всяких речей для политиков разного калибра пойдет за 'серьезное'?
Все эти сценарии из разных антиутопий, где мифический правитель читает воодушевляющие автоматически сгенерированные речи — уже практически возможны.
Полезность тут, конечно, сильно зависит от того, в какую сторону используется, но тем не менее возможную серьёзность вполне демонстрирует.
пойдет за 'серьезное'?
Неа. Сгенерировать 10 вариантов, из которых человек потом будет выбирать наиболее осмысленный, это несерьезно. Вот если бы ИИ сам наиболее осмысленный выбирал, тогда еще можно было бы согласиться.
Я вообще имел в виду то, что написано в статье — генерацию изображений по описанию.
Исследователи утверждают, что не использовали ручной «cherry picking». Примерами являются изображения, полученные при помощи DALL · E, в которых используются 32 лучших примера из 512-ти сгенерированных, отобранных созданным ранее (теми же openai) нейронным ранжированием CLIP.Именно то, что Вы описали:
Вот если бы ИИ сам наиболее осмысленный выбирал, тогда еще можно было бы согласиться.
Нет, не то. Очки с 3 дужками и кривые стаканы это не "наиболее осмысленный".
 «Постоянство памяти» (исп. La persistencia de la memoria, 1931)
«Постоянство памяти» (исп. La persistencia de la memoria, 1931)А разве этой нейросети было задание сгенерировать изображения в стиле Дали? Если нет, значит это ошибка в выполнении задания.
Человек вполне может нарисовать очки как с тремя, так и вовсе без дужек и это назовут «творчество». Еще недавно ИИ обвиняли в том, что он действует сугубо по программе и не способен к творческому подходу. Теперь, когда он создает творческие образы, его обвиняют в том, что он не способен решить задачу достаточно четко. Да вам, человекам, не угодишь…
А как бы вы сами нарисовали очки, если бы у вас не было возможности уточнить запрос, но была бы возможность выдать несколько вариантов?
Теперь, когда он создает творческие образы
Не создает. Сначала докажите, что это творческие образы, а не ошибка в выполнении задачи. А то так и генератор случайных чисел можно творческим назвать.
его обвиняют в том, что он не способен решить задачу достаточно четко. Да вам, человекам, не угодишь…
Да, если решать задачу не так как требуется, то будут обвинять в том, что задача не решена. Какая неожиданность)
А как бы вы сами нарисовали очки, если бы у вас не было возможности уточнить запрос, но была бы возможность выдать несколько вариантов?
Это некорректный вопрос. Эта нейросеть пока не демонстрирует интеллект уровня человека, чтобы можно было сравнивать ее поведение с человеком.
Проблема тут как раз в том, какого черта у нее один из вариантов это очки с 3 дужками. Она ведь точно знает, что у очков 2 дужки. Или… не знает?
Эта нейросеть пока не демонстрирует интеллект уровня человека, чтобы можно было сравнивать ее поведение с человеком.
- Что значит интеллект уровня человека ? Человек не сможет так нарисовать..
- Кто-то сравнивал ее с человеком? Если да, то кто и зачем?
- Если что-то или кто-то не демонстрирует интеллект уровня человека, то с этим чем-то или кем-то нельзя сравнивать? Если да, то почему?
- Что значит «эта сеть пока не демонстрирует»? Нейронные сети и конкретно DALL · E это одна развивающаяся во времени сеть?
- Кто сравнивает поведение DALL · E с поведением человека?
- О каком поведении идет речь? Это не rl модель. Она себя не ведет.
И последний вопрос: «У очков может быть только две дужки?»
А что Вы пытаетесь показать?
"Если нет, значит это ошибка в выполнении задания".
Что значит интеллект уровня человека?
Я уже несколько раз повторил — применительно к данной нейросети это значит, что очки надо рисовать с 2 дужками, а стаканы в форме стаканов.
Кто-то сравнивал ее с человеком? Если да, то кто и зачем?
Кто сравнивает поведение DALL · E с поведением человека?
Да. Elegar в этом комментарии, во фразе, которую я процитировал. Зачем, не знаю, спросите у него.
Если что-то или кто-то не демонстрирует интеллект уровня человека, то с этим чем-то или кем-то нельзя сравнивать?
Если что-то или кто-то не демонстрирует интеллект уровня человека, то это что-то или этого кого-то нельзя сравнивать с человеком. В частности, вопросами "как бы вы сами это сделали". Неважно, как бы я это сделал, нейросеть (которая не демонстрирует интеллект уровня человека) делает это по другим причинам. Например, выбирает генератором случайных чисел.
Нейронные сети и конкретно DALL · E это одна развивающаяся во времени сеть?
Нет. Из моих слов это не следует.
Что значит «эта сеть пока не демонстрирует»?
Ну то и значит — нейросеть DALL · E, описанная в статье, на данный момент не демонстрирует интеллект уровня человека. Возможно кто-то через некоторое время найдет способ дообучить такую сеть, не добавляя какие-то новые принципы работы, и она будет демонстрировать интеллект уровня человека. Но я в этом сомневаюсь.
О каком поведении идет речь? Это не rl модель. Она себя не ведет.
Поведение (словарь Ушакова) — Совокупность поступков и действий
Поведение (справочник технического переводчика) — Совокупность действий, изменений изучаемой системы, ее всякая реакция на внешние воздействия
Любая система, совершающая какие-то действия, как-то себя ведет. Действия DALL-E — генерация изображений по заданному тексту.
У очков может быть только две дужки?
У очков не может быть такой дужки, которая указана на рисунке. Это некорректное выполнение задания "нарисуй очки". У нее вообще ни на одном рисунке нет правильно нарисованных дужек.
Разумеется, нейросеть не знает ничего про то, как и зачем устроены очки. Она не имела возможности одеть их или хотя бы покрутить в руках. Она знает лишь, что очки выглядят примерно вот так. С другой стороны, и требования рисовать исключительно реалистичные очки или очки с двумя дужками у нее не было. Вы сами придумали это требование. Возможно, если бы в запросе уточнили, что должно быть именно 2 дужки, то она бы так и нарисовала. То, что эта нейронка умеет считать (правда, всего до трех), вы бы поняли сами, если бы прочитали оригинал статьи — пример с очками иллюстрирует как раз это, только считает она там не дужки, а сами очки
PS Если бы мне сказали нарисовать 30 разных картинок с очками, я бы тоже стал всякие дурацкие вариации придумывать.
Сперва докажите, что картина Ван Гога — это не ошибка в выполнении задачи:)
Да запросто — у Ван Гога была задача "нарисуй очки"? Если нет, то это не ошибка в выполнении задачи.
Кроме того, про челоека нам уже известно, что у него есть интеллект. Поэтому нестандартные выполнения задачи мы называем творчеством. Мы знаем, что если человек захочет сделать задачу правильно, то он так и сделает.
А про нейросети мы такого сказать не можем. Более того, если на уроке рисования ученик нарисует очки неправильно, учитель ему снизит оценку. Так как это тоже ошибка в выполнении задания.
С другой стороны, и требования рисовать исключительно реалистичные очки или очки с двумя дужками у нее не было.
Было. "a collection of glasses sitting on the table". Если не указано иное, надо рисовать правильно.
Это как раз к вопросу про интеллект уровня человека.
Возможно, если бы в запросе уточнили, что должно быть именно 2 дужки, то она бы так и нарисовала.
Это ничем не отличается от обычного программирования, какой же это тогда интеллект?
Если бы мне сказали нарисовать 30 разных картинок с очками, я бы тоже стал всякие дурацкие вариации придумывать.
А почему вы бы это стали делать? Какие понятия возникли бы в вашем воображении, какие информационные элементы активировались при выполнении этого решения? Разница именно в этом. Генератор случайных чисел тоже разные вариации придумывает. Будем считать его сильным ИИ?
Если не указано иное, надо рисовать правильно.Фактически, у нас тут безблагодатный спор об определениях. Вы считаете, что сеть обязана рисовать правильно. Я считаю, что не обязана. Как можно правильно нарисовать кресло в форме авокадо? Слона в форме арфы? Если мы хотим чтобы она рисовала абстрактные вещи, то мы должны прощать ей «свободу выражения» (пишу в кавычках, чтобы подчеркнуть, что не очеловечиваю ее).
del
Фактически, у нас тут безблагодатный спор об определениях. Вы считаете, что сеть обязана рисовать правильно.
Она обязана рисовать правильно, потому что ей не было задания рисовать неправильно.
Очки с 2 дужками это то, что представляет любой человек при слове "очки". Даже если он с 4 дужками представляет, он все равно знает, что другие люди подразумевают более стандартную форму. Это и есть интеллект уровня человека, и данная сеть его не демонстрирует. Поэтому я так и сказал.
И кстати об определениях.
Очки — Прибор с двумя стеклами для улучшения зрения или для защиты глаз, надеваемый на переносицу и держащийся на ней при помощи двух дужек, закладываемых за уши.
Как можно правильно нарисовать кресло в форме авокадо?
Если мы хотим чтобы она рисовала абстрактные вещи
А при чем тут авокадо и абстрактные вещи? Я говорил про очки и стаканы.
И да, на первом во втором ряду кресло нарисовано неправильно. Такой ножки у такого кресла быть не может, оно упадет. Тут конечно требуется понятие гравитации, с которым сеть не знакома, но нарисовать неправильно можно.
Действительно, а кто говорит о сильном ИИ?
Ну я об этом сказал:
"Это все круто, но бесполезно. Ни для какого-то серьезного практического применения, ни для развития ИИ в целом."
А мне начали возражать, что это не так.
И потом Elegar задал вопрос "А как бы вы сами нарисовали очки?". Это тоже разговор о сильном ИИ, который есть у человека.
Разве это не восхитительно?
Я не говорил, что это не восхитительно. Я сразу сказал, что да, это круто. Только бесполезно.
я открою вам небольшой секрет — бывают очки с одной дужкой и вообще без дужек — монокль и пенсне называются ) поэтому требование наличия двух дужек это конкретно ваше требование. Я лично носил пару дней очки с одной отвалившейся дужкой, вторая сидела на ухе как влитая и очки продолжали быть очками. Это не требование к ИИ, а Ваши личные загоны
Открою вам небольшой секрет — монокль и пенсне называются "монокль" и "пенсне", а не "очки". На английском "monocle" и "pince-nez", а не "glasses".
А поиск в Google-картинках по запросу "glasses" выдает только очки с 2 дужками, а не монокль или пенсне.
Я лично носил пару дней очки с одной отвалившейся дужкой
Это не требование к ИИ, а Ваши личные загоны
То есть я должен был ожидать, что ИИ по текстовому запросу "glasses" должен нарисовать очки с 3 дужками, потому что вы носили пару дней очки с одной дужкой, причем об этом я вообще не знал до того, как вы про это сообщили? Извините, но это ваши загоны. А у остальных людей слово "очки" означает очки с 2 дужками, если иное не указано явно.

Неа. Сгенерировать 10 вариантов, из которых человек потом будет выбирать наиболее осмысленный, это несерьезно. Вот если бы ИИ сам наиболее осмысленный выбирал, тогда еще можно было бы согласиться.
И почему всегда желания такие максимальные?
Экскаватор — он же тоже не сам капает. Он помогает человеку выкопать больше. И радикально уменьшает требование к физической подготовке этого человека. И швейная машинка не сама шьет. А автомобиль до недавних пор не сам ездил.
И тут так же. GPT-3 помогает одному человеку налить больше красивой длинной воды на любую заданную тему, не особенно напрягаясь и значительно убирает требование умения красиво писать.
Ну и пусть убирает. Обычные программы без ИИ тоже много работы за человека делают. Я не понимаю, на что вы возражаете.
"Налить больше красивой длинной воды" в моем понимании
это не "серьезное практическое применение искусственного интеллекта".
«Вопрос о том, может ли компьютер думать, не более интересен,Эдсгер Вибе Дейкстра
чем вопрос о том, может ли субмарина плавать».
Можно считать, что данные сетки — это 'коллективное бессознательное' всего человечества. Вполне ценный артефакт для таканья палочкой и исследования.
Этот шаг с генерацией изображений по тексту очень важен. И в том числе для сильного ии.
Как именно важен-то? Что он дает?
Когда мы говорим чтото друг другу мы порождаем образы у собеседника.
Да, только нам не надо для этого изучать миллионы изображений. И слово порождает именно образ, а не картинку. Образ это результат информационной обработки картинки, со всеми нужными ассоциациями. Он вообще может быть не визуальный, как шум моря например.
Да, только нам не надо для этого изучать миллионы изображенийСкорее всего у нас (у людей) речь идет не о миллионах, а о миллиардах изображений.
Нет. Есть люди, слепые от рождения. Но говорить они учатся примерно в одно время с обычными. Они понимают речь, отслеживают объекты, описанные в тексте, но миллиардов изображений тут нет. И миллиардов слов нет, люди не говорят слова с частотой 60 слов в секунду.
Я отвечал на фразу "Когда мы говорим что-то друг другу, мы порождаем образы у собеседника", пример про миллион изображений относится к ней, а не к статье.
Я вам больше скажу, большинство людей не могут решать задачу генерации изображений по текстовому описанию. Не так уж много людей умеют хорошо рисовать. Значит это умение для возможностей интеллекта не требуется. Потому я и говорю, что для развития ИИ пользы от этого мало.
Я написал "для развития ИИ". Пусть решает, я с этим не спорю. Только практической пользы в задачах, для решения которых хотят изобрести сильный ИИ, или пользы для собственно изобретения этого ИИ, пока не наблюдается. Это шаг в сторону. Круто, но бесполезно. Бесполезно не вообще, а для достижения изначальных целей, для которых это все затевалось.
Чтобы выкинуть человека откуда возможно. И совершенно необязательно, чтобы замена проявляла человеческий интеллект или думала как человек.
Скажем, с этой сеткой заказчик даст задание 'нарисуй кресло в виде...', просмотрит 100 сгенерированных за час (ну или сколько они создаются — вряд ли медленней чем человеком) картинок и потом отдаст самый понравившийся результат дальше.
При этом нанимать толпу художников не потребовалось.
2. Про то, сможет ли нейронка нарисовать «кресло в форме авокадо» если ей скормить 1 авокадо и 1 кресло. С чего вы решили, что 2х фотографий не будет достаточно? Зачем тысячи и сотни тысяч картинок авокадо и кресел?
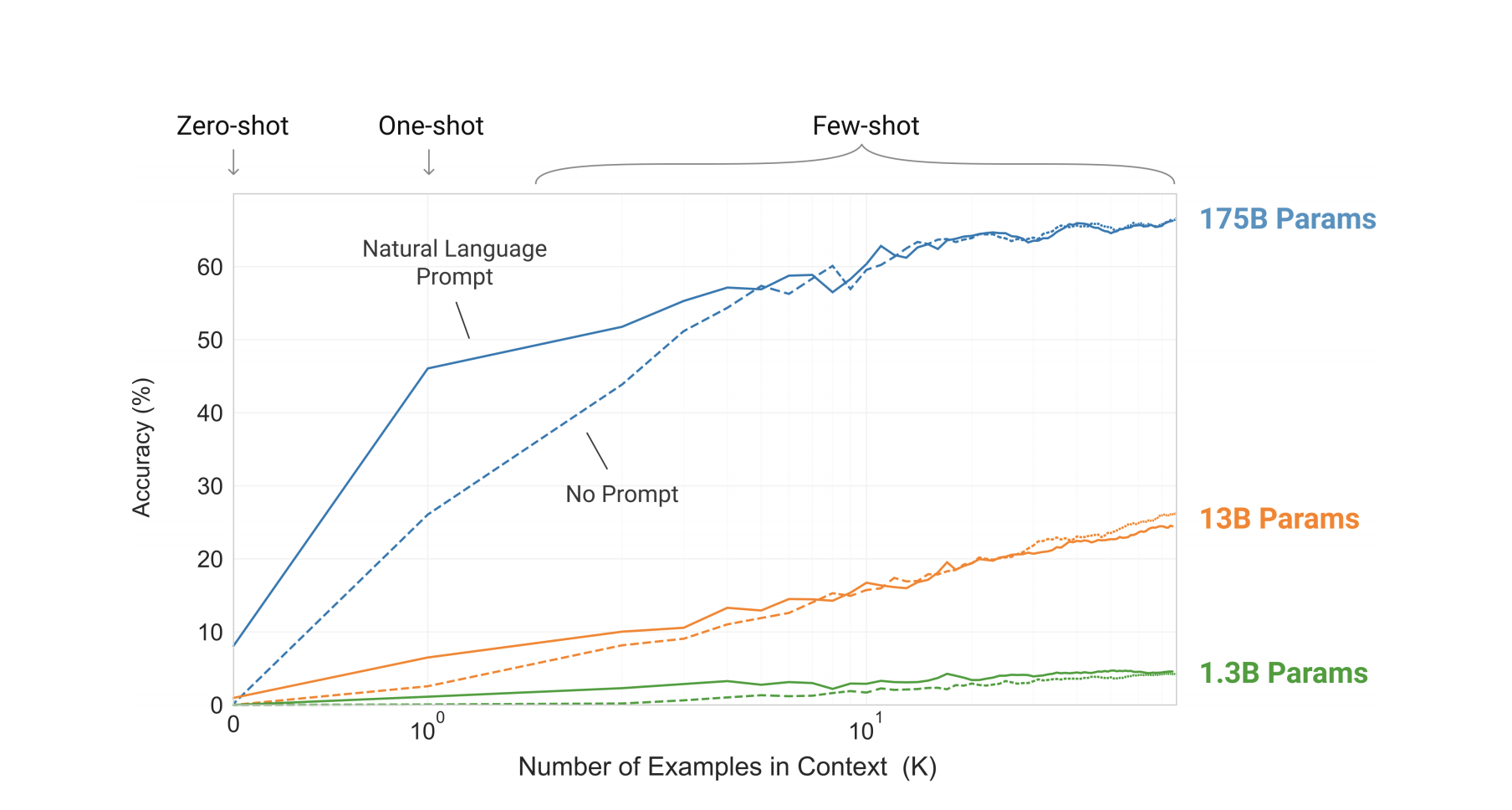 Картинка из оригинального пейпера GPT-3, ссылка на предыдущий пост про Итоги ИИ 2020. Тут как раз видно сколько нужно shot'ов (примеров) для адаптации предобученной GPT-3 для адаптации под конкретный домен. А именно GPT-3, является основой DALL · E
Картинка из оригинального пейпера GPT-3, ссылка на предыдущий пост про Итоги ИИ 2020. Тут как раз видно сколько нужно shot'ов (примеров) для адаптации предобученной GPT-3 для адаптации под конкретный домен. А именно GPT-3, является основой DALL · EПо любой из этих двух причин ваш аргумент про GPT-3 мне кажется не корректным и вторая причина объясняет необходимость «тысяч и тысяч картинок».Откуда у Вас такие сведения, у меня другая информация.

1. Почему Вы решили, что DALL · E не способен на n-shot-learning?
2. Почему GPT-3 по-Вашему может, а DALL · E нет?
3. Есть ли какие-то архитектурные ограничения DALL · E или какая-то другая причина?
Все это позволяет говорить о том, что получить качественные разнообразные результаты(хотя бы как кресло-авокадо) с one-shot техникой не получится.Но как-то получилось же. И даже без one-shot. Тут и zero-shot с головой, а с one-shot и подавно будет.
У меня возник вопрос… А Вы, случайно lpssp и michael_v89 не один и тот же человек?
Вот в комментариях к В работе сервисов Google произошёл масштабный сбой тоже вместе фигурируете.
Может и совпадение…
habr.com/ru/news/t/532968
У меня возник вопрос… А Вы, случайно lpssp и michael_v89 не один и тот же человек? Вот в комментариях тоже вместе фигурируете.
А вы всегда на личности переходите, если других аргументов нет?
Вы вот в комментариях к данной статье вместе с парой десятков других людей фигурируете. Может вы один и тот же человек? Или может вы настолько не умеете воспринимать критику, что готовы обвинять окружающих направо и налево, лишь бы не признавать, что вы оказались не правы?
michael_v89 Оказался не прав в чем? О какой критике Вы говорите? У меня такое чувство, что спор беспредметный. И не только я это подмечал, если Вы заметили. А кого я обвинял и в чем? И, кстати, про интеллект. Ваша статья Что такое интеллект? и Ваш последний комментарий к ней:
Вот если бы вы изложили критику, можно было говорить более предметно, а так получается именно болтовня с оскорблениями.Может опять совпадение…
Что при zero-shot новые градиенты не высчитываются не влияют на сеть, это и ежу понятно. Вы это пытались описать в сотне предложений…
К GPT-3 и к DALL·E может быть применим one-shot learning. Если Вы не согласны или не являетесь специалистом в этой сферы, или просто не владеете терминологией, то отличным решением будет написать еще сотню комментариев. Чем Вы, собственно, только и занимаетесь, судя по активности Вашего профиля.
Выйдет код. Вперед. Попробуйте one-shot learning. Если ничего не выйдет, то доказывайте. Пишите статьи. А не разбрасывайтесь словами и оскорблениями. С этого момента я перестаю Вам отвечать.
Оказался не прав в чем?
В споре с вашим собеседником.
О какой критике Вы говорите?
О критике ваших утверждений.
У меня такое чувство, что спор беспредметный.
А когда начинается переход на личности, обычно так и бывает. Из чего следует, что для конструктивной дискуссии переходить на личности не следует.
А кого я обвинял и в чем?
Обвиняли меня и/или lpssp в том, что я/он притворяюсь кем-то другим и пишу с двух разных аккаунтов, что не разрешается правилами данного сайта.
И, кстати, про интеллект. Ваша статья Что такое интеллект? и Ваш последний комментарий к ней:
Ну да, это мой комментарий к моей статье. Что следует из этого факта и с чем именно совпадение, я не понял, извините. Формулируйте выводы словами пожалуйста, я не умею мысли читать.
Можно прикинуть сколько визуальной информации проходит через наш мозг за жизнь.
Я же вам уже приводил пример про людей, которые не видят. У них вообще нисколько визуальной информации не проходит. Тем не менее, они понимают речь, то есть слова "порождают у них образы".
Нет, вряд ли они визуальные. А должны быть?
Ну раз вы за веткой не следите, и вам лень ее прочитать, скопирую специально для вас.
Vinchi:
Этот шаг с генерацией изображений по тексту очень важен. И в том числе для сильного ии. Когда мы говорим чтото друг другу мы порождаем образы у собеседника.
michael_v89:
Да, только нам не надо для этого изучать миллионы изображений.
Dirac:
Скорее всего у нас (у людей) речь идет не о миллионах, а о миллиардах изображений.
lpssp:
Очень сомнительное утверждение.
Dirac:
Можно прикинуть сколько визуальной информации проходит через наш мозг за жизнь.
michael_v89:
Я же вам уже приводил пример про людей, которые не видят. У них вообще нисколько визуальной информации не проходит. Тем не менее, они понимают речь, то есть слова "порождают у них образы".
Аналогия с незрячими здесь именно к тому, что для образов и понимания речи никакие миллиарды изображений не нужны.
Вроде бы 'нарисовать похоже на это (показывается картинка), чего раньше никогда не видели' — это нейросети уже раньше научились.
А тут задача была нарисовать именно по понятому тексу. Если человеческому художнику сказать 'нарисуй мне ибиса гурилого в виде кониферуса шушпанчикого' — то он тоже ничего не сделает. Потому что у него предообученного представления о ибисе и кониферусе в голове нет.
Этот шаг с генерацией изображений по тексту очень важенИ эта работа тоже, и, возможно, не просто маленький шаг, а рода технологический прорыв.
И в том числе для сильного ииЕсли использовать такую терминологию. Ну и, конечно, важно так же смотреть на жту работу в историческом контексте:
Можно сказать, что уже были все предпосылки к созданию DALL · E: прошлогодний триумф GPT-3 и успешное создание Image GPT сети, способной к генерации изображений на основе текста, использующей языковую модель трансформер GPT-2. Все уже подходило к тому, чтобы создать новую модель, взяв в этот раз за основу GPT-3.
У меня вопрос — там еще отдельная статья про clip? Про нее напишете?
Её как-то можно на домашнем компе поднять? Или в небольшом клауде за разумные деньги, очень хочется поиграться.
— Can a robot write a symphony? Can a robot turn a canvas into a beautiful masterpiece?
— Can you?
— Can a robot write a symphony? Can a robot turn a canvas into a beautiful masterpiece?
— openai.com/blog/jukebox
А, собственно, что пугает-то?
По идее, одновременно развиваются и средства распознавания вот этого вот всего. Так что просто к каждой картинке или тексту будет навешиваться 'коэффициент осмысленности и новизны — x%. Вероятность, что сделано не человеком — y%'. Другое дело, что куча творений вполне живых людей попадет под false positive — но это и к лучшему, скорее всего.
Так ее явно специально так настраивают, чтобы не с первого раза. Вполне возможно, что 'не с первого' — это как раз одна из весомых характеристик именно человека.
Не понял, что на входе, кроме текста, у нейросети?Может быть только текст, а может быть и текст и начало изображения (для его продолжения):
DALL · E — это декодер-трансформер, который принимает и текст, и изображение в виде единой последовательности токенов (1280 токенов = 256 для текста + 1024 для изображения) и далее генерирует изображения авторегрессивном режиме.Здесь нужно понимать как работают подобные трансформеры и как именно работает decoder часть encoder-decoder трансформеров. По сути вы можете интерпретировать работу DALL · E, как нейронный машинный перевод из текста в изображение. И оперировать токенами. В таком режиме (авторегрессивном) сеть способна генерировать как и новые изображения, так и заканчивать (догенеривать) уже начатые, как в примере с Гомером.
И что за 12 мрд параметров?У нейронной сети есть своя архитектура (топология) и обучаемые парамтеры, кторые тренеруются в процессе обучения нейронной сети. У DALL · E этих обучаемых параметров ~12 000 000 000.
Я ответил на Ваш вопрос?
По сути количество обучаемых параметров зависит от «нейронов», ну а если более точно, то от типа операции в слое (или даже блоке) сети, bias'ов, функции активации (e.g., prelu), и типа нормализаций при этом слое.
Правильно я понимаю?
матрица инцидентностиимеет bool значения. А тут float (если без квантизации). Тут граф (его топология) задается уже архитектурой сети. Дальше при обучении меняется матрица перехода, если мы говорим про полносвязные слои (не касается DALL · E, просо легкий для понимания пример), то матрица инцидентности буде треугольная матрицей из единиц и нулей. Веса — это матрица трансформации. Умножаете ее на вход в слой и всех делов.
2. Зависит от числового типа. Умножаем кол-во параметров ~12 000 000 000 на кол-во бит, кодируем архитектуру сети со всеми операциями. Столько и будет весить.
В общем, где я ошибался и где возникала путаница терминов.
1. Параметры. Нужно рассматривать именно как метапараметры функции (по другому веса). Вычисление нейронной сети является функцией R^n x R^wn -> R^m, где n — количество входных данных, wn — количество параметров (весов), m — количество выходных классов.
2. Сверточные сети не являются линейной функцией!, 1) сами активаторы не обязательно линейные 2) max-pool нелинейная функция
3. Из-за нелинейности Нейронные сети не являются Тензором в математическом смысле. Тензором в НН называется строгий multidimensional массив (размерность всех поддеревьев одинакова!). Основной confusion пошел из библиотеки TensorFlow. stats.stackexchange.com/questions/198061/why-the-sudden-fascination-with-tensors/198395#198395
4. Операция свертки не является Тензорной операцией свертки. Свертка в сетях пришла из алгоритмов работы с изображениями (Jpeg), а там использовалось преобразование Фурье (для лучшего сжатия картинок). www.reg.ru/blog/svyortka-v-deep-learning-prostymi-slovami
К сожалению, терминология в нейронных сетях немного отличается от физмат, что создает некоторые проблемы неокрепшим умам.
Эмодзи пингвиненка, одетого в голубую шапку, красные перчатки, зеленую футболку и желтые штаныОсталось только подписать под каждым соотвествующий дистрибутив линукса (сарказм).

А что мы увидим введя текст "nude Gal Gadot"? :)
(наверняка и разработчикам подобное приходило в голову...)
Также, сотрудники из openai выразили озадаченность тем, что уровень реалистичности и результаты работы современных генеративных моделей могут оказать сильное влияние на общество. И опасаются за возможные неоднозначные социальные и экономические последствия использования подобных технологий.Теперь этот абзац не кажется таким уж абстрактным.
Еще когда увидел iGPT, подумал, что стандартным ганам можно потихоньку присматривать стенд в музее. Теперь моя вера в это утвердилась)
Одно жаль, (OpenAI) CloseAI, как обычно, не выпустит модельку с кодом, а будет заявлять во все горло про опасность, как это было с GPT. Надеюсь, кто-то более открытый таки сможет повторить успех и позволит сообществу исследовать по факту новую область.
We recognize that work involving generative models has the potential for significant, broad societal impacts. In the future, we plan to analyze how models like DALL·E relate to societal issues like economic impact on certain work processes and professions, the potential for bias in the model outputs, and the longer term ethical challenges implied by this technology.Скорее всего в ближайшее время будет пейпер. Единственное, что я даже не представляю каких усилий будет стоить комьюнити сделать нечто подобное. Чтобы было действтительно Open.
Про Gan'ы. Да, тоже фиксирую такой тренд. Ну по сути сами Gan'ы могут остаться, как добавочный режим тренеровки. Уверен, что это просто будет рутинная возможноть получить дополнительные градиенты с дискриминатора, если это необходимо.
Применение технологии наверно пока может быть только для как игрушка или генерации тонн «годного» контента или подпитка иссякающих фонтанов идей дизайнеров. А потом оно станет частью чего более впечатляющего и важного, например когда это можно будет не только понять или услышать, но и увидеть.
«до чего дошел прогресс»
Кстати, по поводу
посмотрев описание на оригинальном сайте с большим количеством примеров по которым видно закономерности (посмотрите на подсказки в виде фона), добавилось понимание, как это устроеноТак и есть! Зная архитектуру GPT-3 и VQVAE и то, что я писал выше:
Здесь нужно понимать как работают подобные трансформеры и как именно работает decoder часть encoder-decoder трансформеров. По сути вы можете интерпретировать работу DALL · E, как нейронный машинный перевод из текста в изображение. И оперировать токенами. В таком режиме (авторегрессивном) сеть способна генерировать как и новые изображения, так и заканчивать (догенеривать) уже начатые, как в примере с Гомером.Напрашивается и сама реализация. Как Вы сказали:
добавилось понимание, как это устроеноНо пока еще множество неочевидных технических нюансов и догадок. Так что подождем пейпера. Сделаем и обсудим технический обзор!
DALL·E от OpenAI: Генерация изображений из текста. Один из важнейших прорывов ИИ в начале 2021 года