Про нейронные сети, как один из инструментов решения трудноформализуемых задач уже было сказано достаточно много. И здесь, на хабре, было показано, как эти сети применять для распознавания изображений, применительно к задаче взлома капчи. Однако, типов нейросетей существует довольно много. И так ли хороша классическая полносвязная нейронная сеть (ПНС) для задачи распознавания (классификации) изображений?
Итак, мы собрались решать задачу распознавания изображений. Это может быть распознавание лиц, объектов, символов и т.д. Я предлагаю для начала рассмотреть задачу распознавания рукописных цифр. Задача эта хороша по ряду причин:
В качестве входных данных предлагается использовать базу данных MNIST. Эта база содержит 60 000 обучающих пар (изображение — метка) и 10 000 тестовых (изображения без меток). Изображения нормализованы по размеру и отцентрованы. Размер каждой цифры не более 20х20, но вписаны они в квадрат размером 28х28. Пример первых 12 цифр из обучающего набора базы MNIST приведен на рисунке:

Таким образом задача формулируется следующим образом: создать и обучить нейросеть распознаванию рукописных символов, принимая их изображения на входе и активируя один из 10 выходов. Под активацией будем понимать значение 1 на выходе. Значения остальных выходов при этом должны (в идеале) быть равны -1. Почему при этом не используется шкала [0,1] я объясню позже.
Большинство людей под «обычными» или «классическими» нейросетями понимает полносвязные нейронные сети прямого распространения с обратным распространением ошибки:

Как следует из названия в такой сети каждый нейрон связан с каждым, сигнал идет только в направлении от входного слоя к выходному, нет никаких рекурсий. Будем называть такую сеть сокращенно ПНС.
Сперва необходимо решить как подавать данные на вход. Самое простое и почти безальтернативное решение для ПНС — это выразить двумерную матрицу изображения в виде одномерного вектора. Т.е. для изображения рукописной цифры размером 28х28 у нас будет 784 входа, что уже не мало. Дальше происходит то, за что нейросетевиков и их методы многие консервативные ученые не любят — выбор архитектуры. А не любят, поскольку выбор архитектуры это чистое шаманство. До сих пор не существует методов, позволяющих однозначно определить структуру и состав нейросети исходя из описания задачи. В защиту скажу, что для трудноформализуемых задач вряд ли когда-либо такой метод будет создан. Кроме того существует множество различных методик редукции сети (например OBD [1]), а также разные эвристики и эмпирические правила. Одно из таких правил гласит, что количество нейронов в скрытом слое должно быть хотя бы на порядок больше количества входов. Если принять во внимание что само по себе преобразование из изображения в индикатор класса довольно сложное и существенно нелинейное, одним слоем тут не обойтись. Исходя из всего вышесказанного грубо прикидываем, что количество нейронов в скрытых слоях у нас будет порядка 15000 (10 000 во 2-м слое и 5000 в третьем). При этом для конфигурации с двумя скрытыми слоями количество настраиваемых и обучаемых связей будет 10 млн. между входами и первым скрытым слоем + 50 млн. между первым и вторым + 50 тыс. между вторым и выходным, если считать что у нас 10 выходов, каждый из которых обозначает цифру от 0 до 9. Итого грубо 60 000 000 связей. Я не зря упомянул, что они настраиваемые — это значит, что при обучении для каждой из них нужно будет вычислять градиент ошибки.
Ну это ладно, что уж тут поделаешь,красота искусственный интеллект требует жертв. Но вот если задуматься, на ум приходит, что когда мы преобразуем изображение в линейную цепочку байт, мы что-то безвозвратно теряем. Причем с каждым слоем эта потеря только усугубляется. Так и есть — мы теряем топологию изображения, т.е. взаимосвязь между отдельными его частями. Кроме того задача распозравания подразумевает умение нейросети быть устойчивой к небольшим сдвигам, поворотам и изменению масштаба изображения, т.е. она должна извлекать из данных некие инварианты, не зависящие от почерка того или иного человека. Так какой же должна быть нейросеть, чтобы быть не очень вычислительно сложной и, в тоже время, более инвариантной к различным искажениям изображений?
Решение этой проблемы было найдено американским ученым французского происхождения Яном ЛеКуном, вдохновленным работами нобелевских лауреатов в области медицины Torsten Nils Wiesel и David H. Hubel. Эти ученые исследовали зрительную кору головного мозга кошки и обнаружили, что существуют так называемые простые клетки, которые особо сильно реагируют на прямые линии под разными углами и сложные клетки, которые реагирую на движение линий в одном направлении. Ян ЛеКун предложил использовать так называемые сверточные нейронные сети [2].
Идея сверточных нейронных сетей заключается в чередовании сверточных слоев (C-layers), субдискретизирующих слоев (S-layers) и наличии полносвязных (F-layers) слоев на выходе.
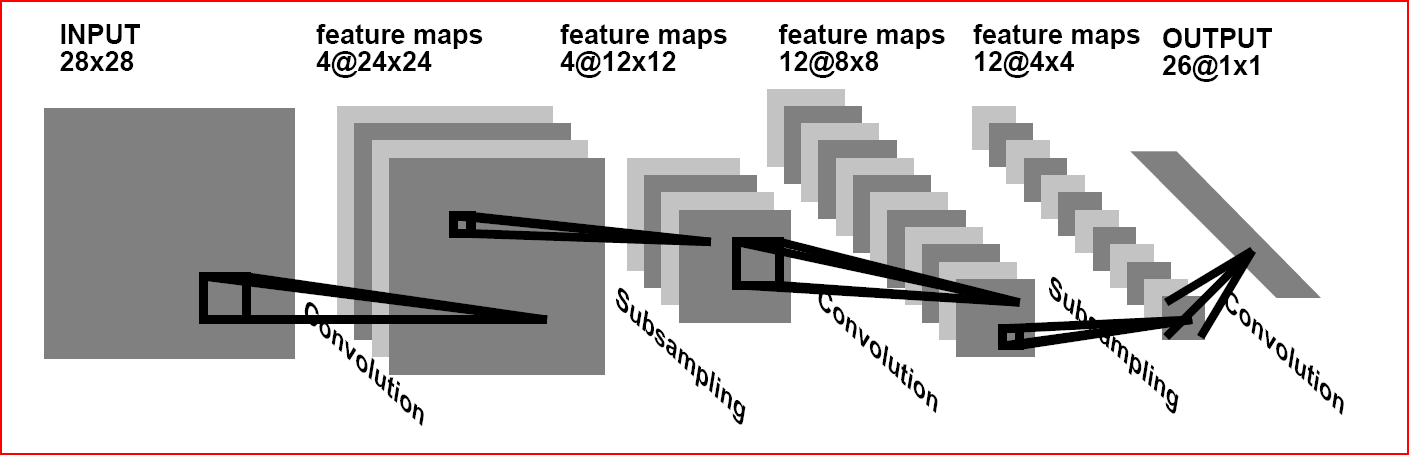
Такая архитектура заключает в себе 3 основных парадигмы:
Локальное восприятие подразумевает, что на вход одного нейрона подается не все изображение (или выходы предыдущего слоя), а лишь некоторая его область. Такой подход позволил сохранять топологию изображения от слоя к слою.
Концепция разделяемых весов предполагает, что для большого количества связей используется очень небольшой набор весов. Т.е. если у нас имеется на входе изображение размерами 32х32 пикселя, то каждый из нейронов следующего слоя примет на вход только небольшой участок этого изображения размером, к примеру, 5х5, причем каждый из фрагментов будет обработан одним и тем же набором. Важно понимать, что самих наборов весов может быть много, но каждый из них будет применен ко всему изображению. Такие наборы часто называют ядрами (kernels). Нетрудно посчитать, что даже для 10 ядер размером 5х5 для входного изображения размерами 32х32 количество связей окажется равным примерно 256000 (сравниваем с 10 млн.), а количество настраиваемых параметров всего 250!
А как же, спросите вы, это скажется на качестве распознавания? Как ни странно, в лучшую сторону. Дело в том, что такое искусственно введенное ограничение на веса улучшает обобщающие свойства сети (generalization), что в итоге позитивно сказывается на способности сети находить инварианты в изображении и реагировать главным образом на них, не обращая внимания на прочий шум. Можно посмотреть на этот подход немного с другой стороны. Те, кто занимался классикой распознавания изображений и знает как это работает на практике (например в военной технике) знают, что большинство таких систем строятся на основе двумерных фильтров. Фильтр представляет собой матрицу коэффициентов, обычно заданную вручную. Эта матрица применяется к изображению с помощью математической операции, называемой сверткой. Суть этой операции в том, что каждый фрагмент изображения умножается на матрицу (ядро) свертки поэлементно и результат суммируется и записывается в аналогичную позицию выходного изображения. Основное свойство таких фильтров заключается в том, что значение их выхода тем больше чем больше фрагмент изображения похож на сам фильтр. Таким образом изображение свернутое с неким ядром даст нам другое изображение, каждый пиксел которого будет означать степень похожести фрагмента изображения на фильтр. Иными словами это будет карта признаков.
Процесс распространения сигнала в C-слое я попытался изобразить на рисунке:
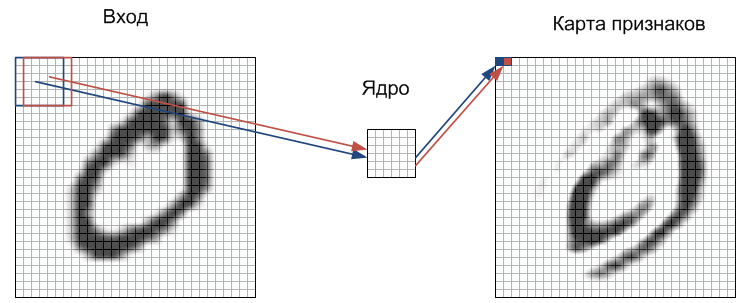
Каждый фрагмент изображения поэлементно умножается на небольшую матрицу весов (ядро), результат суммируется. Эта сумма является пикселом выходного изображения, которое называется картой признаков. Здесь я опустил тот факт, что взвешенная сумма входов еще пропускается через функцию активации (как в любой другой нейросети). На самом деле это может происходить и в S-слое, принципиальной разницы нет. Следует сказать, что в идеале не разные фрагменты проходят последовательно через ядро, а параллельно все изображение проходит через идентичные ядра. Кроме того, количество ядер (наборов весов) определяется разработчиком и зависит от того какое количество признаков необходимо выделить. Еще одна особенность сверточного слоя в том, что он немного уменьшает изображение за счет краевых эффектов.
Суть субдискретизации и S-слоев заключается в уменьшении пространственной размерности изображения. Т.е. входное изображение грубо (усреднением) уменьшается в заданное количество раз. Чаще всего в 2 раза, хотя может быть и не равномерное изменение, например, 2 по вертикали и 3 по горизонтали. Субдискретизация нужна для обеспечения инвариантности к масштабу.
Чередование слоев позволяет составлять карты признаков из карт признаков, что на практике означает способность распознавания сложных иерархий признаков.
Обычно после прохождения нескольких слоев карта признаков вырождается в вектор или даже скаляр, но таких карт признаков становится сотни. В таком виде они подаются на один-два слоя полносвязной сети. Выходной слой такой сети может иметь различные функции активации. В простейшем случае это может быть тангенциальная функция, также успешно используются радиальные базисные функции.
Для того чтобы можно было начать обучение нашей сети нужно определиться с тем, как измерять качество распознавания. В нашем случае для этого будем использовать самую распространенную в теории нейронных сетей функцию среднеквадратической ошибки (СКО, MSE) [3]:
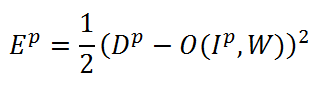
В этой формуле Ep — это ошибка распознавания для p-ой обучающей пары, Dp — желаемый выход сети, O(Ip,W) — выход сети, зависящий от p-го входа и весовых коэффициентов W, куда входят ядра свертки, смещения, весовые коэффициенты S- и F- слоев. Задача обучения так настроить веса W, чтобы они для любой обучающей пары (Ip,Dp) давали минимальную ошибку Ep. Чтобы посчитать ошибку для всей обучающей выборки просто берется среднее арифметическое по ошибкам для всех обучающих пар. Такую усредненную ошибку обозначим как E.
Для минимизации функции ошибки Ep самыми эффективными являются градиентные методы. Рассмотрим суть градиентных методов на примере простейшего одномерного случая (т.е. когда у нас всего один вес). Если мы разложим в ряд Тейлора функцию ошибки Ep, то получим следующее выражение:
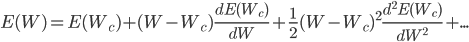
Здесь E — все та же функция ошибки, Wc — некоторое начальное значение веса. Из школьной математики мы помним, что для нахождения экстремума функции необходимо взять ее производную и приравнять нулю. Так и поступим, возьмем производную функции ошибки по весам, отбросив члены выше 2го порядка:
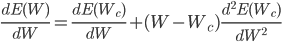
из этого выражения следует, что вес, при котором значение функции ошибки будет минимальным можно вычислить из следующего выражения:
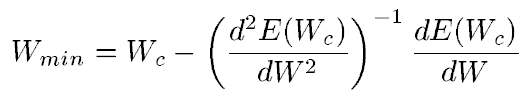
Т.е. оптимальный вес вычисляется как текущий минус производная функции ошибки по весу, деленная на вторую производную функции ошибки. Для многомерного случая (т.е. для матрицы весов) все точно также, только первая производная превращается в градиент (вектор частных производных), а вторая производная превращается в Гессиан (матрицу вторых частных производных). И здесь возможно два варианта. Если мы опустим вторую производную, то получим алгоритм наискорейшего градиентного спуска. Если все же захотим учитывать вторую производную, то обалдеем от того сколько вычислительных ресурсов нам потребуется, чтобы посчитать полный Гессиан, а потом еще и обратить его. Поэтому обычно Гессиан заменяют чем-то более простым. Например, один из самых известных и успешных методов — метод Левенберга-Марквардта (ЛМ) заменяет Гессиан, его аппроксимацией с помощью квадрадного Якобиана. Подробности здесь рассказывать не буду.
Но что нам важно знать об этих двух методах, так это то, что алгоритм ЛМ требует обработки всей обучающей выборки, тогда как алгоритм градиентного спуска может работать с каждой отдельно взятой обучающей выборкой. В последнем случае алгоритм называют стохастическим градиентом. Учитывая, что наша база содержит 60 000 обучающих образцов нам больше подходит стохастический градиент. Еще одним преимуществом стохастического градиента является его меньшая подверженность попаданию в локальный минимум по сравнению с ЛМ.
Существует также стохастическая модификация алгоритма ЛМ, о которой я, возможно, упомяну позже.
Представленные формулы позволяют легко вычислить производную ошибки по весам, находящимся в выходном слое. Вычислить ошибку в скрытых слоях позволяет широко известный в ИИ метод обратного распространения ошибки.
Лично я использую для реализации различных алгоритмов, от которых не требуется функционирование в реальном времени Matlab. Это очень удобный пакет, M-язык которого позволяет сосредоточиться на самом алгоритме не заботясь о выделении памяти, операциях в/в и т.д. Кроме того, множество различных тулбоксов позволяет создавать поистине междисциплинарные приложения в кротчайшие сроки. Можно, например, с помощью Image Acquisition Toolbox подключить вебкамеру, с помощью Image Processing Toolbox обрабатывать изображение с нее, с помощью Neural Network Toolbox формировать траекторию движения робота, а с помощью Virtual Reality Toolbox и Control Systems Toolbox моделировать движение робота. Кстати о Neural Network Toolbox — это довольно гибкий набор инструментов, позволяющий создавать множество нейронных сетей различных типов и архитектур, но, к сожалению, не сверточные НС. Все дело в разделяемых весах. В NN toolbox возможность задавать разделяемые веса отсутствует.
Чтобы устранить этот недостаток мною был написан класс, позволяющий реализовать СНС произвольной архитектуры и применять их к различным задачам. Скачать класс можно здесь. Сам класс был написан так, чтобы тому, кто им пользуется была максимальная видна структура сети. Все очень обильно прокомментировано, на названии переменных не экономил. Скорость симуляции сети неплоха и составляет доли секунды. Скорость обучения пока не велика (>10 ч), но следите за обновлениями, в ближайшее время планируется ускорение на порядки.
Кого интересует реализация СНС на С++, могут найти ее здесь и здесь.
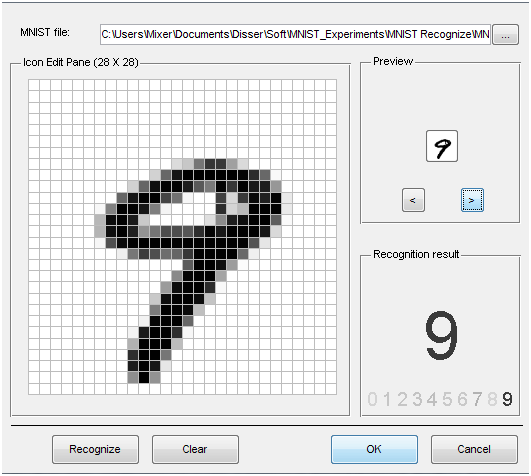
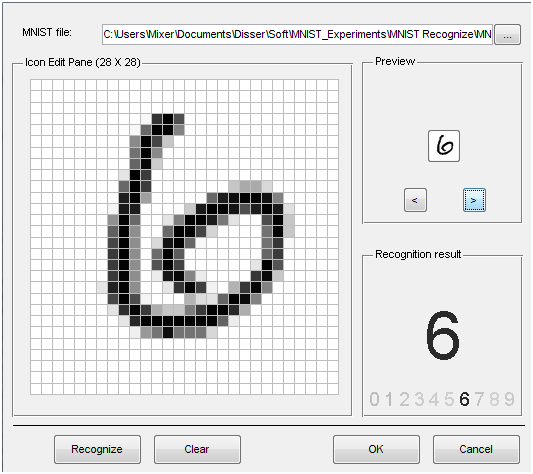
В программе на matlabcentral прилагается файл уже натренированной нейросети, а также GUI для демонстрации результатов работы. Ниже приведены примеры распознавания:
По ссылке имеется таблица сравнения методов распознавания на базе MNIST. Первое место за сверточными нейросетями с результатом 0.39% ошибок распознавания [4]. Большинство из этих ошибочно распознанных изображений не каждый человек правильно распознает. Кроме того в работе [4] были использованы эластические искажения входных изображений, а также предварительное обучение без учителя. Но об этих методах как нибудь в другой статье.
P.S. Всем спасибо за комментарии и за отзывы. Это моя первая статья на хабре, так что буду рад видеть предложения, замечания, дополнения.
1. Задача
Итак, мы собрались решать задачу распознавания изображений. Это может быть распознавание лиц, объектов, символов и т.д. Я предлагаю для начала рассмотреть задачу распознавания рукописных цифр. Задача эта хороша по ряду причин:
- Для распознавания рукописного символа довольно трудно составить формализованный (не интеллектуальный) алгоритм и это становится понятно, стоит только взглянуть на одну и туже цифру написанную разными людьми
- Задача довольно актуальна и имеет отношение к OCR (optical character recognition)
- Существует свободно распространяемая база рукописных символов, доступная для скачивания и экспериментов
- Существует довольно много статей на эту тему и можно очень легко и удобно сравнить различные подходы
В качестве входных данных предлагается использовать базу данных MNIST. Эта база содержит 60 000 обучающих пар (изображение — метка) и 10 000 тестовых (изображения без меток). Изображения нормализованы по размеру и отцентрованы. Размер каждой цифры не более 20х20, но вписаны они в квадрат размером 28х28. Пример первых 12 цифр из обучающего набора базы MNIST приведен на рисунке:
Таким образом задача формулируется следующим образом: создать и обучить нейросеть распознаванию рукописных символов, принимая их изображения на входе и активируя один из 10 выходов. Под активацией будем понимать значение 1 на выходе. Значения остальных выходов при этом должны (в идеале) быть равны -1. Почему при этом не используется шкала [0,1] я объясню позже.
2. «Обычные» нейросети.
Большинство людей под «обычными» или «классическими» нейросетями понимает полносвязные нейронные сети прямого распространения с обратным распространением ошибки:
Как следует из названия в такой сети каждый нейрон связан с каждым, сигнал идет только в направлении от входного слоя к выходному, нет никаких рекурсий. Будем называть такую сеть сокращенно ПНС.
Сперва необходимо решить как подавать данные на вход. Самое простое и почти безальтернативное решение для ПНС — это выразить двумерную матрицу изображения в виде одномерного вектора. Т.е. для изображения рукописной цифры размером 28х28 у нас будет 784 входа, что уже не мало. Дальше происходит то, за что нейросетевиков и их методы многие консервативные ученые не любят — выбор архитектуры. А не любят, поскольку выбор архитектуры это чистое шаманство. До сих пор не существует методов, позволяющих однозначно определить структуру и состав нейросети исходя из описания задачи. В защиту скажу, что для трудноформализуемых задач вряд ли когда-либо такой метод будет создан. Кроме того существует множество различных методик редукции сети (например OBD [1]), а также разные эвристики и эмпирические правила. Одно из таких правил гласит, что количество нейронов в скрытом слое должно быть хотя бы на порядок больше количества входов. Если принять во внимание что само по себе преобразование из изображения в индикатор класса довольно сложное и существенно нелинейное, одним слоем тут не обойтись. Исходя из всего вышесказанного грубо прикидываем, что количество нейронов в скрытых слоях у нас будет порядка 15000 (10 000 во 2-м слое и 5000 в третьем). При этом для конфигурации с двумя скрытыми слоями количество настраиваемых и обучаемых связей будет 10 млн. между входами и первым скрытым слоем + 50 млн. между первым и вторым + 50 тыс. между вторым и выходным, если считать что у нас 10 выходов, каждый из которых обозначает цифру от 0 до 9. Итого грубо 60 000 000 связей. Я не зря упомянул, что они настраиваемые — это значит, что при обучении для каждой из них нужно будет вычислять градиент ошибки.
Ну это ладно, что уж тут поделаешь,
3. Сверточные нейронные сети
Решение этой проблемы было найдено американским ученым французского происхождения Яном ЛеКуном, вдохновленным работами нобелевских лауреатов в области медицины Torsten Nils Wiesel и David H. Hubel. Эти ученые исследовали зрительную кору головного мозга кошки и обнаружили, что существуют так называемые простые клетки, которые особо сильно реагируют на прямые линии под разными углами и сложные клетки, которые реагирую на движение линий в одном направлении. Ян ЛеКун предложил использовать так называемые сверточные нейронные сети [2].
Идея сверточных нейронных сетей заключается в чередовании сверточных слоев (C-layers), субдискретизирующих слоев (S-layers) и наличии полносвязных (F-layers) слоев на выходе.
Такая архитектура заключает в себе 3 основных парадигмы:
- Локальное восприятие.
- Разделяемые веса.
- Субдискретизация.
Локальное восприятие подразумевает, что на вход одного нейрона подается не все изображение (или выходы предыдущего слоя), а лишь некоторая его область. Такой подход позволил сохранять топологию изображения от слоя к слою.
Концепция разделяемых весов предполагает, что для большого количества связей используется очень небольшой набор весов. Т.е. если у нас имеется на входе изображение размерами 32х32 пикселя, то каждый из нейронов следующего слоя примет на вход только небольшой участок этого изображения размером, к примеру, 5х5, причем каждый из фрагментов будет обработан одним и тем же набором. Важно понимать, что самих наборов весов может быть много, но каждый из них будет применен ко всему изображению. Такие наборы часто называют ядрами (kernels). Нетрудно посчитать, что даже для 10 ядер размером 5х5 для входного изображения размерами 32х32 количество связей окажется равным примерно 256000 (сравниваем с 10 млн.), а количество настраиваемых параметров всего 250!
А как же, спросите вы, это скажется на качестве распознавания? Как ни странно, в лучшую сторону. Дело в том, что такое искусственно введенное ограничение на веса улучшает обобщающие свойства сети (generalization), что в итоге позитивно сказывается на способности сети находить инварианты в изображении и реагировать главным образом на них, не обращая внимания на прочий шум. Можно посмотреть на этот подход немного с другой стороны. Те, кто занимался классикой распознавания изображений и знает как это работает на практике (например в военной технике) знают, что большинство таких систем строятся на основе двумерных фильтров. Фильтр представляет собой матрицу коэффициентов, обычно заданную вручную. Эта матрица применяется к изображению с помощью математической операции, называемой сверткой. Суть этой операции в том, что каждый фрагмент изображения умножается на матрицу (ядро) свертки поэлементно и результат суммируется и записывается в аналогичную позицию выходного изображения. Основное свойство таких фильтров заключается в том, что значение их выхода тем больше чем больше фрагмент изображения похож на сам фильтр. Таким образом изображение свернутое с неким ядром даст нам другое изображение, каждый пиксел которого будет означать степень похожести фрагмента изображения на фильтр. Иными словами это будет карта признаков.
Процесс распространения сигнала в C-слое я попытался изобразить на рисунке:
Каждый фрагмент изображения поэлементно умножается на небольшую матрицу весов (ядро), результат суммируется. Эта сумма является пикселом выходного изображения, которое называется картой признаков. Здесь я опустил тот факт, что взвешенная сумма входов еще пропускается через функцию активации (как в любой другой нейросети). На самом деле это может происходить и в S-слое, принципиальной разницы нет. Следует сказать, что в идеале не разные фрагменты проходят последовательно через ядро, а параллельно все изображение проходит через идентичные ядра. Кроме того, количество ядер (наборов весов) определяется разработчиком и зависит от того какое количество признаков необходимо выделить. Еще одна особенность сверточного слоя в том, что он немного уменьшает изображение за счет краевых эффектов.
Суть субдискретизации и S-слоев заключается в уменьшении пространственной размерности изображения. Т.е. входное изображение грубо (усреднением) уменьшается в заданное количество раз. Чаще всего в 2 раза, хотя может быть и не равномерное изменение, например, 2 по вертикали и 3 по горизонтали. Субдискретизация нужна для обеспечения инвариантности к масштабу.
Чередование слоев позволяет составлять карты признаков из карт признаков, что на практике означает способность распознавания сложных иерархий признаков.
Обычно после прохождения нескольких слоев карта признаков вырождается в вектор или даже скаляр, но таких карт признаков становится сотни. В таком виде они подаются на один-два слоя полносвязной сети. Выходной слой такой сети может иметь различные функции активации. В простейшем случае это может быть тангенциальная функция, также успешно используются радиальные базисные функции.
4. Обучение
Для того чтобы можно было начать обучение нашей сети нужно определиться с тем, как измерять качество распознавания. В нашем случае для этого будем использовать самую распространенную в теории нейронных сетей функцию среднеквадратической ошибки (СКО, MSE) [3]:
В этой формуле Ep — это ошибка распознавания для p-ой обучающей пары, Dp — желаемый выход сети, O(Ip,W) — выход сети, зависящий от p-го входа и весовых коэффициентов W, куда входят ядра свертки, смещения, весовые коэффициенты S- и F- слоев. Задача обучения так настроить веса W, чтобы они для любой обучающей пары (Ip,Dp) давали минимальную ошибку Ep. Чтобы посчитать ошибку для всей обучающей выборки просто берется среднее арифметическое по ошибкам для всех обучающих пар. Такую усредненную ошибку обозначим как E.
Для минимизации функции ошибки Ep самыми эффективными являются градиентные методы. Рассмотрим суть градиентных методов на примере простейшего одномерного случая (т.е. когда у нас всего один вес). Если мы разложим в ряд Тейлора функцию ошибки Ep, то получим следующее выражение:
Здесь E — все та же функция ошибки, Wc — некоторое начальное значение веса. Из школьной математики мы помним, что для нахождения экстремума функции необходимо взять ее производную и приравнять нулю. Так и поступим, возьмем производную функции ошибки по весам, отбросив члены выше 2го порядка:
из этого выражения следует, что вес, при котором значение функции ошибки будет минимальным можно вычислить из следующего выражения:
Т.е. оптимальный вес вычисляется как текущий минус производная функции ошибки по весу, деленная на вторую производную функции ошибки. Для многомерного случая (т.е. для матрицы весов) все точно также, только первая производная превращается в градиент (вектор частных производных), а вторая производная превращается в Гессиан (матрицу вторых частных производных). И здесь возможно два варианта. Если мы опустим вторую производную, то получим алгоритм наискорейшего градиентного спуска. Если все же захотим учитывать вторую производную, то обалдеем от того сколько вычислительных ресурсов нам потребуется, чтобы посчитать полный Гессиан, а потом еще и обратить его. Поэтому обычно Гессиан заменяют чем-то более простым. Например, один из самых известных и успешных методов — метод Левенберга-Марквардта (ЛМ) заменяет Гессиан, его аппроксимацией с помощью квадрадного Якобиана. Подробности здесь рассказывать не буду.
Но что нам важно знать об этих двух методах, так это то, что алгоритм ЛМ требует обработки всей обучающей выборки, тогда как алгоритм градиентного спуска может работать с каждой отдельно взятой обучающей выборкой. В последнем случае алгоритм называют стохастическим градиентом. Учитывая, что наша база содержит 60 000 обучающих образцов нам больше подходит стохастический градиент. Еще одним преимуществом стохастического градиента является его меньшая подверженность попаданию в локальный минимум по сравнению с ЛМ.
Существует также стохастическая модификация алгоритма ЛМ, о которой я, возможно, упомяну позже.
Представленные формулы позволяют легко вычислить производную ошибки по весам, находящимся в выходном слое. Вычислить ошибку в скрытых слоях позволяет широко известный в ИИ метод обратного распространения ошибки.
5. Реализация
Лично я использую для реализации различных алгоритмов, от которых не требуется функционирование в реальном времени Matlab. Это очень удобный пакет, M-язык которого позволяет сосредоточиться на самом алгоритме не заботясь о выделении памяти, операциях в/в и т.д. Кроме того, множество различных тулбоксов позволяет создавать поистине междисциплинарные приложения в кротчайшие сроки. Можно, например, с помощью Image Acquisition Toolbox подключить вебкамеру, с помощью Image Processing Toolbox обрабатывать изображение с нее, с помощью Neural Network Toolbox формировать траекторию движения робота, а с помощью Virtual Reality Toolbox и Control Systems Toolbox моделировать движение робота. Кстати о Neural Network Toolbox — это довольно гибкий набор инструментов, позволяющий создавать множество нейронных сетей различных типов и архитектур, но, к сожалению, не сверточные НС. Все дело в разделяемых весах. В NN toolbox возможность задавать разделяемые веса отсутствует.
Чтобы устранить этот недостаток мною был написан класс, позволяющий реализовать СНС произвольной архитектуры и применять их к различным задачам. Скачать класс можно здесь. Сам класс был написан так, чтобы тому, кто им пользуется была максимальная видна структура сети. Все очень обильно прокомментировано, на названии переменных не экономил. Скорость симуляции сети неплоха и составляет доли секунды. Скорость обучения пока не велика (>10 ч), но следите за обновлениями, в ближайшее время планируется ускорение на порядки.
Кого интересует реализация СНС на С++, могут найти ее здесь и здесь.
6. Результаты
В программе на matlabcentral прилагается файл уже натренированной нейросети, а также GUI для демонстрации результатов работы. Ниже приведены примеры распознавания:
По ссылке имеется таблица сравнения методов распознавания на базе MNIST. Первое место за сверточными нейросетями с результатом 0.39% ошибок распознавания [4]. Большинство из этих ошибочно распознанных изображений не каждый человек правильно распознает. Кроме того в работе [4] были использованы эластические искажения входных изображений, а также предварительное обучение без учителя. Но об этих методах как нибудь в другой статье.
Ссылки.
- Yann LeCun, J. S. Denker, S. Solla, R. E. Howard and L. D. Jackel: Optimal Brain Damage, in Touretzky, David (Eds), Advances in Neural Information Processing Systems 2 (NIPS*89), Morgan Kaufman, Denver, CO, 1990
- Y. LeCun and Y. Bengio: Convolutional Networks for Images, Speech, and Time-Series, in Arbib, M. A. (Eds), The Handbook of Brain Theory and Neural Networks, MIT Press, 1995
- Y. LeCun, L. Bottou, G. Orr and K. Muller: Efficient BackProp, in Orr, G. and Muller K. (Eds), Neural Networks: Tricks of the trade, Springer, 1998
- Ranzato Marc'Aurelio, Christopher Poultney, Sumit Chopra and Yann LeCun: Efficient Learning of Sparse Representations with an Energy-Based Model, in J. Platt et al. (Eds), Advances in Neural Information Processing Systems (NIPS 2006), MIT Press, 2006
P.S. Всем спасибо за комментарии и за отзывы. Это моя первая статья на хабре, так что буду рад видеть предложения, замечания, дополнения.
