Comments 204
Все то же самое применимо к многоядерности. Да и софт в основном не готов использовать множество ядер, поэтому «быстрее» становится, к сожалению, для весьма малого класса задач
ага. программистам приходится заниматься «прыжками в ширину»
Современные ОС по определению исполняют все программы в параллели, им разнести софт по разным ядрам не проблема. Каждой программе по ядру! Почему бы и нет… :)
Это милое мнение с хабра. «Им разнести софт по разным ядрам не проблема».
А вот в linux'е так не думают, и процесс переноса процесса с ядра на ядро вызывает массу возражений из-за засирания кешей и снижения производительности.
А так да, никаких проблем нет. Welcome multicore.
А вот в linux'е так не думают, и процесс переноса процесса с ядра на ядро вызывает массу возражений из-за засирания кешей и снижения производительности.
А так да, никаких проблем нет. Welcome multicore.
да тут вопрос более фундаментальный, чем технические сложности — в том, что не все алгоритмы можно распараллелелить — опять же аналогия со строителями — нельзя построить следующий этаж, не построив предыдущий — чтобы вычислить следующий член последовательности Фибоначчи — надо знать предыдущий, вот матрицы например перемножить в параллель — это запросто — поэтому видеокарты имеют дофигища ядер — перемножение матриц — одна из основных операций в видеообработке
Немного позанудствую, но для вычисления чисел Фибоначчи существует рекурсивный алгоритм, а он в принципе распараллеливается: даже для малого значения n рекурсивными вызовами порождается очень большое число параллельных процессов.
чего — рекурсивный алгоритм распараллеливается? то есть я правильно понимаю, что
int fib(int n)
{
if (n <= 2) return 1;
else
{
return fib(n — 1) + fib(n — 2);
}
}
по вашему быстро отработает? это по сути дерево — то есть каждая функция должна ждать пока вычислятся вызванные ей функции — где тут параллельность? — сложность алгоритма ЭКСПОНЕНЦИАЛЬНАЯ. вот матрицы перемножить — взяли строку, умножили на столбец и сложили — никто никого ждать не должен
int fib(int n)
{
if (n <= 2) return 1;
else
{
return fib(n — 1) + fib(n — 2);
}
}
по вашему быстро отработает? это по сути дерево — то есть каждая функция должна ждать пока вычислятся вызванные ей функции — где тут параллельность? — сложность алгоритма ЭКСПОНЕНЦИАЛЬНАЯ. вот матрицы перемножить — взяли строку, умножили на столбец и сложили — никто никого ждать не должен
Про скорость никто не говорил, я говорил, что существует возможность распараллелить. Ведь этот алгоритм так и называется: параллельная рекурсия. Отправляете fib(n — 1) на одно ядро, fib(n — 2) на другое — вот и все. И на каждом шаге так. Да, ядра заканчиваются, но на теоретическую возможность распараллеливания это никак не влияет (use-case — тестирование возможностей систем параллельных вычислений). А если вы хотите скорости, то если использовать формулу Бине, то вообще не нужно знать ничего, кроме номера числа в последовательности.
так все равно — ядра то простаивают, пока ждут числа от других ядер
Если не нравится рекурсивный пример, а нравятся матрицы, то тогда вычисление чисел Фибоначчи можно распараллелить, воспользовавшись следующим тождеством:
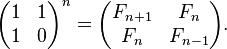
хорошо конечно, что посмотрели таки википедию, но также посмотрите, что на основе этого свойства — операция сводится все равно к последовательному вычислению то есть каждое новое число получается на основе числа, вычисленного в предыдущем шаге:
//возвращает n-е число Фибоначчи
int fib(int n)
{
int a = 1, ta,
b = 1, tb,
c = 1, rc = 0, tc,
d = 0, rd = 1;
while (n)
{
if (n & 1) // Если степень нечетная
{
// Умножаем вектор R на матрицу A
tc = rc;
rc = rc*a + rd*c;
rd = tc*b + rd*d;
}
// Умножаем матрицу A на саму себя
ta = a; tb = b; tc = c;
a = a*a + b*c;
b = ta*b + b*d;
c = c*ta + d*c;
d = tc*tb+ d*d;
n >>= 1; // Уменьшаем степень вдвое
}
return rc;
}
//возвращает n-е число Фибоначчи
int fib(int n)
{
int a = 1, ta,
b = 1, tb,
c = 1, rc = 0, tc,
d = 0, rd = 1;
while (n)
{
if (n & 1) // Если степень нечетная
{
// Умножаем вектор R на матрицу A
tc = rc;
rc = rc*a + rd*c;
rd = tc*b + rd*d;
}
// Умножаем матрицу A на саму себя
ta = a; tb = b; tc = c;
a = a*a + b*c;
b = ta*b + b*d;
c = c*ta + d*c;
d = tc*tb+ d*d;
n >>= 1; // Уменьшаем степень вдвое
}
return rc;
}
Хочу заметить, что мы можем сложить другую матрицу, с количеством строк и ячеек порядка N, которая за одно умножение себя будет давать переход из fib(a) -> fib(a+N). А после юзать какое-нибудь распараллеленное умножение матрицы на матрицу. Т.е. по сути нам нужно будет умножить не logN матриц, а log(N/c), но при этом потеряем на умножении матриц, что чисто теоретически мы можем покрыть большим количеством воркеров. Это вообще даже не примерные прикидки, там нужно считать, выгороит ли это или нет. Но это и вправду чисто гипотетические прикидки. Закон Амдала он суров, да.
Если мы будем использовать матрицу размера K, то вычисление N-го числа Фибоначчи будет требовать O(logN/logK * K^3) операций. При этом максимальная степень параллелизма составит K^2, что даст время O(log N / log K * K). Как видно, асимптотика не улучшилась, а ровным счетом наоборот.
Но попытка интересная.
Но попытка интересная.
не нашел) удалил комментарий)
да вы нарисуйте картинку то — это не параллельность, это дерево
На эту тему весьма обстоятельно:
trigonakis.com/blog/2011/02/27/parallelizing-simple-algorithms-fibonacci/
trigonakis.com/blog/2011/02/27/parallelizing-simple-algorithms-fibonacci/
Рекурсивные алгоритмы тоже параллелятся, другое дело что менее эффективно и более сложно, чем итеративные. В шахматных движках например при поиске в глубину (а это даже сложнее, чем числа Фибоначчи, поскольку там дерево вызовов может быть сильно не симметричным) существуют алгоритмы для работы в несколько потоков.
Сложность приведенного вами алгоритма экспоненциальная на одном ядре, а если бы у вас было бесконечное число ядер, то отправляя каждый вызов в новое ядро, вы бы получили выполнение задачи за линейное время. Про это я и говорил. Распараллелить можно, но смысла в этом мало, потому что именно для этой задачи существуют обходные пути. Но вот тот же самый quicksort имеет похожий вид и для него такое распараллеливание работает хорошо и быстро, хотя тоже ведь рекурсия.
Еще раз: я написал, что позанудствую и подчеркнул разницу между «нельзя распараллелить» и «можно, но выигрыша не принесет по сравнению с другими реализациями». Вот 1+1 нельзя распараллелить, а некоторые реализации вычисления чисел фибоначчи можно, но ускорения это не приносит.
quicksort паралелится, т.к. там дерево и обработка обеих веток друг от друга не зависит. При вычислении чисел Фибоначи как F(n) = F(n-1)+F(n-2) обе ветки явно зависят друг от друга.
Кстати, справедливости ради стоит упомянуть что n-ное число Фибоначи можно итеративно вычислить за время O(log n). Описание мне попадалось в mitpress.mit.edu/sicp/full-text/book/book-Z-H-11.html, Exercise 1.19
Кстати, справедливости ради стоит упомянуть что n-ное число Фибоначи можно итеративно вычислить за время O(log n). Описание мне попадалось в mitpress.mit.edu/sicp/full-text/book/book-Z-H-11.html, Exercise 1.19
Справедливости ради, для чисел Фиббоначи есть формула Бине (в Википедии есть) — никаких рекурсий, никаких матриц, никаких O(log n), все делается за O(1).
Делается-то за O(1), но 16-элемент ряда, например, получается равным 986.99999999999999995928
А сложность вычисление показательного выражения символьными методами, как мне кажется, совсем не O(1).
А сложность вычисление показательного выражения символьными методами, как мне кажется, совсем не O(1).
Справедливости ради, числа фибоначчи нельзя даже вывести ни за O(1), ни за O(logn). N-е число фибоначчи — это экспонента от N. Количество в цифре любого числа — это примерно логарифм этого числа. Т.е. N-е число фибоначчи имеет примерно N цифр домноженное на какую-то константу.
Я тоже немного позанудствую, но рекурсивное вычисление чисел Фибоначчи медленнее циклического при любом числе потоков.
Медленнее, да, но из-за того, что для параллельной рекурсии не хватает физических ядер, а потоки медленные сами по себе.
В языках поддерживающих хвостовую рекурсию, сложность цикла и рекурсивного вызова примерно одинаковы, более того чаще всего циклы реализируются через рекурсивный вызов функции.
Что?
Во-первых, хвостовую рекурсию может поддерживать компилятор, но не язык.
Во-вторых, формула f(x+2) = f(x+1) + f(x) не дает хвостовой рекурсии ни при каких условиях.
Во-первых, хвостовую рекурсию может поддерживать компилятор, но не язык.
Во-вторых, формула f(x+2) = f(x+1) + f(x) не дает хвостовой рекурсии ни при каких условиях.
Но ведь можно вот так сделать?
tratt.net/laurie/blog/entries/tail_call_optimization
tratt.net/laurie/blog/entries/tail_call_optimization
def fib(i, current = 0, next = 1):
if i == 0:
return current
else:
return fib(i - 1, next, current + next)
В контексте процессора всё просто — делать симметричную многопроцессорность не дорого, а очень дорого. Каждый write lock стопит все все ядра на всех операциях с памятью. Чем больше процессоров, тем больше ожидания синхронизации.
multicore до сих пор не выкатили не только по причине жадности интела, но и по объективным причинам.
multicore до сих пор не выкатили не только по причине жадности интела, но и по объективным причинам.
Простите, но что вы понимаете под терминами «multicore» и «не выкатили»? Такое ощущение, что мы обсуждаем разные проблемы на разных языках…
Ага, я их опять попутал. Разумеется, речь про many-cores. Сейчас по мнению интела эпоха multicores, а потом будет many-cores, и там текущие подходы к ПО и процессорам перестанут работать из-за того, что ядер будет так много, что оверхед на SMP будет недопустимо высокий.
www.altera.com/technology/system-design/articles/2012/multicore-many-core.html
www.altera.com/technology/system-design/articles/2012/multicore-many-core.html
и процесс переноса процесса с ядра на ядро
Кто говорит о переносе процесса с ядра на ядро? Речь идет о том, что одна программа выполняется на первом ядре, другая — на втором и т. д. Результат получается в любом случае быстрее (ну, не медленнее) и отзывчивее, нежели одноядерный вариант.
от этого игрушка меньше лагать не станет — прирост от того, что ресурсы ядра теперь только одной программой заняты — минимален — программа все равно выполняется на одном ядре, если хочется, чтоб реально работала в параллель — нужно специальным образом реализовывать алгоритмы, при том — не все пока поддаются распараллеливанию
Игрушка будет лагать меньше хотя бы от того, что есть возможность выделить ей гарантировано целое ядро в индивидуальное пользование. Видео для вашей игрушки спокойно обрабатывается тысячами ядер вашей видеокарты. Звук и сеть обрабатываются через DirectX и тоже выносятся на свободные ядра, без участия разработчика.
В контексте «одноядерный» — да. Но вот что быстрее — 60 процессов по штуке на 60 ядер или 60 процессов на 30 ядрах, выполняющиеся по очереди — это вопрос открытый. На соответствующих кривых производительность начинает падать из-за оверхеда процессорной шины, общей памяти и т.д.
И в какой доле современных серверных систем runnable-процессов больше, чем количество ядер/потоков? Про домашние и так понятно, что 0.
Жаль, что только в пределах ядра программа тоже бы хотела исполняться параллельно на таких вот процессорах (не беру в расчёт GPU), но к сожалению не все задачи можно распараллелить :(
На одном ядре у меня любимая игрушечка (95% нагрузки), на втором фоновые процессы (20% нагрузки), третьим и четвертым ядром мы с пацанами меряемся по пятницам :)
Софт со временем созреет. Сейчас многое для этого делается: синтаксические расширения языков программирования, библиотеки хорошие, обучение студентов в ключе «параллельного мышления».
Основная проблема как раз в этом и есть: нынешние поколения программистов не привыкли мыслить параллельно. Как говорит один мой знакомый, параллельно умеют мыслить только домохозяйки. У них в одном углу ребенок растет, в другом кастрюля кипит, а в третьем белье гладится. И ведь все синхронизовано! :)
Кстати, над автоматическим распараллеливанием программ работы тоже ведутся. Но здесь все как-то запредельно сложно получается пока что…
Основная проблема как раз в этом и есть: нынешние поколения программистов не привыкли мыслить параллельно. Как говорит один мой знакомый, параллельно умеют мыслить только домохозяйки. У них в одном углу ребенок растет, в другом кастрюля кипит, а в третьем белье гладится. И ведь все синхронизовано! :)
Кстати, над автоматическим распараллеливанием программ работы тоже ведутся. Но здесь все как-то запредельно сложно получается пока что…
еще бы стоило отметить, что львиную долю энергозатрат занимает поддержка устаревших архитектур, в архитектуру вносятся дополнительные элементы, что так же ограничивает максимальную скорость работы системы
какие дополнительные тормозящие элементы вы имеете в виду?
которые отвечают за совместимость с более старой архитектурой — абстрактный пример — допустим (ДОПУСТИМ) сперва сделали 8 битные регистры и на этом построили архитектуру, то есть передача данных по 8 разрядным шинам идет, потом сделали 32 битную архитектуру и данные передаются по 32 разрядным шинам — соответственно для каждой архитектуры свой набор инструкций — одни инструкции могут работать с 32 битной шиной, другие-более старые — нет, соответственно — поскольку процессор должен поддерживать ВСЕ инструкции, которые были когда либо заложены в архитектуру — нужен какой то дешифратор, который определяет — с какой шиной и регистрами будет работать процессор — если надо — переключает — на это все доп время и энергия тратится
Intel когда-нибудь собирается отказаться от поддержки старых архитектур для увеличения производительности?
спросить у интела надо), но вряд ли — вы представляете — сколько софта написано за годы существования процессоров? как от этого всего отказаться
Itanium — принципиально другая архитектура. Тут речь скорее про отказ от 8-ми битных и 16-ти битных регистров и пары команд, нужных только в DOS.
Intel менее всего выгодно банкротство AMD. Их же антимонопольщики съедят. Посмотрите структуру владельцев, сильно удивитесь. Как только AMD испытывает серьёзные трудности – сразу же получает заметные инвестиции.
Если бы эта «современная архитектура» действительно работала-бы быстрее, но ничего с этим сделать бы AMD не смогла. Но она не работала быстрее: в большинстве задач она просто-напросто работала медленнее, а там, где она могла разогнаться (всякого рода математика) она оказалась гораздо медленнее видеокарт. И тогда зачем весь этот огород?
Это вы про итаниум которые потреблял так, что AMD устали снимать смешную рекламу про них? У итаниума не было будущего за пределами серверов.
Извините, вы работали с Itanium.
я пробывал сравнить сервер с 8 itanium на hpux 11.24, сервер на parisc тоже hpux на тот момент ему было около 10 лет, sun fire 240 sunos 5.8, и помоему 585 пролиант на 4 оптеронах RHEL.
Простым gzip видео > /dev/null
gzip не распаралеливается, то есть сравнивал производительность 1 ядра.
Отстающими оказались parisc и itanium.
я пробывал сравнить сервер с 8 itanium на hpux 11.24, сервер на parisc тоже hpux на тот момент ему было около 10 лет, sun fire 240 sunos 5.8, и помоему 585 пролиант на 4 оптеронах RHEL.
Простым gzip видео > /dev/null
gzip не распаралеливается, то есть сравнивал производительность 1 ядра.
Отстающими оказались parisc и itanium.
arm же шагает по планете и ничего, достаточно уверенно набирает обороты. большую часть этого старого софта можно было и 10 лет назад выкинуть.
ARM-ы только немного выигрывают по энергопотреблению по сравнению с x86 процессорами но по производительности пока еще не конкуренты совершенно, да и в будущем тоже врядли ситуация изменится. Архитектура другая, заточенная под более узкие задачи — низкое потребление, воспроизведение HD-видео и т.д. а как процессоры общего назначения они не привлекательны в основном из-за низкой производительности.
Какая еще львиная доля? Если вы видите какие-то существенные изъяны в x86, то это как бы не «поддержка», а и есть сама архитектура. От всяких старых команд вред разве что в том. что они занимают короткие коды. Но это мелочь.
Замечу, что за один такт 3ГГц процессора электромагнитная волна преодолевает 10 см, что сопоставимо с размером процессора.
Ну это все-таки еще довольно много, так как в процессоре существует кэш.
В будущем наверное вся ОЗУ будет размещаться прямо в процессоре.
Интересно, какая максимальная теоретическая частота возможна (или хотя бы ее предел), если предположить, что вся память находится на процессоре, если исходить из ограничений по скорости света?
В будущем наверное вся ОЗУ будет размещаться прямо в процессоре.
Интересно, какая максимальная теоретическая частота возможна (или хотя бы ее предел), если предположить, что вся память находится на процессоре, если исходить из ограничений по скорости света?
Это сопоставимо (хотя и в несколько раз больше) с размером корпуса процессора, который в свою очередь в несколько раз больше кремниевого ядра, а все процессы, происходящие с трёхгигагерцевой частотой, происходят именно в нём.
Только там далеко не прямолинейное распространение — надо же включать/выключать элементы.
Волна преодолевает, но основной ограничитель — время заряда паразитных емкостей.
Что-то я не совсем понял аналогию со строительством стен и перекрытий, а что мешает рабочим, которые строят стены перейти в другой дом и начать строить стены там(после завершения постройки стен в первом доме)?
ничто не мешает, но этаж в итоге быстрее не построится, то есть время исполнения одной инструкции от этого не уменьшится — следующий этап невозможно начать, пока не получен результат предыдущего
Ничего не мешает. Вы изобрели/описали hyper threading
Пока будешь идти от дома к дому у тебя как раз этаж построят.
Неправильно проводимый разгон опасен не только для ваших процессоров, но и для вас лично!
Общество жаждет историй :D
Ещё один вопрос, который напрашивался после прочтения статьи: получается, из-за почти полной обратной совместимости в x86-процессорах, невозможно сильно укоротить самые длинные стадии в инструкциях? И именно в это всё и упирается?
И именно из-за этого любители ARM так хотят «похоронить» x86?
Но похоронить его не получится, т.к. слишком много хорошего софта уже написано и переписывать его никто не будет?
И именно из-за этого любители ARM так хотят «похоронить» x86?
Но похоронить его не получится, т.к. слишком много хорошего софта уже написано и переписывать его никто не будет?
Много проприетарного хорошего софта уже написано. С появлением ARM на серверах, а там везде Open Source, когда можно будет скомпилировать софт под любую архитектуру, а приложения уйдут в Web, Intel придется что-то делать со всем тем багажом костылей ее архитектуры. Кроме того, там все здорово параллелится и количество ядер добавляет производительность практически пропорционально.
А компилятор с хорошей оптимизацией под ARM64 сам материализуется? gcc и clang до сих не поддерживают интринзики под ARMv6, хотя архитектуре уже больше пяти лет. Пока их допилят генерировать качественный код под ARM64, может и мода на облака уйти.
ARM64 появился две недели назад в конечных устройствах все-лишь. Кроме того, несмотря на отсутствие интринзиков, как-то ведь появляются игры на iPhone/Android. Что же касается серверного софта, там на FPU/SIMD нагрузки вообще очень мало.
Разработчики серверного софта (тем более опен сорсного) не готовы на такие жертвы ради производительности, на которые идут разработчики игр. Дело не в FPU/SIMD (ARMv6 интринзики это вообще про целочисленную арифметику), а про то, что компиляторы под ARM64 генерируют говнокод, и их ещё предстоит много лет вылизывать, прежде чем они сравняются по качеству кодогенерации с x86.
Вы хотите сказать Apple выпустила iPhone5S с совсем сырым компилятором? И кто такие эти разработчики серверного софта? Разработчики серверного софта это разработчики Java, Ruby, Python, PHP, а там все уже давно заточено и отшлифовано весьма. Вот в новом JBoss AS 8, который будет называться Wildfly и выйдет в этом году специально было проведено много работы с учетом особенностей других архитектур.
Представьте себе серверную стойку, и ещё представьте себе юнит. Обчный такой юнит, но размером с iPhone 4 и как в рекламе Эльрадо, 4 ядра 4 гига. $200-$300; цена(и это поначалу, потом подтянутся китайцы и спустят до сотки). Производительность на Ватт/Цену/Объем такая, что Интел впору бы было посыпать голову пеплом и скупать какой-нибудь Broadcom или TI уже сейчас. Кроме того там нечего администрировать, потому что устройства поставляются с чем-то типа готоваой прошивки => больше производительность труда админов => ещё меньше совокупная стоимость владения.
Такие дела. Будущее здесь.
Представьте себе серверную стойку, и ещё представьте себе юнит. Обчный такой юнит, но размером с iPhone 4 и как в рекламе Эльрадо, 4 ядра 4 гига. $200-$300; цена(и это поначалу, потом подтянутся китайцы и спустят до сотки). Производительность на Ватт/Цену/Объем такая, что Интел впору бы было посыпать голову пеплом и скупать какой-нибудь Broadcom или TI уже сейчас. Кроме того там нечего администрировать, потому что устройства поставляются с чем-то типа готоваой прошивки => больше производительность труда админов => ещё меньше совокупная стоимость владения.
Такие дела. Будущее здесь.
Кроме того там нечего администрировать,На сервере-то? рофл…
Любители разбрасываться производительностью на Ватт, покажите мне хоть один пруф в пользу любого Arm. Пока я вижу только маркетинговый обман, и все бенчмарки говорят обратное.
По бенчмаркам даже Intel Atom (Z2760) энергоэффективнее Tegra 3 либо на уровне Cortex A15 — www.anandtech.com/show/6536/arm-vs-x86-the-real-showdown/8. И при этом Intel в этом сравнении быстрее.
Ну чтобы по скорости догнать Haswell i7, ARM должен быть раз в 5-10 быстрее.
Ну и хотелось бы посмотреть на сервер с хотя бы минимально необходимым SSD 256Gb за $300, и главное зачем он нужен на ARM, если есть тот же hetzner на Haswell с SSD за 48 евро (без VAT), которые быстрее любого арма раз в 10.
По бенчмаркам даже Intel Atom (Z2760) энергоэффективнее Tegra 3 либо на уровне Cortex A15 — www.anandtech.com/show/6536/arm-vs-x86-the-real-showdown/8. И при этом Intel в этом сравнении быстрее.
Ну чтобы по скорости догнать Haswell i7, ARM должен быть раз в 5-10 быстрее.
Ну и хотелось бы посмотреть на сервер с хотя бы минимально необходимым SSD 256Gb за $300, и главное зачем он нужен на ARM, если есть тот же hetzner на Haswell с SSD за 48 евро (без VAT), которые быстрее любого арма раз в 10.
Ок, хватит этого буллшита, где сравнивают Chrome на Android на ретине и WinRT на Эксплорере. Сейчас готовлю серию бенчей на серверных задачах. Внезапно. Cortex-A9 против Sandy Bridge. По первым данным по Ruby and Rails, там даже при таком раскладе у Intel есть серьезные затруднения в плане производительности/ватт и производительности на доллар. Но подождите, будет классная статья, обещаю. Если народу понравится, то потом будет Java, по которой я данные примерно представляю, может Python, обязательно NoSQL.
Мечты, но такого не будет. Хотя бы потому что вы замучаетесь делать из под Web что то похожее на тяжелые редакторы (Photoshop, CorelDraw) или игрушки онлайн. Плюс не у каждого жителя планеты есть доступ хотя-бы к 512\64 КБит интернету. Поэтому в вебе будет очень ограниченное число приложений ближайшие лет 5.
Не стоит напрямую связывать обратную совместимость и возможность работать над длиной стадии. Однако действительно: отказ от совместимости позволяет работать над проблемой более эффективно.
Идеальная машина — это та, в которой единственные связи между инструкциями — это связи по данным (т.е. одни инструкции используют результаты работы других). Задача разработчиков архитектуры — постоянно приближаться к этому идеалу, устраняя все другие (кажущиеся искусственными) зависимости. Не думаю, что ARM сейчас ближе к этому идеалу, чем x86.
Зачем любители ARM хотят «похоронить» x86 (а они действительно хотят?), я не знаю. Я за разнообразие архитектур. Без конкуренции ничего хорошего не получается :)
И еще я бы не сказал, что единственная причина, по которой x86 жива, — это большое количество написанных программ. Все-таки, на сегодняшний день, это самая эффективная архитектура, которая все еще продолжает развиваться.
Идеальная машина — это та, в которой единственные связи между инструкциями — это связи по данным (т.е. одни инструкции используют результаты работы других). Задача разработчиков архитектуры — постоянно приближаться к этому идеалу, устраняя все другие (кажущиеся искусственными) зависимости. Не думаю, что ARM сейчас ближе к этому идеалу, чем x86.
Зачем любители ARM хотят «похоронить» x86 (а они действительно хотят?), я не знаю. Я за разнообразие архитектур. Без конкуренции ничего хорошего не получается :)
И еще я бы не сказал, что единственная причина, по которой x86 жива, — это большое количество написанных программ. Все-таки, на сегодняшний день, это самая эффективная архитектура, которая все еще продолжает развиваться.
нет не поэтому. старые инструкции не причем, в основном ограничителем является АЛУ — а именно время прохождения сигнала от его входа к выходу. Элементарная операция сложения двух чисел — сигнал логических состояний операндов на входе проходит несколько уровней логических вентилей прежде чем попадет на выход, из этого складывается минимальное время стадии. Впрочем, есть наверняка команды и потяжелее. Сами вентили из которых стоят логические блоки вполне способны работать на частотах до 20-30ГГц, но сложность самих логических блоков сильно увеличивает время прохождения сигнала от входа к выходу.
Единственный способ сократить это время — упрощение структуры логических блоков в ущерб универсальности — что-то подобное и делают в ARM-ах.
Проблема ARM-ов в том что они более узкоспециализированные вычислители чем процессоры широкого применения x86 за счет чего ARM-ы в планшетах и телефонах потребляют меньше энергии, но соотношение количества работы к затраченной энергии по сравнению с x86 или даже x64 на общих задачах отличается ненамного.
Единственный способ сократить это время — упрощение структуры логических блоков в ущерб универсальности — что-то подобное и делают в ARM-ах.
Проблема ARM-ов в том что они более узкоспециализированные вычислители чем процессоры широкого применения x86 за счет чего ARM-ы в планшетах и телефонах потребляют меньше энергии, но соотношение количества работы к затраченной энергии по сравнению с x86 или даже x64 на общих задачах отличается ненамного.
Итаник не может утонуть. Итаник не может утонуть. Итаник не тонет. Итаник не тонет. Итаник не утонул. Итаник не утонул.
Представитель intel может это подтвердить.
Представитель intel может это подтвердить.
Тоже немного по нему ностальгирую. Технически он еще жив, т.к. все еще есть клиенты, которые его покупают. Но уже не развивается.
Itanium отлично показал себя на некоторых классах задач, но на некоторых оказался средненьким. В общем, не потянул на general purpose архитектуру.
Однако на нем были обкатаны некоторые интересные фишки (двоичная трансляция, например). Многие из этих фишек, подозреваю, получат новые воплощения, но уже с учетом полученных уроков.
Itanium отлично показал себя на некоторых классах задач, но на некоторых оказался средненьким. В общем, не потянул на general purpose архитектуру.
Однако на нем были обкатаны некоторые интересные фишки (двоичная трансляция, например). Многие из этих фишек, подозреваю, получат новые воплощения, но уже с учетом полученных уроков.
Не жаль. На HP-UX-ia64 11i-v3 образца 2009 года (уже вполне развитый и матёрый релиз) самая популярная машинная инструкция в /bin:/usr/bin всё ещё была nop. Itanium не угробили, он сам не взлетел.
Странно слышать про микроархитектурные проблемы роста частоты. Особенно с учетом оверклокерских достижений.
Самая большая проблема — TDP и токи утечек. Чем меньше транзистор, тем тоньше прослойка диэлектрика, соответственно повышается шанс паразитных утечек, которые и повышают нагрев кристалла.
Длина конвейера у последних P4 была равна 31 стадиям, и максимальные частоты были в районе 3.8 GHz. Новая архитектура Haswell имеет 14-19 стадий конвейера, а тактовые частоты находятся все в том же районе, и легко подымаются выше. Длина конвейера архитектуры Piledriver составляет те же 14-17 стадий и тот же уровень частот, может чуть выше.
Самая большая проблема — TDP и токи утечек. Чем меньше транзистор, тем тоньше прослойка диэлектрика, соответственно повышается шанс паразитных утечек, которые и повышают нагрев кристалла.
Длина конвейера у последних P4 была равна 31 стадиям, и максимальные частоты были в районе 3.8 GHz. Новая архитектура Haswell имеет 14-19 стадий конвейера, а тактовые частоты находятся все в том же районе, и легко подымаются выше. Длина конвейера архитектуры Piledriver составляет те же 14-17 стадий и тот же уровень частот, может чуть выше.
Вы о чем?
Он хотел сказать, что вы даже не прочитали статью, или прочитали ее невнимательно, но уже написали критический комментарий, полагая, что знаете эту проблему лучше, чем специалисты Intel.
В статье довольно понятно написано, почему оверклокерские достижения не могут стать массовыми. На всякий случай повторю: среднестатистический пользователь не может использовать те системы охлаждения, которые используются оверклокерами.
В статье довольно понятно написано, почему оверклокерские достижения не могут стать массовыми. На всякий случай повторю: среднестатистический пользователь не может использовать те системы охлаждения, которые используются оверклокерами.
Как человек, который наблюдает за развитием микропроцессоров и их архитектур на протяжении последних 15 лет, я повидал достаточно маркетинговых заманух (Pentium ускоряет интернет) и различных решений как на уровне архитектур, так и на уровне физических реализаций.
Так вот, я скептически отношусь к заявлениям, которые маркетинговые по сути.
Давайте разберем главный тезис, что основной тормоз — конвейер. Да, выполнение некоторых инструкций требует занятости ФУ на разное количество тактов. Однако P4 имел 2ALU, которые работали на удвоенной частоте и могли обрабатывать инструкции за половину такта. Мало того, P4 имел избыточное количество ALU для его трехМОПного планировщика, т.е. 4, что позволяло освобождать дополнительный ресурс уже на следующий такт. О чем это говорит? О том, что вполне можно ускорять отдельные блоки по частоте, если вы хотите добиться какой-то цели.
Идем дальше. HyperThreading появился потому, что половина ресурсов ЦП не может быть эффективно утилизирована из-за проблем с доставкой данных из памяти, потому что латентность этих операций идет более 70 тактов (если данные не осели в кэше). Да, HT дает до 40% прироста производительности на двух параллельно выполняемых потоках, что снова же подтверждает факт простоя ФУ.
Смотрим на подход AMD с их модульной архитектурой, где модуль состоит из двух половинок с 2 ALU на борту (напомним, что в том же Core три ALU), утилизация ресурсов на оптимизированных алгоритмах весьма впечатляющая, и как минимум не уступает архитектуре Core второго поколения.
Суммируя хотя бы эти три факта мы получаем простой вывод, что рост частоты бесполезен ровно до тех пор, пока ФУ не будут загружаться постоянно и своевременно. Конвейер всегда можно расширить или применять тактику удвоения частоты работы ФУ, только бы патроны подавались вовремя.
Но, за увеличением количества ФУ стоит его величество ТДП. В спецификации по управлению питанием мы можем увидеть многофакторную систему удержания теплопакета в рамках допустимых значений. Там участвует и температура, и вольтаж, и частота отдельного ядра, и уровень загруженности…
Опять же, возьмем рендеринг 3D. Там применяются весьма впечатляющие оптимизации алгоритмов, поэтому они позволяют выжимать максимум из процессора и его архитектуры. Банально, не будем ходить далеко, сравним прирост частоты и прирост производительности i7-2600K при разгоне. Так вот, разгон с 3.4 до 4.45 (+30%) дает прирост производительности в районе 20%. Да, рост не линейный, но он есть. Погодите, в статье рассказывается, что конвейер не дает повышать частоту, но мы видим обратное, частота растет, и растет производительность. Да, не линейно, но рост есть. Упираемся в синхронизацию выполнения МОПов? А может все больше простаиваем по причине увеличения латентности доступа к памяти?
Но хабр такой хабр… Лучше ведь уличить кого-то в некомпетентности…
Так вот, я скептически отношусь к заявлениям, которые маркетинговые по сути.
Давайте разберем главный тезис, что основной тормоз — конвейер. Да, выполнение некоторых инструкций требует занятости ФУ на разное количество тактов. Однако P4 имел 2ALU, которые работали на удвоенной частоте и могли обрабатывать инструкции за половину такта. Мало того, P4 имел избыточное количество ALU для его трехМОПного планировщика, т.е. 4, что позволяло освобождать дополнительный ресурс уже на следующий такт. О чем это говорит? О том, что вполне можно ускорять отдельные блоки по частоте, если вы хотите добиться какой-то цели.
Идем дальше. HyperThreading появился потому, что половина ресурсов ЦП не может быть эффективно утилизирована из-за проблем с доставкой данных из памяти, потому что латентность этих операций идет более 70 тактов (если данные не осели в кэше). Да, HT дает до 40% прироста производительности на двух параллельно выполняемых потоках, что снова же подтверждает факт простоя ФУ.
Смотрим на подход AMD с их модульной архитектурой, где модуль состоит из двух половинок с 2 ALU на борту (напомним, что в том же Core три ALU), утилизация ресурсов на оптимизированных алгоритмах весьма впечатляющая, и как минимум не уступает архитектуре Core второго поколения.
Суммируя хотя бы эти три факта мы получаем простой вывод, что рост частоты бесполезен ровно до тех пор, пока ФУ не будут загружаться постоянно и своевременно. Конвейер всегда можно расширить или применять тактику удвоения частоты работы ФУ, только бы патроны подавались вовремя.
Но, за увеличением количества ФУ стоит его величество ТДП. В спецификации по управлению питанием мы можем увидеть многофакторную систему удержания теплопакета в рамках допустимых значений. Там участвует и температура, и вольтаж, и частота отдельного ядра, и уровень загруженности…
Опять же, возьмем рендеринг 3D. Там применяются весьма впечатляющие оптимизации алгоритмов, поэтому они позволяют выжимать максимум из процессора и его архитектуры. Банально, не будем ходить далеко, сравним прирост частоты и прирост производительности i7-2600K при разгоне. Так вот, разгон с 3.4 до 4.45 (+30%) дает прирост производительности в районе 20%. Да, рост не линейный, но он есть. Погодите, в статье рассказывается, что конвейер не дает повышать частоту, но мы видим обратное, частота растет, и растет производительность. Да, не линейно, но рост есть. Упираемся в синхронизацию выполнения МОПов? А может все больше простаиваем по причине увеличения латентности доступа к памяти?
Но хабр такой хабр… Лучше ведь уличить кого-то в некомпетентности…
Так вот, разгон с 3.4 до 4.45 (+30%) дает прирост производительности в районе 20%. Да, рост не линейный, но он есть.Вот этот факт уже интереснее, над ним можно думать (если он подтвердится, конечно же). Надо было написать его сразу, вместо абстрактных «оверклокерских достижений».
В смысле если подтвердится?
Исследование производительности на реальном софте реальными людьми. Изучайте сколько влезет.
Идем дальше.
Смотрим на латентность инструкции MOVNTI
Nehalem: ~270 тактов
Sandy Bridge: ~350
Ivy Bridge: ~340
Haswell: ~400
Ха, латентность растет, частота находится на одном и том же уровне для всех этих архитектур. Это говорит про то, что латентность этой команды всем пофиг, она незначительна и не вносит серьезного влияния в общую производительность. Но нам усердно рассказывают, что проблема в этих самых «дорогих» операциях…
Давайте посмотрим на ту же фичу, которая появилась в архитектуре Core, такая как Macro Fusion. Она нам говорит, что некоторые операции могут соединяться в одну, чтобы выполняться в ФУ за 1 такт. Это значит, что есть операции, которые выполняются за доли такта. Так есть еще порох в пороховницах…
И, напоследок, почти все современные процессоры имеют блоки изменения очередности выполнения команд, которые позволяют равномерно распределять нагрузку по ФУ, достигая их более высокого уровня загруженности. Это снова же говорит в пользу простоя блоков и снижения влияния «толстых» комманд на общую производительность.
Еще раз повторю, можно просто увеличить количество ALU или FPU, или разрезать ALU на несколько частей, чтобы отделить одни операции от других. Но этим никто не будет заниматься, потому что бюджет транзисторов не бесконечный.
Исследование производительности на реальном софте реальными людьми. Изучайте сколько влезет.
Идем дальше.
Смотрим на латентность инструкции MOVNTI
Nehalem: ~270 тактов
Sandy Bridge: ~350
Ivy Bridge: ~340
Haswell: ~400
Ха, латентность растет, частота находится на одном и том же уровне для всех этих архитектур. Это говорит про то, что латентность этой команды всем пофиг, она незначительна и не вносит серьезного влияния в общую производительность. Но нам усердно рассказывают, что проблема в этих самых «дорогих» операциях…
Давайте посмотрим на ту же фичу, которая появилась в архитектуре Core, такая как Macro Fusion. Она нам говорит, что некоторые операции могут соединяться в одну, чтобы выполняться в ФУ за 1 такт. Это значит, что есть операции, которые выполняются за доли такта. Так есть еще порох в пороховницах…
И, напоследок, почти все современные процессоры имеют блоки изменения очередности выполнения команд, которые позволяют равномерно распределять нагрузку по ФУ, достигая их более высокого уровня загруженности. Это снова же говорит в пользу простоя блоков и снижения влияния «толстых» комманд на общую производительность.
Еще раз повторю, можно просто увеличить количество ALU или FPU, или разрезать ALU на несколько частей, чтобы отделить одни операции от других. Но этим никто не будет заниматься, потому что бюджет транзисторов не бесконечный.
Почему вы считаете, что специалисты(мы же про маркетологов говорим?) Интел имеют цель продать вам самый быстрый процессор?
Им достаточно продать вам процессор быстрее процессора конкурента.
> На всякий случай повторю: среднестатистический пользователь не может использовать те системы охлаждения, которые используются оверклокерами.
Это софистика, и внедрить её в массы и есть цель написания статьи. Да, средний пользователь 7 ГГц не получит, а 4.5 — вполне.
Им достаточно продать вам процессор быстрее процессора конкурента.
> На всякий случай повторю: среднестатистический пользователь не может использовать те системы охлаждения, которые используются оверклокерами.
Это софистика, и внедрить её в массы и есть цель написания статьи. Да, средний пользователь 7 ГГц не получит, а 4.5 — вполне.
Два года назад я помог десяти людям понизить тактовую частоту процессора, благодаря чему их компьютеры перестали перезагружаться на «веселой ферме» при +37 на улице и +35 в комнате.
Сам я сейчас имею планы по понижению тактовой частоты моей видеокарты, надеясь хоть после этого суметь пройти Скайрим.
Я честно искал более мощные системы охлаждения, пригодные для эксплуатации неспециалистами. Я менял термопасту. Но не помогало ничего, кроме понижения частоты. А теперь вы мне рассказываете, что эту частоту можно, видите ли, поднять. В северных широтах — может и можно. Но не в моем городе.
Сам я сейчас имею планы по понижению тактовой частоты моей видеокарты, надеясь хоть после этого суметь пройти Скайрим.
Я честно искал более мощные системы охлаждения, пригодные для эксплуатации неспециалистами. Я менял термопасту. Но не помогало ничего, кроме понижения частоты. А теперь вы мне рассказываете, что эту частоту можно, видите ли, поднять. В северных широтах — может и можно. Но не в моем городе.
То есть вы утверждаете, что «специалисты» Intel не способны подобрать частоту и гонят брак в промышленных масштабах?
У меня средний аптайм месяц на всех компах, перезагружаюсь только если софт требует или электричество выключают. Попробуйте нормальный блок питания купить, например. И память.
У меня средний аптайм месяц на всех компах, перезагружаюсь только если софт требует или электричество выключают. Попробуйте нормальный блок питания купить, например. И память.
В таком случае я завидую климату дефолт-сити.
Эффект Даннинга — Крюгера?
> Процессоры рассчитаны производителем на то, чтобы эксплуатироваться в широком диапазоне внешних условий (которые влияют на длину стадии), поэтому производятся с некоторым запасом по частоте.
> Процессоры рассчитаны производителем на то, чтобы эксплуатироваться в широком диапазоне внешних условий (которые влияют на длину стадии), поэтому производятся с некоторым запасом по частоте.
Специально для вас посмотрел, что пишут специалисты: www.intel.ru/content/dam/www/public/us/en/documents/design-guides/4th-gen-core-family-desktop-tmsdg.pdf
То есть в описанной мною ситуации процессоры работали на пределе заложенных температурных возможностей. Добавим сюда любую мелкую помеху системе охлаждения — вот и перегрев. Напомню, компьютер эксплуатируется неспециалистами, которые всегда найдут способ чем-нибудь перекрыть поток воздуха. А не найдут люди — так кот поможет.
3.1 Boundary Condition Definition
…
TEXTERNAL = 35 °C. This is typical of a maximum system operating environment or room temperature
То есть в описанной мною ситуации процессоры работали на пределе заложенных температурных возможностей. Добавим сюда любую мелкую помеху системе охлаждения — вот и перегрев. Напомню, компьютер эксплуатируется неспециалистами, которые всегда найдут способ чем-нибудь перекрыть поток воздуха. А не найдут люди — так кот поможет.
Специально для вас посмотрел, что пишут специалисты
The results may be excessive noise from fans having to operate at a speed higher than intended. In the worst case this can lead to performance loss with excessive activation of the Thermal Control Circuit (TCC).
Перезагрузка — это брак.
> А не найдут люди — так кот поможет.
вы до скольки занижаете частоту, чтоб от кота защититься? От пролитого чая?
The results may be excessive noise from fans having to operate at a speed higher than intended. In the worst case this can lead to performance loss with excessive activation of the Thermal Control Circuit (TCC).
Перезагрузка — это брак.
> А не найдут люди — так кот поможет.
вы до скольки занижаете частоту, чтоб от кота защититься? От пролитого чая?
Вы ищете системы охлаждения. А возможно, проблема кроется в плохом корпусе. Вот мой (картинка устарела — с тех пор добавилась вторая видеокарта, да и плашек памяти стало четыре). На процессоре заводская водянка, никаких сложностей, ставится даже проще суперкулеров. Напротив видеокарт 200мм вертушка поставляет свежий воздух, еще одна спереди, и несколько 120мм пропеллеров сверху и сзади. Паутина проводов не мешает воздушному потоку (типичная ошибка).
Видеокарты и процессор слегка (где-то на треть) разогнаны. Процессор, 3770к, до тех самых 4,5ггц (у меня неудачный чип, он для этого требует целых 1,3в).
В самую лютую жару никаких проблем с перегревом не испытываю. Я даже не про полный ахтунг вида «троттлинг, ребут в веселой ферме», а про «не более 80 градусов на процессоре под линпаком и 90 градусов на видеокартах под бубликом».
Мораль — не надо экономить на охлаждении, тогда не придется заниматься даунклокингом.
Видеокарты и процессор слегка (где-то на треть) разогнаны. Процессор, 3770к, до тех самых 4,5ггц (у меня неудачный чип, он для этого требует целых 1,3в).
В самую лютую жару никаких проблем с перегревом не испытываю. Я даже не про полный ахтунг вида «троттлинг, ребут в веселой ферме», а про «не более 80 градусов на процессоре под линпаком и 90 градусов на видеокартах под бубликом».
Мораль — не надо экономить на охлаждении, тогда не придется заниматься даунклокингом.
А что за «заводская» водянка?
H100. Выхлоп сразу наружу корпуса (но крепится радиатор внутри корпуса, лишнего места не занимая, на фотографии как раз под ним вплотную 2х120мм привинчены). Конечно, по эффективности это не Silver Arrow, но уступает мало, и есть масса своих преимуществ.
я на своем компе дело поправил, сделав притяжно-вытяжную систему внутри корпуса — что толку ставить суперкуллер, если горячий воздух никуда из корпуса не выходит — лучше поставить 2 куллера на маленьких оборотах — один вдувает, другой выдувает воздух из корпуса
По поводу предмета спора: средний пользователь не будет ставить себе систему водяного охлаждения.
По поводу моих проблем и вашего корпуса: я рад, что в дефолт-сити достать нормальный корпус с заводской системой водяного охлаждения — не проблема, но в Челябинске систем водяного охлаждения нет вообще. По крайней мере, ни мои знакомые специалисты, ни папины знакомые специалисты, ни дедушкины знакомые специалисты, ни даже бабушкины знакомые специалисты не смогли подсказать мне нужного магазина.
По поводу моих проблем и вашего корпуса: я рад, что в дефолт-сити достать нормальный корпус с заводской системой водяного охлаждения — не проблема, но в Челябинске систем водяного охлаждения нет вообще. По крайней мере, ни мои знакомые специалисты, ни папины знакомые специалисты, ни дедушкины знакомые специалисты, ни даже бабушкины знакомые специалисты не смогли подсказать мне нужного магазина.
достать нормальный корпус с заводской системой водяного охлаждения
Корпус отдельно, вода отдельно.
средний пользователь не будет ставить себе систему водяного охлаждения.
А почему бы и нет?
Есть и воздушные кулеры с хорошей эффективностью. Что угодно лучше боксового кулера.
в Челябинске систем водяного охлаждения нет вообще
Сходу, за 10 секунд поиска:
chel.utinet.ru/hardware/liquid_cooling/zalman/cnps20lq/
Внизу ссылки на множество заводских водянок других брендов.
Да и почему именно Челябинск, когда есть Ebay и Amazon? Я половину железа там беру.
Обратите внимание: все, что находится сходу — интернет-магазины. То есть мне предстоит увлекательная игра «оплати заказ — подожди месяц — получи товар — убедись, что он не помог, ибо слабый — отправь обратно с заявлением почтой России — подожди 3 месяца возврата денег — перейди к пункту 1». Плюс ненулевая вероятность на очередной итерации потерять деньги из-за особенностей работы почты россии.
Конкретно по той ссылке, которую вы нашли — я так и не нашел, где указана хотя бы одна количественная характеристика эффективности охлаждения. Как вообще сравнивать эту систему охлаждения с аналогами?
Конкретно по той ссылке, которую вы нашли — я так и не нашел, где указана хотя бы одна количественная характеристика эффективности охлаждения. Как вообще сравнивать эту систему охлаждения с аналогами?
все, что находится сходу — интернет-магазины. То есть мне предстоит увлекательная игра
Доставка до пункта выдачи — бесплатно и без предоплаты. Домой — 443 рубля. Прямо по моей ссылке, найденной сходу.
Как вообще сравнивать эту систему охлаждения с аналогами?
Очевидно, что надо смотреть независимые обзоры. Любые количественные характеристики по отдельности или вместе не говорят вообще ни о чем. Первый попавшийся пример.
Будто вы в XX-м веке застряли, причем в совковые времена :)
Я вот когда что-то беру в интернет-магазине сначала гуглю предлагаемую модель и смотрю характеристики на сайте производителя, если таковой есть а если нет — то уже на свой страх и риск, естественно в итоге побеждает самый подходящий товар который максимально описан производителем. Там же, на сайте производителя можно посмотреть соседние модели, сравнить выбрать и найти в другом магазине. Это значительно снижает риски «кота в мешке» и пока ни разу подход не подвёл.
Я тоже так делаю, но это имеет смысл только когда имеешь хотя бы минимальные представления о предметной области.
Выше вы писали и про даунклокинг, и про:
Следовательно — вы имеете хотя бы минимальные представления о предметной области, и должны понимать, что описания площади радиаторов, силы воздушного потока, напряжений и оборотов вертушек, количества теплотрубок, массы, количестве хладагента, скорости его прокачки и так далее не позволяют судить об эффективности СО. Есть только одна цифра, которая важна: температура процессора с данной СО под нагрузкой, в сравнении с другими СО того же класса. Т.е. обзоры, которых полно.
Я честно искал более мощные системы охлаждения, пригодные для эксплуатации неспециалистами. Я менял термопасту. Но не помогало ничего, кроме понижения частоты.
Следовательно — вы имеете хотя бы минимальные представления о предметной области, и должны понимать, что описания площади радиаторов, силы воздушного потока, напряжений и оборотов вертушек, количества теплотрубок, массы, количестве хладагента, скорости его прокачки и так далее не позволяют судить об эффективности СО. Есть только одна цифра, которая важна: температура процессора с данной СО под нагрузкой, в сравнении с другими СО того же класса. Т.е. обзоры, которых полно.
возможность незначительно повысить частотуЧастоту можно повышать очень значительно, пока некоторые компании на «и» не начинают блокировать всеми силами эту возможность.
Core 2 и первое поколение i5/i7 — живой тому пример.
Странно, чего же некоторые компании на букву «А» не пользуются ситуацией и не захватывают рынок.
Некоторые компании на букву «А» не могут захватить рынок потому, что лет 5 не могут, к сожалению, достойный конкурента процессор выпустить и конкурируют только ценой.
Это внутренние проблемы «А», чем и пользуется компания на «И».
Это внутренние проблемы «А», чем и пользуется компания на «И».
Минусуют воинствующие фанаты интела?
Автор действительно является экспертов теме, о которой пишет, а вы демонстрируете яркий пример эффекта Даннинга — Крюгера. То есть да, с суперскалярностью вы человека подловили — скорее всего этот момент изначально в статье был, но потом выпал (суперскалярность, как бы, имеет прямое отношение к производительности и весьма косвенное — к частоте работы процессора) и остался обычный конвеер известный где-то с 70х (а может и раньше). Prescott же — идельный процессор для демонстрации тезисов, описанных в статье: в нём была сделана попытка «задрать частоту до небес», в конвеере создали аж 32 стадии (из-за чего многие вещи пришлось исполнять спекулятивно), в результате получили офигительную частоту и «прекрасное» тепловыделение при посредственной производительноти. Для справки: Nehalem имеет ровно вдвое меньше стадий и на той же частоте, что и Prescott исполняет программы чуть не вдвое быстрее (это без учёта многоядерности и прочего).
Название эффекта я действительно взял из комментария выше, но про этот феномен все знают и так.
Статья «Почему не растет частота» прекрасно объясняет почем частоты не увеличились. Вернее так: она даёт всё необходимое для того, чтобы понять почему частоты не увеличились (они, кстати, чуток таки увеличились — Turbo Bust, не забываем, да). Но для этого нужно, о ужас, сопоставить несколько фактов. Похоже хабражители это делать разучились.
Статья «Почему не растет частота» прекрасно объясняет почем частоты не увеличились. Вернее так: она даёт всё необходимое для того, чтобы понять почему частоты не увеличились (они, кстати, чуток таки увеличились — Turbo Bust, не забываем, да). Но для этого нужно, о ужас, сопоставить несколько фактов. Похоже хабражители это делать разучились.
Факты? Где факты? Что-то я не увидел в статье таблицы латентности операций и средней частоты их использования в софте (а такие факты однозначно есть в недрах компании Intel).
Таблицы (а они довольно большие для статьи) латентности операций есть в документации по архитектуре. Среднюю частоту использования тех или иных опкодов, вы, извините, и сами посчитать можете, причем даже специфичную для вашего софта, тем более, что «средняя температура по больнице» вряд ли будет представлять практический интерес.
Я думаю, Интел в состоянии сделать массовый проц с частотой 5ГГц, только зачем им это? Сейчас другие тренды — понижение энергопотребления, встроенные видеоядра.
В этом тексте меня смущает один момент: а что, 5-10 лет назад, во время взрывного роста частот, эти проблемы были неактуальны? Да вроде как всё сказанное можно легко оттранслировать во времени назад, во времена микрометровых техпроцессов. Т.е. как раз основной вопрос — что же такого произошло на рубеже в 90 нм — так и не раскрыт.
Если бы всё было так, как вы описываете, то частоты процессоров в определённый момент просто упёрлись бы и перестали расти. Однако этого не происходит: частоты (при том же уровне тепловыделения) растут примерно с той же скоростью, с какой уменьшаются транзисторы (другое дело, что в последнее время с размерами транзисторов всё стало сложнее: они сейчас уменьшаются в размерах медленнее, чем это может показаться если просто сравнивать титулярные нанометры у разных техпроцессов). Статья же объясняет почему раньше частоты могли расти быстрее, чем уменьшались транзисторы.
Эффект, про который вы рассказываете тоже имеет место быть, но он скорее ограничивает частоту одного отдельно взятого процессора, а не рост частоты процессоров при изменении их конструкции.
Эффект, про который вы рассказываете тоже имеет место быть, но он скорее ограничивает частоту одного отдельно взятого процессора, а не рост частоты процессоров при изменении их конструкции.
Что, эти 8 лет отсутствия прогресса — вина проклятого длинного конвеера, о котором нам рассказывают в картинках три экрана?Нет. Отсутствие прогресса в частоте — есть следствие отказа от сверхдлинного конвеера. А вот почему от него отказались — это уже другая история.
Частоты процессров с конвеерами одинаковой длины в последние 8 лет растут так же исправно как и раньше.
А эти вещи — они уже совсем из другой оперы. TDP топового Nehalem'а — 130 ватт, топового Haswell'а — пока что 84 ватта. Это притом, что топовый Nehalem не имел в себе GPU, а Haswell'а без GPU не бывает. С уменьшением техпроцесса «вдвое» тоже не всё так просто: в 45 nm Nehalem'а помещалось 774 миллиона транзисторов на 296mm² (то есть 2.6 миллиона на mm²), а в Haswell'е на 177mm² уместилось 1.4 миллиарда (то есть 7.9 миллиона на mm²), то есть транзисторы уменьшились на вчетверо, а втрое и, соответственно, время срабатывания также возросло не так сильно, как кажется из простого сравнения титульных названий техпроцессов.
Предельно высокая частота не обозначает предельно высокой производительности, а сделав предельно скоростной процессор вам нужно будет придумать кому его продать. Всё-таки Intel не на серверные рынки в основном работает, потому процессор работающий на 5GHz сделал не Intel, а IBM — причём ещё аж на 65 nm. А уже на 45 nm таких частот IBM не предлагал, а вместо этого предложил удвоить-учетверить количество ядер на сокет.
То есть ваши замечания о том, что в последнее время частота растёт гораздо медленнее уменьшения техпроцесса, в общем, справедливы, но они связаны во-многом не с техническими, а с маркетинговыми соображениями: продолжить тренд 90х и создать процессор на 10GHz сейчас, в принципе, не проблема — но он будет одноядерным и будет выделять хорошо за 1000 ватт (не забываем про то, что Pentium работал от 5V и выделял всего-то 16 ватт, что по тем временам было просто-таки «безумно горячо»), так что продать его будет проблематично.
Предельно высокая частота не обозначает предельно высокой производительности, а сделав предельно скоростной процессор вам нужно будет придумать кому его продать. Всё-таки Intel не на серверные рынки в основном работает, потому процессор работающий на 5GHz сделал не Intel, а IBM — причём ещё аж на 65 nm. А уже на 45 nm таких частот IBM не предлагал, а вместо этого предложил удвоить-учетверить количество ядер на сокет.
То есть ваши замечания о том, что в последнее время частота растёт гораздо медленнее уменьшения техпроцесса, в общем, справедливы, но они связаны во-многом не с техническими, а с маркетинговыми соображениями: продолжить тренд 90х и создать процессор на 10GHz сейчас, в принципе, не проблема — но он будет одноядерным и будет выделять хорошо за 1000 ватт (не забываем про то, что Pentium работал от 5V и выделял всего-то 16 ватт, что по тем временам было просто-таки «безумно горячо»), так что продать его будет проблематично.
По поводу x86 и суперскалярности. Все верно: x86 != суперскалярность. Но сейчас все представители семейства суперскалярны (даже Atom с недавних пор обрел это свойство), так что я не стал здесь вдаваться в детали.
Частота P4 не была «отвоевана». Она была завоевана. P4 из-за постоянного реплэя выделял мощность в соответствии со своей частотой, а IPC демонстрировал низкий. Эффективно он работал как процессор с более низкой частотой.
Частота P4 не была «отвоевана». Она была завоевана. P4 из-за постоянного реплэя выделял мощность в соответствии со своей частотой, а IPC демонстрировал низкий. Эффективно он работал как процессор с более низкой частотой.
А при чем тут IPC? Ну более низкий, и что? Речь идет про частоту, а не про IPC…
Мда… Вот что значит писать комменты во втором часу… Atom, конечно же, изначально суперскалярен. Я почему-то держал в голове OOO когда писал коммент. Прошу прощения.
скажу по секрету, «провода» на 32 нм перестали масштабироваться, можно сказать, совсем, а на 22-14 нм и транзисторы не слишком-то уменьшаются по сравнению с предыдущей технологией.
втрое оно только в цифрах нанометров.
втрое оно только в цифрах нанометров.
Вам уже недостаточно в рот еду положить, ещё и разжевать надо? Исходные данные вам даны, запрос в любую поисковую систему даст вам вот эту статью где есть исходные данные:
1989й год: 486й — конвеер в 5 стадий
2004й год: Prescott — конвеер ажно в 31 стадию (32 если считать декодер)
Ну и? Когда там у нас частоты бурно росли? Сходится? Проблема в том, что при таком длинном конвеере весь пар «уходит в свисток»: в Pentium 4 очень много работы совершалось спекулятивно и её результат приходилось выкидывать, а мощности системы охлаждения небесконечны, потому у всех последующих процессоров конвеер находится между этими двумя крайностями (в Nehalem — 16 стадий).
P.S. Был ещё Tejas в котором планировалось не то 40, не то 50 стадий (как и следует из описанного в статье) и его даже вроде довели до матриц, но «выпекать» после фиско Prescott'а не стали ибо было ясно что при осмысленном уровне тепловыделения его производительность будет совсем никакая.
1989й год: 486й — конвеер в 5 стадий
2004й год: Prescott — конвеер ажно в 31 стадию (32 если считать декодер)
Ну и? Когда там у нас частоты бурно росли? Сходится? Проблема в том, что при таком длинном конвеере весь пар «уходит в свисток»: в Pentium 4 очень много работы совершалось спекулятивно и её результат приходилось выкидывать, а мощности системы охлаждения небесконечны, потому у всех последующих процессоров конвеер находится между этими двумя крайностями (в Nehalem — 16 стадий).
P.S. Был ещё Tejas в котором планировалось не то 40, не то 50 стадий (как и следует из описанного в статье) и его даже вроде довели до матриц, но «выпекать» после фиско Prescott'а не стали ибо было ясно что при осмысленном уровне тепловыделения его производительность будет совсем никакая.
> Вам уже недостаточно в рот еду положить, ещё и разжевать надо? Исходные данные вам даны,
^ Идеальный образец сферического русского хамства.
> Ну и? Когда там у нас частоты бурно росли? Сходится?
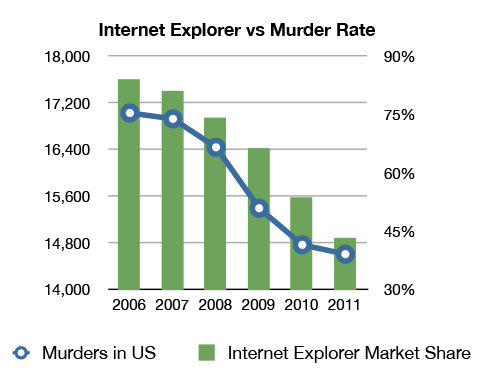
Сделайте вывод из этого графика, пожалуйста.
^ Идеальный образец сферического русского хамства.
> Ну и? Когда там у нас частоты бурно росли? Сходится?
Сделайте вывод из этого графика, пожалуйста.
Сделайте вывод из этого графика, пожалуйста.Недостаточно данных, однако. Подобные графики годятся для проверки теории, но никак не для построения теорий. Где ваша теория, которая свзяывает два наблюдаемых вами феномена? Желательно чтобы она появилась до появления соотвествующего графика, а не после.
> Недостаточно данных, однако.
Ну вам же достаточно данных по количеству ступеней конвейера 486-го и Прескотта, чтобы объяснить феномен отсутствия роста частот процессоров в последние 10 лет.
> Где ваша теория, которая свзяывает два наблюдаемых вами феномена?
Вот: с падением доли IE уменьшилось общее количество агрессии, которую испытывали люди, созерцая глюки и тупняки этого браузера.
Ну вам же достаточно данных по количеству ступеней конвейера 486-го и Прескотта, чтобы объяснить феномен отсутствия роста частот процессоров в последние 10 лет.
> Где ваша теория, которая свзяывает два наблюдаемых вами феномена?
Вот: с падением доли IE уменьшилось общее количество агрессии, которую испытывали люди, созерцая глюки и тупняки этого браузера.
Есть еще такой нюанс, как маркетинг и позиционирование. Некоторые процессоры может и могут работать на бОльших частотах не выбиваясь из теплового пакета, но им по лестнице не положено. Но мало просто нужную частоту задать, нужно сделать оверклокинг не самым простым занятием. Самый простой способ — ограничить множитель. Можно еще вместо пайки кристалла к крышке положить термопасту. Причем не совсем по уму положить. В итоге разгон без «скальпирования» будет упираться в пергрев ядра, хоть кулер и может спокойно справиться с теплоотводом, до него просто не успеет дойти. «Скальпированные» же модели после замены термоинтерфейса спокойно могут показать температуры градусов на 20 ниже, чем при тех же условиях до замены, что на частотном потенциале сказывается крайне благоприятно.
В принципе не велика беда, об этих особенностях все равно знает только небольшая кучка энтузиастов, которые рискуя процессором иногда доводят его до ума. Среди них, кстати, такой подход организации теплоотвода получил довольно емкое название «навоз под крышкой».
Тема в комментах опять превратилась в срач x86 vs ARM, похоже людям важен спор ради спора, а не суть.
Рост частоты ограничен способностью корпуса микросхемы рассеивать тепло. До тех пор, пока это не проблема, как в случае с относительно маленькими кристаллами, частота действительно значительно растет при переходе на техпроцесс с меньшими нормами (при прочих равных условиях)!
Вот циферки для процессора Synopsys ARC EM6 из официального даташита (http://www.synopsys.com/dw/doc.php/ds/cc/arc_em6.pdf), конфигурация процессора идентичная:
65LP (Low Power): 350 МГц
40LP: 540 МГц
28HP: 900 МГц
Этот процессор на 65-нм процессе занимает 0,04 мм2 и рассеивает 5 мВт. Очевидно, что такое мизерное тепловыделение никак не ограничивает рост частоты.
В случае, когда кристалл значительно большего размера, именно тепловыделение играет решающую роль. Микросхема, изготовленная по техпроцессу 40LP с кристаллом площадью примерно 10 мм2, засунутым в пластиковый корпус размером 15х15мм, может работать без радиатора на 400 МГц. На 700 МГц ей нужен радиатор, и он уже весьма теплый.
Что происходит, когда у вас кристалл в районе 100 мм2, работающий на частоте за 2 ГГц, можете догадаться сами. Поэтому частоту повышают на столько, сколько может выдержать корпус.
Так что стадии конвейера тут не при чем. Мало того, имхо, именно проблемы с тепловыделением позволили вернуть длину конвейера к приличным значениям наперекор маркетологам.
Вот циферки для процессора Synopsys ARC EM6 из официального даташита (http://www.synopsys.com/dw/doc.php/ds/cc/arc_em6.pdf), конфигурация процессора идентичная:
65LP (Low Power): 350 МГц
40LP: 540 МГц
28HP: 900 МГц
Этот процессор на 65-нм процессе занимает 0,04 мм2 и рассеивает 5 мВт. Очевидно, что такое мизерное тепловыделение никак не ограничивает рост частоты.
В случае, когда кристалл значительно большего размера, именно тепловыделение играет решающую роль. Микросхема, изготовленная по техпроцессу 40LP с кристаллом площадью примерно 10 мм2, засунутым в пластиковый корпус размером 15х15мм, может работать без радиатора на 400 МГц. На 700 МГц ей нужен радиатор, и он уже весьма теплый.
Что происходит, когда у вас кристалл в районе 100 мм2, работающий на частоте за 2 ГГц, можете догадаться сами. Поэтому частоту повышают на столько, сколько может выдержать корпус.
Так что стадии конвейера тут не при чем. Мало того, имхо, именно проблемы с тепловыделением позволили вернуть длину конвейера к приличным значениям наперекор маркетологам.
Наверное, не совсем корректно сравнивать Low Power процессы c 28HP, поэтому вот данные по «быстрым» процессам из того же документа:
— 90GP: 420 МГц (90нм — это как раз времена позднего Pentium 4)
— 40GP: 770 МГц
То есть только за счет перехода с 40 нм на 28 нм увеличение частоты составляет 16%.
А вот данные по интеловским процам с одинаковой архитектурой (Nehalem/Westmere) и сопоставимыми техпроцессами (брал самую высокую частоту отсюда: en.wikipedia.org/wiki/List_of_Intel_Core_i7_microprocessors):
45 нм: 3,33 ГГц
32 нм: 3,47 ГГц (+4%)
— 90GP: 420 МГц (90нм — это как раз времена позднего Pentium 4)
— 40GP: 770 МГц
То есть только за счет перехода с 40 нм на 28 нм увеличение частоты составляет 16%.
А вот данные по интеловским процам с одинаковой архитектурой (Nehalem/Westmere) и сопоставимыми техпроцессами (брал самую высокую частоту отсюда: en.wikipedia.org/wiki/List_of_Intel_Core_i7_microprocessors):
45 нм: 3,33 ГГц
32 нм: 3,47 ГГц (+4%)
Ну и напоследок, увеличение частоты при переходе с 65 нм на 40/45нм:
У Интела (Conroe/Wolfsdale: http://en.wikipedia.org/wiki/Core_(microarchitecture) ): 3 ГГц -> 3,33 ГГц (+11%)
У ARC EM6: 350 МГц -> 540 МГц (+54%)
У Интела (Conroe/Wolfsdale: http://en.wikipedia.org/wiki/Core_(microarchitecture) ): 3 ГГц -> 3,33 ГГц (+11%)
У ARC EM6: 350 МГц -> 540 МГц (+54%)
Я только одного не понял.
Если, не смотря на то, что Core i7-4770K промаркирован на 3.5 ГГц, после замены термоинтерфейса, на воздухе и без поднятия напряжения гонится до 4500 ГГц, то что мешает от 150-200$ продавать процессоры порядка 4 ГГц?
По-моему очевидно, что технология отработана и готова.
А тезис про маркировку процессоров в 95% от их максимума не имеет отношения к реальности и служит оправданием преднамеренного занижения возможностей процессоров.
Если, не смотря на то, что Core i7-4770K промаркирован на 3.5 ГГц, после замены термоинтерфейса, на воздухе и без поднятия напряжения гонится до 4500 ГГц, то что мешает от 150-200$ продавать процессоры порядка 4 ГГц?
По-моему очевидно, что технология отработана и готова.
А тезис про маркировку процессоров в 95% от их максимума не имеет отношения к реальности и служит оправданием преднамеренного занижения возможностей процессоров.
что мешает от 150-200$ продавать процессоры порядка 4 ГГц?
Тот факт, что можно продавать за $300 камни на 3.5ггц, и уже даже тут конкурентов нет.
Кто хочет получить 4,5ггц и выше — не вопрос. Палки в колеса никто не сует (ну кроме термокаки под крышкой вместо православного припоя — это тоже объяснимо, так как старые камни в руках оверклокеров конкурируют с новыми, и потому оверклокер не так часто покупает новый камень).
Intel — коммерческая компания. Цель — не обеспечить каждого жителя планеты максимальным числом гигагерц, а заработать денег. А стоимость товара определяется в первую очередь не себестоимостью его производства, а тем, за сколько его готовы купить.
Не совсем понимаю, о каких выводах, «сделанных в топике», вы говорите.
В статье предлагается определенная точка зрения на проблему: частоту можно поднять, только уменьшив длину стадии. Иначе никак. Стадия обязана влезать в такт.
Каким образом уменьшать длину стадии — вопрос сложный и многогранный. Вы хотите зайти со стороны техпроцесса, как я понимаю.
Давайте зайдем со стороны техпроцесса. Никаких противоречий я здесь не вижу. Мы реально наблюдаем рост частоты при совершенствовании техпроцесса (при условии, что этот рост не разменивается на лучшую энергоэффективность; сейчас тенденции таковы, что в low-end и middle-сегментах такой размен может быть выгоден из-за того, что производительность там не очень интересна).
Теперь про вашу ссылку. Автор там делает то же самое, что и вы, — сравнивает несравнимое, т.е. ставит в один ряд принципиально разные микроархитектуры. Нельзя ставить в один ряд, например, процессоры семейства P4 и процессоры семейства Core, а затем сравнивать их исключительно с позиции техпроцесса.
По-хорошему, P4 с микронным процессом нужно сравнивать с P4 с нанометровым процессом (если бы такой был). При таком сравнении мы бы увидели приличный рост частоты (+ примерно линейный рост мощности + по-прежнему бестолковый IPC).
В скопированных вами сюда рассуждениях автор явно путает помехи (это то, что искажает фронт сигнала) с тепловыделением…
В статье предлагается определенная точка зрения на проблему: частоту можно поднять, только уменьшив длину стадии. Иначе никак. Стадия обязана влезать в такт.
Каким образом уменьшать длину стадии — вопрос сложный и многогранный. Вы хотите зайти со стороны техпроцесса, как я понимаю.
Давайте зайдем со стороны техпроцесса. Никаких противоречий я здесь не вижу. Мы реально наблюдаем рост частоты при совершенствовании техпроцесса (при условии, что этот рост не разменивается на лучшую энергоэффективность; сейчас тенденции таковы, что в low-end и middle-сегментах такой размен может быть выгоден из-за того, что производительность там не очень интересна).
Теперь про вашу ссылку. Автор там делает то же самое, что и вы, — сравнивает несравнимое, т.е. ставит в один ряд принципиально разные микроархитектуры. Нельзя ставить в один ряд, например, процессоры семейства P4 и процессоры семейства Core, а затем сравнивать их исключительно с позиции техпроцесса.
По-хорошему, P4 с микронным процессом нужно сравнивать с P4 с нанометровым процессом (если бы такой был). При таком сравнении мы бы увидели приличный рост частоты (+ примерно линейный рост мощности + по-прежнему бестолковый IPC).
В скопированных вами сюда рассуждениях автор явно путает помехи (это то, что искажает фронт сигнала) с тепловыделением…
Почему латентность инструкции MOVNTI растет с каждой новой архитектурой, при этом частота процессоров не изменяется?
Потому что на одну и ту же память вешается всё больше потребителей. Скорость работы movnti вообще никак с частотой процессора не связана.
Контроллер памяти в SB, IB, HW работает на частоте ядра. Точно не связана?
Абсолютно. Я даже не знаю как можно процессорные технологии обсуждать с человеком, который этого не понимает.
Как связана мощность двигателя локомотива со временем доставки почты на поезде ведомым оном локомотиве из Москвы во Владивосток? Да никак не связана: всё определяется длиной железной дороги и ограничением скорости на ней. Вот количество почты, которое вы можете доставить — да, связано, чем мощнее локомотив тем больше можно на него поцепить вагонов. А скорость — ну никак. Если заставите ваш поезд по дороге заехать в Одессу (==прогоните данные через дополнительный модуль) будет медленнее, спрямите дорогу — быстрее, но от замены локомотива скорость вообще никак не зависит.
То же самое и тут: основные задержки вносятся просто-напросто динамической памятью (скорость работы которой прекратила расти ещё в конце XX века), ещё что-то отбирают контроллеры между памятью и процессором, скорость же самого процессора влияет на этот параметр настолько слабо, что и говорить, в общем, не о чем.
Как связана мощность двигателя локомотива со временем доставки почты на поезде ведомым оном локомотиве из Москвы во Владивосток? Да никак не связана: всё определяется длиной железной дороги и ограничением скорости на ней. Вот количество почты, которое вы можете доставить — да, связано, чем мощнее локомотив тем больше можно на него поцепить вагонов. А скорость — ну никак. Если заставите ваш поезд по дороге заехать в Одессу (==прогоните данные через дополнительный модуль) будет медленнее, спрямите дорогу — быстрее, но от замены локомотива скорость вообще никак не зависит.
То же самое и тут: основные задержки вносятся просто-напросто динамической памятью (скорость работы которой прекратила расти ещё в конце XX века), ещё что-то отбирают контроллеры между памятью и процессором, скорость же самого процессора влияет на этот параметр настолько слабо, что и говорить, в общем, не о чем.
А вот я и ошибся. Частота контроллера памяти не связана с частотой процессора, а тактуется отдельно. Итак, инструкция MOVNTI, попадая на 4й порт (store data), потом отправляется по кольцевой шине Агенту, который отправляет данные через IMC в память. Ядра, шина и контроллер памяти в последних процессорах Intel имеют свою частоту работы, поэтому на каждом из этапов могут возникать задержки синхронизации. Бенчмарки показывают, что пропускная способность памяти растет с увеличением частоты ядер. Это может говорить о том, что уменьшается лаг синхронизации сигналов между отдельными частями CPU, достигая тем самым более высокой производительности записи данных в память.
1) Под «помехами» автор понимает именно помехи. С ростом частоты, спектральный состав помех изменяется. Факт! На помехи расходуется мощность. Факт!
Дальше автор, видимо, пытается связать мощность помех с нагревом МП. Такая связь, очевидно, есть. В самых ужасных случаях до 10-20% полной мощности может уйти в помехи (т.е. 10-20% процентов нагрева происходит по вине помех).
Дальше я могу только задать вопрос: и что?
Самое страшное в помехах не то, что они греют процессор, а то, что из-за них деградирует сигнал.
И это проблема.
Но я все еще не понимаю, с чем именно вы спорите.
Нагрев МП — проблема. Деградирование фронта — проблема. Никто с этим не спорит. Куча других проблем еще есть.
Может, вы хотите сказать, что существует какое-то принципиальное ограничение на частоту МП, которое лежит в районе 3.8ГГц? Но ведь это не так. Даже оверклокеры гонят частоту до 8ГГц.
Поясните, пожалуйста, что вы хотите доказать.
2) Разгонять P4 дальше никакого смысла не было. Это был утюг с производительностью калькулятора. Успехи в области техпроцесса шли не на разгон, а на снижение мощности.
Дальше автор, видимо, пытается связать мощность помех с нагревом МП. Такая связь, очевидно, есть. В самых ужасных случаях до 10-20% полной мощности может уйти в помехи (т.е. 10-20% процентов нагрева происходит по вине помех).
Дальше я могу только задать вопрос: и что?
Самое страшное в помехах не то, что они греют процессор, а то, что из-за них деградирует сигнал.
И это проблема.
Но я все еще не понимаю, с чем именно вы спорите.
Нагрев МП — проблема. Деградирование фронта — проблема. Никто с этим не спорит. Куча других проблем еще есть.
Может, вы хотите сказать, что существует какое-то принципиальное ограничение на частоту МП, которое лежит в районе 3.8ГГц? Но ведь это не так. Даже оверклокеры гонят частоту до 8ГГц.
Поясните, пожалуйста, что вы хотите доказать.
2) Разгонять P4 дальше никакого смысла не было. Это был утюг с производительностью калькулятора. Успехи в области техпроцесса шли не на разгон, а на снижение мощности.
Еще вопрос, что именно вы называете стадией? Многие инструкции выполняются около 20 тактов (AAM, DIV, FDIV, FPREM, FSQRT и т.д), некоторые около 400 (MOVNTQ, MOVNTDQ, VMOVNTDQ), и однотактовых инструкций довольно таки мало (около четверти).
Интел схожего мнения с вашим автором. На Хабре уже есть статьи где достаточно качественно расписано:
Жизнь в эпоху «тёмного» кремния. Часть 1
Жизнь в эпоху «тёмного» кремния. Часть 2
Жизнь в эпоху «тёмного» кремния. Часть 2,
в моём коментарии ниже есть ссылки.
А статья автора, графоманство человека, который пропустил курс «Компьютерной архитектуры»
Жизнь в эпоху «тёмного» кремния. Часть 1
Жизнь в эпоху «тёмного» кремния. Часть 2
Жизнь в эпоху «тёмного» кремния. Часть 2,
в моём коментарии ниже есть ссылки.
А статья автора, графоманство человека, который пропустил курс «Компьютерной архитектуры»
Автор, скажите, а Turbo Boost в mac — компьютерах работает именно увеличением напряжения и охлаждения?
Рискно набрать минусов, но для любого кто хоть как-то слушал курсы микропроцессорной архитектуры и электроники начало статьи полный бред.
Длительность выполнения части/инструкции не меряется во времени, а меряется в тактах процессора. Ничего в процесоре синхронизированного с тактами генератора не происходит(за исключением советских асинхронных архитектур, которые канули в лету).
Дальше уже можно не читать, потому что ваши предположения построены на полностью ложных предпосылках. Читайте лучше Хеннеси и Патерсона, Computer Architecture, Fifth Edition: A Quantitative Approach John L. Hennessy (Author), David A. Patterson (Author). На компьютерной инженерии рассказывают примерно на третьем курсе.
Есть разные стадии конвейера, выборка, декодирование, исполнение и т. д. каждая в разных архитектурах занимает определенное количество тактов. И если вы откроете руководство разработчика про архитектуре х86 от Интел или АМД вы также не увидите времени исполнения инструкций, а увидите количество тактов.
Если говорить точнее почему не увеличивается частота, лучше чем Интел я не напишу наверное:
И на хабре было несколько статтей от Интела о «тёмном кремнии»
Жизнь в эпоху «тёмного» кремния. Часть 1
Жизнь в эпоху «тёмного» кремния. Часть 2
Жизнь в эпоху «тёмного» кремния. Часть 2
где упоминается закон Деннарда, а также любимый вопрос экзаменационных билетов закон Амдала.
А также нужно упомянуть о росте тока утечки при росте частоты и о том что размеры элементов настолько малые по сравнению с скоростью распространения сигнала кристалла и длиной шин что для нужно добавлять синхронизирующие элементы которые дополнительно усложняют схему(где то видел цыфры, что для интел уже более 10% кристала) и ограничивают рост частоты(разработчики на больших FPGA стыкаются достаточно часто на больших чатотах).
Длительность выполнения части/инструкции не меряется во времени, а меряется в тактах процессора. Ничего в процесоре синхронизированного с тактами генератора не происходит(за исключением советских асинхронных архитектур, которые канули в лету).
Дальше уже можно не читать, потому что ваши предположения построены на полностью ложных предпосылках. Читайте лучше Хеннеси и Патерсона, Computer Architecture, Fifth Edition: A Quantitative Approach John L. Hennessy (Author), David A. Patterson (Author). На компьютерной инженерии рассказывают примерно на третьем курсе.
Есть разные стадии конвейера, выборка, декодирование, исполнение и т. д. каждая в разных архитектурах занимает определенное количество тактов. И если вы откроете руководство разработчика про архитектуре х86 от Интел или АМД вы также не увидите времени исполнения инструкций, а увидите количество тактов.
Если говорить точнее почему не увеличивается частота, лучше чем Интел я не напишу наверное:
И на хабре было несколько статтей от Интела о «тёмном кремнии»
Жизнь в эпоху «тёмного» кремния. Часть 1
Жизнь в эпоху «тёмного» кремния. Часть 2
Жизнь в эпоху «тёмного» кремния. Часть 2
где упоминается закон Деннарда, а также любимый вопрос экзаменационных билетов закон Амдала.
А также нужно упомянуть о росте тока утечки при росте частоты и о том что размеры элементов настолько малые по сравнению с скоростью распространения сигнала кристалла и длиной шин что для нужно добавлять синхронизирующие элементы которые дополнительно усложняют схему(где то видел цыфры, что для интел уже более 10% кристала) и ограничивают рост частоты(разработчики на больших FPGA стыкаются достаточно часто на больших чатотах).
Кстати IBM Power4 серийные образцы на 5 ГГц работают, вот только это несколько иное ядро и средняя вычислительная мощность иструкции архитектуры Power иная чем у x86.
x86 — виртуальный набор команд (в том смысле, что аппаратных цепей, реализующих эти команды, нет), который транслируется в микрокоманды, иногда несколько микрокоманд (отсюда число тактов), в редких случаях (пишу для зануд) несколько x86 команд транслируются в одну микрокоманду. в статье речь о микрокомандах
А какая разница? Разве я написал иначе? Микрокоманды prefecth, decoding, execution их распаралеливают на конвеере. Длина каждой микрокоманды измеряется в количестве тактов, а не времени, именно по тактам синхронизируют задержки от разных блоков. У современных чипов плавающая частота, соответственно каждая стадия может занять разное время, но в общем случае та же самая стадия для одной и той же команды занимает разное время на разной частоте но тоже количество тактов. Об это я говорил, привязка к времени это полная безграмотность. Закон что производительность системы ограничена самым медленным элементом, Закон Амдала, который учат третьекурсники компьютерной архитектуры.
Посмотрите статьи Интела что я привёл. Куча ссылок, список литературы.
А здесь куча противоречивых и ложных утверждений и мешанина фактов и выдумок, зато вроде бы написано по простецки.
Посмотрите статьи Интела что я привёл. Куча ссылок, список литературы.
А здесь куча противоречивых и ложных утверждений и мешанина фактов и выдумок, зато вроде бы написано по простецки.
Ага, кажется я понял о чем вы…
наверное в статье привязка ко времени идет в ключе «минимальное время, за которое эта микрокоманда может выполниться на текущей элементной базе»
вы же утверждаете, что физических ограничений подобного нет, и частота ограничена отводимым теплом
кстати это статья тоже из блога Интел, написана их же сотрудниками… может из-за этого вас негативно оценили
наверное в статье привязка ко времени идет в ключе «минимальное время, за которое эта микрокоманда может выполниться на текущей элементной базе»
вы же утверждаете, что физических ограничений подобного нет, и частота ограничена отводимым теплом
кстати это статья тоже из блога Интел, написана их же сотрудниками… может из-за этого вас негативно оценили
Я не утверждаю что физических ограничений нет они есть но не они есть главной причиной отсутствия роста частоты. Для того чтобы не было проблем с задержкой сигналов ставят специальную логику, да она занимает площадь кристала, но это решабельно.
Чтобы не было проблем с самой длинной стадией один из подходов был дробить далее конвейер на более мелкие, что мы увидели в Пентиум-4, который имел наверное самый длинный конвейер, тогда можна было увеличивать частоту, но возникает много проблем, от проблемы заполнености конвеера, до самой главной, как отводить тепло. Радиатор Пентиум 4 был очень большим и притом всё одно сильно грелся.
То что статья написана интел разве что-то значит? Это не маркетинговая статья, причем с ссылками на научные работы, а у автора статья из разряда «они скрывают», а я вот умный закон Амдала сам вывел и нашел решение над которым бьются лучшие умы.
Мне не понравилось что в статье очень много неточностей и просто неграмотных выводов которым учат студентов 3-го курса.
Чтобы не было проблем с самой длинной стадией один из подходов был дробить далее конвейер на более мелкие, что мы увидели в Пентиум-4, который имел наверное самый длинный конвейер, тогда можна было увеличивать частоту, но возникает много проблем, от проблемы заполнености конвеера, до самой главной, как отводить тепло. Радиатор Пентиум 4 был очень большим и притом всё одно сильно грелся.
То что статья написана интел разве что-то значит? Это не маркетинговая статья, причем с ссылками на научные работы, а у автора статья из разряда «они скрывают», а я вот умный закон Амдала сам вывел и нашел решение над которым бьются лучшие умы.
Мне не понравилось что в статье очень много неточностей и просто неграмотных выводов которым учат студентов 3-го курса.
О, да прям? транзисторы теперь переключаются мгновенно? Логические вентили пропускают сигнал через себя мгновенно? Классический АЛУ — обычное сложение двух чисел — это логическая схема в которой сигнал на выходе появится через некоторое время после того как поданы на вход операнды. НЕ РАНЬШЕ. И если частота тактов будет больше, процессор будет просто простаивать все то время пока сигнал не пройдет все АЛУ от входа до выхода.
Читайте моё замечание от линиях задержки в конце. Но это не есть главным ограничителем частоты, по крайней мере пока. Если делать блоки локализироваными без длинных линий, то в пределах этого блока существенных проблем не возникает. Дальше нужно синхронизировать блоки. Для этого ставят схемы синхронизации, в самом простом случае регистр защёлка.
Если бы проблема была бы исключительно в линиях задержек то поднятие частоты не давало бы ничего, так что вы сами себе отрицаете, а ведь рост производительности есть. Но отчего-то оверлокерам нужен жидкий азот, чтобы получить большую частоту. Значит проблема с отводимой мощностью.
Ну и перечитайте статьи интел и прекратите нести чушь.
Если бы проблема была бы исключительно в линиях задержек то поднятие частоты не давало бы ничего, так что вы сами себе отрицаете, а ведь рост производительности есть. Но отчего-то оверлокерам нужен жидкий азот, чтобы получить большую частоту. Значит проблема с отводимой мощностью.
Ну и перечитайте статьи интел и прекратите нести чушь.
Опечатался «Ничего в процесоре не синхронизированного с тактами генератора не происходит(за исключением советских асинхронных архитектур, которые канули в лету).»
Странно… Минусов вам так и не налепили…
Длительность можно измерять хоть в попугаях, если это будет удобно. Но при выборе частоты речь должна идти именно об астрономическом времени. Потому что длина такта выбирается на основе времени работы логических устройств, а не наоборот.
Представьте себе процессор, который должен уметь выполнять одну-единственную операцию. Например, логическое «И». Такой процессор будет состоять из транзистора и нескольких проводов. Задержки транзистора и проводов фиксированы. Повлиять на них могут только внешние условия, вроде влажности и температуры.
Длина такта для такого «компьютера» будет выбрана так, чтобы в него уместилось время работы элемента + некоторый допуск на внешние условия.
Так первичны абслютные времянки, а не такты…
Длительность можно измерять хоть в попугаях, если это будет удобно. Но при выборе частоты речь должна идти именно об астрономическом времени. Потому что длина такта выбирается на основе времени работы логических устройств, а не наоборот.
Представьте себе процессор, который должен уметь выполнять одну-единственную операцию. Например, логическое «И». Такой процессор будет состоять из транзистора и нескольких проводов. Задержки транзистора и проводов фиксированы. Повлиять на них могут только внешние условия, вроде влажности и температуры.
Длина такта для такого «компьютера» будет выбрана так, чтобы в него уместилось время работы элемента + некоторый допуск на внешние условия.
Так первичны абслютные времянки, а не такты…
Боюсь у нас приципиальное расхождение в понимании. Вся существующая серийная техника синхронная. Она тактируется частотой тактового генератора(если упрощённо, потому что ещё есть делители и множители). Ничего несинхронизированого с тактами не происходит, точнее происходят какие-то переходные процессы, но фиксируется конечное состояние именно в момент тактирования, чаще всего по фронту, иногда по спаду, или по тому и по тому.
Допустим что вы правы и транзистор вносит задержку в распространении сигнала на один такт.
Теперь допустив что для схемы есть два пути для прохождения сигнала, один через 5 транзисторов, другой через 3. Выход результата нужно как-то синхронизировать, что ж нет проблем мы тактируем регистр защелку чтобы он открыл запись условно для пути 1 не третьем такте, для другого на 5-ом и условно на 5-ом выпустил результат. Но вот чего вы не понимаете, так того что вся схема работает паралельно. Это конвейер который каждый такт даст что-то на выход, пусть выход и будет холостой. На пятом такте специальная сигнальна линия выдаст единицу как сигнал что результат готов. Это в самом примитивном и сильно упрощённом виде. Потому время иссполняют инструкции измеряют в тактах.
Дальше идём от теории к практике, частота переключения транзистора
en.wikipedia.org/wiki/Field-effect_transistor
Давайте вспомним что у интела техпроцес на 2011- был уже 22 нано метра, download.intel.com/newsroom/kits/22nm/pdfs/22nm-Details_Presentation.pdf При текущей частоте в 5 ГГЦ, можно переключить одновременно не менее 5 транзисторов, насколько помню курс электроники одна ячейка хранения данных статической памяти строится на 3-х транзисторах (а в реальности я уверен переключить можно даже больше транзисторов, так как рабочее напряжение у интел ниже, к сожалению Интел не привела значений маштаба графиков), а ведь сейчас тех процесс меньше, и рабочая частота ниже(3,4ГГц максимум обычно). Я мог бы приводить более детальные формулы, но честно говоря не вижу смысла тратить время, на повторение университетских учебников электроники и микропроцессорной техники. Чтобы устранить задержку сигнала интел встраивает также синхронизирующие схемы, это уже другая история.
Потому задержки времени на прохождение сигнала в пределах одного транзистора всё еще недостаточно существенны в пределах существующих частот(как минимум до 5ГГц).
Идём дальше. Университетский курс цифровой электроники en.wikipedia.org/wiki/CMOS
Скролим к секции Power: switching and leakage. Charging and discharging of load capacitances.
Берём формулу, подставляем пусть даже несколько сот миллионов активных транзисторов(а в современном чипе их милиарды) и думаем как отвести эти десятки ватов тепла с площади несколько десятков миллиметров квадратных. Видим что зависимость от частоты линейная. Как Интел с этим борется. Понижает частоту, понижает рабочее напряжение(очень важно, потому что зависимость от напряжения квадратичная), а также уменьшает альфа, коэффициент задействованы транзисторов через отключение работающих блоков(это в статьях интел о тёмном кремнии). Потолок который научились отводить в воздушном охлаждении примерно 150 Ват, при очень мощной турбине и радиаторе. А мы все ведь хоти очень тихий ПК, который умещается в ладони и чтобы работал от батарейки целый день? Какой здесь выход у производителей?
Повышение частоты даёт линейное повышение потребления энергии.
Та же статья от Интел о 22 нм техпроцесе:
Почему мне не понравилась ваша статья, как вопрос в разделе вопросы она могла бы существовать. Но она написана в стиле разоблачения с неграмотными утверждениями. Тут же нашлось много людей, любителей «теорий заговора» которые заплюсовали и пошла гулять «новая истина» что «кошки разносят чуму». Потом читают студенты и выдают за истину в последней инстанции. Хотя даже достаточно поверхностные статьи википедии о транзисторах могут развеять сомнения.
Допустим что вы правы и транзистор вносит задержку в распространении сигнала на один такт.
Теперь допустив что для схемы есть два пути для прохождения сигнала, один через 5 транзисторов, другой через 3. Выход результата нужно как-то синхронизировать, что ж нет проблем мы тактируем регистр защелку чтобы он открыл запись условно для пути 1 не третьем такте, для другого на 5-ом и условно на 5-ом выпустил результат. Но вот чего вы не понимаете, так того что вся схема работает паралельно. Это конвейер который каждый такт даст что-то на выход, пусть выход и будет холостой. На пятом такте специальная сигнальна линия выдаст единицу как сигнал что результат готов. Это в самом примитивном и сильно упрощённом виде. Потому время иссполняют инструкции измеряют в тактах.
Дальше идём от теории к практике, частота переключения транзистора
en.wikipedia.org/wiki/Field-effect_transistor
A gate length of 1 µm limits the upper frequency to about 5 GHz, 0.2 µm to about 30 GHz.
Давайте вспомним что у интела техпроцес на 2011- был уже 22 нано метра, download.intel.com/newsroom/kits/22nm/pdfs/22nm-Details_Presentation.pdf При текущей частоте в 5 ГГЦ, можно переключить одновременно не менее 5 транзисторов, насколько помню курс электроники одна ячейка хранения данных статической памяти строится на 3-х транзисторах (а в реальности я уверен переключить можно даже больше транзисторов, так как рабочее напряжение у интел ниже, к сожалению Интел не привела значений маштаба графиков), а ведь сейчас тех процесс меньше, и рабочая частота ниже(3,4ГГц максимум обычно). Я мог бы приводить более детальные формулы, но честно говоря не вижу смысла тратить время, на повторение университетских учебников электроники и микропроцессорной техники. Чтобы устранить задержку сигнала интел встраивает также синхронизирующие схемы, это уже другая история.
Потому задержки времени на прохождение сигнала в пределах одного транзистора всё еще недостаточно существенны в пределах существующих частот(как минимум до 5ГГц).
Идём дальше. Университетский курс цифровой электроники en.wikipedia.org/wiki/CMOS
Скролим к секции Power: switching and leakage. Charging and discharging of load capacitances.
Берём формулу, подставляем пусть даже несколько сот миллионов активных транзисторов(а в современном чипе их милиарды) и думаем как отвести эти десятки ватов тепла с площади несколько десятков миллиметров квадратных. Видим что зависимость от частоты линейная. Как Интел с этим борется. Понижает частоту, понижает рабочее напряжение(очень важно, потому что зависимость от напряжения квадратичная), а также уменьшает альфа, коэффициент задействованы транзисторов через отключение работающих блоков(это в статьях интел о тёмном кремнии). Потолок который научились отводить в воздушном охлаждении примерно 150 Ват, при очень мощной турбине и радиаторе. А мы все ведь хоти очень тихий ПК, который умещается в ладони и чтобы работал от батарейки целый день? Какой здесь выход у производителей?
Повышение частоты даёт линейное повышение потребления энергии.
Та же статья от Интел о 22 нм техпроцесе:
While higher frequency is great for improving CPU performance, it is not always the best choice. For example, GPUs tend to rely on a huge number of more efficient transistors and run about 2-4X slower than a CPU. For scenarios where active power is most critical, the 22nm process can keep the same frequency but lower the operating voltage (e.g. from 1V to 0.8V). Active power falls even faster since P ~ F * V2 and Intel claims 50% less power, so the voltage reduction may be slightly larger in some circumstance. Similarly, transistors could use this headroom to significantly lower leakage power for always-on circuits, instead of changing frequency or active power. While Intel did not cite any specific numbers, it seems likely that an improvement of 1-2 orders of magnitude is realistic given the exponential relationship between leakage and drive currents.
Почему мне не понравилась ваша статья, как вопрос в разделе вопросы она могла бы существовать. Но она написана в стиле разоблачения с неграмотными утверждениями. Тут же нашлось много людей, любителей «теорий заговора» которые заплюсовали и пошла гулять «новая истина» что «кошки разносят чуму». Потом читают студенты и выдают за истину в последней инстанции. Хотя даже достаточно поверхностные статьи википедии о транзисторах могут развеять сомнения.
Ни одного упоминания OpenMP, MPI…


{kind=link}
Почему бы не продублировать третье вычислительное устройство? Тогда можно сделать частоту вдвое большей при увеличении размера процессора всего на 25%.
То есть на нижней картинке не будет простоя. Инструкции 1 и 2 запускаются вдвое быстрее, а инструкция 3 обрабатывается то на одном, то на втором вычислительном устройстве.
Иногда так и делают. Но нужно понимать, что обычно самая длинная стадия так или иначе связана с доступом в память (к кэшам, например). По понятным причинам целиком продублировать память далеко не так же просто, как обычное вычислительное устройство типа АЛУ. Поэтому обычно ее начинают делить на банки с незваисимым доступом, делают доступ к каждому банку за несколько тактов в расчете на то, что последовательный доступ обычно не потребует двух подряд обращений к одному и тому же банку, делают широкую память, которая может работать во столько раз медленнее, во сколько она шире, и т.д.
В любом случае, современные процессоры оптимизированы по максимуму и все столь очевидные решения там уже давно добавлены.
В любом случае, современные процессоры оптимизированы по максимуму и все столь очевидные решения там уже давно добавлены.
Sign up to leave a comment.
Почему не растет частота?