DDoS attacks send ripples on the ocean of the Internet, produced by creations of various sizes - botnets. Some of them feed at the top of the ocean, but there also exists a category of huge, deep water monstrosities that are rare and dangerous enough they could be seen only once in a very long time.
November 2021 we encountered, and mitigated, several attacks from a botnet, that seems to be unrelated to one described and/or well-known, like variants of Mirai, Bashlite, Hajime or Brickerbot.
Although our findings are reminiscent of Mirai, we suppose this botnet is not based purely on propagating Linux malware, but a combination of brute forcing and exploiting already patched CVEs in unpatched devices to grow the size of it. Either way, to confirm how exactly this botnet operates, we need to have a sample device to analyze, which isn’t our area of expertise.
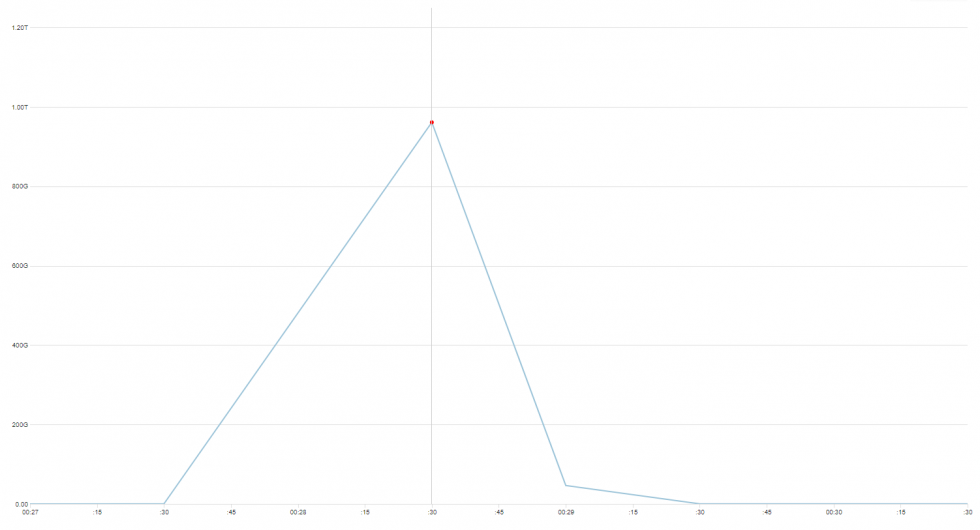
This time, we won’t give it a name. It is not 100% clear what we are looking at, what are the exact characteristics of it, and how big this thing actually is. But there are some numbers, and where possible, we have made additional reconnaissance in order to better understand what we’re dealing with.
But let us first show you the data we’ve gathered, and leave conclusions closer to the end of this post.