
Объясняем код с помощью ASCII-арта
2 мин
Перевод
Примечание от переводчика: типично пятничная статья во вторник утром… почему бы и нет?
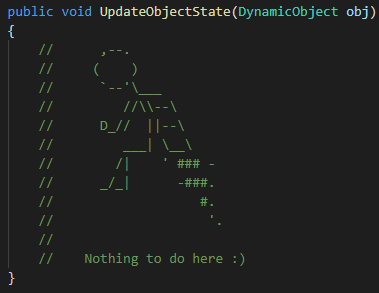
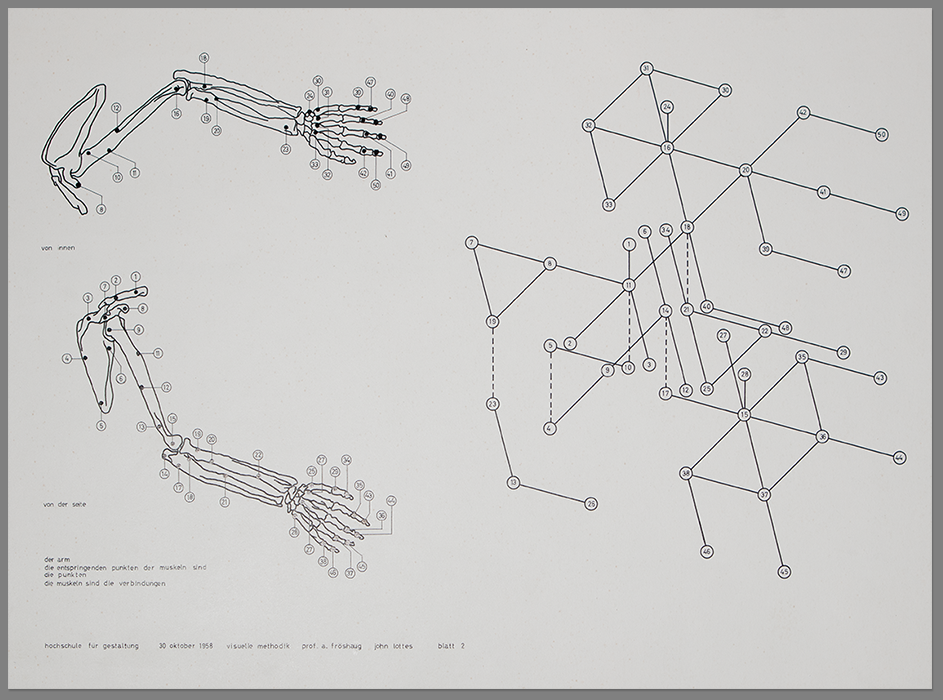
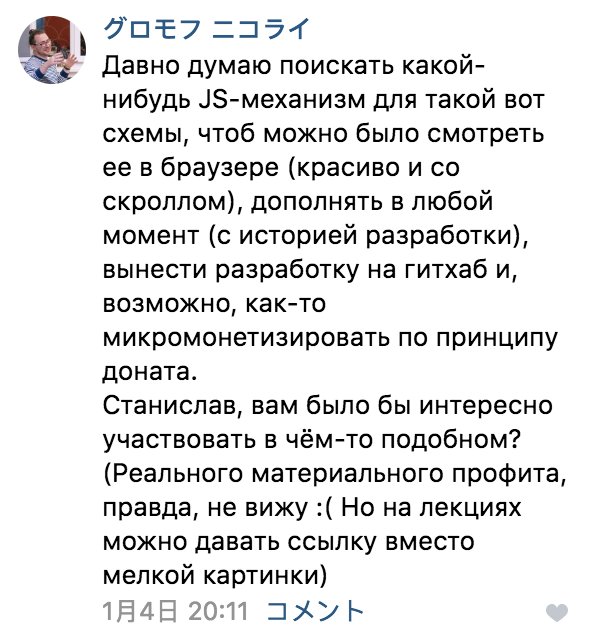
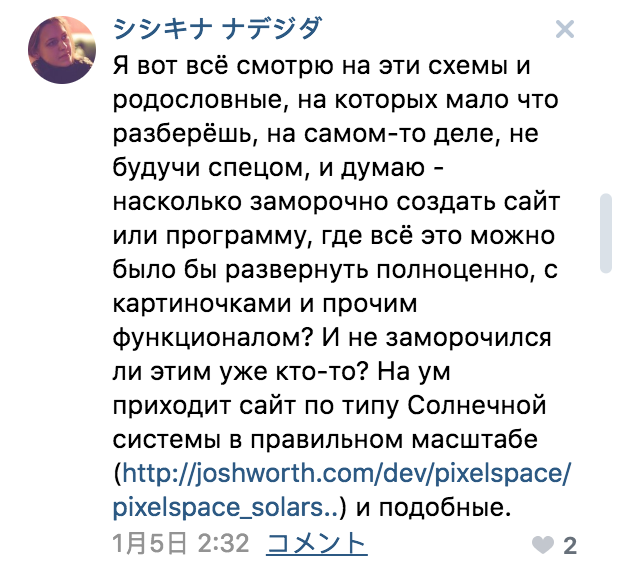
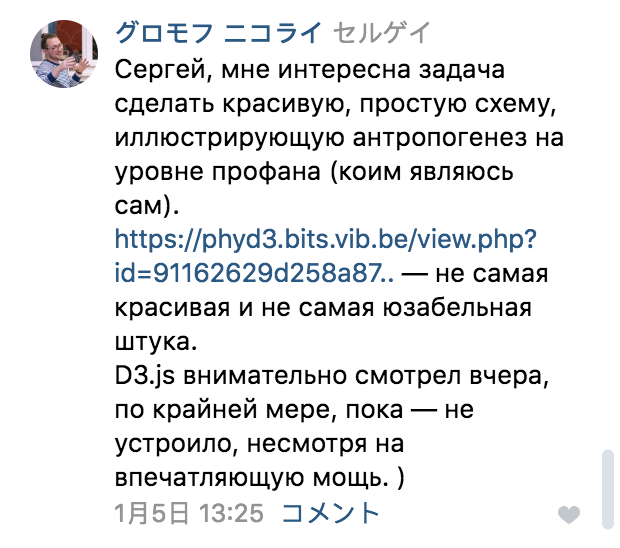
Большинство людей — визуалы. Они используют изображения, чтобы вникнуть в суть проблемы. А вот мэйнстримные языки программирования, напротив, основаны на текстовом представлении. Возникающую пропасть между текстом и графикой заполняют ASCII-изображения, нарисованные с помощью текстовых символов и вставленные в исходный код программы. Я их обожаю! Как-то раз я кинул клич в Twitter и мне прислали гораздо больше примеров, чем я ожидал. Спасибо всем участвовавшим. В этой теме попалось несколько прекрасных примеров, которые я собрал и разложил на категории. Для каждого изображения дается ссылка на соответствующий репозиторий.
Большинство людей — визуалы. Они используют изображения, чтобы вникнуть в суть проблемы. А вот мэйнстримные языки программирования, напротив, основаны на текстовом представлении. Возникающую пропасть между текстом и графикой заполняют ASCII-изображения, нарисованные с помощью текстовых символов и вставленные в исходный код программы. Я их обожаю! Как-то раз я кинул клич в Twitter и мне прислали гораздо больше примеров, чем я ожидал. Спасибо всем участвовавшим. В этой теме попалось несколько прекрасных примеров, которые я собрал и разложил на категории. Для каждого изображения дается ссылка на соответствующий репозиторий.




 Я уже делал на Хабре
Я уже делал на Хабре 






{kind=link}
{kind=link}
{kind=link}
{kind=link}