Comments 116
А можно детальнее про Заббикс и как его вкрутить?
Я сделал простенький скрипт на php, который плюется числами, а потом его наш админ вывел в заббикс через «внешнюю проверку».
Была цель — получить время, за которое выполняются 80%, 90%, 99% самых быстрых запросов. ИМХО эта метрика гораздо более значима, чем среднее время выполнения.
Была цель — получить время, за которое выполняются 80%, 90%, 99% самых быстрых запросов. ИМХО эта метрика гораздо более значима, чем среднее время выполнения.
если вы прикрепите к посту ещё и скрипт, то хуже точно не будет, а людям может и пригодится ;-)
В текущем виде не могу, к сожалению, там есть кусок бизнес-логики.
Я вот здесь писал мост к нашему фреймворку, может в свободное время закончу github.com/Wapstart/onphp-framework/tree/1.0-wapstart/main/Monitoring
Пример скрипта есть в вики, кстати pinba.org/files/scripts/pinba_scripts_stats.php.txt
Я вот здесь писал мост к нашему фреймворку, может в свободное время закончу github.com/Wapstart/onphp-framework/tree/1.0-wapstart/main/Monitoring
Пример скрипта есть в вики, кстати pinba.org/files/scripts/pinba_scripts_stats.php.txt
<img src="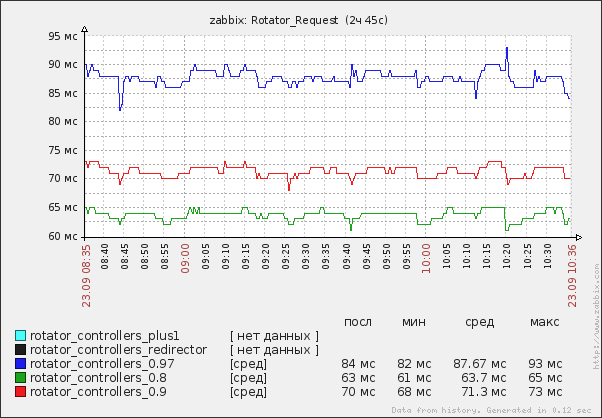 " alt=«image»/>
" alt=«image»/>
Как-то так.
" alt=«image»/>Как-то так.
Действительно хороший подарок для пинбы. Попробую и я сделать что то полезное, а именно отказаться от zabbix и использовать highcharts
А нет у вас оценки, сколько оно добавляет нагрузки на сервер (сравнительный бенчмарк или что-то типа того)?
Если мы говорим про клиент, то там включение pinba даже не удалось отследить. Нагрузки она добавила меньше, чем погрешность измерений.
Сервер пинбы у нас стоит на виртуалке:
Сервер пинбы у нас стоит на виртуалке:
dovg@pinba:~$ w
18:53:41 up 50 days, 6:31, 1 user, load average: 0.22, 0.14, 0.10
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
dovg pts/0 192.168.1.203 15:36 0.00s 0.01s 0.00s w
dovg@pinba:~$ free
total used free shared buffers cached
Mem: 1424000 1175020 248980 0 0 0
-/+ buffers/cache: 1175020 248980
Swap: 0
А вы выполните 'ab -n 1000 -c 10 yoursite.com/somepage.here' два раза, один раз с отключенным пимбом, второй раз с включенным, и покажите нам результаты.
Ближе к рабочему времени, ОК ;)?
Какие-нибудь предложения по составу скрипта будут?
Какие-нибудь предложения по составу скрипта будут?
Я бы предложил использовать один из самых сложных скриптов с вашего production сервера, доступного по публичному URL. ;)
Обычно самая загруженная инфой страница это стартовая, попробуйте ее и страницу, которую вы минимально кешируете
Протестировали?
Какой долгий тест получился ) Скоро можно будет год отметить.
Чуть ниже автор говорит, что бенчмарки бессмысленны, т.к. оверхеда нет. У меня нет оснований ему не доверять.
Предположим, у вас есть скрипт, который шлёт на сервер N таймеров (у нас в Badoo, например, N в среднем около 30-ти).
В каждом таймере есть два-три тага (операция, сервер, результат операции или что-то около того).
В результате оверхед выходит: обработать N таймеров, сделать уникальный набор строк (для экономии на размере UDP-пакета), добавить это всё в пакет Google Protobuf и послать результат по UDP (и да, всё это на C, в экстеншене).
Сами эти операции совсем мизерные, а если принять во внимание, что таймеры в 99% случаев измеряют общение с внешними сервисами, то на фоне всего скрипта они вообще теряются.
Кроме того, все эти операции делаются во время request shutdown, когда сам скрипт уже закончил работу.
Так что я не вижу смысла даже начинать делать бенчмарки.
В каждом таймере есть два-три тага (операция, сервер, результат операции или что-то около того).
В результате оверхед выходит: обработать N таймеров, сделать уникальный набор строк (для экономии на размере UDP-пакета), добавить это всё в пакет Google Protobuf и послать результат по UDP (и да, всё это на C, в экстеншене).
Сами эти операции совсем мизерные, а если принять во внимание, что таймеры в 99% случаев измеряют общение с внешними сервисами, то на фоне всего скрипта они вообще теряются.
Кроме того, все эти операции делаются во время request shutdown, когда сам скрипт уже закончил работу.
Так что я не вижу смысла даже начинать делать бенчмарки.
Есть ли смысл прикручивать pinba для измерения работы демонов?
Да, с ее помощью очень удобно мониторить кол-во запросов и время ответа в реальном времени
Иногда нужно узнать узкие места любого кода
А нету обработки для munin'а, чтобы всё на одной странице видеть?
просто отличная вещь! Спасибо.
/me пошел ставить на све серво
/me пошел ставить на све серво
Все же интересно узнать в цифрах какой она добавляет оверхед
А что в случае с пинбой вы подразумеваете под оверхедом?
Отсылка UDP пакета с счетчиками вообще не заметена.
Единственная проблема — утечки памяти на хранении кастомных счетчиков во время выполнения cli скриптов. В теории эту проблему решает pinba_flush, но на практике оно отваливается с какими-то жуткими ворнигами. Поэтому мы используем пинбу только на web front-end`е.
Отсылка UDP пакета с счетчиками вообще не заметена.
Единственная проблема — утечки памяти на хранении кастомных счетчиков во время выполнения cli скриптов. В теории эту проблему решает pinba_flush, но на практике оно отваливается с какими-то жуткими ворнигами. Поэтому мы используем пинбу только на web front-end`е.
> Это не анализ логов apache, это профайлинг и мониторинг прямо на продакшене!
Думаю этот инструмент нужно ставить все таки на девелопмент сервер. Для продакшена это в любом случае это оверхед.
Думаю этот инструмент нужно ставить все таки на девелопмент сервер. Для продакшена это в любом случае это оверхед.
а смысл мониторить нагрузку на девелопмент сервере? гораздо полезнее посмотреть как это будет выглядеть в реальных условиях и в случае чего предпринимать какие-то действия в плане оптимизации
для продакшена и апачевские логи — оверхэд.
Но как часто их выключают?
Но как часто их выключают?
Пинба как раз заточена, чтобы мониторить продакшен, а оверхед, как уже было сказано выше, находится в пределах погрешности измерения.
это мониторинг проекта, на девелоперском сервере нет смысла его ставить, интересует именно текущее состояние проекта и сервисов, которые в нём используются.
а зачем оверхедить на продакшене, если можно выполнить нагрузочные тесты на девелоперском сервере?
тесты != мониторинг.
Ну это и так понятно. Имелось ввиду: выполнить нагрузочные тесты на девелоперском сервере с включенным пинбой. Пинба промониторит работу скриптов во время нагрузочных тестов. Потом команда сможет проанализировать мониторинг и внести коррективы в работу скриптов (при необходимости).
А так вы оверхедите на продакшене, а это как то не очень фей-шуйно.
А так вы оверхедите на продакшене, а это как то не очень фей-шуйно.
ИМХО вы путаете мониторинг и профайлинг.
Любая система мониторинга — это в любом случае оверхед, но спокойный сон того стоит. Плюс к этому процессы на проде и в тестах все же отличаются, как бы мы не пытались сделать их идентичными.
Любая система мониторинга — это в любом случае оверхед, но спокойный сон того стоит. Плюс к этому процессы на проде и в тестах все же отличаются, как бы мы не пытались сделать их идентичными.
> ИМХО вы путаете мониторинг и профайлинг.
Ну раз так Вы считаете, то не могли бы Вы описать отличия понятий «мониторинга» и «профайлинга»? С точки зрения эти процессы похожи тем что они оба выполняют сбор информации о выполнении скрипта/программы. Поэтому я не считаю что я в чем то путаюсь, скорее Вы ;)
> Плюс к этому процессы на проде и в тестах все же отличаются, как бы мы не пытались сделать их идентичными.
Приведите пример дискретного PHP процесса, который выполняется пользователем и не может быть идентично реализован в нагрузочных тестах?
Ну раз так Вы считаете, то не могли бы Вы описать отличия понятий «мониторинга» и «профайлинга»? С точки зрения эти процессы похожи тем что они оба выполняют сбор информации о выполнении скрипта/программы. Поэтому я не считаю что я в чем то путаюсь, скорее Вы ;)
> Плюс к этому процессы на проде и в тестах все же отличаются, как бы мы не пытались сделать их идентичными.
Приведите пример дискретного PHP процесса, который выполняется пользователем и не может быть идентично реализован в нагрузочных тестах?
Профайлинг дает сильно больше информации о процессе. Мониторинг же показывает только общую картину. Не будете же по LA во время нагрузочных тестов говорить чему равен LA на продакшене.
А самое главное отличие в них достаточно простое. У мониторинга постоянная величина — время выполнения кода. Но переменная величина — количество и поведение пользователей.
У профайлинга во время тестирования наоборот. Количество и поведение тестовых полльзователей ( роботов ) — одинаково. А время выполнения кода — разное.
Хотя конечно бывают и случаи, когда код профилируется, «чтобы было», а не чтобы оптимизировать.
А самое главное отличие в них достаточно простое. У мониторинга постоянная величина — время выполнения кода. Но переменная величина — количество и поведение пользователей.
У профайлинга во время тестирования наоборот. Количество и поведение тестовых полльзователей ( роботов ) — одинаково. А время выполнения кода — разное.
Хотя конечно бывают и случаи, когда код профилируется, «чтобы было», а не чтобы оптимизировать.
Спасибо за развернутый ответ. Но контекст темы все таки про сбор информации о работе PHP скриптов, а так как и профайлинг и мониторинг собирают некую информацию о работе программы, то эти процессы можно считать условно идентичными в пределах данного контекста.
LA к ним же приравняем?
По-моему, нельзя их считать условно идентичными. Профайлинг выдаст вам информацию по вашим тестовым сценариям в лабораторных условиях, а мониторинг по реальным сценариям в реальных условиях. Например, профилируется обычно один скрипт, а в реальности может возникнуть гонка за ресурсами у двух. Если не предвидели такую ситуацию в тестах и не мониторите время ответа, то можно очень долго недоумевать, почему пользователи не остаются на сайте при пиковой нагрузке.
Очень простой пример, с которым мы столкнулись. В деплое разложился бесконечный редирект, при некоторых редких условиях (этот редирект не удалось отловить на тестах до раскладки). После раскладки резко скакануло кол-во запросов к ПХП скриптам. Заметили, начали внимательно искать — нашли. А теперь скажите мне — без мониторинга когда бы вы поняли что у вас в бесконечный редирект в редких случаях существует? Пока пользователи вам писать не стали? Пока сами бы не напоролись (настолько редкий, что ну вряд ли бы напоролись)? Или бы так и жили бы.
У вас что тестировщиков нет? Или они не тестируют функциональность перед деплоем новой версии?
«Редкий бесконечный редирект»? Извините меня, но надо очень постараться что бы такое нагородить. И каким образом он может быть таким редким что даже разработчики вряд ли бы напоролись?
К тому же вопрос был в другом. Я не просил приводить примеры ваших злостных багов, а просил привести пример дискретной процедуры выполняемой пользователем, которая не может быть воспроизведена в нагрузочных тестах.
«Редкий бесконечный редирект»? Извините меня, но надо очень постараться что бы такое нагородить. И каким образом он может быть таким редким что даже разработчики вряд ли бы напоролись?
К тому же вопрос был в другом. Я не просил приводить примеры ваших злостных багов, а просил привести пример дискретной процедуры выполняемой пользователем, которая не может быть воспроизведена в нагрузочных тестах.
Тестировщики есть и они прекрасно тестируют, но 100% кейсов ловить это потратить невообразимо много времени, которое как известно деньги — или вы этого не знали?
Вы часто делали системы с геораспределёнными датацентрами? Вот там нужно иногда отредиректить на другой ДЦ и если там какая-то комбинация не получится то там уже железяка может отредиректить обратно и вот так может возникнуть. На простых проектах я согласен — такого не возникнет, но там и пинба не нужна, там и так всё видно.
«Гонка за ресурсами».
Вы часто делали системы с геораспределёнными датацентрами? Вот там нужно иногда отредиректить на другой ДЦ и если там какая-то комбинация не получится то там уже железяка может отредиректить обратно и вот так может возникнуть. На простых проектах я согласен — такого не возникнет, но там и пинба не нужна, там и так всё видно.
«Гонка за ресурсами».
Как раз тестировщики и должны протестировать 100% кейсов, и не важно сколько это времени займет, потому что если выкладывать не качественно протестированный продукт себе дороже — или вы этого не знали? ;)
Заведите им документ в котором будут описаны все «use case»-ы и требуйте 100% тестирования их, всеми возможными тестами.
По поводу геораспределенных датацентров, то с такой задачей не сталкивался. Но могу сказать что это очень легко решается, и разработчик (и/или архитектор) должен был это предусмотреть.
Ну а так пинба вам помогла :)
Заведите им документ в котором будут описаны все «use case»-ы и требуйте 100% тестирования их, всеми возможными тестами.
По поводу геораспределенных датацентров, то с такой задачей не сталкивался. Но могу сказать что это очень легко решается, и разработчик (и/или архитектор) должен был это предусмотреть.
Ну а так пинба вам помогла :)
Да… вы идеалист. 100% и неважно сколько времени… Ну ваши конкуренты уже выкатили сырую версию и обогнали вас. И ваша 100% рабочая версия никому уже не нужна, а все подсели на 90% рабочую версию конкурентов. Да 10% не работает вначале, но в процессе они починят. А вы за бортом.
Вы реально представляете проект на 1кк строк, пишушийся 6 лет что бы в нём были все use case и при минимальном изменении ядра надо всё пробегать? Ну это примерно 1000 человеко часов. Вперёд.
Предусмотрели на тот момент всё, но вот пришли 0,5% пользователей с очень странными данными и на них такое получилось — такие данные были получены вообще впервые. Их никто не знал. Как такое предусмотреть?
Так пример, который я вам привёл вы сможете синтетическими тестами повторить? А это один из важнейших косяков что случается на высоконагруженных проектах, для которых Пинба как раз и писалась.
Вы реально представляете проект на 1кк строк, пишушийся 6 лет что бы в нём были все use case и при минимальном изменении ядра надо всё пробегать? Ну это примерно 1000 человеко часов. Вперёд.
Предусмотрели на тот момент всё, но вот пришли 0,5% пользователей с очень странными данными и на них такое получилось — такие данные были получены вообще впервые. Их никто не знал. Как такое предусмотреть?
Так пример, который я вам привёл вы сможете синтетическими тестами повторить? А это один из важнейших косяков что случается на высоконагруженных проектах, для которых Пинба как раз и писалась.
тесты != поведение пользователей
КО?
Пинба — мониторит работу PHP скриптов. Какая разница кто будет дергать тест — пользователь или тест? Вы же не работу с интерфейсом мониторить будете.
Пинба — мониторит работу PHP скриптов. Какая разница кто будет дергать тест — пользователь или тест? Вы же не работу с интерфейсом мониторить будете.
Для тех, кто пишет про оверхед рекомендую потестировать самим, насколько быстро пхп работает с сетью.
В моих тестах на ноутбуке мне удалось достичь скорости около 5000 тсп запросов-ответов в секунду при 100% загрузке одного ядра моего ноута. Это значит, что отправка одного юдп пакета займет около 0.1 мс. Что составляет 0.25% времени выполнения быстрого пхп-скрипта ( 40мс ).
И да. Я привожу цифры для ядра в 1.6Ггц и 100Мбит сеть.
В моих тестах на ноутбуке мне удалось достичь скорости около 5000 тсп запросов-ответов в секунду при 100% загрузке одного ядра моего ноута. Это значит, что отправка одного юдп пакета займет около 0.1 мс. Что составляет 0.25% времени выполнения быстрого пхп-скрипта ( 40мс ).
И да. Я привожу цифры для ядра в 1.6Ггц и 100Мбит сеть.
Приведите пожалуйста показатель «Request per second» с включенной и выключенной «пинбой». Я думаю этот параметр будет более актуален чем время выполнения скрипта.
Pinba шлет UDP-пакеты.
Она отправляет данные по завершению скрипта, когда пользователь уже получил что хотел. Поэтому она может осуществлять отправку сколь угодно долго, и это никак не повлияет на время отклика.
в случае фиксированного количетва процессов-воркеров, которые обрабатываю запросы, это будет означать, что следующий запрос скрипт выполнит позже, чем обычно
>насколько быстро пхп работает с сетью.
Я понимаю откуда берется эта логическая связь, но вы всё-таки сами подумайте:
экстеншен шлёт UDP пакет с помощью sendto(), PHP в данном случае — это обёртка для пользователя.
Можно сколько угодно тестить TCP-коннекты в PHP, но здесь идёт речь:
1) не о PHP, а о С;
2) не о TCP, а о UDP.
>Это значит, что отправка одного юдп пакета займет около 0.1 мс. Что составляет 0.25% времени >выполнения быстрого пхп-скрипта ( 40мс ).
вы где-то пропустили логическое обоснование формулы «скорость работы TCP = скорость работы UDP * 4».
Я понимаю откуда берется эта логическая связь, но вы всё-таки сами подумайте:
экстеншен шлёт UDP пакет с помощью sendto(), PHP в данном случае — это обёртка для пользователя.
Можно сколько угодно тестить TCP-коннекты в PHP, но здесь идёт речь:
1) не о PHP, а о С;
2) не о TCP, а о UDP.
>Это значит, что отправка одного юдп пакета займет около 0.1 мс. Что составляет 0.25% времени >выполнения быстрого пхп-скрипта ( 40мс ).
вы где-то пропустили логическое обоснование формулы «скорость работы TCP = скорость работы UDP * 4».
Насколько я помню, работа с сокетами в пхп практически напрямую работает с сишным кодом. То есть разница по скорости выполнения не превышает двух раз.
Я надеюсь никто не считает что UDP будет медленнее TCP?
В остальном я беру коэфициент 4, исходя из следующих моих установок: В своем коде я считал приём запроса и отправку ответа. Пинба не принимает входщий запрос, а только отправляет одно сообщение. Это уже коэфициент 2.
TCP для отправки сообщения сначала устанавливает соединение ( это самое долгое событие в данном сценарии, исходя из моих знаний о особенностях работы сети), а UDP это без надобности. Соответсвенно я условно считаю что UDP отработает быстрее. Тут стоит особо отметить, что я считаю реальное время, а не время процессора. По процессору это будет примерно аналогично — время на скидывание данных в буфер. И ещё одна оговорка — я исхожу из того, что пинба работает с сетью в синхронном режиме, поскольку асинхронный режим в сценарии сбора статистики в момент завершения скрипта не поможет добиться увеличения производительности.
Конечно это писалось ночью с оценками на глаз. Так что я не буду отстаивать эти цифры до последнего издыхания. Но в любом случае считаю свой результат достаточно близким к правде. Пинба даст оверхэд менее процента в случае быстрых скриптов. И менее десятой или даже сотой доли процента в случае использования тяжелых движков.
Я надеюсь никто не считает что UDP будет медленнее TCP?
В остальном я беру коэфициент 4, исходя из следующих моих установок: В своем коде я считал приём запроса и отправку ответа. Пинба не принимает входщий запрос, а только отправляет одно сообщение. Это уже коэфициент 2.
TCP для отправки сообщения сначала устанавливает соединение ( это самое долгое событие в данном сценарии, исходя из моих знаний о особенностях работы сети), а UDP это без надобности. Соответсвенно я условно считаю что UDP отработает быстрее. Тут стоит особо отметить, что я считаю реальное время, а не время процессора. По процессору это будет примерно аналогично — время на скидывание данных в буфер. И ещё одна оговорка — я исхожу из того, что пинба работает с сетью в синхронном режиме, поскольку асинхронный режим в сценарии сбора статистики в момент завершения скрипта не поможет добиться увеличения производительности.
Конечно это писалось ночью с оценками на глаз. Так что я не буду отстаивать эти цифры до последнего издыхания. Но в любом случае считаю свой результат достаточно близким к правде. Пинба даст оверхэд менее процента в случае быстрых скриптов. И менее десятой или даже сотой доли процента в случае использования тяжелых движков.
>Насколько я помню, работа с сокетами в пхп практически напрямую работает с сишным кодом.
если говорить про ext/socket — да, там всё напрямую почти.
если говорить про PHP streams — там всё сложнее.
>В остальном я беру коэфициент 4
Непонятно почему коэффициент 4, а не 8 или не 16, например.
Если следовать вашей логике, то можно просто придумать некий коэффициент, посчитать в уме некие числа базируясь на тестах, которые проведены на ноуте, и вывести в результате что угодно.
На данный момент у вас выходит, что послать 1 UDP пакет в С/PHP занимает 0.05 секунды, я ничего не путаю? (коэффициент теперь 2, а не 4).
Это просто проверить:
pastebin.com/Uxi8T0XG
Этот скрипт у меня на ноуте =) выполняется за:
real 0m3.741s
user 0m0.622s
sys 0m0.465s
Итого: около 0.00003741 сек на один вызов sendto().
если говорить про ext/socket — да, там всё напрямую почти.
если говорить про PHP streams — там всё сложнее.
>В остальном я беру коэфициент 4
Непонятно почему коэффициент 4, а не 8 или не 16, например.
Если следовать вашей логике, то можно просто придумать некий коэффициент, посчитать в уме некие числа базируясь на тестах, которые проведены на ноуте, и вывести в результате что угодно.
На данный момент у вас выходит, что послать 1 UDP пакет в С/PHP занимает 0.05 секунды, я ничего не путаю? (коэффициент теперь 2, а не 4).
Это просто проверить:
pastebin.com/Uxi8T0XG
Этот скрипт у меня на ноуте =) выполняется за:
real 0m3.741s
user 0m0.622s
sys 0m0.465s
Итого: около 0.00003741 сек на один вызов sendto().
не совсем.
5000 пар запрос-ответ в секунду при коэфициенте 4 превращаются в 20000 юдп запросов в секунду. это 0.00005 секунд на один вызов.
А исходя из аналогичного времени выполнения вашего скрипта:
real 0m3.766s
user 0m1.220s
sys 0m1.116s
Я ошибся менее чем в два раза. То есть можно было бы взять коэфициент 8 — это было бы даже ближе. А вот коэфициент 16 был бы уже менее точным, нежели коэфициент 4.
5000 пар запрос-ответ в секунду при коэфициенте 4 превращаются в 20000 юдп запросов в секунду. это 0.00005 секунд на один вызов.
А исходя из аналогичного времени выполнения вашего скрипта:
real 0m3.766s
user 0m1.220s
sys 0m1.116s
Я ошибся менее чем в два раза. То есть можно было бы взять коэфициент 8 — это было бы даже ближе. А вот коэфициент 16 был бы уже менее точным, нежели коэфициент 4.
В pinba есть возможность переопределять имя скрипта. Если точка входа у вас одна, то сделать это надо ровно в одном месте.
Я так и делаю ;)
Я так и делаю ;)
на самом деле оно показывает нагрузку по $_SERVER['REQUEST_URI']
вообще, я считаю, что в таких случаях всё как раз совершенно верно: мы мониторим код, а не УРЛы.
поэтому, если у вас index.php выполняется на каждый запрос, то он и является очевидным узким местом.
но для сбора статистики и/или разделения запросов на какие-то логические/виртуальные УРЛы, можно подменить имя скрипта, как у же написали ранее.
поэтому, если у вас index.php выполняется на каждый запрос, то он и является очевидным узким местом.
но для сбора статистики и/или разделения запросов на какие-то логические/виртуальные УРЛы, можно подменить имя скрипта, как у же написали ранее.
статья отличная, за что автору спасибо
но к сожалению опоздала эдак года на два…
пришлось много биться лбом об стену, чтоб разобраться что и как
но к сожалению опоздала эдак года на два…
пришлось много биться лбом об стену, чтоб разобраться что и как
ждём DEB пакетов
SRPM для EL6 (centos 6, scientific linux 6) для pinba-engine, собираемого вместе с MySQL 5.5:
yum.aclub.net/pub/linux/centos/6/umask/SRPMS/mysql55-5.5.15-3.el6.src.rpm
Там же php-5.3.8 с pinba-extension:
yum.aclub.net/pub/linux/centos/6/umask/SRPMS/php-5.3.8-4.el6.src.rpm
Есть бинарная сборка для архитектуры x86_64.
Ставим репозиторий:
cd /etc/yum.repos.d/
wget yum.aclub.net/pub/linux/centos/6/umask/umask.repo
sed -i 's/gpgkey/#gpgkey/' umask.repo
rpm --import yum.aclub.net/pub/linux/centos/$releasever/umask/RPM-GPG-KEY-umask
Ставим пакеты:
yum install php-pinba
yum install mysql55-plugin-pinba
Сегодня собрал, проверил — всё работает.
P.S. естественно, что pinba-engine надо ставить на mysql55-server, что в общем-то очевидно и не конфликтует с пакетом mysql-libs, от которого зависит часть минимальной системы.
yum.aclub.net/pub/linux/centos/6/umask/SRPMS/mysql55-5.5.15-3.el6.src.rpm
Там же php-5.3.8 с pinba-extension:
yum.aclub.net/pub/linux/centos/6/umask/SRPMS/php-5.3.8-4.el6.src.rpm
Есть бинарная сборка для архитектуры x86_64.
Ставим репозиторий:
cd /etc/yum.repos.d/
wget yum.aclub.net/pub/linux/centos/6/umask/umask.repo
sed -i 's/gpgkey/#gpgkey/' umask.repo
rpm --import yum.aclub.net/pub/linux/centos/$releasever/umask/RPM-GPG-KEY-umask
Ставим пакеты:
yum install php-pinba
yum install mysql55-plugin-pinba
Сегодня собрал, проверил — всё работает.
P.S. естественно, что pinba-engine надо ставить на mysql55-server, что в общем-то очевидно и не конфликтует с пакетом mysql-libs, от которого зависит часть минимальной системы.
Пожалуйста.
Я раньше только для SLES собирал, но забросил это дело. Это было года 3 назад, когда ещё не было публичной версии Pinba.
Для CentOS 5 пока сборку делать не планирую, но всё может случится, если по работе нужно будет. Возможно, что SRPM для EL6 соберётся и на EL5.
Я раньше только для SLES собирал, но забросил это дело. Это было года 3 назад, когда ещё не было публичной версии Pinba.
Для CentOS 5 пока сборку делать не планирую, но всё может случится, если по работе нужно будет. Возможно, что SRPM для EL6 соберётся и на EL5.
а кто может подробнее объяснить настройки плагина mysql?
в частности интересует что значит pinba_tag_report_timeout
в частности интересует что значит pinba_tag_report_timeout
поскольку обновление отчетов по тагам — дело затратное, то предполагалось, что отчеты через некоторое время после последнего чтения могут таймаутиться и переставать обновляться.
на практике этот функционал оказался _у нас_ не востребован, в основном потому, что перегенерация отчета «с нуля» на миллионах таймеров занимает неприлично много времени.
на практике этот функционал оказался _у нас_ не востребован, в основном потому, что перегенерация отчета «с нуля» на миллионах таймеров занимает неприлично много времени.
эта опция, как и все другие, описана в мануале: pinba.org/wiki/Manual:Configuration#pinba_tag_report_timeout
коротко говоря, можете игнорировать её.
коротко говоря, можете игнорировать её.
ещё вопрос, что показывает колонка req_time_per_sec
req_time_total — суммарное время работы скрипта, SUM(req_time)
req_time_percent — суммарное время работы скрипта поделенное на суммарное время работы всех скриптов, (SUM(req_time)/time_total)*100
req_time_per_sec — суммарное время работы скрипта, поделенное на интервал времени, за который у нас собраны данные, SUM(req_time)/time_interval
скажем так, это «сколько времени тратится на этот скрипт в секунду».
по правде говоря, там эта колонка только для единообразия — во всех остальных случаях per_sec имеет бОльший смысл.
req_time_percent — суммарное время работы скрипта поделенное на суммарное время работы всех скриптов, (SUM(req_time)/time_total)*100
req_time_per_sec — суммарное время работы скрипта, поделенное на интервал времени, за который у нас собраны данные, SUM(req_time)/time_interval
скажем так, это «сколько времени тратится на этот скрипт в секунду».
по правде говоря, там эта колонка только для единообразия — во всех остальных случаях per_sec имеет бОльший смысл.
Установка не такая уж и тривиальная, выдает ошибку:
INSTALL PLUGIN pinba SONAME 'libpinba_engine.so';
ERROR 1126 (HY000): Can't open shared library '/usr/lib/mysql/plugin/libpinba_engine.so' (errno: 2 libprotobuf-lite.so.7: cannot open shared object file: No such file or directory)
И хз что с этим делать, все библиотеки на месте.
INSTALL PLUGIN pinba SONAME 'libpinba_engine.so';
ERROR 1126 (HY000): Can't open shared library '/usr/lib/mysql/plugin/libpinba_engine.so' (errno: 2 libprotobuf-lite.so.7: cannot open shared object file: No such file or directory)
И хз что с этим делать, все библиотеки на месте.
Система врать не будет. Если она говорит, что «libprotobuf-lite.so.7: cannot open shared object file: No such file or directory», значит этот файл системе не известен.
Я могу предположить, что надо как минимум выполнить ldconfig.
Возможно, надо еще положить эту либу туда, где ldconfig её увидит или добавить путь к ней в /etc/ld.so.conf.
В любом случае `ldd /usr/lib/mysql/plugin/libpinba_engine.so` должен успешно находить все либы.
Я могу предположить, что надо как минимум выполнить ldconfig.
Возможно, надо еще положить эту либу туда, где ldconfig её увидит или добавить путь к ней в /etc/ld.so.conf.
В любом случае `ldd /usr/lib/mysql/plugin/libpinba_engine.so` должен успешно находить все либы.
в том то все и дело, что `ldd /usr/lib/mysql/plugin/libpinba_engine.so` находит все либы, я в недоумении…
может быть, у юзера mysql нет прав на эту либу?
ldconfig -p | grep protobuf её показывает?
ldconfig -p | grep protobuf её показывает?
ага,
ldconfig -p | grep protobuf
libprotobuf.so.7 (libc6) => /usr/local/lib/libprotobuf.so.7
libprotobuf.so.5 (libc6) => /usr/lib/libprotobuf.so.5
libprotobuf.so (libc6) => /usr/local/lib/libprotobuf.so
libprotobuf-lite.so.7 (libc6) => /usr/local/lib/libprotobuf-lite.so.7
а как права юзера на либу проверить?
ldconfig -p | grep protobuf
libprotobuf.so.7 (libc6) => /usr/local/lib/libprotobuf.so.7
libprotobuf.so.5 (libc6) => /usr/lib/libprotobuf.so.5
libprotobuf.so (libc6) => /usr/local/lib/libprotobuf.so
libprotobuf-lite.so.7 (libc6) => /usr/local/lib/libprotobuf-lite.so.7
а как права юзера на либу проверить?
Столкнулся также с проблемой установки плагина, но получаю другую ошибку:
mysql> INSTALL PLUGIN pinba SONAME 'libpinba_engine.so';
ERROR 1126 (HY000): Can't open shared library '/usr/lib/mysql/plugin/libpinba_engine.so' (errno: 2 undefined symbol: _ZN7handler5cloneEPKcP11st_mem_root)
Нужные файлы есть по указанному пути, mysql версии 5.1.54, pinba ставил из пакетов dotdeb'а. Куда стоит копнуть?
mysql> INSTALL PLUGIN pinba SONAME 'libpinba_engine.so';
ERROR 1126 (HY000): Can't open shared library '/usr/lib/mysql/plugin/libpinba_engine.so' (errno: 2 undefined symbol: _ZN7handler5cloneEPKcP11st_mem_root)
Нужные файлы есть по указанному пути, mysql версии 5.1.54, pinba ставил из пакетов dotdeb'а. Куда стоит копнуть?
решили эту проблему? у меня аналогичная проблема. CentOS 6
yum.aclub.net/pub/linux/centos/6/umask/ — здесь были готовые пакеты для CentOS 6.
А как в ней с вложенностю?
Будет ли работать Pinba с PHP 5.4?
Заодно можно было бы протестировать столь расхваленное увеличение производительности 5.4 VS 5.3 в реальных улсовиях :) (конечно же, когда 5.4 станет стабильной)
Заодно можно было бы протестировать столь расхваленное увеличение производительности 5.4 VS 5.3 в реальных улсовиях :) (конечно же, когда 5.4 станет стабильной)
Настраивать Пинбу довольно сложно. Вариант проще — использовать программу профайлер прямо в рабочей среде программера. Neor Profile SQL позволяет мониторить взаимодействие вашего сайта с Mysql.

Не путайте теплое с мягким.
для девелоперов решение аналогичное, но в разы проще.
для системщиков, конечно не одинаковое.
для системщиков, конечно не одинаковое.
Перечитайте статью еще раз, пожалуйста.
Pinba — это не профайлер sql запрсоов, как вам показалось.
Pinba — это не профайлер sql запрсоов, как вам показалось.
не хочу разводить полемику, но вот что написано на офф сайте программы:
Pinba is a realtime monitoring/statistics server for PHP using MySQL as a read-only interface.
и вот что такое профилирование с википедии:
сбор характеристик работы программы, таких как время выполнения отдельных фрагментов (обычно подпрограмм), число верно предсказанных условных переходов, число кэш промахов и т. д. Инструмент, используемый для анализа работы, называют профилировщиком. Обычно выполняется совместно с оптимизацией программы.
Pinba is a realtime monitoring/statistics server for PHP using MySQL as a read-only interface.
и вот что такое профилирование с википедии:
сбор характеристик работы программы, таких как время выполнения отдельных фрагментов (обычно подпрограмм), число верно предсказанных условных переходов, число кэш промахов и т. д. Инструмент, используемый для анализа работы, называют профилировщиком. Обычно выполняется совместно с оптимизацией программы.
Учите английский
Он всего лишь хранит данные в чем-то похожем на mysql, но ни как не профайлит mysql, как вам могло показаться.
Pinba is a realtime monitoring/statistics server for PHP using MySQL as a read-only interface.
Пинба — это сервер мониторинга/статистики для php в реальном времени, который использует mysql в качестве интерфейса для чтения.
Он всего лишь хранит данные в чем-то похожем на mysql, но ни как не профайлит mysql, как вам могло показаться.
профилировать можно по разному, с разных точек. Получатся разные результаты, но косвенно ведут к одному и тому же. Так что не надо утверждать что Пинба не профайлер.
1. самая дальняя точка — смотреть на время выдачи страницы. Так делает 99% прогеров.
2. смотреть на взаимодействие php с mysql — более глубокая точка. Так привыкли делать. Пинба здесь же.
3. смотреть на то как именно работают запросы — чистый профайлинг mysql
1. самая дальняя точка — смотреть на время выдачи страницы. Так делает 99% прогеров.
2. смотреть на взаимодействие php с mysql — более глубокая точка. Так привыкли делать. Пинба здесь же.
3. смотреть на то как именно работают запросы — чистый профайлинг mysql
Есть ли какие-нибудь особенности установки Pinba с Percona 5.5 из репозитория? (в смысле Percona из репозитория, Pinba — из сорцов)
Всё заканчивается так:
Опции cmake, взятые отсюда www.percona.com/doc/percona-server/5.5/installation.html#installing-percona-server-from-the-bazaar-source-tree, применял к Pinba.
На просторах Интернета видел несколько подобных проблем без решения.
Уж очень не хотелось бы запускать второй бинарник mysqld только ради Pinba…
Всё заканчивается так:
# mysql -D pinba < default_tables.sql
ERROR 1005 (HY000) at line 3: Can't create table 'pinba.request' (errno: 140)
Опции cmake, взятые отсюда www.percona.com/doc/percona-server/5.5/installation.html#installing-percona-server-from-the-bazaar-source-tree, применял к Pinba.
На просторах Интернета видел несколько подобных проблем без решения.
Уж очень не хотелось бы запускать второй бинарник mysqld только ради Pinba…
Исходники нужно сконфигурировать/собрать с такими же опциями, что и бинарник, включая CFLAGS/CXXFLAGS.
Судя по опыту людей, они всё-таки какие-то флаги добавляют, которые в документации отсутствуют:
groups.google.com/d/msg/pinba-engine-ru/mQDa18eup-c/8NUPyWoITpoJ
Поэтому, как возможно решение, можно собрать самому и то, и другое из исходников.
Судя по опыту людей, они всё-таки какие-то флаги добавляют, которые в документации отсутствуют:
groups.google.com/d/msg/pinba-engine-ru/mQDa18eup-c/8NUPyWoITpoJ
Поэтому, как возможно решение, можно собрать самому и то, и другое из исходников.
Тему много раз читал.
Видимо да, собирают с какими-то незадокументированными опциями.
Пытался у них в твиттере об этом спросить: twitter.com/lu4e3ar/status/372686817256288256 — не ответили, хотя обычно отвечают оперативно. Непонятно, что такого секретного в этих опциях…
Нет ли какого-то другого способа выяснить эти опции?
Сейчас успешно поставил pinba на другой сервер с чистым MySQL. Но всё же хотелось бы добить Percona…
Видимо да, собирают с какими-то незадокументированными опциями.
Пытался у них в твиттере об этом спросить: twitter.com/lu4e3ar/status/372686817256288256 — не ответили, хотя обычно отвечают оперативно. Непонятно, что такого секретного в этих опциях…
Нет ли какого-то другого способа выяснить эти опции?
Сейчас успешно поставил pinba на другой сервер с чистым MySQL. Но всё же хотелось бы добить Percona…
Sign up to leave a comment.
Pinba — мониторим php в реальном времени