Comments 529
Этот код прекрасно иллюстрирует гипотезу. Он был написан так же, как мы привыкли решать примеры. Масса промежуточных шагов удерживалась непосредственно в голове, а «на бумагу» попало лишь окончательное решение. 150 строк, которые решают всю чёртову задачу одним махом. Этот код явно был написан очень талантливым парнем!
Вы не думаете что могло быть так, что сначала было написано 1500 строк, а потом за несколько проходов оптимизировано или воообще переписано? Тогда не надо голове держать много. Наверное есть гении которые сразу пишут оптимизированный код, но я думаю что это больше связано с опытом а не с тем скольк можно в голове удержать.
Способность писать сразу понятный код именно что связана с опытом, а не со способностью удерживать в памяти много объектов.
Только вот чтобы сначала написать 1500 строк, нужно их всё таки все держать в памяти. А во вторых, рефакторинг 1500 строк до 10 раз по 150 — это не очень хороший рефакторинг. Надо тогда уж хотя бы до 100 раз по 15.
Логичнее писать псевдокод, его оптимизировать, а потом уже реализовывать (и еще раз оптимизировать). Сам псевдокод можно оставить в комментарии к исходнику.
Простой пример — двойное отрицание над int в С++.
Двойное отрицание дает нам приведение к строгому bool.
Но в псевдокоде что даст двойное отрицание? Это будет логическая операция или бинарная? Конкретно в случае двойного отрицания понятно, что оно бессмысленно в случае бинарной операции. Но в любом случае однозначности нет.
Язык псевдокода может быть достаточным образом формализован и однозначен. Основное его отличие от языка программирования лишь в том, что он не предназначен для исполнения машиной, например, написан исходя из предположения бесконечной памяти и скорости.
PS и да, если вы не можете написать свои сишные уродцы типа «двойного отрицания над int» русским языком, то ваш код сразу можно выкинуть в помойку. Только там место недокументированному коду. Такому коду нельзя доверять, пока его сам не проверишь целиком. А, значит, проще написать заново.
в чем проблема написать «строгий boolean»?
А почему "троечник" не может решить пример в три действия?
(lnx/x^2)' = (lnx)'/x^2 + lnx * (x^-2)' = 1/x / x^2 -2 * lnx / x^3=(1-2*lnx)/x^3И не связана ли возможность "отличника" быстро щелкать примеры с тем
что он в десятки, а возможно и в сотни раз больше задачек решил, чем троечник (
который например банально не делает домашнее задание) и тем самым просто натренировался как "собака Павлова"?
Безусловно, бывают такие талантливые троечники, которым просто на математику наплевать, потому что у них есть куда более интересные для них занятия: литература, плавание и КВН, например. На таких ведь так мало…
А почему мало? У меня один одноклассник троечник — руководитель в строительной компании, второй — бизнесмен в области холодильного оборудования (мерседес новенький купил только только закончив универ). У отличников, тоже все нормально, но троечник это не приговор. Отличники часто чсв свое применить в жизни не могут.
(lnx/x^2)' = (lnx * x^-2)'Это и есть «отличие» — увидеть возможность упростить задачу ещё до применения стандартных правил. А способность в уме выполнять последовательность действий, которую записал «троечник» — тоже, конечно, «отличие», но уже другое.
Но здесь нет никакого «отличия» — как сказали выше, просто заученный алгоритм и всё
Два человека, решившие одинаковое количество одинаковых примеров, не будут одинаково выполнять одинаковые примеры
Способность отличника быстро щёлкать примеры связана с другой работой мозга. У меня старший ребенок решает примеры и не устаёт. Я старшего спрашивал как ты это делаешь. А он, оказывается числа в голове видит, он работает с зрительной памятью, он их не запоминает а представляет зрительно. Он математику любит. А младший биология и химия, районную олимпиаду выиграл. В биологии как рыба в воде. А считать долго не может, быстро устаёт.
Если модели в голове по какой то причине нет, то не важно сколько вы решили задач, это просто форма зубрёжки.
И первое условие не всегда верное, а уж второе-то…
успеваемость по таким предметам, как чтение и математика, напрямую связана с рабочей памятью
Эллоуэй Трейси, глава «Рабочая память и коэффициент интеллекта IQ» из книги «Включите свою рабочую память на полную мощь».
Понятие рабочей памяти тесно связывают с понятием подвижного интеллекта. Некоторые учёные находили связь между размером рабочей памяти и уровнем подвижного интеллекта, в связи с чем возникла теория о возможности развития подвижного интеллекта посредством тренировки рабочей памяти при использовании техник вроде n-назад.
Рабочая память, Википедия.
Так что первое условие я не придумал. А второе условие — да, это гипотеза, о чём я так прямо и написал. И мне хотелось бы обсудить её. Может быть, следовало обратиться к сообществу психологов? Однако затронутая проблема касается именно программистов, поэтому я предпочёл хабр.
Я сделал определённые выводы, и мне интересно, что о них думают мои собраться по профессии. Прошу высказываться!
Непомерно длинные функции что я видел были написаны или в режиме «на отвали», или фрилансерами(по сути тоже что и первое) или по старой памяти с более низкоуровневых языков. Программисты которые сильно умны, думают не только об уравнениях, но и о качестве кода и его последующей поддержке или они не очень-то и умны как по мне.
Умные программисты знают, что:
- Есть менее умные, но при этом не менее полезные.
- Мозг не всегда одинаково хорошо думает.
if занимает 38 строк? GCC тоже писали «на отвали»?По-моему достаточно одной цитаты: Reload is the GCC equivalent of Satan, чтобы понять как к ней относятся разработчики…
Не думаю, чтобы её писали «на отвали», скорее «так уж вышло»… но да — это не то, чем можно гордится.
1) Можно настроить IDE на схлопывание всех этих if-ов и расставить границы блоков фолдинга, и всё сразу станет коротко и изящно (ну если не открывать код в обычном редакторе, разумеется).
2) Если мы пишем реально что-то очень длинное, типа автомата — у нас неизбежно будет много if-ов, но мы не можем просто так взять, и использовать вызов других методов, если мы пишем в ООП, поскольку тогда мы потеряем доступ к переменным состояния, которые так мы можем сделать локальными, а в противном случае придётся хранить их или как поля объекта (что выглядит безобразно), или завести объект с набором всех этих данных и передавать его как аргумент другим методам, заменив if-ы на вызовы этих методов. Как по мне, затраты по памяти и циклам CPU на создание и передачу такой структуры не стоят того, чтобы сделать основной метод «в пределах разумного по длине».
Тем более, такие методы очень редко правятся, а если и правятся, то людьми, которые очень в теме того, что там внутри происходит :)
Можно настроить IDE на схлопывание всех этих if-ов
Для ясности: там не тело ифа на два экрана, а само его условие.
Условия ифов ваша IDE тоже схлопывает?
Тем более, такие методы очень редко правятся, а если и правятся, то людьми, которые очень в теме того, что там внутри происходит :)
Ну естественно, что раз код с одного взгляда вызывает желание закрыть его и больше никогда не открывать, — то он будет правиться очень редко и только теми людьми, кто смогут в себе эту естественную реакцию подавить.
Такой код нетестируем и неподдерживаем
Весьма спорное утверждение. Очень даже поддерживаем. А тестирование — ну да, тут сложнее, надо сразу писать без ошибок, иначе потом дебажить не так просто. Хотя тоже возможно, устанавливая точки останова в нужные if-ы прямо в начало.
А просто не надо писать стейтмашины в ООП.
Почему не надо, и какие альтернативы, если нам надо парсинг делать? К тому же, стейтмашина под конкретный язык — будет быстрее регулярок, причём в разы, имхо.
Если у вас грамматика языка зафиксирована один раз и навеки, то, пожалуй, да, потому что поддерживать и не надо.
А разве бывает иначе (если мы пишем парсер существующего, а не своего языка)? Язык конечно меняется и совершенствуется, но отличия в версиях обычно не столь грандиозны. Да и в случае чего можно будет просто заново всё переписать, имхо.
Регулярка задаёт соответствующую стейтмашину, между ними (вернее, между фактор-множествами по отношению эквивалентности на них) есть биекция.
Но регулярка как инструмент более универсальна, т.к. может тестировать что угодно, а не только конкретную грамматику. Разве код без регулярок не будет в конечном итоге работать быстрее?
А у вас ООП фиксированный констрейнт или необходимость распарсить язык? Откажитесь от ООП [в этой задаче].
У меня констрейнт — язык разработки. Вы таки сможете написать парсер на Java, не используя ООП?)
Когда у вас там виноградные гроздья if'ов, то проблемы возникают уже с выделением нужного if'а.
Виноградных гроздьев у меня, вроде, нет. Может, потому что парсер писался для относительно простого языка.
Когда вы пишете на комбинаторах, вы можете протестировать каждый комбинатор отдельно и чуть ли не породить минимальный ломающий пример в автоматическом режиме каким-нибудь quickcheck.
А не подскажете, что называется комбинатором? Я просто только недавно начал изучать эту тему :)
Потом, Вы сказали, что pcre может компилировать регулярки. Но pcre — это стандарт синтаксиса. А ещё есть реализации pcre в разных языках программирования. Вы правда уверены, что они всегда всё компилируют и кэшируют, а не считают всё в рантайме (и даже что можно косвенно на это поведение влиять)? Я вот нет :) Потому и предположил, что без регулярок будет работать быстрее (и контроля больше).
Несложно переписать любой код на лямбды так, чтобы никаких ифов там вообще не было. Код станет более тестируемым, что ли? Нет. А именно это происходит в случае с комбинаторами.
Но это и есть обмазывание лямбдой вместо ветвления. Ветвление в данном случае никуда не уходит. В графе потока управления как была вилка, так и осталась вилка. И эту вилку надо тестировать.
> с чётко определённой семантикой и единожды проверенной реализацией.
У if семантика тоже четко определена и неединожды проверена.
> лучше хотя бы думать о покрытии бранчей, если так метрик хочется
Я покрытие бранчей и имел ввиду. Но проблема в том, что любой виртуальный вызов, передача лямбды или указателя на ф-ю, дает потенциально бесконечное количество бранчей, по-этому покрытие всегда 0%.
Просто на всякий случай, мы правда обсуждаем, что лучше — функция на 1000 строк с полсотней ифов (пусть и в известном смысле минимальная такая функция), или же набор из полсотни мелких и удобных комбинаторов (тоже, для честности сравнения, в известном смысле минимальный)?Да. Я, впрочем, не буду заявлять, что «граф потока не меняется» от декомпозиции, но был у нас случай, когда мы хотели всё сделать «серьёзно», «по-настоящему безопасно».
И оказалось, что надёжнее всего не доказывать какие-то свойства «полсотни мелких и удобных комбинаторов» — а просто взять сгенерированную ragel'ем функцию, рассмотреть свойства языка, который она принимает — и всё. Не требуется знать и проверять все сотни DFA, из которых «собрана» функция, не требуется доказывать что ragel их правильно комбинирует… просто берём граф и изучаем его свойства.
Впрочем стоит признать что такой «финт ушами» мне встретился в моей карьере один раз. И фишка была в том, что мы хотели уменьшить как можно сильнее обьём кода, которому нам приходится доверять. Но… так тоже бывает.
P.S. Только не надо говорить «вы же всё равно собрали свой автомат из комбинаторов». Да — так нам показалось удобнее. Но тестировали мы именно функцию на 1000 строк (на самом деле на 100'000 строк, но не принципиально) — если бы она была написана руками с точки зрения тестирования ничего бы не поменялось.
То есть, вы взяли сгенерированный ragel'ом код, в известном смысле отреверсили его и что-то про него доказали?Угу.
А зачем? Почему бы не изучить то, что вы скормили ragel'у в предположении о том, что ragel корректен?Потому что, во-первых, были сомнения в корректности рагеля. Неизвестно — корректен ли он, но точно нестабилен: одинаковые входы дают на машинах разных разработчиков разные (хотя и эквивалентные) выходы. Чтобы это побороть мы перешли от прямой генериации кода
ragelем к ragel -x с последующей генерацией кода уже нашим скриптом). Что, кстати, облегчило и исследование тоже.Во-вторных — у нас было подробное и достаточно точное описание того, что мы хотели получить в терминах исходной задачи (правда при этом использовался
objdump -d, скорость которого была так примерно порядка на три меньше, чем нам было нужно). А все промежуточные DFA пришлось бы исследовать руками.А, вот зачем. Ну libc, компилятор и, чего мелочиться, микрокод вы, надеюсь, тоже верифицировали?libc и компилятором занимаются другие люди. А ragel'ем никто не занимается. Микрокод вне Intel никто исследовать не может… хотя и очень хочется — там точно есть баги, неизвестно только, насколько страшные. У security team есть идеи по этому поводу — но они под NDA, потому про них пока рано говорить. Но мне нравится ход ваших мыслей.
Было бы интересно сравнить время разработки этой функции руками и через ragel.Это тяжело будет сделать. Но сама эта функция заменила более старую подсистему, которая как раз была написана в «полноценном ООП-стиле». Ну там интерфейсы всякие и композиция в рантайме.
В программе у нас два режима — более «точный» и менее «точный». Соотвественно в оригинальной программе был флаг, а в случае с DFA — было две независимых DFA. Только менее точная была в 100 раз меньше, чем старая подсистема (и работает в 20 раз быстрее), а более точная — примерно то же самое по обьёму (но в 10 раз быстрее).
Это риторический вопрос? Вам слова «reproducible builds» о чём-нибудь говорят?Неизвестно — корректен ли он, но точно нестабилен: одинаковые входы дают на машинах разных разработчиков разные (хотя и эквивалентные) выходы.А это было для вас недостатком?
Это (и связь с objdump) я вот не понял. Видимо, это уж слишком завязано на вашу конкретную задачу.Угу.
И они правда занимаются верификацией какого-нибудь современного gcc или clang?До формальной верификации — им ещё как пешком до луны. Пока речь идёт о самых базовых вещах. В частности нужно, чтобы builds были reproducible, а то непонятно — что с чем сравнивать. Но да, в идеале дойти до формальной верификации — было бы неплохо.
Я плохо себе представляю, кто и зачем в здравом уме будет писать парсеры в ООП-стиле, с интерфейсами и композицией в рантайме.Можете попробовать догадаться. Hint: это связано с предыдущим абзацем, который вы не поняли. Люди писавшие первую версию, не осознавали, что они, на самом-то деле, пишут парсер некоего языка.
Это с одной и той же версией ragel? Тогда да, тогда это не очень хорошо (а на самом деле очень нехорошо).Не только «та же самая версия». Тот же самый бинарник.
Причём на простых DFA вроде такого не случалось. А когда обнаружили — было поздно уже всё переделивать.
Он там когда машину строит — один из вариантов выносит в
switch в default, а остальное — уже обрабатывает. При этом выносит так, чтобы минимизировать размер кода, но если вариантов выноса два или больше — может на разных машинах разные интервалы выносить.Вы можете написать
switch и 128 меток от 0 до 127 (а 128...255 пойдут в default) или 128 меток от 128 до 255 (а 0..127 пойдут в default).Вот на одних машинах ragel выбирает первую альтернативу, а других — вторую.
P.S. На самом деле ragel умнее и если у вас есть только два таких диапазона — будет использовать
if. Проблемы начинаются когда у вас есть несколько диапазонов одинакового размера и несколько отдельных вариантов.Таки да, легче. Тут проблема в том, что ragel не совсем на DFA оперирует. В частности если у вас есть машина принимающаяНе требуется знать и проверять все сотни DFA, из которых «собрана» функция.Ну да, требуется всего лишь проверить их композицию, что, конечно, легче.
a и печатающая Yes, this is a! и другая машина, принимающая ab и перечающая Yes, this is ab!, то их композиция напечатает обе строчки получив на вход ab.Это, зачастую, упрощает его использование на практике, но сильно усложняет теоретическую оценку правильности результата. Если же мы рассматриваем только конечный автомат «в сборе» — то это проблемой для нас не является…
успеваемость по таким предметам, как чтение и математика, напрямую связана с рабочей памятью
Есть исследования утверждающие что "общий" интеллект нельзя свести к одному фактору:
http://www.cell.com/neuron/abstract/S0896-6273(12)00584-3
и полагаю что такие обширные области как математика или прикладное программирование требуют всех возможностей интеллекта для разных классов задач
и свести все кто одному фактору типа "быстрая память" будет ошибочным упрощением.
Причем тут "рабочая память", когда ПО пишут команды разработчиков. Код должен быть понятным и храниться в памяти компьютера, а не в голове конкретного разработчика. Тем-более код по статистике чаще читается, а не пишется. И читается он не только автором, но и его коллегами и т.д.
Длина метода в 100+ строк — это уже не есть хорошо. По этому поводу Макконелл еще давно писал. А его книга "Совершенный код" — это классика, к которой все прислушиваются. У него по поводу размера метода отдельный раздел есть, где он пишет, что метод в идеале должен полностью помещаться на экране монитора (50-80 строк).
Плюс к этому, рекомендуется заменять комментарии, методами с подходящим названием.
А держать методы в уме (что вылетит из бошки очень быстро) — это не правильно, как по мне.
Имхо, память и ум вещи совсем разные. Можно много чего запомнить и держать в голове—это память, но что делать с тем, что у тебя запомнилось? нужно что то еще, например ум, что бы это все вытащить из памяти и скомпоновать все это
Если под отличником(-цей) понимать не зубрилу и выскочку (катати как и подлец только мужского рода слова), а способного мальчика или девочку, то точно не согласен что так будет брать производную. Будет расписывать по шагам а не заучивать формулу. У нас в университете даже это просто запрещалось делать. Поэтому решение примера чуть сложднее шекольного например по теме интегралы были на 4-х страницах с двух сторон в каждой клеточке.
Что касается магического числа семь. По этому поводу мне очень хорошо запомнилась байка одного из преподавателей прмышленного дизафна в политехе, где училась моя сестра. Вобщем-то тема была как раз о памяти. По поводу ворон например оказалось что сичтают до трех. Проверяли таким способом. Клали сыр в закрытое помещение куда входили по очереди и потом выходили 1, 2, 3 и 4 человека. Так вот вороны дожидались пока не выйдет 1, 2, 3 человека а на 4-м начали ошибаться.
По поводу человека проводили опыты с пастухами. Забирали у них из стада численностью 1,2,3 и т.п. голов одну корову и просили сказать все ли коровы на месте не пересчитывая их. Пастухи действтельно начинали ошибаться при стаде из 8 коров.
Потом сделали тот же оптыс с оленеводами. Дошли ждос стада в 1000 оленей и оленевод всегда точно отвечал типа Сохатого не хватает, однако.
Тут важен сам подход
А вот тот код написал троеччник или отличник это еще нужно доказать. С кодом функции в пару тысяч строк например я еще могу разобраться. Но если троечник начинает делать все «по науке» и разбивать 50 строк на модули, но не в стиле «раздляй и властвуй», а в стиле: разложи листики в конвертики, потом конвертики сложи в коробочки, коробчки положи в ящички, потом подойди к ящичкам и найди где лежит заначка. То это гораздо более утомительно. Прошлая Ваша публикация на данную тему кажется мне более инересной.
А когда решение на четырёх страницах — его ни один отличник в уме не решит. Более того, каждый отличник (и я в том числе) будет сразу записывать именно по шагам, чтобы потом можно было проверить правильность решения.
Опыт с оленеводом немного к другой теме относится. Пастух — он чужих коров пасёт, и у него они действительно сидят в памяти, близкой к кратковременной. А оленевод своё стадо знает с пелёнок, и кратковременная память тут меньшую роль играет — он здесь на долговременную опирается.
Про код могу так ответить. «Отличник» и «троечник» здесь — условные категории. Надеюсь, их не будут воспринимать слишком буквально. Надо же было их как-то кратко назвать. Не писать же каждый раз «лица с хорошо развитым подвижным интеллектом» и «лица с не так хорошо развитым подвижным интеллектом».
Я просто хотел двинуть идею, что если мы видим длинный код — то написавший его человек обладает хорошо развитой кратковременной памятью. А значит, согласно исследованиям «некоторых учёных», и хорошо развитым подвижным интеллектом. И, скорее всего, — был отличником по математике.
А вот обратное — не всегда верно. Некоторые «отличники» (читай: «талантливые парни с хорошо развитой кратковременной памятью и подвижным интеллектом») — да, всё ещё продолжают писать длинные методы. А некоторые — уже набили достаточно шишек, и перешли к коротким.
Вы что — ни разу не видели, как человек дописывает код в процедуру, давно забыв, что было в её начале? Обычное же дело. В итоге длинную глючную процедуру пишет как раз человек, который не смог удержать её в памяти (и благодаря этому почувствовать, что она слишком разрослась).
А функции да, по возможности нужно разбивать на более мелкие — проанализировать 2 независимые функции по 10 строк намного проще, чем одну из 20 строк. Ну и конечно именование функций, параметров, переменных и т. д. очень важно (а особенно важен API).
Положенная в основу статьи ошибка характерна для всех начинающих программистов и отлично описана. Встречается у программистов любого начального уровня, вне зависимости от их школьных оценок. И лечится активным социальным взаимодействием (в виде старших коллег, неодобрительно взирающих на код, который невозможно использовать повторно).
Беда в том, что из-за низкого порога входа такие вот программисты начинают проектировать свои собственные системы. Которые чуть более, чем полностью состоят из таких вот богоподобных функций с кучей предусловий и неясной механикой работы. В таких системах сложные задачи вполне решаются за 150 строк, если вы достаточно «вкурили» странную логику автора. Только вот это будет навык использования этой конкретной системы, а не навык программирования или решения задач.
Если люди считают, что программирование это решение задач с помощью кода — они «кодеры», программисты низшего уровня. То есть, попросту, или хреновые, или начинающие специалисты. Даже отличники при переходе к реальной работе будут начинающими специалистами. Даже отличники будут совершать типичные ошибки новичков. По опыту могу сказать, что отличники чаще не готовы признать себя начинающими. А значит, склонны дольше оставаться таковыми. Отсюда возникает иллюзия ошибок, характерных именно для отличников. На деле же — обычная ошибка новичка.
Кроме ошибки новичка здесь, несомненно, вина школьного образования в целом. Ибо это образование представляет программирование именно как написание кода. А на деле, написание кода — наименьшая и наиболее простая из задач программиста, вышедшего за пределы начального уровня. Если признать, что отличник это такой ученик, который наилучшим образом встроился в образовательную программу, очевидно, он будет тащить за собой больше всего ошибок этой самой программы.
Мой коллега после прочтения статьи сразу же предположил, что из гениев, способных перепрыгивать огромные этапы решения, выйдут совсем хреновые программисты. Опровергну. Главная черта гения: умение предсказывать результат своих действий далеко вперёд. Если этот гений ещё и программист, он не будет подкладывать себе же грабли. Он скорее сразу разобьёт код на блоки, которые будут удобны для повторного использования ему самому.
Из всего вышеописанного следует, что оценки когнитивной психологии в общем смысле здесь применять неверно. Они, несомненно, важны в деле программирования. Но важны в другом месте. Человеку, который может удержать в голове больше объектов, проще построить грамотную архитектуру. Проще разбить задачу на подзадачи наиболее оптимальным образом. В общем смысле, эффективная архитектура не должна оперировать больше, чем пятью объектами на каждом уровне. Это исходит именно из оценки когнитивной психологии. Достичь этого можно кучей методов композиции и уменьшения связности. Чем больше объектов в человек может удержать в голове в один момент времени, тем лучше он выделит наиболее сильные связи и устранит слабые. Самый важный навык — умение быстро переключаться между уровнями архитектуры: между переменными в функции, системными объектами и промежуточными уровнями абстракции. Но это уже тема для статьи, а комментарий как-то подзатянулся.
А про когнитивные метрики — так я же как раз об этом. Как сообщить кодеру, что пора завязывать кодить и настало время подумать об архитектуре? Вот тебе метрика: как только вылезет выше семи — начинай грамотно проектировать. И кстати, такая когнитивная метрика сама по себе работать не будет, а только в комплексе со всеми прочими метриками. Потому что про связность и зацепление тоже надо помнить, и прочее, и прочее.
Тут возникает другой аспект: какому-нибудь «сеньору», как правило, очевидно, где решение хорошее, а где — плохое, без всяких метрик когнитивной психологии. Эти самые метрики нужны для людей, которые в самой профессии не смыслят. То есть, для внешних управленцев. И мы внезапно оказываемся ну очень далеко от исходной темы.
Кстати, кто-нибудь смотрел исходники, которые выложил ВК? Там ведь сплошь гении и наверняка есть кучи гениальности по всем проектам.
github.com/vk-com/kphp-kdb/blob/master/queue/queue-engine.c#L1486
а дело не только в длинне или непонятности синтаксиса но и в общих правилах структурирования кода
Простая функция, пусть и довольно длинная.
Первая же строчка:
int r, c;Что такое r и что такое c? Это первая строчка функции! Хотя бы коммент оставили.
Хотя фиг знает, может это общепринятное соглашение, и эти r и c используются 100 раз в коде, но что-то я сомневаюсь, что они писали 100 похожих парсеров.
И почему функция парсера конфига ничего не возвращает? Причём с первой же строчки начинает менять глобальные переменные. Глобальные надо менять, когда реально состояние приложения изменилось. А тут всего лишь парсер конфига.
Что такое r и что такое c? Это первая строчка функции! Хотя бы коммент оставили.Зачем? Посмотрите где они инициализируются — и всё станет ясно.
C99 ещё не везде, так что да, приходится описывать переменные в начале функции, а не там, где они нужны…
Хотя фиг знает, может это общепринятное соглашение, и эти r и c используются 100 раз в коде, но что-то я сомневаюсь, что они писали 100 похожих парсеров.Ноборот — они там 5 строчках используются. И в них легко понять — что это за переменные и что они делают.
Вы пытаетесь читать программу на C89 опираясь на подходы какого-то другого языка (C++? Python?) — отсюда сложности.
Глобальные надо менять, когда реально состояние приложения изменилось.Опять-таки — это подход современных языков и современных приложений. Которые, типа, могут прочитать конфиг и поменять его «на лету» (ага, три раза). Программки на C обычно читают конфиг один раз и если он неправильный — выдают ошибку. Зачем тут лишние сущности устраивать?
Просто я обычно даю переменным имена, которые явно показывают, для чего они предназначены. Сокращать до одной буквы очень редко имеет смысл.Старая привычка от которой просто сложно отказаться. Как с курением.
Старые мониторы (80x24), нет IntelliSense… а переменные нужно обьявлять в начале функции в C89 (до первого оператора). Когда-то это имело смысл. А если ты пишешь 10+ лет в таком стиле, то уже как-то и не видишь ничего страшного в одной букве. c(haracter), s(tring), p(ointer) — наиболее частые сокращения. «r»… думаю r(ead result) имелся в виду.
То есть да — не могу сказать что это прям код — верх изящества, но он вполне в духе «old school» и не сказать чтобы уж прям ужас-ужас…
P.S. Вообще, конечно же, лучше описывать переменные где используешь… C99 и C++ не зря придумали (и давно), но грехи (Windows и MSVC) не пускают…
Но ещё в своём языке я привык объявлять переменные по мере использования. Просто
const c — такого не бывает, а вот const c = s[i] — может быть, т. е. несмотря на короткое имя, назначение очень понятно.Но таких коротких переменных можно пересчитать по пальцем, даже a — array — не всегда хороший вариант, потому что если это не совсем временная переменная, лучше назвать users, к примеру. А там все переменные так названы =)
C99 ещё не везде, так что да, приходится описывать переменные в начале функции, а не там, где они нужны…
Конкретно в этом коде переменные в середине функции объявляются. (int was_created = -1;) — мне это сразу резануло глаза. Не знаю что в этой "фиче" хорошего, тоже писал так 10 лет назад по глупости, потом перестал.
Потому что о программах без глобального состояния проще
Не всегда. А в случае высоконагруженного специализированного процесса — почти всегда наоборот. А если точнее, то "глобальное состояние" там — это состояние всего сервера (железки) с операционной системой. А любой процесс — уже локален, считайте что это экземпляр объекта "сервер" со своими полями. Вас же не смущает, когда методы класса меняют состояние класса, а не только свои локальные переменные? А оверхед "модного ооп-кода" убрали — он тут ни к чему, экземпляр этого объекта строго один на процесс, а может быть и на серверную железку, и поддержка нескольких экземпляров одновременно только создаёт лишнюю нагрузку (например обратиться к this->a всегда сложнее чем к глобальной переменной a).
Почему специализированный у нас процесс, а состояние — вся железка?
Потому что там ещё было слово "высоконагруженный". В таких случаях на каждого функционального демона выделяется своя железка, а то и несколько железок (как в вк). И цель оптимизаций — выжать максимум из железки для конкретного одного демона, и полностью плевать на сценарии, где на том же компе будет запущено что-то ещё.
то бранч индирекшон предиктор быстро обучится.
Вам всё равно придётся держать лишний занятый регистр под этот this и тратить несколько лишних байт кода чтобы в него загрузить нужное значение. Может быть это и не особо большой оверхед (хотя насчёт занятого регистра мне всё-таки кажется что заметный) но польза то от этого вообще нулевая в данном случае.
И да, индирекшон всё равно есть.Где? %rip это ж не регистр, это просто запись такая, адрес в декодере вычисляется…
В 32-битном режиме адрес задаётся прямо в команде. А в 64 битах так сделать нельзя: требовалось бы 64-битное смещение, что расточительно.
Потому кроме режима абсолютной адресации, который позволяет добраться только до первых 4GB (на самом деле первых 2GB и последних 2GB, но не суть), в x86-64 есть ещё и «адрес относительно текущей инструкции». И в 64-битном режиме именно он и используется обычно. Вот именно его мы видим по вашей ссылке.
Дополнительного времени при работе процессора он не требует и пайплайн не сбивает: адрес инструкции декодеру известен, сумматор — это меньше тысячи транзисторов, так что μop получает уже сразу адрес из декодера.
А при обращении к «обычному» регистру ничего подобного сделать нельзя. Там — нужно «вынуть» адрес из регистра, возможны разного рода задержки и прочее.
А адрес глобальной переменной относительно текущей инструкции на каком этапе становится известен?Зависит от настроек компиляции. Обычно на этапе статической линковки, но бывают и исключения. Смотрим сюда. Первое окошечко — главная программа, там индирекции нет. Второе окошечко — разделяемая библиотека, скомпилированная нормальным программистом, там тоже индирекции нет. Третье окошечко — варинт «на отвали», там индирекция есть.
Какого рода задержки?Хотя бы уже тот факт, что вы задействуете больше исполняемых устройств может аукнуться.
В горячем коде оно и так всё будет хорошо.Нет. В зависимости от режима адресации могут получиться задержки на такт из-за необходимости пересылки адреса из блока вычисляющего адрес в ALU. Для «горячего» кода — это прилично.
P.S. Впрочем обычно потеря 10-15% скорости не так критична, как потеря безопасности. Потому глобальные переменные сейчас часто не используют даже для очень «горячего кода». Но таки задержки эти есть — даже на самых современных процессорах.
Это уже лучше на личной машине попробовать, из godbolt'а мне не удалось выковырять нужный выход, но соберите на x86_64 бинарь из двух файлов (с пустойО боги. Вам про разницу между статическим и динамическим линкером никто не рассказывал? И про то, чтоdoFoo()рядом, например) и сравните его дизасм с дизасмом объектного файла из одного только main. Во втором случае там будет что-то вроде0(%rip), который именно что заполняется линкером.
relocationы бывают динамическими и статическими? О чём мы тогда, вообще, тут говорим?Конечно в обьектном файле там будет
0(%rip)! А вот уже в исполняемом файле или в динамической библиотеке — там будет конкретное число.Вы, я извиняюсь, обьектный файл собрались запускать или как?
А загрузчик в ОС — как раз эти самые ваши исключения, по крайней мере, для не-PIC-кода (я в исходном комментарии описался на эту тему, да).Ну нельзя так. Просто нельзя. Если вы понятия не имеете о том, как работают обьектные файлы, динамические библиотеки и загрузчик OS — то не очень понятно, о чём дальше говорить. Почитайте хотя бы Drepperа, что ли…
С точностью до определений, считать foo(%rip) за индирекцию или нет.Давайте не считать ангелов на кончике иглы, а? Мы вроде об эффективности говорим. То, что существует в промежуточном представлении, но не в итоговом бинарнике на эффективность ну никак не может влиять. А вопросы терминологии — не так важны и интересны.Если количество считанных из конфига байт — такой же горячий код, то ну я вообще не знаю, что тут ещё можно сказать.Какие-нибудь флаги вполне могут проверяться внутри «горячего» кода, а заводить часть конфига в виде глобальных переменных, а часть — в виде локальный или какой-нибудь структуры — это уже перебор, согласитесь.
Если класс на стеке, то там скорее всего оно всё относительно (%rsp), и опыт показывает, что можно забить.На стеке у вас скорее всего будет какой-нибудь другой класс. Вряд лы вы будете передавать класс с настройками программы по значению (ну то есть можно, конечно — но это ещё большее извращение, чем глобальные переменные).
Но как-то мы уже далеко не в ту степь зашли, ИМХО, и всерьёз обсуждать качество кода для парсинга опций в контексте высоконагруженных серверов — это та ещё импликация, но выводить её некорректность лень и непродуктивно.Это вы не в ту степь зашли, судя по вашим примерам.
Вы уже не просто «за деревьями не видите леса», а обсуждаете какие-то трещинки на поверхности коры, не обращая внимание на то, является ли этот кусок коры ещё частью дерева или нет.
Давайте я попробую вам лес показать? Это же несложно!
- Время разбора конфи гурационного файла — мало кого интересует. За исключением очень редких и патологических случаев — это очень быстро даже если конфигурационные файлы большие и сложные.
- Время обращения к данным (флагам и разным настройкам), напротив, может быть очень критически важным и может случаться даже в самых внутренних циклах (например какой-нибудь флаг может влиять на количество вызовов VRECPS в вашем алгоритме).
- Если ваша программа не требует хитрых «атомарных» изменений конфига «на лету», то результат разбора конфига разумно поместить в набор глобальных переменных
- А вот уже временные переменные, предназначенные только для разбора конфига — лучше бы в глобальные переменные не класть. Тут я согласен. Ибо на скорость не влияют, а место занимают.
В это смысле у GNU LD парсер почище будет. Я больше про него думал, чем про пример от VK. Пример от VK, конечно, доставляет. Код в стиле C89, но при этом с кучей C99 фич — это нечто. Кто и зачем такое пишет — мне непонятно.
Зачем
rpc_default_ct глобал — я могу понять. И даже то, что парсер конфигов всё прямо туда пишет — не страшно. Но вот зачем делать глобальной переменную config_buff — загадка, этого я ничем обьяснить не могу…И GOT и прочие механизмы для релокейшнов как обеспечивают это самое ваше конкретное число, ради интереса? Или я опять не в ту степь зашёл, и это всё не то?Нет — это уже почти то. GOT «включается в работу» когда ваш символ экспотрируется из библиотеки. Вот эта ссылочка — она ровно про это. Третий вариант.
И там хорошо видно — у вас либо GOT, две инструкции и
%rbx, либо одна инструкция, прямой доступ и %rip. То есть да — если у вас переменнай экспортируется из библиотеки, то доступ к ней будет через индирекцию — но и обычный регистр, не %ripКак-то я упустил пропажу таких выражений из итогового бинарника. Если с малым влиянием ввиду лёгкости работы для декодера (но это нужно бенчмаркать) я ещё готов согласиться, то это уже как-то перебор.Из бинарника пропадают релокейшены. Правда-правда. Ну проверьте:
$ cat test.c
int i;
int main() {
return i;
}
$ gcc -O3 -c test.c -o test.o
$ objdump -dr test.o
test.o: file format elf64-x86-64
Disassembly of section .text.startup:
0000000000000000 <main>:
0: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # 6 <main+0x6>
2: R_X86_64_PC32 i-0x4
6: c3 retq
$ gcc -O3 test.o -o test
$ objdump -dR test
test: file format elf64-x86-64
Disassembly of section .init:
...
Disassembly of section .text:
0000000000000530 <main>:
530: 8b 05 f6 0a 20 00 mov 0x200af6(%rip),%eax # 20102c <i>
536: c3 retq
537: 66 0f 1f 84 00 00 00 nopw 0x0(%rax,%rax,1)
53e: 00 00
...
Как видите всё было сделано на этапе сборки бинарника, ничего для динамического линкера не осталось…
Эти флаги можно отдельно внутрь горячего кода и передать (и я бы сказал, что и нужно).Ну это вопрос очень и очень философский. Глобальный флаг — быстрее. Передача в горячий код — медленнее, но более гибко.
3 — нет. Это не дело кода, парсящего конфиги.А почему, собственно?
Я, как бы человек простой. Если в меня начинают бросаться всякими вумными словами типа «неSOLIDно», «нарушение инкапсуляции» и прочее, то я обычно останавливаю этот поток сознания и прошу снизойти до «простых смертных». И описать пример цепочки начиная с бизнес-требований.
Ну то есть «если мы сделаем по-другому и владелец нашего бизнеса потребует X, для чего нам потребуется Y и мы можем это сделать без переписывания половины программы только если у нас будет выполняться условие Z»… ну и кончаться это должно заключением «вот поэтому -это не дело кода, парсящего конфиги». Иначе — это архитектурная астронавтика какая-то.
И рядом в комментарии напишите только, зачем это сделано, какая методика оценки, и как оно оценивалось.Извините — но нет. Вы предлагаете заменить простой, понятный, быстрый код на нечто более сложное, менее удобное в использовании и менее понятное. Так что это вам нужно обьяснять — какую проблему вы, тем самым, решаете и чего хотите добиться… после чего уже можно оценить вероятность того, что такая проблема кому-то в работе реально встретится…
Почему 63 байта на длину хоста магическим числом?RFC1025: labels must be 63 characters or less.
Где ещё 63, 62 и 64 вылезает из проверок?Не понял вопроса.
Что за танцы сКто вам сказал, что читающего код здесь кто-то ненавидит?sиcна строках 1520-1521 и потом на 1534-1535? За что так ненавидеть читающего код?
gethostbyname требует там '\0', а мы там имеем что-то другое… что такого странного в том, чтобы записать туда требуемый '\0', а потом вернуть всё «как было»?А тестами это вообще покрыто? А как автор покрывать будет? Куда послал, я не расслышал?А для вас тесты — как религия? Или? Они, вообще-то, средство, не цель.
То есть да, можно сделать этого код более модульным, более удобным для рефакторинга и прочее… Но это точно окупится? Человек, могущий менять конфиги у вас на сервере — и так, в общем-то, имеет над ним более-менее полный контроль… так зачем всё это дело обильно покрывать тестами и, скажем, фаззить? С чем боремся-то?
И кто занимается подстановкой правильных значений в GOT?Динамический загрузчик во время запуска программы.
Кто занимается подстановкой правильных значений перед %rip?Статический линкер во время сборки программы. В готовой программе, в бинарнике, там уже ничего не меняется никогда.
В бинарнике — это не релокейшен. Когда линкер из нескольких обьектных файлов делает бинарник там записывается фиксированное число, которое больше уже никогда не меняется. Что там было на этапе сборки программы — никого не волнует, мы же всё это обсуждаем в контексте влияния на скорость.Из бинарника пропадают релокейшены. Правда-правда.Я говорил оfoo(%rip).
Ну хоть парсер опций-то у вас отделён от вычисляющего кода, и они не перемежаются, аки вермишель?Отделён, конечно.
Соответственно, какая-то высокоуровневая обёртка над горячим кодом может решить, передать самому коду это как параметр, или выставить одному ему известную глобальную переменную, или ещё что сделать?А это зачем? Пользователь программы может задать флаг, если хочет, а обёртке это зачем?
И по моему опыту работы с другими людьми, те, кто любит обмазывать код глобальными переменными и всякими однобуквенными обозначениями, до оптимизации алгоритма просто не доходят, потому что очень часто тонут в неподдерживаемом коде.Не знаю, не знаю. У нас этим целые команды занимаются. Хотя однобуквенные обозначения у нас не в чести…
Изоляция систем и сужение интерфейсов между ними — естественное требование.И вот тут, как раз, глобальные флаги — отличная вещь. Ибо когда «высокоуровневая обёртка над горячим кодом может [что-то там] решить» — это как раз и нарушает принцип изоляции.
Ибо получается, что параметры кроме пользователя с командной строки или конфигурационного файла кто-то там ещё может менять.
Чем в коде больше глобального неохраняемого состояния (и вообще чем больше состояния, но то такое), тем он менее простой и понятный.Не совсем. Чем больше мест, которые могут менять состояние — тем сложнее во всём этом разобраться.
Подход «флаги глобальны, читать их может кто угодно, но менять может только пользователь программы» — работает вполне надёжно. 3325 флагов у программы копирования файлов — никого особо не напрягают, так как все их мало кому приходится «дёргать» (думаю что практически — никому).
А всё потому, что чтение хостнейма и его валидация размазана что по kbd_gethostbyname (почему бы ей не передавать рейндж указатель на начало и конец строки, чёрт возьми?) и по вызывающей функции.В С функции получают строку закрытую нулём. gethostbyname — не исключение. Можно было бы создать язык, где они принимали бы рейнджи… но это уже будет не C.
Кстати, в kbd_gethostbyname есть обработка случая, когда длина строки больше или равна 128. Так что искомая проверка на 63 символа — это баг? Или тут должна быть не kbd_gethostbyname? Или тут может быть не только хостнейм? Или что вообще почему тут так?Можете посмотреть на код, однако. Или нет?
kbd_gethostbyname запросы кеширует, но только для коротких (не более 128 символов) имён. Для длинных — пропускает как есть. Это механизм вообще не имеет никакого отношения к ограничению на 64 символа, которые приходят прямо из DNS'а. В главной программе допускаются только весьма ограниченное множество «правильных» имён хостов… хотя непонятно — зачем их на этом уровне-то проверять, когда gethostbyname(3) это сама должна сделать.Потому что кривая работа с памятью — это не только всегда свежие 0-day, но и ваш личный геморрой по отладке багов, проявляющихся через 10 вызовов функций, 10 секунд или 10 часов в совсем другом модуле. Спасибо, я этого в своё время наелся достаточно.Для этого Asan есть.
P.S. Вот, кстати,
kdb_gethostbyname огорчила больше. В частности тем, что граница в 128 символов для кешированного имени выглядит какой-то абсолютно произвольной… и встречается в коде далеко не в одном месте. Тут уже и константу бы не грех сделать…Потому что о программах без глобального состояния проще
Не всегда.
Вы представляете себе, чем бы являлись системы логгирования, будь они строго локальны? Т.е. инициализация происходила бы на каждый класс?
(Это был риторический вопрос, можете не рассказывать мне что такое MonadWriter)
Глобальная static-переменная мало чем отличается, у неё точно так же ограничена область видимости окружающим её кодом (для static-поля окружающий код это класс, для глобальной static-переменой — файл исходника с ней, а есть ещё локальные static-переменные с областью видимости — функией, где она объявлена).
Это относится к функциональным языкам — у них есть своя специфика, которая и позволяет обходить глобальные состояния… за счет глобальных монад. Да что уж, предлагаю пойти дальше — класс, функция — это тоже глобальный объект, в своем роде. Только вот их глобальность скрыта ЯП и не доступна, обычно, программисту. Хотя умельцы патчат классы в рантайме прямо в виртуалке при загрузке этих классов — AspectJ как пример.
И да, как решение для ликвидации глобального состояния — ФОП отличное решение.
А в остальных случаях как? Или идеализм и перфекционизм вездесущи и все строем должны идти учить хаскель?
Ну давайте посмотрим на «с».
c = *s;Ок, пошли смотреть на «s»
char *ptr, *s;Хорошо. Ищем инициализацию «s».
ptr = s = cfg_curУра! Всё сразу понятно стало, сэкономленное на оформлении кода время окупилось, разработчику — премию (сарказм!).
Вот так и ходишь и смотришь большую часть времени, вместо того, чтобы просто читать понятный код.
Такое оформление, по которому нужно «Посмотрите где...» — это то же самое, что и «идите на...» по отношению к тому, кто в дальнейшем будет работать с кодом.
Пойдешь вот так, как Вы предлагаете, смотреть, что означает переменная "_suprknadel", а через полчаса обнаруживаешь 15 открытых модулей и еще больше вопросов.
Поубивал бы.
Извините за эмоции, но я только что вынырнул из модуля в 17000 строк, с которым работаю :(
В когнитивной психологии ту часть памяти, в которой непосредственно производятся вычисления «в уме», называют кратковременной и рабочей. Там всё сложно и неоднозначно, но как её ни назови, а объём этой памяти сильно ограничен. Разные исследователи называют «магические числа» семь и пять. Это средние значения. Объём «рабочей» памяти зависит от обстоятельств и коррелирует с интеллектуальными способностями.
— Петька, приборы?
— 42.
— Что «42»?!
— А что «приборы»?
В каких единицах числа приведены? В битах? Байтах? Вариках?
Это я к тому, что число объяснять надо. Вы говорите, что рассматривается случайная последовательность букв, но в тексте этого нет. Да и код отнюдь не случаен. Да даже для случайной последовательности следует указать размер алфавита «объектов» (7 букв запомнить — не 7 слов, что в свою очередь не 7 иероглифов).
А вот семь букв или семь слов (знакомых) для нас — это как раз всё равно. Потому что те и другие мы обрабатываем как целостные объекты, гештальты.
А Вы знали значение этих иероглифов?Разве это существенно? Скажем, иероглифы хираганы я могу запомнить вряд до 15, если при восстановлении будет под рукой таблица, и до 7-10, если не будет. Китайские иероглифы даже в количестве 5 штук я не восстановлю, даже если под рукой будет соответствующая таблица. Значение ни тех, ни иных я не знаю. Просто алфавит меньше.
А вот семь букв или семь слов (знакомых) для нас — это как раз всё равно. Потому что те и другие мы обрабатываем как целостные объекты, гештальты.Опять же. Что проще, запомнить «оывхзку» («о! ы-ы-ы-ы… вот хз… ку» — уже запомнил) и «овации пароходом гештальту пенсне шизофазия велюром седло»? Букв-то всего 33 и многовероятно появление слогов и других знакомых групп. А слов больше и далеко не каждое вызывает устойчивый запоминаемый образ.
Или же под объектом в тексте понимается именно образ? Но тогда как сделать однозначное сопоставления объекта и формальных языковых конструкций (букв, слов, словосочетаний)? У каждого же по-разному.
Опять же. Что проще, запомнить «оывхзку» («о! ы-ы-ы-ы… вот хз… ку» — уже запомнил) и «овации пароходом гештальту пенсне шизофазия велюром седло»?Во втором случае очень много редких слов, а часть — явно распадается на два (шизофазия) или вообще не воспринимается как слово (гештальту). Если бы там не было таких ужасов — разницы бы не было.
А слов больше и далеко не каждое вызывает устойчивый запоминаемый образ.Это да, некоторые слова будут занимать не один «обьект» в голове, а два или три.
Или же под объектом в тексте понимается именно образ? Но тогда как сделать однозначное сопоставления объекта и формальных языковых конструкций (букв, слов, словосочетаний)? У каждого же по-разному.Именно поэтому мы не можем сказать точно сколько обьектов нужно держать в голове, чтобы осознать как работает функция. Можем только оценить.
Но можно заметить, что 5-7 обьектов — это столько, сколько мы можем «захватить» не напрягаясь. Если «загружать» в сознание обьекты постепенно и если это — не случайные, никак не связанные друг с другом обьекты, то можно уместить гораздо больше.
При написании программ очень мало функций укалыдваются в это ограничение — потому и требуется над кодом посидеть и подумать, чтобы понять. Даже если код хорошо написан.
иероглифы хираганыВ хирагане нет иероглифов. Это слоговая азбука. Т. е. в японском используют сразу хирагану, катаканы и иероглифы одновременно (например, начало слова может писаться иероглифами, а конец хираганой).
Знаки хираганы называются знаками хираганы (или знаками каны, если более обобщённо).
Проще запомнить много знакомого, чем мало незнакомого. Например, те же иерогрифы. Нам они кажутся темным лесом, и даже один нам трудно запомнить, зато читая многие слова, напримр: элктчтво, мы его прочтем, даже если нет некоторых букв, просто по памяти. А память наша держит сотни и тысячи русских слов.
Резюме понравилось.
Любая индустриальная технология основана на расчётах, на возможности их проверки. Любой алгоритм должен давать простое понимание границ его применимости. Computing science должна быть доказательной и повторимой, как любая наука.
А отличники пишут запутанный код 1) из-за спешки 2) Из-за неуважения к себе и другим
Некоторые из отличников пишут длинный запутанный код потому, что могут это делать, интеллект позволяет. А опыт ещё не подсказывает, что так делать нельзя.
Нам, отличникам, всё это ни к чему. Зачем писать столько ненужных промежуточных действий, когда можно сразу готовый ответ?
Звучит примерно как: «Тестировать свой код — это для троечников. Зачем писать столько ненужного лишнего когда, если программа и так будет работать как-нибудь?» Ну… Чем не точка зрения, конечно.
Я тоже училась на все пятёрки и помню, какой это был понт, когда ты промежуточных вычислений не записываешь. Зачастую это приводило к ошибкам, которые трудно было отследить и исправить (что осложняло работу учителя в разы, как я поняла в дальнейшем, когда сама стала преподавать), но мы велись, и это всё счастье до сих пор живо в наших школах. Но мало ли на что школьники ещё ведутся: что курить — это круто, что если все пойдут с крыши прыгать…
Называть ли это всё «горем от ума»? Я бы, скорее, говорила о попытке самоутвердиться в своей социальной группе. У разных групп — свои критерии «крутизны», одними и теми же методами стать крутым вообще везде сложно (и это очевидно). А оценки — это просто оценки, они учителе-зависимые. Когда ты ещё ребёнок и не понимаешь, что оценивание твоей контрольной работы на 5 или 4 не имеет ничего общего с оценкой тебя, как человека, ты начинаешь за этой оценкой гоняться. А учителя — разные. Кто-то за многостраничную работу сразу ставит 5, не читая (ибо лень), а кто-то гарантированно снижает на балл-другой (потому что читать было лень, но всё равно пришлось).
Если ребёнку на уроках информатики начать снижать оценки за нечитабельный код, то через пару месяцев у «завзятого отличника» код станет самым читабельным в классе. Не думаю, что он от этого как-то резко поглупеет.
Школа она в любом случае и хорошо, что была, и хорошо, что была окончена. Если её выкинуть из головы, хуже не станет.
Почитайте «Программный код и его метрики», и особенно метрики Холстеда. Там много пищи для размышления.
А всякие количественные метрики это ерунда — ту же самую программу можно переписать в другом виде чтоб весь тот расчёт был другой, то есть он не репрезентативен.
Нет пока ещё такого алгоритма
Думаю, и не будет. По крайней мере — одного для всех.
Многообразие метрик от равнозначных по солнцеподобности гуру свидетельствует, на мой взгляд, о многообразии одинаково качественных способов достижения цели.
Метрики будут действовать в границах, которые вы обязаны будете выбрать и наложить — выбором языка, парадигмы программирования, платформы, страны проживания, и т.п.
Подавляющее большинство практических задач натуральным образом являются граничными (краевыми) задачами, и чем длиннее граница очерченной области, тем больше гитик.
Есть Цикломатическая сложность некоторые linter'ы ее умеют считать и выдавать предупреждение, например rust-clippy
До сих пор помню один из самых обидных фейлов в жизни.
На одной из пар (насколько помню, по диффурам) была задача, что-то там про пулю, которая врезается в крутящийся барабан. Решил её раньше всех – сразу было ясно, что всё решается методами простейшей физики и геометрии, тупо школьный курс же.
Но получил «трояк». Ибо препод решил, что «не по уставу». Даже несмотря на то, что ответ полностью сошёлся с ответами
Мораль сей басни такова – хорош не тот, кто просто зубрит, а тот, кто понимает предмет в целом и суть конкретного вопроса в частности. И на оценки тут уже плевать – они важны только лишь в узких рамках ВУЗа, а дальше жизнь сама расставит всё и всех по своим местам… ;)
P.S. Хорошо, что хоть по информатике нам достался хоть и «советски»-отсталый, но крайне здравый преподаватель – «неуставные» решения не рубил и не критиковал, а сам приходил от них в восторг. До сих пор вспоминаю его с искренней теплотой… ^_^
Хорош тот, кто в состоянии в задании преподавателя увидеть задачу для себя. В данном случае она должна была быть "изучение конкретных подходов к решению дифференциальных уравнений", а не в "раньше всех сказать ответ". Ты тройка, видимо, была именно по дефурам.
увидеть задачу для себя
Вот именно об этом я и говорил.
Образ мышления отличника – решить всё «правильно, как учили». Образ мышления программиста – решить всё максимально рационально, пусть даже это будет «не канонично». Иначе говоря, «труъ-программистское решение» – найти путь к тому же (!) результату, но меньшими усилиями и меньшей тратой ресурсов. Оптимизация же, и всё такое (о чём, кстати, вообще и статья)…
Конечно, идеально, когда оба варианта совпадают. Но если вдруг не совпадают – то, всё же, второй вариант видится как-то намного более предпочтительным.
Ты решение из другой сферы взял, и при этом не достиг цели.
Вот если бы ты в контексте дифуров придумал свое решение, пусть даже менее элегантное — это было бы круто.
Ваш вариант — это в соревновании бега в мешках пробить в нем дно и бежать.
Решение не подпадает под заданную цель. Считайте это как ТЗ.
В целом же, в абстрактном случае, получи вы такую же задачу с просьбой решить — ваше решение было бы как раз самым правильным, потому что дифуры — это микроскопом гвозди забивать, когда есть более простое и доступное решение.
Где же в вашем первоначальном комментарии "правильно, как учили"?
Решение не подпадает под заданную цель. Считайте это как ТЗ.
ИМХО, для программиста заданная цель – не конкретные методы решения, а решение в целом. Оно и является настоящим ТЗ (если только, конечно, ограничения в методах не вызваны объективными причинами).
дифуры — это микроскопом гвозди забивать, когда есть более простое и доступное решение.
Вот, оно самое, о том и речь!
Это и есть «образ мышления настоящего программиста». Что также во многом зависит и от методов обучения, кстати. Если учили думать – ищи методы оптимизации. Если учили решать «в лоб», «только как положено» – забивай гвозди микроскопом и прочими не предназначенными для этого гаджетами.
Ведь настоящая цель программиста не просто «решить и проставить галочку» (это как раз пресловутая «проблема отличника», описанная в статье).
Настоящая цель – решить оптимально! Чтобы потом не получались тонны «индусского кода» даже в простых проектах (что как раз схоже с решением той приведённой мной ранее задачи – моё было в несколько строчек, «оригинальное» в несколько раз длиннее)…
Чтобы решать _оптимально_ надо уметь эффективно использовать широкий спектр методов, понимать как они работают. Если же вместо того, чтобы отрабатывать эти методы, ты занимался «ищи методы оптимизации», то никакого уменя не будет и оптимизировать, соответственно, будет нечего.
Если человек вечно рисует картинки, вместо того, чтобы формулировать диффур, то он просто и не научится формулировать диффуры (тот самый наук, на развитие которого и дают подобного рода задачи). Это на самом деле _очень_ сложно (в реальных задачах, в учебных задачах для тренировки, конечно, просто).
Если же вместо того, чтобы отрабатывать эти методы, ты занимался «ищи методы оптимизации», то никакого уменя не будет и оптимизировать, соответственно, будет нечего.
А разве кто-то говорил, что одно исключает другое? Вовсе ведь нет – никто не призывает отказываться от навыков составления диффуров.
Говорилось о том, что важно понимать, какие конкретно методы наиболее оптимально использовать конкретно в этой в поставленной задаче. Если диффуры – то диффуры, если простая геометрия+арифметика – значит, именно их.
Иначе говоря, превыше всего соотношение «усилия/результат». И, кстати, не только у программистов – без этой формулы не было бы вообще совершенно никакого технического прогресса. Поэтому ради данной формулы всегда стоит хотя бы немного обдумать оптимизацию задачи перед тем, как начинать решать её «в лоб»…
В противном случае, условно говоря – так и будут использовать кучу «линейного» кода вместо того, чтобы предварительно подумать над более изящными и скоростными решениями.
P.S. Кстати, в том примере также виден явный «подход отличника» – со стороны составителей задачника (не помню уж, кто там был). Те самые «шоры» просто помешали им сразу же понять, что в этой задаче вообще нечего городить диффуры. ))
В современных условиях, если оценка времени "решить в лоб" меньше оценки "подумать и найти изящное решение", то по умолчанию надо выбирать "в лоб". Думать надо начинать, когда решение "в лоб" станет узким местом. Увы, но так :(
А если получается наоборот, то это тоже своего рода «профессиональная патология», которая называется перфекционизмом. Что является другой крайностью – эта штука в излишних количествах может мешать работе не менее сильно, чем отсутствие оптимизации.
Так "по умолчанию" означает, что разработчику принимать решение не нужно, оно уже принято за него.
Хороший разработчик тем и отличается от «масс-кодера», что способен поспорить за действительно правильное решение. Иначе говоря – ему НЕ плевать на результат работы, он не просто пассивный исполнитель из серии «любая тупость за ваши деньги».
Да и вообще, собственно, это касается настоящих профессионалов в совершенно любых областях, не только айтишных.
И все мои слова означают как раз то, что спорить с ТЗ порой чертовски нужно – если видите либо его некорректность, либо изъяны в требуемых методах, либо ещё что-то, либо всё вместе.
На то вы и специалист, чтобы знать свою работу лучше заказчика. И чтобы при необходимости указать ему на ошибки и/или альтернативные варианты решений.
P.S. При этом вновь оговорюсь, что даже в этом благом деле нужен разумный баланс между реальными обоснованными замечаниями к ТЗ и собственными амбициями. Иначе, с другой стороны, получается не профессионал, а просто скандалист-социофоб с манией величия… ))
Потому что:
по умолчанию надо выбирать "в лоб"
Но принятие такого решения – тоже есть в своём роде оптимизация.
В целом индустрия приняла такое решение в качестве умолчания, для ситуаций когда выбор способа решения за исполнителем — по умолчанию оптимизировать нужно по скорости разработки(в кратко-, средне- или долгосрочной перспективе — локальные нюансы).
Потому что первому таки-надо решить задачу. Второму-таки нужно научиться определённым приёмам.
Для разработчика — во многих случаях «лобовое» решение — правильный выбор.
Не «правильное» – а просто самое удобное (что есть разные понятия). Особенно если всё поставлено на поток и надо штамповать по стопицот проектов в месяц – тут уж не до глубоких размышлений, разумеется…
Не всегда могу назвать это халтурой, но и высоким профессионализмом назвать тоже не могу. Как уже писал – выбор между вариантами «в лоб» и «как лучше» зависит от множества параметров…
по умолчанию оптимизировать нужно по скорости разработки
Во-первых, речь не только о скорости исполнения, но и о скорости разработки…
А) Три дня мудохаться, писать «линейный» код. После каждого исправления переписывать большую часть.
Б) Один день подумать, ещё за день написать чётко структурированный код, в котором всё строится всего на паре-тройке ключевых параметров. Исправления делаются за несколько минут.
В первом случае – решение «в лоб».
Во втором – та самая оптимизация.
Недавно как раз был такой веб-проект. Нанятые разрабы писали всё сразу «набело» (то бишь, «в лоб») – в итоге чего каждое исправление/комментарий вылетали минимум в день-два (а то и больше) полного переписывания всех функций, плюс полной отладки заново. Просто вот их так научили – не думать, сразу писать.
После всей ругачки и «поучений» (кряхтя, вспомнил все азы) – таки добились того, что теперь в проекте любые исправления обрабатываются максимум за пару-тройку часов. За счёт той самой оптимизации кода, да…
И в каком варианте в итоге получилась бОльшая скорость разработки, как вы считаете?
Я не зря упомянул про разносрочные перспективы.
ИМХО – разработчик сразу (!) должен писать так, чтобы быть готовым к любым возможным исправлениям. То есть – сначала продуманная структура, только потом код.
Тем более, что ему же самому придётся нереально мудохаться, случись вдруг какие действительно серьёзные исправления. Если даже не «профессионализьму ради» – так хоть ради собственного комфорта…
P.S. Не зря ведь есть старинная пословица: «Семь раз отмерь, один отрежь». ;)
К любым возможным исправлениям всегда быть готовым невозможно практически. ЧТобы принять решение о подготовке к некоторым изменениям нужно оценить
- стоимость подготовки
- стоимость внесения изменений при условии подготовки
- стоимость внесения изменений при условии отсутствия подготовки
- вероятность появления необходимости внесения изменений
Чтобы написать действительно хороший проект – прежде всего, вы должны его понять. Это, пожалуй, самая сложная задача. И вот как раз она требует хотя бы 20-25% от общего времени разработки (и это лишь как самый минимум).
А дальше уже относительно «проще». Если вы действительно понимаете проект в самой сути – вы уже с достаточно высокой долей вероятности можете предвидеть, какие конкретно параметры могут меняться в дальнейшем. И на основе этого пишете код, в котором заранее максимально предусмотрены любые возможные изменения.
Совершенно всего, разумеется, предугадать невозможно (клиенты хоть и редко, но бывают крайне внезапны))) – но от будущего геморроя такой подход точно избавит.
То есть, как уже писал ранее – сначала чёткая структура, потом код. Это избавит от совершенно большей части указанных вами пунктов…
стоимость
Кстати, мимо…
Стоимость как раз проще всего накручивать на «тупо-работах» – вроде переделок и прочего описанного выше. И, в любом случае – вашу зарплату это никак не поднимет, всю пенку снимет работодатель…
Предвидеть, что может измениться — это уровень понимания бизнеса, а не проекта.
Предвидеть, что может измениться — это уровень понимания бизнеса, а не проекта.
Не вполне согласен.
Чаще всего – это либо проблемы всё того же написания ТЗ, либо проблемы понимания разработчика.
Если первый вариант – спорьте с ТЗ и/или дополняйте его собственным видением проекта.
Если второй вариант – надо расширять кругозор. Да, как ни странно, но программирование – это не только про код. Это про как раз про понимание сути задачи – на основе коего понимания и пишется нужный код…
А откуда они возьмутся, если человек упорно сачкует вместо того, чтобы их развивать?
> Говорилось о том, что важно понимать, какие конкретно методы наиболее оптимально использовать конкретно в этой в поставленной задаче.
В поставленной задаче требовалось сформулировать и решить диффур. Если автор может сформулировать и решить диффур как-то хитро — да ради бога. Но он ведь в итоге решил совсем другую задачу.
> Те самые «шоры» просто помешали им сразу же понять, что в этой задаче вообще нечего городить диффуры.
Еще раз, смысл решения задач в задачнике не в том, чтобы решить задачу, а в том, чтобы отработать навык. Использование другого навыка — обычный читинг, такой же как пользование калькулятором вместо того, чтобы считать столбик (ну ответ ведь правильный! и время сэкономлено!) или подтягивания, стоя на подставке (ну а чо, подбородком перекладины коснуться надо было — я коснулся!). Подобные «решения» — это никакая не оптимизация. Наоборот — это зряшная трата времени!.. Упражнение, выполняемое неправильно, в лучшем случае — бесполезно, а в худшем — вредно!
А откуда они возьмутся, если человек упорно сачкует вместо того, чтобы их развивать?
Странно вы называете поиск оптимального решения «сачкованием». Результат ровно тот же самый. Времени – намного меньше. Расскажите, пожалуйста, почему это «сачкование»? )))
Но он ведь в итоге решил совсем другую задачу.
Нет, не другую, а ровно ту же самую. Но совершенно другими методами, более сложными. А другой пришёл к цели более простыми методами, да ещё и за меньшее время. Тут в теме уже проскакивало про «забивание гвоздей микроскопом» – так вот это самое оно… )))
Использование другого навыка — обычный читинг
Использование реальных навыков «читингом» не может быть просто по определению. Это и есть верное и самое кратчайшее решение задачи. Без обмана, без подсказок (что и есть читинг)…
Возражения будут?
Потому что человек занимается бесполезными вещами вместо выполнения упражнения.
> Нет, не другую, а ровно ту же самую.
Нет, другую. Задача была — прокачать навык написания и решения диффуров.
> Без обмана, без подсказок (что и есть читинг)…
Читинг — это не обман и подсказки, а просто неверное выполнение упражнения. Которое не дает никакой пользы. Что вам непонятно в примере с использованием калькулятора вместо того, чтобы учиться считать в столбик? Вы ведь честно и без обмана получаете ответ. Быстро и оптимизировано. И прокачиваете навык владения калькулятором (который, в принципе-то, может быть и полезнее, чем умение считать в столбик). Только, думаю, вы не станете спорить что о верном выполнении упражнения здесь речь не идет? Несмотря на то, что вы получили правильный ответ.
бесполезными вещами
Спасибо, вопросов больше не имею… ))))))
> Упражнение, выполняемое неправильно, в лучшем случае — бесполезно, а в худшем — вредно!
Мы сейчас говорим о реальной практике – в которой критически важно не верное выполнение, а верное решение. Суть вещи разные.
Будь я на месте того преподавателя – поставил бы
Иначе получается случай, когда соблюдение «протокола» важнее результата. И очень плохо, когда такой подход остаётся в головах некоторых студентов чуть ли не навсегда.
И статья как раз о том, что «синдром отличника» часто подразумевает непременное соблюдение всех формальностей. Не «как лучше», а «как учили» – что как раз и идёт во вред результату…
Ведь стать отличником можно двумя путями:
- Первый путь, самый лёгкий – усердно зубрить и следовать строго в русле учебной программы, без малейших сомнений в возможности ошибок курса и/или его преподавателей.
Они решают исключительно задачу получения оценки.
- Второй путь, более сложный – пытаться действительно разобраться и «глубинно» понять самому. Стать лучшим не только в оценках, но и в практике применения полученных знаний.
Они решают задачу получения реальных знаний и навыков.
Первых, увы – абсолютное большинство. Именно о них и статья – к большинству задач они подходят «как трамвай по рельсам», используя знания достаточно пассивно, «в режиме read-only». Вторых намного меньше, но именно они и становятся действительно хорошими специалистами, настоящими мастерами своего дела, используя знания активно и сами их дополняя «в режиме read-write»…
P.S. Просто сам имею немалый опыт руководящей работы, от начальника отдела до работодателя – поэтому давно понял, что никакой красный диплом сам по себе не является гарантией того, что перед тобой действительно хороший специалист.
Реальный профессионализм познаётся только лишь на практике – и вот тут, к сожалению, у многих бывших отличников как раз и начинается та самая беда, о которой и говорится в статье, в общем-то…
Нет, мы сейчас говорим об _упражнениях_. В них как раз верное решение совершенно не существенно. Более того — очень часто неправильно решенная задача приносит значительно больше пользы, чем решенная правильно.
А на поиск оптимального метода решения в учебном плане тоже есть свои упражнения, не волнуйтесь. Там-то и надо проявлять гибкость мышления. И, конечно же, человек, который хорошо освоил все методы, продемонстрирует большую гибкость, чем человек, который изучил только половину, а остальные знает кое-как. Тот, кто умеет обращаться только с молотком, везде будет видеть гвозди.
Первые пропустили явно спорную задачу, а второй этого не заметил и дал её аудитории – после чего даже не признал «спорности вопроса»…
А вообще, речь была о том, что больше всего в данном примере удручает даже не столько оценка, а как раз то, что из двадцати человек «подвох» заметил только один – остальные потом удивлялись, что даже ничего не заметили.
ИМХО, это уже само по себе неправильно.
Как уже писал – преподаватель имел все шансы на этом примере провести отдельный (и крайне полезный!!!) «мини-ликбез» аудитории на тему того, как искать кратчайшее решение. Пусть даже это и не было в рамках его предмета, но как специалист он был обязан объяснить это будущим специалистам.
Если, конечно, специалисты интересны ему не только лишь в рамках своего предмета (что неправильно), а в целом (что правильно)…
P.S. Упражнения «на составление», насколько помню, всегда были лишены конкретики. А если требовался конкретный числовой ответ при вводных параметрах – следовательно, была именно задача, и именно «на решение». Даже ответы в конце задачника были одним значением…
Первые пропустили явно спорную задачу, а второй этого не заметил и дал её аудитории – после чего даже не признал «спорности вопроса»…Не бывает задач, которые могут быть решены только одним способом.
Например почти все геометрические школьные задачи можно расписать в координатах и свести к решению уравнений.
Это не значит, что все другие методы не имеют смысла.
Даже ответы в конце задачника были одним значением…Именно поэтому учитель не появляется на 5 мин в начале урока со списков задач, которые нужно решить, а общается с учениками все 45 минут.
Не бывает задач, которые могут быть решены только одним способом.
Разумеется. Но для программиста-то критически важно нахождение кратчайшего и наиболее оптимального решения (как раз вот чуть ниже обсуждали этот момент с автором).
Поэтому ладно ещё труъ-математикам, но давать студентам ПМП подобные задачи «с двойным дном» – нууу… как-то странно, что ли, как минимум…
О какой спорности задачи речь идет? Это была вполне конкретная задача на диффуры в курсе диффуров, про которую преподаватель сказал, что она о диффурах.
> что из двадцати человек «подвох» заметил только один
В чем подвох-то?
> P.S. Упражнения «на составление», насколько помню, всегда были лишены конкретики.
Сформулируйте хоть _одну_ задачу на составление диффура без конкретики.
О какой спорности задачи речь идет?
В чем подвох-то?
Подвох в том, что предлагалось решать сложнее и дольше то, что можно решить гораздо проще и короче. Думал, этот момент очевиден…
Сформулируйте хоть _одну_ задачу на составление диффура без конкретики.
Да полно же их – тех, в которых требуется не конкретный числовой результат, а именно составление. И ответом в таких задачах всегда будет уравнение, а не числовой результат.
И где здесь подвох? Практически все упражнения правильно выполнять сложнее и дольше, чем неправильно. Только и эффект от неправильного выполнения обычно околонулевой или даже отрицательный. Например, в зал пойдете заниматься с железом, и неправильной техникой сорвете себе спину. Ну или будете бестолково руками размахивать с бесполезными весами, без нормальной изоляции мышц и с отсутствием какого-то реального эффекта. По-этому должна быть определенная сила воли, чтобы не пойти по простому пойти и сделать все, как требуется, а не схалтурить. В обсуждаемой истории человек был слабовольный, поддался своей лени. Преподаватель, видя это, применил «кнут» в виде плохой оценки. Все как и должно быть.
> Да полно же их – тех, в которых требуется не конкретный числовой результат, а именно составление.
А в чем проблема предложить студенту сразу и решить уравнение, раз уж он его составил?
Практически все упражнения правильно выполнять сложнее и дольше, чем неправильно.
Миль пардон, но что за ересь???
Любое упражнение направлено на отработку определённых навыков. Если упражнение не отрабатывает веру в полезность этих навыков, не заставляет учащихся искренне поверить в силу предмета, а лишь симулирует данную полезность – тогда просто в топку такое упражнение! Оно не породит в учащихся ничего, кроме уверенности в том, что им «пихают какую-то бесполезную хрень»…
Об этом ведь речь.
А в чем проблема предложить студенту сразу и решить уравнение, раз уж он его составил?
Эээмм… Простите, а вы действительно имели дело с задачами по диффурам? Или просто путаете определения «решить» и «привести к требуемому виду»?
Это не ересь, это суровая правда жизни. Обучение заключается в преодолении трудностей. Человек получает навык тогда, когда делает то, что ему сложно делать. Когда он делает то, что делать просто, то и навыков никаких не прокачивается. No pain — no gain.
> Оно не породит в учащихся ничего, кроме уверенности в том, что им «пихают какую-то бесполезную хрень»…
Оно породит навык использования конкретного метода. Это то, что оно должно порождать. Заинтересовывать учащегося и доказывать полезность навыка от учебного процесса не требуется. Не интересно — нахер с пляжу. Пусть место займет тот, кому интересно.
> Или просто путаете определения «решить» и «привести к требуемому виду»?
Мы везде обсуждали — «составить и решить». Никто ничего не путает.
Обучение заключается в преодолении трудностей.
Согласен. Но трудностей реальных, а не выдуманных.
Заинтересовывать учащегося и доказывать полезность навыка от учебного процесса не требуется.
Хммм… Я вот сейчас даже как-то затрудняюсь прокомментировать этот «труъ-армейский» тезис без ненормативной лексики…
Возможно, именно в подобном подходе и есть все первопричины нынешнего достаточно бедственного уровня образования?..
Мы везде обсуждали — «составить и решить»
Мы везде в теме, с самого начала, обсуждали принципы решения «труъ-отличника» и программиста. Как уже говорил, для первого важно соответствие «ТЗ», а для второго важен исключительно результат – на чём и выводилась разница между этими совершенно разными подходами…
Так никто и не говорил о выдуманных трудностях, откуда вы их взяли?
> Возможно, именно в подобном подходе и есть все первопричины нынешнего достаточно бедственного уровня образования?..
Так нету никакого такого подхода. Сейчас преподаватели не то что в школе, а даже и в университете прыгают вокруг студентов как дрессированные обезьянки в надежде на то, что дитятко сделает одолжение и испьет знаний из кувшина их мудрости. Так, конечно, быть не должно. Мотивировать на учебу должны родители, идеология, общество, но никак не само учебное заведение. Так это было, например, в союзе. В учебном заведении должны учить. Если человек перешагнул порог учебного заведения, то должно считаться, что он заведомо мотивирован и пришел учиться. А если нет — пошел вон. Зачем учить человека, который учиться не хочет? Лучше направить свои силы на того, кто хочет. Это просто более эффективно.
> а для второго важен исключительно результат
Для них обоих важен результат. Только тру-отличник понимает, какого результата от него хотят, и в чем заключается задача, а «программист» (специально в кавычках) делает не то, что нужно заказчику, а то, что ему хочется. В нашем примере заказчик (преподаватель) хотел от студента отработки и демонстрации навыка составления и решения диффуров, тру-отличник задачу решил и продемонстрировал результат. «Программист» же решил, что он не хочет добиваться результата, а хочет фыр-фыр-фыр.
В любом случае, тру-отличник может строго больше и строго лучше, чем «программист». Так как он обладает не менее глубоким (а скорее — более глубоким) пониманием предмета, но при этом у него есть еще и навыки, которых программист, в силу своей лени, лишен.
Так никто и не говорил о выдуманных трудностях, откуда вы их взяли?
Если простую задачу предлагают решить более сложным методом – это выдуманная трудность.
Если человек перешагнул порог учебного заведения, то должно считаться, что он заведомо мотивирован и пришел учиться.
Немного не так.
Вы, конечно, можете сказать, что у меня какие-то слишком уж возвышенные представления… Но талант настоящего Преподавателя-С-Большой-Буквы в том и состоит, чтобы не просто тупо отбарабанить свой курс в воздух аудитории – а именно «зажечь» студентов своим предметом. И от таких преподавателей чаще всего и выходят будущие профессионалы, а не просто «прослушавшие курс».
А самомотивация – оно, конечно, отлично и приятно. Но, во-первых, априори доступна не всем. А во-вторых – уж тем более не в таком юном возрасте (когда полно гораздо более заманчивых искушений))…
Вот и получается старинная дилемма, из серии всяких там про государство и граждан. У вас – «студент для ВУЗа». У меня – «ВУЗ для студента».
«Программист» же решил, что он не хочет добиваться результата, а хочет фыр-фыр-фыр.
Не так. Программист увидел, что ему подсунули «дутую» проблему – и решил её оптимально. В этом и есть вся «труъшность» подобного решения.
А что важнее всего – запросто мог бы решить и «как положено», «как отличник». Но это заняло бы намного больше времени.
Ну и где тут «фыр-фыр-фыр»? )))
В чем выдуманность? Трудность вполне реальная.
> Но талант настоящего Преподавателя-С-Большой-Буквы в том и состоит, чтобы не просто тупо отбарабанить свой курс в воздух аудитории – а именно «зажечь» студентов своим предметом.
Естественно, слушать хорошего преподавателя полезнее и интереснее (обычно, иногда бывает и такое, что более интересный преподаватель объективно хуже менее интересного). Но это не является необходимостью. Если студент пришел на лекцию — он по умолчанию считается «заженным».
> А во-вторых – уж тем более не в таком юном возрасте (когда полно гораздо более заманчивых искушений)
Ради бога, пускай искушаются. Когда (если) они, вылечившись от инфантилизма, осознают необходимость того или иного обучения — тогда и придут.
> Не так. Программист увидел, что ему подсунули «дутую» проблему – и решил её оптимально.
Никакой дутости. Ему подсунули проблему отработки навыка составления и решения диффуров. Он данную проблему не решил. Ни оптимально, ни неоптимально — вообще в принципе никак не решил.
Между прочим, понимать, какую именно задачу следует решить и каковы реальные требования — один из необходимых для хорошего программиста навыков. Ваш «программист», совершенно очевидно, подобным навыком не обладает.
> А что важнее всего – запросто мог бы решить и «как положено», «как отличник».
Но он не решил. Потому что ленивый (и не факт, что вообще смог бы, он ведь плохо учится). В итоге он хуже как специалист. Из-за отсутствия наработанной практики он не сможет (или сможет, но медленно и неэффективно) решать те задачи, которые сможет эффективно решать «отличник». И это в лучшем случае! В худшем — он будет просто саботировать проект, сперва тратя время на решение того, что решать не требовалось, а потом делая удивленные глаза: «ну я вот что-то не так понял».
В чем выдуманность?
В наличии заведомо более простого решения.
Если студент пришел на лекцию — он по умолчанию считается «заженным».
Ох, вот тут вы категорически ошибаетесь, вновь применяя тот же подход, где «галочка» важнее всего. Студент либо «горит» предметом, либо нет. Нет тут никакого «по умолчанию», и быть не может – этот момент не решается «в явочном порядке»!
Студенты приходят на лекцию порой лишь ради того, чтобы не проставили пропуск. Чтобы потом не иметь хвостов. Чтобы тупо закрыть сессию. Или даже просто от нечего делать (да, бывало, каюсь))…
Если они приходят – это далеко-далеко-далеко не показатель того, что они реально «горят» предметом. Это означает лишь то, что они пришли.
Посидел, скучая. Что-то там записал. В одно ухо влетело, из другого вылетело. Но на зачёте уже как-нибудь прорвётся, хотя бы на «трояк» – и то хорошо, и то не пересдача…
Когда (если) они, вылечившись от инфантилизма, осознают необходимость того или иного обучения — тогда и придут.
Пока существует культ диплома вместо реальных знаний – никто не придёт. Либо будут учиться сами, уже не у вас.
Ему подсунули проблему отработки навыка составления и решения диффуров.
Ранее уже отвечал на эту тему. Но могу ещё раз, уже иначе…
Программист и должен первым делом видеть задачу, понимать её в самой сути. Условно говоря, если предлагают вкручивать саморезы пилкой для ногтей или пилить ногти отвёрткой – программист должен первым сообразить, что это неправильно и должно быть «как-то наоборот», мягко говоря…
Потому что ленивый (и не факт, что вообще смог бы, он ведь плохо учится). В итоге он хуже как специалист.
Согласен, ленивый. Лень решать долго то, что можно решить быстро. Хороший программист должен ценить своё время – что и толкает на оптимизации.
Тут самое место для знаменитой цитаты дядюшки Гейтса о ленивых – надеюсь, вы с ней знакомы. А если нет, то самое время познакомиться – это вот оно самое и есть… ;)))
А выдуманность в чем?
> Ох, вот тут вы категорически ошибаетесь, вновь применяя тот же подход, где «галочка» важнее всего.
Галочки не важны, важны эффективные решения. Обучение того, кто учиться не хочет — неэффективно.
> Студенты приходят на лекцию порой лишь ради того, чтобы не проставили пропуск.
Таких студентов следует отчислять, а не «зажигать» или что там еще.
> Программист и должен первым делом видеть задачу, понимать её в самой сути.
Итак, задача, ее суть — составить и решить диффур. Четко, ясно, однозначно. Никаких непоняток. Студент задачу решил? Не решил. Какие еще могут быть вопросы?
> Согласен, ленивый. Лень решать долго то, что можно решить быстро.
Но студент не решил задачу. Из-за своей лени он вместо нужной, полезной задачи, которую его требовали решить, решил другую — бесполезную. И на работе он будет делать точно так же.
Таких студентов следует отчислять, а не «зажигать» или что там еще.
В недавнем переводе книги понравилась фраза: «Что вы сегодня сделали альтруистичного, изобретательного, или интересного?». С помощью этого вопроса и интереса к ответам отец «зажигал» своих детей, мотивировал их искать и совершать Поступки.
Человек знает и умеет только то, что ему показали и рассказали другие люди. Если людей вокруг не было, то вырастают Маугли. Не надо сразу отчислять, этих «Маугли» и так слишком много вокруг нас. Будьте гуманнее. Студентам, которые ходят на лекции ради галочки, просто не встретился Человек, с которого они захотели бы брать пример. Они видели вокруг лишь преподавателей, которые тоже ходят на лекцию ради галочки. В Москву с рыбным обозом приходят единицы.
Я же и не говорю, что не надо этим заниматься в принципе. Надо, только не учебному заведению. Человек должен идти в университет тогда, когда он знает «я хочу научиться Х». Это должно быть четким, осознанным желанием. Иначе он пойдет на специальность, которая ему не нужна и будет учиться там тому, что не любит. И «зажигающий преподаватель» тут только скрасит процесс, как таблетка обезболивающего. Но не решит проблему прогрессирующего рака в целом.
> Студентам, которые ходят на лекции ради галочки, просто не встретился Человек, с которого они захотели бы брать пример.
Поиск подобного примера среди преподавателей в универе и подобное «зажигание» приведет исключительно к тому, что человек таки доучится, и потом в лучшем случае просто не будет работать по специальности. В худшем — будет всю жизнь заниматься нелюбимым делом. Так что отчисление — это как раз самое гуманное.
И «зажигающий преподаватель» тут только скрасит процесс, как таблетка обезболивающего. Но не решит проблему прогрессирующего рака в целом.
Да нет же!!!
Вы зачем-то сразу ориентируетесь на заведомых «случайных студентов» – которых априори подавляющее меньшинство. И только лишь на основании самого факта наличия таких – вы призываете всех (!!!) преподавателей «не париться и тупо-нудно читать курс».
Если руководствоваться исключительно подобными принципами – то и будет продолжаться нынешний регресс вместо прогресса.
А вы просто попробуйте читать курс так, словно вся аудитория – хорошие студенты! Читайте именно для них, для таких! И насрать на остальной «балласт». Просто делайте свою работу хорошо.
Тогда, более чем вероятно – выявятся даже и «скрытые таланты». И даже там, где вы и не ожидали…
С чего бы?
> И насрать на остальной «балласт».
На балласт не насрать, потому что этот баланс — объективно неэффективное использование средств. Балласт следует сбрасывать, в первую очередь — ради самого балласта. Если человек не хочет учиться на Х, то ему следует попробовать идти учиться на кого-то другого, чья деятельность ближе душе, а не скакать вокруг, завлекая разными интересностями.
> Тогда, более чем вероятно – выявятся даже и «скрытые таланты».
Опять же, выявление талантов — никак не задача учебного заведения, по крайней мере, не задача во время учебного процесса (во время приема, быть может). Вместо того, чтобы какими-то окольными путями пробуждать в человеке интерес, следует его отчислить и направить куда-то в иное место. В первую очередь — для самого этого человека.
В этом смысле, я даже за искусственное наполнение учебного процесса необязательными страданиями и трудностями. Это будет стимулировать людей уходить с тех направлений, к которым они не склоны, и искать то, что им действительно нравится, то, чего они действительно хотят. Ради чего они будут _готовы_ терпеть эти страдания и трудности. Вместо этого человек идет на программиста, или еще кого (хотя ему это нафиг не надо) и пять лет развлекается в компании преподавателей-клоунов, которые обеспечивают ему веселье и радость.
Это вредит в первую очередь самим студентам — вместо того, чтобы спустя полгода свалить на другую специальность, он просидит, отучится 5 лет, получит диплом, и дальше будет работать на ненавистной работе (или не по специальности, в результате чего те 5 лет окажутся просто тратой времени).
Естественно, тут проблема на самом деле глобальная — прыгать туда-сюда в поисках подходящей специальности как порицаемо общественно, так и просто накладно (т.к. бесплатно можно поступить лишь раз). Но это не значит что подобную ситуацию надо поощрять и усугублять.
Если же вокруг меня «гореть» никто не будет, то и у меня повода задуматься о перемене места просто не будет: какой смысл менять шило на мыло, если вокруг один мрак беспросветный и безнадёга, хоть здесь, хоть везде. Отучусь-ка я здесь как-нибудь…
А искусственных трудностей — не надо, у нас и натуральных хватает.
Это то, чего требует от преподавателя Garruz. Чтобы учебный процесс для студента был классный и веселый даже в том случае, если он студенту нахрен не нужен.
> Если же вокруг меня «гореть» никто не будет
Вы опять выводите проблему во вне. Хочет человек или нет заниматься Х — зависит _исключительно от этого человека_. Но никак не от преподавателя по диффурам. Хотите вы быть программистом — значит хотите, не хотите — значит не хотите. Если не хотите — следует вас отчислить ради вас же, чтобы вы пошли туда, куда хотите.
Цель обучения — не в процессе, она в том, чтобы потом использовать полученные навыки. Если у вас есть желание использовать эти навыки — вы будете вкалывать ради того, чтобы их получить. Если нету такого желания — не будете. Сама привлекательность процесса получения навыка — сугубо вторична, это просто труд. Его не требуется делать интересным или веселым, точно так же, как работодатель не обязан делать потом интересной и веселой вашу работу.
Вы уводите фокус в сторону. Желание изучать предмет ученику _вообще не требуется_. Оно лишнее. Если человек хочет получить какие-то навыки, то он будет изучать соответствующие предметы, даже в том случае, если процесс ему активно неприятен.
Вы ведете рассуждение о том, как бы сделать процесс приятнее и желательнее. Я же упираю на то, что процесс не важен, работать надо с целеполаганием.
Научить человека тому, что ради результата требуется совершать неприятные вещи — это весьма полезный навык, я бы даже сказал необходимый.
Попытка «скрасить» неприятные процессы не приводит ни к чему кроме того, что этот навык атрофируется. В результате получается не человек, а безвольный кусок мяса.
Это вредит в первую очередь самим студентам — вместо того, чтобы спустя полгода свалить на другую специальность, он просидит, отучится 5 лет, получит диплом, и дальше будет работать на ненавистной работе (или не по специальности, в результате чего те 5 лет окажутся просто тратой времени).
Работая на ненавистной работе он будет приносить пользу как себе (зарплата, статус), так и обществу в лице работодателя( раз уж платит зарплату)
- Даже работая не по специальности, с большой вероятностью время проведенное в вузе нельзя отнести к абсолютно бесполезному времяпровождению.
С чего бы?
Да всё с того бы – если перечитать все ваши предыдущие сентенции…
Балласт следует сбрасывать, в первую очередь — ради самого балласта.
Нередко кажущийся «балласт» на поверку оказывается вовсе даже не «балластом» – как раз если правильно «зажечь»…
Опять же, выявление талантов — никак не задача учебного заведения, по крайней мере, не задача во время учебного процесса (во время приема, быть может). Вместо того, чтобы какими-то окольными путями пробуждать в человеке интерес, следует его отчислить и направить куда-то в иное место.
Это вот просто роковой способ мышления для любого настоящего (!!!) преподавателя.
Преподаватель должен работать с тем, что есть здесь и сейчас. Других студентов ему никто не даст. Поэтому и должен вытягивать максимум именно из этих студентов – вместо того, чтобы как-то там сортировать их по неким «критериям годности» на своё собственное усмотрение.
Соответственно – и работать всегда должен «как для самых лучших». Иначе это ни хрена не настоящий Учитель, а просто тупая штатная единица, ИМХО…
Очевидно, вы невнимательно читали. Перечитайте еще раз.
> Нередко кажущийся «балласт» на поверку оказывается вовсе даже не «балластом» – как раз если правильно «зажечь»…
Зачем вредить человеку?
> Преподаватель должен работать с тем, что есть здесь и сейчас. Других студентов ему никто не даст.
Ну вот здесь я с вами не согласен. На мой взгляд преподаватель не должен учить тех, кто учиться не хочет. Более того — это преступно и вредно. Вместо того, чтобы путем развлечений пытаться снизить неприятие человека от обучения тому, что ему неинтересно, следует направить усилия на поиск того, что ему интересно. Что он будет изучать сам, без зажиганий, с любым преподавателем и в любых условиях. Все остальное — лишь вредительство и попытка уничтожить в человеке человеческое.
> Соответственно – и работать всегда должен «как для самых лучших».
Так именно об этом я и говорю. Работать надо для лучших в рассчете на лучших. Заниматься же (в ущерб толковым студентам, которые знают, зачем они пришли в университет) развлечениями ради того, чтобы просиживальщикам штанов было не так скучно просиживать штаны — не стоит.
Перечитайте еще раз.
Я перечитывал. Поэтому аналогичный совет…
Зачем вредить человеку?
Вредить???
Поясните этот момент, будьте добры…
Что он будет изучать сам, без зажиганий, с любым преподавателем и в любых условиях.
А вот как раз это уже и есть просто потакание всем слабостям. Совершенно пассивная позиция – даже без малейших попыток «перевоспитания» в какую-либо сторону.
Заниматься же (в ущерб толковым студентам, которые знают, зачем они пришли в университет) развлечениями ради того, чтобы просиживальщикам штанов было не так скучно просиживать штаны — не стоит.
Но это и есть одна из главных задач настоящего Преподавателя – всегда пытаться вытянуть максимум из всех, а не только лишь из самых способных…
Понятно, конечно, что «максимумы» будут разными, в зависимости от конкретного студента – но хоть реально максимумы, а не просто «сброс в утиль»…
Склонять человека к трате времени на бесполезные занятия, которые ему не нравятся, вместо того, чтобы тратить время на полезные занятия, которые ему нравятся. Что это если не вред?
> А вот как раз это уже и есть просто потакание всем слабостям.
Наоборот, потакать слабостям предлагаете вы. Здесь же никакого потакания нет, наоборот — развитие воли и понимание того, что для достижения цели надо трудиться.
> даже без малейших попыток «перевоспитания» в какую-либо сторону.
А в чем смысл такого «перевоспитания»? Если человек хочет быть врачом, и при этом ненавидит рисовать, то не надо его перевоспитывать в художники (и по пути меняя программу художников так, чтобы ему не было совсем уж отвратно). Пускай идет учится на врача. А те, кто любит рисовать, пускай рисуют. Не надо их заставлять со скальпелем в руках лягушек вскрывать,
или убирать вскрытие лягушек из обучения врачей (а то вдруг там среди художников люди, которые от вида крови в обморок падают?).
Зачем пытаться делать из человека того, кем он ну никак не хочет быть?
> Но это и есть одна из главных задач настоящего Преподавателя – всегда пытаться вытянуть максимум из всех, а не только лишь из самых способных…
Никто не говорил о способностях, речь шла о желании. Если человек не хочет учиться рисовать, а хочет вскрывать лягушек — то задача настоящего Преподавателя по изобразительному искусству сдать такого человека с рук на руки настоящему Преподавателю по медицине.
Склонять человека к трате времени на бесполезные занятия, которые ему не нравятся, вместо того, чтобы тратить время на полезные занятия, которые ему нравятся. Что это если не вред?
Не склонять – заинтересовывать. Вспомните хоть классический забор Тома Сойера. Что это, если не грамотная мотивация? )))
Наоборот, потакать слабостям предлагаете вы.
Я предлагаю не «потакать», а всего лишь не грести всех под одну гребёнку. Не бывает никакого идеального «сферического студента в вакууме» – каждый со своими плюсами и минусами (даже отличники, да).
Именно поэтому и надо по максимуму пытаться работать со всеми, а не только лишь с узким «пулом любимчиков».
А в чем смысл такого «перевоспитания»?
В том, чтобы вовлечь в тему как можно больше активных учащихся, даже «спящих». А там уж, кто знает – вполне возможно, что и полностью переключатся в это русло. А если даже и нет – то хотя бы знать предмет будут точно хорошо.
Таким образом, хороший «промоушн» своего предмета – одна из первостепенных задач хорошего университетского преподавателя.
Если человек не хочет учиться рисовать, а хочет вскрывать лягушек — то задача настоящего Преподавателя по изобразительному искусству сдать такого человека с рук на руки настоящему Преподавателю по медицине.
Немного не так. Точнее – так, но лишь в идеале.
Если человек оказался уже здесь и сейчас, конкретно на этом курсе – вы не сможете его никуда «передать». Но вы, как преподаватель, обязаны сделать всё от вас зависящее, чтобы дать человеку максимальные шансы проникнуться вашим предметом.
Да, не факт, что получится именно с ним. Зато получится с остальыми.
Если человек оказался уже здесь и сейчас, конкретно на этом курсе – вы не сможете его никуда «передать».
Конечно, сможете. Отчисляете — и у него нету никакого иного выбора, кроме как «передаться». Ну, либо можете его развлекать вместо обучения, только толку?
Ведь его реальные данные не обуславливаются только лишь посещаемостью ваших лекций. Может быть и так, что у него просто некая «аллергия» конкретно на ваши методы преподавания…
Понимаете, тут самый главный затык именно в том, что ваша задача как преподавателя – не «сортировать» студентов, а пытаться сделать специалиста из каждого. Получится не с каждым, да. Но пытаться вы обязаны именно с каждым, пока не получится.
Такого быть не может. Отличный специалист не получится из того, кто не хочет учиться.
> Понимаете, тут самый главный затык именно в том, что ваша задача как преподавателя – не «сортировать» студентов
Да нет, что же вы. Контроль знаний студента — одна из основных обязанностей преподавателя как раз. Если студент не учится — значит его надо отчислять, ради самого этого студента.
Такого быть не может. Отличный специалист не получится из того, кто не хочет учиться.
Вопрос в том почему не хочет. Возможно потому что вместо понимания зубрежка требуется? Или используется неподходящий подход? (сколько там человек может сконцентрированным оставаться) Или интересный предмет преподается так что хочется пойти вскрывать лягушек хотя это никогда не нравилось?
Вопросы вида «почему человек хочет стать космонавтом, а не балериной» особого смысла не имеют. Так воспитали. Это данность.
> Возможно потому что вместо понимания зубрежка требуется?
При чем тут понимание и зубрежка? Еще раз — мы не говорим о желании учиться. Желания учиться быть и не должно, это все лишнее. Должно быть желание _научиться_. Если человек хочет научиться — он будет превозмогать, даже если ему учиться не нравится.
Вот тогда и надо учиться.
> Что касается желания учиться или научиться — во втором случае приходиться себя заставлять, тратить волевые усилия, морально уставать
Конечно. Без этого никакого обучения и не бывает. Это всегда труд и страдания, иначе и результата нет.
> Таким образом учиться становится гораздо проще.
И результат, конечно же, становится на порядок хуже.
Это уже не говоря о том, что факт преодоления трудностей при обучении полезен сам по себе.
Ну почему, как таковое это необходимым не является. Однако, такова данная нам в ощущениях реальность, что иногда в жизни возникают моменты, когда надо прикладывать усилия через «не хочу». В частности, на работе такие моменты возникают нередко (даже если работа в принципе вам нравится). И если человек даже в университете трудиться не научился — то он и дальше не сможет, будет все делать халтурно.
Такого быть не может. Отличный специалист не получится из того, кто не хочет учиться.
Поправочка…
Из того, кто не хочет учиться вообще? Или из того, кто не хочет учиться конкретно по вашим методам – и как раз потому, вполне возможно, потенциально гораздо талантливее вас?
Контроль знаний студента — одна из основных обязанностей преподавателя как раз.
Не контроль «знаний», а контроль способностей.
В этой короткой фразе – вся суть глобальной разницы между вашей и моей точками зрения…
Из того, кто не хочет учиться данной конкретной деятельности. Не хочет человек учиться на программиста — ну не будет из него программиста.
> Или из того, кто не хочет учиться конкретно по вашим методам
Ради бога, пусть учится по другим.
> Не контроль «знаний», а контроль способностей.
А в чем смысл контроля способностей? Это то, на что преподаватель повлиять не может, обратной связи нет. Бессмысленная задача. А вот знания контролировать — вполне осмысленно, т.к. на их наличие преподаватель повлиять может (хотя бы косвенно).
Не хочет человек учиться на программиста — ну не будет из него программиста.
Согласен. Но говорим-то мы совершенно о другом – о слепом следовании предложенной методике…
Ради бога, пусть учится по другим.
Да, но преподаватель-то у него вы – который считает любой отход от своей программы «жуткой крамолой» и не оценивает любые альтернативные варианты решений.
И что делать студенту, если преподаватель – вы? Менять ВУЗ? Или подстраиваться под вашу программу, хотя он способен на большее?
Поэтому если такой студент бросит ваш курс – в этом будет ваша и только ваша вина. Это будет означать, что именно вы не смогли увлечь и раскрыть потенциально хорошего специалиста.
А в чем смысл контроля способностей? Это то, на что преподаватель повлиять не может, обратной связи нет. Бессмысленная задача.
Хм…
Вы правда настолько искажённо представляете себе задачу Настоящего Учителя? Неужели вообще нет опыта в этом, неужели даже отработку на преподавании не проходили?..
Настоящий Учитель всегда работает в режиме диалога, а не монолога.
Вы что-то уже совсем свое выдумываете. Никто не говорил про отходы от программы, речь шла о том, что студент просто не выполняет задания. В принципе. Ему дали задание — он его не выполнил из-за лени. Конец истории.
> Настоящий Учитель всегда работает в режиме диалога, а не монолога.
И при чем тут способности, на которые Учитель не может повлиять?
> Вот потому у нас и едва ли не полстраны таких «горе-специалистов» (от программистов до преподавателей) – которые учились ради корочек и должностей, а не ради знаний…
Вы как будто не то читаете. «стать специалистом» — как раз предполагает наличие знаний, а не корочки.
> Человек должен «гореть» своей работой. И «зажечь» его – задача именно преподавателя.
Человек идет учиться, если горит работой. Если он работой не горит — ему не надо учиться на эту профессию, надо искать, от чего он горит. Потому что если человек от чего-то не горит — он и не загорится. Вне зависимости от преподавателя.
> Речь не о «свободной мысли». Речь о Мысли Вообще – которая выше любых статичных методик.
Ну так я об этом и говорю. Человек либо мыслит вообще — то есть понимает что от него хотят, каков контекст задачи, как он влияет на возможное решение. Либо не мыслит — потому что ленив и делает тупо как проще, влоб.
> А если вы преподаватель – то вы просто обязаны хотя бы пытаться.
Это уже не преподаватель — это вредитель, который ломает людям жизнь.
Ему дали задание — он его не выполнил из-за лени.
Не «из-за лени» – а из-за наличия более разумного и быстрого (!) решения. Разницу видите?
И при чем тут способности, на которые Учитель не может повлиять?
При том, что Учитель должен их видеть и пытаться раскрыть всеми доступными способами.
«стать специалистом» — как раз предполагает наличие знаний, а не корочки.
Увы, нет…
Звание «специалиста» (тут в кавычках) и реальный специалист – совершенно разные сущности.
Множество глупых контор до сих пор набирают себе сотрудников исключительно по «корочкам». Это тупо слепая калька с западных манер. Но там «у них» это объясняется тем, что красный диплом реально хоть чего-то стоит (впрочем, тоже являясь гарантией не полной, но хотя бы максимально возможной).
У нас же (да и у всех «постсоветских») красный диплом не стоит почти ничего в реальном мире. О том и речь.
Человек либо мыслит вообще — то есть понимает что от него хотят, каков контекст задачи, как он влияет на возможное решение. Либо не мыслит — потому что ленив и делает тупо как проще, влоб.
Настоящий специалист должен понимать не «что от него хотят» – а что надо делать. Поскольку специалист тут именно он.
Только это и есть настоящее профессиональное мышление. Всё прочее – всего лишь тупо приспособленчество, пардон…
Это уже не преподаватель — это вредитель, который ломает людям жизнь.
Весьма оригинально…
А можно более подробно раскрыть этот более чем странный тезис?
Но он не предоставил решение. Его задача была — написать по условию диффур и его решить.
> При том, что Учитель должен их видеть и пытаться раскрыть всеми доступными способами.
Ну так влиять на них он не может. Либо они есть (есть что раскрывать), либо нету.
> Увы, нет…
Звание «специалиста» (тут в кавычках) и реальный специалист – совершенно разные сущности.
А где кто говорил о звании специалиста? Речь шла именно о «реальном специалисте».
> Настоящий специалист должен понимать не «что от него хотят» – а что надо делать.
Ну вот в нашем примере с диффурами человек не понял, что ему надо составить и решить диффур. В дальнейшем примере, когда этот человек устроился на работу — он не понял, что ему надо написать быстрый и эффективный алгоритм, чтобы сервис потом не упал под нагрузкой.
Точнее — соль ситуации в том, что в обоих случаях он все _понял_. Но не сделал. Потому что лентяй.
> А можно более подробно раскрыть этот более чем странный тезис?
Я, вроде, уже раскрывал. Если человек хочет препарировать лягушек, то не надо заставлять его раскрываться в области ненавистного рисования. Возможно, вы сможете как-то построить процесс так, что ему будет не особенно отвратно. В итоге он не особенно хорошо научится рисовать (но научится) и даже примириться с тем, чтобы терпеть ненавистную работу. Но это ли то, что должен делать Учитель?
Его задача была — написать по условию диффур и его решить.
Это задача/решение математика. А мы говорим о задаче/решении программиста. И чаще всего это совсем разные методы решения…
Ну так влиять на них он не может.
Ну может же, блджад! Даже я, будучи не преподавателем, а руководителем всяких отделов – мог раскрывать в людях «скрытые таланты». А уж настоящий преподаватель обязан это уметь просто по определению…
Речь шла именно о «реальном специалисте».
А вот если о реальном – тогда уж и к чертям все условные ограничения. Либо решаешь задачу быстро (насколько хватит мозгов), либо решаешь медленно (как учили), либо не решаешь вообще. Иного не дано.
В дальнейшем примере, когда этот человек устроился на работу — он не понял, что ему надо написать быстрый и эффективный алгоритм, чтобы сервис потом не упал под нагрузкой.
Вот именно о нагрузке и речь. )))
Первый человек написал «как учили» – долго и тяжело. Второй написал «как правильно» – быстрее и проще, максимально оптимально.
У кого там что упадёт первым, где тут соль, а? )))
Но это ли то, что должен делать Учитель?
Да. Отдавать всего себя обучению своему предмету. И если даже вдруг на курсе оказался «случайный» слушатель – не задача и даже не право Учителя гнать такого слушателя со своего курса.
Его задача – заинтересовать и научить. Все прочие вопросы решают уже другие инстанции.
Мы говорим о задаче по диффурам, то есть о решении математика. Про решение программиста пример ниже — человек выбрал из-за лени медленный алгоритм и ваш сервис упал.
> Ну может же, блджад! Даже я, будучи не преподавателем, а руководителем всяких отделов – мог раскрывать в людях «скрытые таланты».
Ну так раскрывается то, что есть. А влиять никак на наличие нельзя.
> Первый человек написал «как учили» – долго и тяжело. Второй написал «как правильно» – быстрее и проще, максимально оптимально.
У кого там что упадёт первым, где тут соль, а? )))
У второго, конечно. Первый напишет как учили — проанилизирует задачу, увидит, что на реальных данный простой алгоритм будет работать слишком медленно и потратит время на оптимизацию. Человек ведь является квалифицированным специалистом, учился не зря и привык _работать_.
Второй же — просто поленится (привык делать так во время обучения) и решит задачу быстро и просто, как вы тут пропагандируете. Только вот работать его решение в итоге не будет и придется переписывать.
> А вот если о реальном – тогда уж и к чертям все условные ограничения. Либо решаешь задачу быстро (насколько хватит мозгов), либо решаешь медленно (как учили), либо не решаешь вообще. Иного не дано.
Ну вот в примере с диффурами человек не решил задачу вообще.
> Да. Отдавать всего себя обучению своему предмету.
Извините, но по вашим словам, настоящий Учитель — полная мразь. Хорошо, что таких мало.
Мы говорим о задаче по диффурам, то есть о решении математика.
Мы говорим о любой задаче вообще. Если есть более простое и быстрое решение – нечего городить там диффуры на ровном месте. К чему искусственно усложнять то, что можно сделать проще и быстрее, и даже с тем же результатом? «Процесс ради процесса»?
Ну так раскрывается то, что есть. А влиять никак на наличие нельзя.
На само наличие – разумеется, никак нельзя. Но вот на «раскрываемость» – не только можно, но и нужно.
Иначе у вашего «преподавателя» (тут именно в кавычках) получается какой-то совершенно пассивный подход к вопросу – максимум требований к студентам и ноль требований к себе самому.
Первый напишет как учили — проанилизирует задачу, увидит, что на реальных данный простой алгоритм будет работать слишком медленно и потратит время на оптимизацию.
Так это именно и есть решение второго. )))
Только без ненужных лишних (!!!) телодвижений по решению задачи более долгим путём. Чтобы изобрести круглое колесо – вовсе необязательно сначала мастерить квадратное… )))
Ну вот в примере с диффурами человек не решил задачу вообще.
Конкретно саму задачу – решил. Не решил лишь требуемыми методами – заранее просчитав, что есть намного более простое решение (а следовательно, более эффективное).
Да, то самое «П», которое «Прогресс». Только так всё и делается ведь…
Извините, но по вашим словам, настоящий Учитель — полная мразь.
Крайне любопытный тезис…
Либо я что-то не так понял, либо вы сейчас назвали совершенно всех специалистов, полностью отдающихся своему делу – «полными мразями»… О_о
Поясните этот момент, во избежание недоразумений…
Мы рассматриваем вполне конкретную ситуацию — человеку дали упражнение на составление и решение диффуров, а он ничего не составил и не решил.
> Если есть более простое и быстрое решение
Если оно есть. Но в данном случае его не было (точнее, может и было, но студент его не увидел. вместо этого он предпочел вообще ничего не решать).
> Так это именно и есть решение второго.
Нет, это решение первого (который составил и решил диффур, как и было нужно). Решение второго (который лентяй и привык сачковать) — идти по _простому и легкому пути_. То есть использовать простой алгоритм, который можно быстро написать и забить. Формально же, оно работает? Работает. Задача решена!
> Конкретно саму задачу – решил.
Ну вот и в примере с алгоритмом второй тоже саму задачу решил. Только потом прод упал и пришлось все переделывать :)
> специалистов, полностью отдающихся своему делу – «полными мразями»
Я назвал мразями тех, кто упорно пытается сделать хирурга из человека, который хочет рисовать и теряет сознание от вида крови.
человеку дали упражнение на составление и решение диффуров
Прежде всего – человеку дали конкретную задачу. Которую он решил (!) наиболее оптимальным способом. Ровно так же, как ему пришлось бы решать такую же задачу в реальной жизни. И только не говорите, что в реальной жизни вы бы выбрали для этой задачи более долгое и нудное решение. Тогда вы уж точно ни разу не программист…
А если у задачи «на решение» по диффурам есть настолько простой альтернативный вариант – то претензии уже исключительно к авторам задачника, как уже говорил… )))
вместо этого он предпочел вообще ничего не решать
Что значит «вообще ничего не решать» – если ответ полностью совпал с требуемым результатом??? )))
Этот момент отдельно поясните, пожалуйста. ;)
Формально же, оно работает? Работает. Задача решена!
Внезапно, задача может быть либо решена, либо нет. Третьего тут просто не дано. И если уж решена – то наиболее верен именно кратчайший и самый простой путь решения. Желаете поспорить на эту тему? Милости прошу! ;)
Я назвал мразями тех, кто упорно пытается сделать хирурга из человека, который хочет рисовать и теряет сознание от вида крови.
Нет.
В вашем варианте – «мразями» получаются все те, кто отходит от неких «инструкций».
Понимаю, что сказать вы хотели совершенно другое, просто выразились коряво. Потому и указал вам на этот момент настолько жёстко – чтобы лучше запомнилось.
Такого быть не может.
Увы, может.
Отличный специалист не получится из того, кто не хочет учиться.
Вновь поправка – не хочет учиться вообще, или не хочет учиться конкретно по вашим методам?
Контроль знаний студента — одна из основных обязанностей преподавателя как раз.
Про «контроль знаний» – и его отличие от контроля способностей, что присуще лишь настоящим Преподавателям – уже отвечал ранее…
Зачем пытаться делать из человека того, кем он ну никак не хочет быть?
Хотя бы, чтобы приносил больше пользы обществу. Грубо, вносил бОльший вклад в ВВП страны, работая по этой специальности, а не по той, которая больше нравится. Пускай мотивированный лишь одной зарплатой, но приносил.
А выдуманность в чем?
Весьма занятно отвечать вопросом на ответ… )))
Обучение того, кто учиться не хочет — неэффективно.
А с чего вы взяли, что «не хочет»???
Крайне вероятно, что это именно вы, как преподаватель, не смогли его увлечь своим предметом.
Вот вы сначала со своей стороны приложите все описанные выше усилия – а уже только потом и вычисляйте тех, чьё внимание не привлекло даже это…
Или вы считаете, что работа преподавателя – это всего лишь унылая бубниловка, тупо ради отработки часов? Тут ведь тоже стараться надо, внезапно…
Таких студентов следует отчислять, а не «зажигать» или что там еще.
ИМХО, прежде всего – надо массово увольнять преподавателей, считающих так.
Итак, задача, ее суть — составить и решить диффур. Четко, ясно, однозначно.
Суть – найти ответ. Уже выяснили ранее. Нашли, даже без диффуров. Чётко, ясно, однозначно… ;)))
И на работе он будет делать точно так же.
Если на работе он будет делать точно так же – я сам первым заберу такого!!! )))
Это и будет означать, что мыслит такой не тупо по «рельсам» ТЗ – а обладает действительно истинным видением задачи и решения.
Вот именно этот момент вам всё никак не доступен…
Очевидно, я не вижу, как ваш ответ связан с вопросом. Попробуйте ответить еще раз.
> А с чего вы взяли, что «не хочет»???
Потому что если бы хотел — то учился бы. Ему ведь обычно даже не требуется прилагать для этого какие-то особые специальные усилия. При этом, когда человек учиться _хочет_ — то он их прилагает, если требуется.
> Крайне вероятно, что это именно вы, как преподаватель, не смогли его увлечь своим предметом.
Обучение не должно быть увлекательным процессом. Это труд. Люди учатся не для того, чтобы развлечься в процессе. Люди учатся для того, чтобы в итоге получить набор определенных навыков/знаний. Если человек _хочет_ получить указанные навыки/знания — он учится, учится без завлеканий и зажиганий.
Если же человек получать их не хочет — значит ему следует идти на другую специальность. Туда, где он будет готов терпеть и страдать.
> Суть – найти ответ. Уже выяснили ранее.
Нет, мы выяснили как раз обратное. Ответ в учебных упражнениях совершенно не важен. Важно — отработать/продемонстрировать владение конкретным навыков. Упражнения делаются не для получения ответа.
> Нашли, даже без диффуров.
То есть сделали то, чего вообще никто не просил.
> Если на работе он будет делать точно так же – я сам первым заберу такого!!! )))
Который будет вместо полезной деятельности заниматься реализацией никому не нужного функционала? Очень полезный работник!
> а обладает действительно истинным видением задачи и решения.
> Вот именно этот момент вам всё никак не доступен…
Мы как раз обсуждаем тот факт, что он недоступен _вам_.
В нашем случае истинное видение задачи — это отработать навык составления/решения диффуров. Человек этого не увидел. Точно так же он и на работе будет подходить к выполнению задач сугубо формально, без оглядки на реальную ситуацию, контекст.
Очевидно, я не вижу, как ваш ответ связан с вопросом.
Вижу, что не видите. Потому и иронизирую. Просто перечитайте ветку – тогда сам поймёте… ;)
Потому что если бы хотел — то учился бы.
Разные люди – разные подходы. Это ведь элементарные азы психологии, даже любой хороший школьный учитель знает этот простейший принцип, а уж университетские и подавно просто обязаны…
Обучение не должно быть увлекательным процессом.
Вот на этой цитате и можно поставить жирнейшую точку. Именно в этом наши взгляды диаметрально противоположны.
А кто говорил про один и тот же подход? Вы опять отвечаете нерелевантно.
> Вот на этой цитате и можно поставить жирнейшую точку. Именно в этом наши взгляды диаметрально противоположны.
То есть вы действительно считаете, что смысл обучения — развлекаться? Тогда почему бы не заменить лекции просмотром забавных видосов про котиков, распитием спиртных напитков, играми и т.д.? Или подобное учебное заведение как раз и было бы с вашей точки зрения идеальным?
А кто говорил про один и тот же подход? Вы опять отвечаете нерелевантно.
Да что ж тут «нерелевантного»-то? Вы делите всё лишь на «хочет — не хочет». Я говорю, что всё намного сложнее – и что при должном подходе можно заинтересовать даже тех, кто на первый взгляд якобы «не хочет».
То есть вы действительно считаете, что смысл обучения — развлекаться?
Не надо передёргивать. ))
Уверен, вы прекрасно понимаете, о чём речь – о способности преподавателя увлечь своим предметом. И если преподаватель действительно толковый – для этого не понадобятся ни котики, ни напитки (впрочем, и с их участием можно придумать немало интересных задач)))…
А я говорю, что заинтересовывать тех, кто не хочет, _не нужно_ и, более того — _вредно_. Надо их направить учиться тому, что они делать хотят.
> Уверен, вы прекрасно понимаете, о чём речь – о способности преподавателя увлечь своим предметом.
Еще раз — развлекать ученика не задача преподавателя. Задача преподавателя — научить. И если ученик по результату научился (пусть и вспоминает потом процесс обучения как ад) — то это хороший преподаватель, а если не научился (пусть ему было весело и интересно в процессе) — то это плохой преподаватель.
И, почему-то, по факту, хорошими преподавателями в итоге оказываются в основном те, кто студентов дрочит по максимуму и кого студенты ненавидят (до окончания универа :)), а не те, кто прыгает веселым кловуном, развлекая публику.
Интерес нужен не к процессу (любое нетривиальное обучение в принципе интересным быть не может, так как состоит на 90% из со стороны бессмысленного механического повторения одного и того же), интерес нужен к результату. А на него преподаватель повлиять не может никак. Преподаватель может повлиять на процесс обучения, но от процесса не требуется быть интересным, веселым и приятным. Наоборот — процесс любого серьезного обучения скучен и неприятен по своему определению. Попытка сделать процесс «интересным» приведет лишь к снижению качества результата (то есть, снизит заинтересованность тех лиц, заинтересованность которых как раз-таки важна) — ничего более.
И самое главное тут: суметь популярно объяснить, что все эти вот нынешние «нудные» задачи – и есть путь к той самой «вишенке на торте».
Ну тупо мотивация же…
Если же ваш процесс будет «скучен и неприятен», будет без той самой вожделенной «вишенки на торте» – то и большой отдачи от студентов не ждите при таком подходе к преподаванию, ИМХО…
Достижения какого результата? Интерес к предмету ни на что не влияет и не обязателен.
> И самое главное тут: суметь популярно объяснить, что все эти вот нынешние «нудные» задачи – и есть путь к той самой «вишенке на торте».
Это все и так понимают, ничего объяснять тут не требуется. Но притворяются дурачками и рационализируют свою лень якобы «непониманием» (точно так же как в рассматриваемом примере человек закосил под дурачка, что типа он не понимал, как надо решать задачу). А идет все от того же — проблемы с целеполаганием и криво устроенная система образования, которая эти проблемы лишь стимулирует, вырабатывая в ученике безволие и неспособность к труду.
> Если же ваш процесс будет «скучен и неприятен», будет без той самой вожделенной «вишенки на торте» – то и большой отдачи от студентов не ждите при таком подходе к преподаванию, ИМХО…
Единственный источник отдачи от студентов — их желание стать хорошими специалистами. Это все. Человек либо хочет стать специалистом и учится, либо не хочет — тогда пусть не занимает место. Уговаривать, веселить и как-то иначе привлекать — в образовательном учреждении не должны. В учебное заведение должны попадать только те, кто хочет учиться. Конец истории.
Достижения какого результата? Интерес к предмету ни на что не влияет и не обязателен.
Достижения конечного результата. То бишь, знания предмета. И для это как раз требуется увлечение предметом – чтобы решать не «на отлепись», а полностью погрузиться в предмет и проникнуться его реальной необходимостью.
проблемы с целеполаганием и криво устроенная система образования, которая эти проблемы лишь стимулирует, вырабатывая в ученике безволие и неспособность к труду.
Согласен, крайне криво всё устроено – если стимулируется способность решать «по рельсам» вместо способности реально думать.
Единственный источник отдачи от студентов — их желание стать хорошими специалистами.
Увы, у многих это благое желание подменяется желанием просто тупо получить «красный диплом» – именно об этом и речь.
Это не конечный результат. Конечный результат — стать специалистом в конкретной области.
> если стимулируется способность решать «по рельсам» вместо способности реально думать.
Так это вы предлагаете решать по рельсам, формально. А я как раз за то, чтобы студент понимал контекст задачи. Если студент понимает, что задача — про диффуры, то решит ее диффурами, несмотря на то, что это сложнее и вообще лень.
Потом и на работе он так же поймет, например, что задача требует оптимизации и выберет более сложный в реализации (но и более эффективный) алгоритм для ее решения. А тот товарищ, который косил под дурочка — выберет простой, но неэффективный алгоритм (потому что лень). И в лучшем случае это выяснится на ревью/нагрузочном тестировании (издержки — переписывание говнокода «ленивого программиста»), в худшем же — дойдет до продакшена и ваш сервис отвалится (издержки — сколь угодно большие).
А когда вы предъявите ему за непрофессионализм, он ответит, что вы — зажимающее свободную мысль быдло-с, тупой заучка-краснодипломник. И как подтверждение своего мнения процитирует что-нибудь из постов уважаемого Garruz.
> Увы, у многих это благое желание подменяется желанием просто тупо получить «красный диплом» – именно об этом и речь.
Если человек пришел в универ просто чтобы получить диплом — то и не надо вокруг него прыгать и «увлекать».
Конечный результат — стать специалистом в конкретной области.
Вот потому у нас и едва ли не полстраны таких «горе-специалистов» (от программистов до преподавателей) – которые учились ради корочек и должностей, а не ради знаний…
Человек должен «гореть» своей работой. И «зажечь» его – задача именно преподавателя.
А когда вы предъявите ему за непрофессионализм, он ответит, что вы — зажимающее свободную мысль быдло-с, тупой заучка-краснодипломник.
Мда… Зело оригинально вы истолковали мои тезисы – не могу не восхититься полётом фантазии… )))
Речь не о «свободной мысли». Речь о Мысли Вообще – которая выше любых статичных методик.
В конце концов, даже все эти методики писали те, кто когда-то в своё время также опровергал или дополнял ещё более старые методики. Только так всё и двигается вперёд. П – Прогресс же ж…
Если человек пришел в универ просто чтобы получить диплом — то и не надо вокруг него прыгать и «увлекать».
А если вы преподаватель – то вы просто обязаны хотя бы пытаться. Иначе ваше место с лёгкостью займёт любой вчерашний студент, тупо бубня курс по книжке – и разницы не будет почти никакой, увы…
На самом деле и это требование излишне. Изучение математики все равно состоит чуть менее чем полностью — из решения задачек, в котором преподаватель по определению не участвует, прослушивание теорем на лекциях — капля в море, по времени, так что на это даже не следует обращать внимание.
Опять же — есть море литературы, и вообще не важно, как преподаватель лекции ведет, важно, как он спрашивает.
И это в общем-то верно практически для всего остального — чуть менее чем весь процесс обучения преподаватель контролирует лишь косвенно, т.к. ученик там делает все сам, лично. И либо он хочет и делает, либо не хочет и не делает.
Никто и не говорит о задачах без теории (это как вообще? как можно решать задачки по теории групп, например, не зная, что такое группа? вы ведь даже не поймете формулировку задачи в таком случае). Смысл в том, что теория — просто некий справочный набор информации (определений и формулировок, по факту). Но этот набор фактов должен уложиться в голове и человек должен научиться оперировать соответствующими абстракциями. Это сродни обучению иностранному языку, только новые неизвестные слова в данном случае не переводятся на слова известные, и вообще не соответствуют каким-то реальным объектам из окружающего мира.
И никакого иного способа изучить этот язык кроме как много и планомерно использовать эти слова в разных контекстах (читай — решать задачки по данной теме), вобщем-то не придумано. Так что качество знаний по любому суровому матану прямо пропорционально качеству и количеству решенных задачек.
Так что интересная лекция — это хорошо конечно, но по факту мало эффективно и практически не отличаются от максимально сухой подачи информации. Что действительно эффективно — это хорошие, верно подобранные задачки. Вот это — реально то, чем следует заниматься преподавателю.
> Если он спрашивает по своему курсу, то у вас особо нет вариантов.
Да какая разница, по какому курсу он спрашивает? Теоремы и определения от этого не меняются (разве что совсем в деталях).
Уравнения математической физики? Ну так это чисто прикладная дисциплина, там теории-то и нет, просто набор эдаких best practices по решению у-й конкретного вида. А уж переходы «исходя из физических соображений...» во время доказательств некоторых у нас до нервного тика доводили :)
> Этот набор фактов куда лучше укладывается в голове, когда вы понимаете, как он строится.
Ну так это понимание исключительно с практикой и приходит. До наработки понятийного аппарата все звучит как сепульки с сепулькариями.
> Есть разница между тупым зазубриванием и осознанным восприятием с пониманием, откуда что берётся, почему, и какое условие в теореме зачем нужно.
Так я и противопоставляю тупому заучиванию решение задачек, в результате которых происходит выстраивание глубоких ассоциативных связей.
> Тот же линал можно читать как матричный анализ
Не-не-не, слушайте. Это конкретно разные курсы. Один и тот же преподаватель может легко для прикладников вести курс как описываемый вами «матричный анализ», по Ильину-Позняку, например. Другой курс, для теоретиков, который в бОльшей степени алгебра — по Ленгу с знакопеременной полилинейной формой. И третий — тензорное исчисление, опять же, в одном варианте более алгебраичное, в другом — как придаток к физическим приложениям (СТО, ОТО), с большим упором на координатное представление (как у Коренева), с-но, с определением через символ Леви-Чевиты.
Но это не хотелки преподавателя, это именно все _разные курсы_. Так уж сложилось, что любой математический объект можно исследовать в разных контекстах (как теоретических, так и прикладных), и какого-то одного «правильного» варианта тут нет. Способ диктуется назначением курса.
> И задачки на матрицы из того учебника, которые было очень трудно решать через матричный анализ, решались влёт через правильное восприятие линала.
Двухгодичный курс диффуров у прикладников вообще заменяется несколькими лекциями линейной алгебры (для линейных систем и т.п.), введением в функан (теоремы о существовании решений) и методичкой Ибрагимова по групповому анализу на три десятка страничек с описанием метода решения через группы Ли (вычисление интегрирующего множителя через допускаемую группу), который работает для всех ОДУ (в итоге надо запомнить всего пару формул, при том несложных, чтобы решать любое ОДУ, вместо кучи разных формул для специфических ОДУ). Но это был бы другой курс.
А существование и единственность обычно в курсах функана/диффуров.
> Не, просто прочитать учебник как художественную книгу, конечно, недостаточно.
О чем и речь.
> Но только подавляющее число задачек на матричный анализ легко решается из алгебраических соображений, как только понимаешь связь матрицы и оператора.
Здесь вообще тонкий момент. Есть мнение, что «операторное понимание» у людей возникает исключительно из-за того, что они до этого работали с объектом в матричной форме (то есть просто нарабатывали практическое понимание поведения данного объекта). То есть к тому моменту, как они получат то самое «красивое определение», они уже понимают, что это за объект, какие у него свойства. Понимают на интуитивно понятном уровне. И именно по-этому данный объект для них не является сепульками, и определение воспринимается как нечто красивое.
1) Который Druu предлагает, тупая зубрежка и нудное бормотание лекций
2) Упор на понимание, на задействование как можно большего числа ассоциаций, приведение живых примеров с участием аудитории, интересных аналогий.
В каком случае проще увидеть ту самую красоту? Когда ее сам преподаватель не видит или когда преподаватель понимает что не обязательно жизнь у его учеников сложилась так что им в принципе кто то мог ее показать раньше.
Можно, но зачем? Еще раз, целью образование не является развлечение.
> 2) Упор на понимание, на задействование как можно большего числа ассоциаций, приведение живых примеров с участием аудитории, интересных аналогий.
Я вобщем-то как раз и говорю об упоре на понимание. Вместо того, чтобы тратить время на развлечение студента каким-то особыми лекциями, надо просто понять тот факт, что польза лекций для обучения — минимальна. Лекции — это лишь необходимая информация которая нужна для выполнения практических заданий. И уже эти задания дают понимание. Не лекции.
> В каком случае проще увидеть ту самую красоту?
Чтобы видеть красоту надо обладать определенным эстетическим восприятием. Либо видите, либо нет, преподаватель тут не при делах. Да и вкусы у людей сильно разные.
любое нетривиальное обучение в принципе интересным быть не может
Видимо тут у нас совсем разный опыт. Я в общем то далеко не отличник, но по тем предметам которые мне были интересны — мне действительно был интересен в т.ч. и процесс изучения. Часто даже больше чем результат который он дает. В общем то эта черта и сейчас сохранилась, частенько почитываю википедию и хабр на интересные мне темы, несмотря на то что на практике мне это не понадобится.
Разве что ещё раз уточнить, что «заинтересовать» – вовсе не синоним слова «развлекать».
А зачем вам в масштабах страны нужно столько зажённых диффурами людей?
Да тут речь вовсе не только о приснопамятных диффурах – а о системе образования в целом.
К слову, меня тоже совершенно не «вставила» линейная алгебра – ибо препод был из семейства дубовых, на его лекциях спали практически все. ))
А на деле — высшее образование не для всех.
Согласен. Но дополню, пожалуй…
Преподавать в сфере высшего образования – тоже не для всех.
Я же как раз наоборот имел в виду именно тех отличников, которые соображают и понимают, а не зубрят. В учебных предметах их способности позволяют им получать верные решения очень быстро, пропуская несущественные промежуточные шаги. Да и в реальных технических задачах высокая скорость решения, как правило, — положительный фактор.
А в программировании промежуточные шаги внезапно оказываются самыми существенными. И отличники начинают искренне недоумевать по поводу наездов на их прекрасные 300-строчные функции. Но они ведь старались, они делали лучшее, на что способны! Просто никто не объяснил, что в программировании нужно в точности наоборот — писать тупой код, а быстрые и умные решения всегда имеют вредные последствия.
Мне в универе рассказывали только про структурное программирование Дейкстры, а про принцип единственной ответственности я узнал много позже. Что удивительного, что я рассуждал о длине метода, опираясь на чьи-то советы по поводу размера экрана, не понимая, какова истинная причина того, почему методы должны быть короткими.
Я же как раз наоборот имел в виду именно тех отличников, которые соображают и понимают, а не зубрят. В учебных предметах их способности позволяют им получать верные решения очень быстро, пропуская несущественные промежуточные шаги.
Да, бывает и такое – благодаря врождённым способностям, всё даётся «слишком легко», вследствие чего возникает поверхностность. И чем дольше практикуется такая надежда исключительно на собственный талант, без укрепления фундамента – тем хуже потом получается специалист (да так, в общем-то, не только в программировании, но и вообще везде – от музыки до физики)…
Но, ИМХО, тогда это уже несколько про другое – что-то вроде «синдрома таланта».
И, кстати, далеко не все такие люди действительно отличники, как ни странно. Равно как и реально понимающие отличники (из моей второй категории) – далеко не все такие «природные гении». Встречаются и те, кто действительно более чем достойно заслужил свои красные дипломы.
Просто никто не объяснил, что в программировании нужно в точности наоборот — писать тупой код, а быстрые и умные решения всегда имеют вредные последствия.
Ну, если уж мы взялись «категоризировать симптомы», то это назвал бы, скорее, «синдромом гика-нарцисса» (некая айтишная разновидность «синдрома перфекциониста» в сочетании с манией величия)). Это когда в коде даже простейшей задачи выдают такие запилы – что аж читать потом сложно, не то что разбираться…
Это тоже дикая крайность, согласен. Таких разработчиков нередко интересует не столько конечный оптимальный результат, сколько сама возможность показать своё «глубинное знание предмета», постоянно доказывая что-то окружающим (как верно подмечено в статье по Вашей ссылке)…
И тут действительно далеко не каждое быстрое решение будет умным, как и наоборот.
Я же, говоря о «быстрых и умных решениях», имел в виду именно то, о чём Вы говорите – нахождение как можно более простого метода решения, с использованием как можно более простого инструментария (видимо, тоже не вполне ясно выразился ранее, описывая тот казус со злосчастной задачей по диффурам)).
Полностью согласен, что чаще всего такой способ как раз действительно и будет одновременно самым «тупокодным», но и самым эффективным. И его простота действительно будет лишь кажущейся – в этой простоте как раз и будет заключаться настоящее изящество и мастерство.
Это и будет настоящей оптимизацией – выгодно отличаясь как от неоптимального решения «тупо в лоб» (у отличников-зубрил), так и от вычурного переоптимизированного (sic!)) решения из разряда «смотрите-как-я-ещё-умею» (у гиков-нарциссов).
И такой подход как раз достоин твёрдой пятерки и полностью подтверждает красный диплом того самого нашего условного «правильного отличника», ну разве нет?.. ))
Одно время мне казалось, что это разница между «старой школой» и «поколением твиттера» — но увидев недавно исходники Turbo Vision, нашинкованные в мелкую лапшу, понял, что нет — это таки не так, во все времена были как люди, для которых один метод на 100 строк иметь комфортнее, чем 100 методов по 5 строк, так и наоборот.
я никогда не имел проблем с необходимостью прочитать «мой собственный код годовой давности»
Тут есть ещё слегка другое правило – всегда читай свой код так, словно это чужой. Проверено, реально помогает…
А вот о том, что «во все времена» – полностью согласен. Дело вовсе не в каких-то там «временах», а исключительно в компетентности конкретных разработчиков конкретного продукта (и там уж «роляет» только то, насколько реальной компетенцией обладали представители заказчика, чтобы собрать действительно сильную команду, а не просто самых дешёвых «тупокодеров»)…
а исключительно в компетентности конкретных разработчиков конкретного продуктаВот только не надо грязи, а? К компетентности это вообще отношения не имеет.
Turbo Vision — грамотная оконная библиотека. Настолько качественная, что её ещё 10 лет использовали после официальной смерти продукта.
GCC — качественный компилятор, который до сих пор является самым популярным в мире и в ближайшее время замены ему нет и не предвидится (количество платформ, поддерживаемых clang'ом и GCC даже сравнивать не стоит — разница в разы).
Разработаны они примерно в одно время, но Turbo Vision — порезан «в лапшу» по 5-10 строк, а в GCC — нормальные, полновесные функции по 50-100 строк. О чём это говорит? Да только о том, что люди, их писавшие, имеют разные привычки, больше ни о чём!
Да только о том, что люди, их писавшие, имеют разные привычки, больше ни о чём!
Возможно это и одна из причин, но по-моему главная причина кроется в самих продуктах. GCC это самодостаточная программа, а Turbo Vision — библиотека, сделанная с расчётом на гибкую изменяемость под конкретные нужды. Поэтому каждое действие, которое потенциально может быть переопределено, там вынесено в отдельную функцию, да ещё и виртуальную обычно. Ну а остальные (не виртуальные) вероятно уже из соображений единообразия пришлось писать так же.
Всего лишь естественное (!) разделение на хорошие и плохие команды разработчиков.
ИМХО, как бы ни был хорош сам конечный продукт – это ни разу не оправдывает кривизны конечностей его создателей. Без коей кривизны продукт мог бы стать ещё лучше…
ИМХО, как бы ни был хорош сам конечный продукт – это ни разу не оправдывает кривизны конечностей его создателей. Без коей кривизны продукт мог бы стать ещё лучше…Это какая-то софистика. Едиственный обьктивный критерий качества команды — это качество продукта. Рассказы про то, что «без этой кривизны было бы ишшо лутче» упираются в простой факт: никто не сделал «лучте» работая «по фен-шую», так что сравнивать особо и не с чем.
Вот взять хоть тот же мелкомягкий «Офис». Оброс новыми фичами? Да! Стал «умнее»? Да! Исправили все основные косяки? Нет!
В итоге получаем что??? Качество в целом лучше. Но в целом всё так же просится в руки напильник, и достаточно регулярно.
Теперь, надеюсь, более понятно?
Если бы в командах были реально думающие люди – не было бы подобных фейлов. А вот то самое наличие реально думающих людей – в итоге всегда определяется кадровой политикой работодателя…
Неужели всё ещё не чувствуете связи (конкретно в контексте статьи, разумеется)?
Неужели всё ещё не чувствуете связи (конкретно в контексте статьи, разумеется)?Я почувствую связь, если вы предьявите более качественную и более популярную альтернативу.
Потому что пока что мы ходим по кругу: вы заявляете, что если бы люди, не исповедующую вашу «религию» ею бы прониклись, то результат получился бы гораздо лучше, а, не являясь, в общем-то, человеком религиозным, требую доказательств.
На что получаю куча разного рода бессмысленных фраз типа «неужели всё ещё не чувствуете связи».
Формально доказывать правильность программ — учили. Всякие там «дано/надо», инварианты и индуктивные расширения. Это — было, да.
Нашинковать код «в лапшу» — никто никогда не просил и функции на 100-150 строк (при наличии прописанных инвариантов, пред и постусловий) — никого не удивляли.
Правда я по образованию математик, не программист.
Плюс, возможно, математиков в программировании действительно не «дрочили» так сильно как нас. Я на их парах не был, но точно помню, что после разделения общего потока ПМП на специальности – математики уже к концу третьего курса значительно отставали от нас в этих вопросах (равно как и мы в их профильных предметах). Что, ИМХО, вполне естественно, с учётом разницы специализаций…
Поэтому, думаю, тут ещё и другая проблема (вызванная целым рядом внешних причин, от политики до экономики) – частая работа не по специальности. Когда диплом говорит работодателю лишь о наличии высшего образования (о, как они обожают этот бесполезный в наших условиях пункт!)), но не гарантирует ровным счётом ничего, порой даже не влияет на профиль работы. Что, в том числе, также сильно влияет на обсуждаемый вопрос.
Впрочем, это уже совершенно отдельная, огромная и печальная тема…
Возможно, оттого и не понимаем друг друга, что были разные преподаватели.У меня есть ощущение, что вы сами себя не очень понимаете. Потому тут — вы толкаете мысль о том, что всё нужно делать «по правилам», соблюдая «профессиональную этику» и всё такое прочее.
А чуть выше вы толкаете ровно противоположную мысль: игра «по правилам» — это «для слабаков», если вы всё делаете не «как сказали», а «как проще» — то вы молодец, заслуживаете пятёрки… и всё такое прочее.
Не объясните — как эти мысли совмещаются? Почему вдруг у человека, который решает задачи не так, как ему сказали, а как ему хочется возьмётся «профессиональную этика» и желание всё делать не так, как ему удобнее и проще, а так, «как его учили»?
А вот вы почему-то не понимаете разницы между указанными двумя совершенно разными тезисами…
Соблюдение правил «профессиональной этики и всего такого прочего» требуется там, где их нарушение может повлечь за собой последствия не только для вас лично, но и для ваших коллег, и для заказчиков и/или работодателей, и даже для пользователей. В лучшем случае это будут просто неудобства, в худшем случае это будет либо громадная потеря времени на рефакторинг, либо сырое/глючное/тормозное ПО.
Ведь правила-то эти придуманы вовсе не мной, я тут выступил лишь в роли Кэпа-Напоминателя… ))
А вот по второму варианту «несоблюдения правил», когда предлагается искать нетривиальные решения, направленные на максимальное упрощение структуры – всё прямо противоположно. Это просто «маст хэв». Находить кратчайший и наиболее эффективный*** путь решения поставленной задачи – и есть основная цель хорошего программиста.
Просто представьте себе ту же самую упомянутую выше задачу в коде. Вы бы написали «как положено», я бы написал «как проще и быстрее». При получении в обоих случаях равного результата – мой код работал бы намного быстрее. Реальная оптимизация налицо.
*** – Отдельно отмечу, что понятие «эффективность» тут весьма ёмкое. Кроме прочего, в него входят, в том числе, и все «заморочки» из первого пункта (про читаемость, простоту, и далее по списку).
В лучшем случае это будут просто неудобства, в худшем случае это будет либо громадная потеря времени на рефакторинг, либо сырое/глючное/тормозное ПО.Сырое/глючное/тормозное ПО я как раз наблюдаю там, где люди всё делают «по правилам», забывая про здравый смысл. Но это — другая история.
Вы бы написали «как положено», я бы написал «как проще и быстрее».Странно. Вот тут вы предлагали делать строго противопложное.
При получении в обоих случаях равного результата – мой код работал бы намного быстрее.У вас либо мало опыта, либо вы реально не умеете писать эффективный код.
Если алгоритм, реализуемый в коде, неизменен (да, это самое главное, конечно, тут не поспорить), то его скорость — редко когда оказывается максимальной у пропогандируемого сегодня «лапшеобразного» подохода.
Как говорит Линус: Trust me: every problem in computer science may be solved by an indirection, but those indirections are *expensive*. Pointer chasing is just about the most expensive thing you can do on modern CPU's.
**** – Отдельно отмечу, что понятие «эффективность» тут весьма ёмкое. Кроме прочего, в него входят, в том числе, и все «заморочки» из первого пункта (про читаемость, простоту, и далее по списку).Увы и ах, но так понимаемая «эффективность» — прямой враг эффективности в смысле «скорость работы по секундомеру» и «потребления памяти в байтах». Все (ну хорошо, почти все) приёмы, пропагандируемые как способ сделать код понятнее и гибче — делают это за счёт эффективности.
Введение «удобных» абстракций и разрезание единого целого на маленькие кусочки почти всегда замедляют программу. В моей практике — от трёх до десяти раз.
Главная беда — что очень часто разделение задачи на подзадачи приводит к тому, что подзадачу невозможно решить достаточно эффективно.
Мой любимый пример для собеседований: функция
is_binary_search_tree (возвращающая true для деревьев, являющихся двоичными деревьями поиска и false для деревьев не являющихся двоичными деревьями поиска). Если вы «для понятности» разобьёте задачу на три подзадачи (как это описано в определении)… то вы безвозвратно потеряете возможность решить эту задачу эффективно.Так как проверка того, что все элементы в дереве меньше (или больше) заданного числа — это O(N), а дальше, если дерево у нас несбалансированно многократный вызов этих проверок — это O(N2). И всё. Вот совсем всё.
Почему-то эта простейшая, даже во многом тривиальная задача является таким «ударом под дых», что они его перенести просто не могут: ну как так-то? Они всё «по фен-шую» делают, а оно… не работает! Так «не положено»!
Любое эффективное (без кавычек) решение будет с неизбежностью смешивать проверки этих трёх свойств — а стало быть будет более сложным (в смысле читаемости), чем неэффективное решение.
И в реальных задачах — то же самое: "«заморочки» из первого пункта" почти всегда вступают в противоречие с эффективностью (в нормальном, человеческом смысле: время работы в секундах и потребность в памяти в байтах).
Сырое/глючное/тормозное ПО я как раз наблюдаю там, где люди всё делают «по правилам», забывая про здравый смысл.
Это, конечно, странно – но вы сейчас практически повторяете мои слова. ))
Разница лишь в том, что мы с вами говорим о разных правилах – и, соответственно, расходимся во мнениях, какие правила когда конкретно разумнее применять.
Странно. Вот тут вы предлагали делать строго противопложное.
Не вижу там совершенно ничего «противоположного» всему ранее сказанному. Поясните, пожалуйста.
Если алгоритм, реализуемый в коде, неизменен (да, это самое главное, конечно, тут не поспорить), то его скорость — редко когда оказывается максимальной у пропогандируемого сегодня «лапшеобразного» подохода.
Скажите, а разве разработка более оптимального алгоритма как-то непременно способствует появлению «лапши»? Это я сейчас даже не вспоминаю про более оптимальную структуру в целом, остановимся только лишь на алгоритмах…
До выяснения этого момента – даже не буду возвращать вам обратно вашу же фразу про малый опыт и прочие «неумения»… ))
Увы и ах, но так понимаемая «эффективность» — прямой враг эффективности в смысле «скорость работы по секундомеру» и «потребления памяти в байтах».
Эффективность измеряется вовсе не только в секундах и байтах. Но и в совместимости со всем подотчётным зоопарком осей – а также их версий и/или разрядностей, каждая из которых со своими заморочками, даже не считая всяких сервиспаков. Либо, в случае веб-разработок – со всем подотчётным зоопарком браузеров, каждый из которых со своими заморочками, даже не считая всяких минорных версий.
И ваша задача как программиста – сделать так, чтобы ваш код работал в любом окружении. А для этого он как раз и должен быть максимально простым. Но в то же время и максимально скоростным.
И вот именно в этом «компромиссе» между скоростью и совместимостью – и требуется максимальное приложение всех знаний и умений.
P.S. Я тут в какой-то из тем уже приводил самый тупой пример той же 1С. Сама по себе – достаточно годная штуковина, да. Но, мля, сколько же там лютейших косяков именно в плане совместимости между версиями (я уж даже не вспоминаю про «сажаемость» на разные оси, там вообще только «обнять и плакать»)…
Вот сразу видно, что там писали тупо «как учили» – вообще не думая о том, «как надо».
Скажите, а разве разработка более оптимального алгоритма как-то непременно способствует появлению «лапши»?В данном случае «лапша» — это 100500 методов в 3 строки каждый. И она, как правило, препятствует написанию оптимального алгоритма. Просто потому, что во процессе подобного разбиения вы, как правило, будете вводить некоторые абстракции, которые, может быть, и упростят понимание кода, но зато замедлят его и потребуют больше памяти.
Покажите, к примеру, как вы будуте писать
is_binary_search_tree — тогда можно будет обсудить влияние «профессиональной этики и всего такого прочего» на качество результата.Эффективность измеряется вовсе не только в секундах и байтах. Но и в совместимости со всем подотчётным зоопарком осей – а также их версий и/или разрядностей, каждая из которых со своими заморочками, даже не считая всяких сервиспаков.Далеко не всегда это нужно. Если вы пишите код, который запускается у вас на сервере, то вы, зачастую, вполне можете полагаться на то, что у вас используется конкретный компилятор с конкретным сервис-паком и на конкретном железе.
И ваша задача как программиста – сделать так, чтобы ваш код работал в любом окружении. А для этого он как раз и должен быть максимально простым. Но в то же время и максимально скоростным.Не бывает, извините. Либо-либо, никак не одновременно. Вплоть до того, что некоторые вещи, ускорящие код под clang'ом могут замедлять его под MSVC и наоборот.
И вот именно в этом «компромиссе» между скоростью и совместимостью – и требуется максимальное приложение всех знаний и умений.Кавычки тут, увы, неуместны. Вы всегда выбираете что-то. Либо максимальную скорость, либо максимальную совместимость, либо максимальную читабельность. Даже последние две вещи зачастую сложно совместить, а уж про то, чтобы совместить все три — и говорить не стоит.
P.S. Я тут в какой-то из тем уже приводил самый тупой пример той же 1С. Сама по себе – достаточно годная штуковина, да.Нет. Они с самого начала сделали достаточно разумный (на тот момент) выбор в сторону совместимости и переносимости — использовали формат DBF и свой собственный язык. В результате — смогли завоевать рынок. Но говорить о скорости работы в приложении к 1C… это просто смешно. Вещи, которые можно было бы делать за секунды — занимают, зачастую, часы. Но это — плата за совместимость и простоту поддержки.
Было ли это хорошим выбором? Ну если судить по популярности, то да, наверное.
Вот сразу видно, что там писали тупо «как учили» – вообще не думая о том, «как надо».Они думали как раз о том «как надо». Но из этих «как надо» — было выбрано некоторое подмножество. Которое и было реализовано.
Вы же выступаете то «за всё хорошее, против всего плохого», то за «максимально эффективный код, совместымый со всем зоопарком» — а так не бывает, извините.
В данном случае «лапша» — это 100500 методов в 3 строки каждый.
Я прекрасно понимаю, что такое «лапша». Странно, что вы не заметили, но вопрос был совершенно в другом – каким образом «лапша» связана с оптимизацией?
Если вы пишите код, который запускается у вас на сервере, то вы, зачастую, вполне можете полагаться на то, что у вас используется конкретный компилятор с конкретным сервис-паком и на конкретном железе.
Согласен.
Но, во-первых, мы говорим о клиентах. А во-вторых, даже на сервере скорость никто не отменял.
В масштабах одного юзера – это «всего-то» какие-то доли секунды. Но вот в масштабах уже хотя бы тысячи юзеров – это уже десятки секунд…
А теперь – вновь в условиях той задачи – попробуйте трезво оценить время исполнения той задачи сначала на вашем «правильном» решении, а затем на моём «неправильном». Надеюсь, после этого большинство вопросов исчезнет само собой…
Не бывает, извините. Либо-либо, никак не одновременно.
Даже последние две вещи зачастую сложно совместить, а уж про то, чтобы совместить все три — и говорить не стоит.
Бывает, извините. Просто пишите код на самых суровых стандартах – которые уж точно никак не зависят от сиюминутной моды и прочих «местечковых» ништяков. И никогда не бросайтесь сразу же использовать все новые фичи – как минимум до тех пор, пока они не будут поддерживаться хотя бы 2/3 вашего предполагаемого «зоопарка» осей/браузеров.
В противном случае – либо вам, либо вашим коллегам потом всё равно придётся долго мудохаться с обратной совместимостью…
Было ли это хорошим выбором? Ну если судить по популярности, то да, наверное.
Тут с самого начала была не столько популярность, сколько некая «безальтернативность». Все мои бухи (и админы)) чуть ли не буквально рвали волосы на пятых точках от заходов сего «шедевра» – но деться от него никуда не могли.
Но согласен в том, что этот рынок у нас ещё крайне мало освоен – на фоне чего лидерство конкретно 1С выглядит крайне нездоровым явлением…
Вы же выступаете то «за всё хорошее, против всего плохого», то за «максимально эффективный код, совместымый со всем зоопарком» — а так не бывает, извините.
Вновь говорю – бывает же.
Чтобы далеко не ходить, взгляните на продукты хоть тех же мелкомягких, равно как и на продукты ключевых win-разработчиков – какие-то совсем уж «катастрофические» ограничения случаются у них крайне редко, минимум раз в пять лет (а то и больше, в зависимости от степени следования гайдам).
ИМХО, это уже вполне разумный цикл жизни версии.
Странно, что вы не заметили, но вопрос был совершенно в другом – каким образом «лапша» связана с оптимизацией?
Некоторые задачи поддаются оптимизации только целиком, а не по частям. Чем больше частей — тем сложнее понять что происходит и как переписать оптимальнее.
Тут просто человек приводит «лапшу» в качестве якобы «непременного последствия» хорошей полноценной оптимизации. Вот потому и вопросы к нему такие.
Если вдруг ошибаюсь – пожалуйста, укажите, когда именно и в каком конкретно комментарии я «свернул не в ту сторону» в понимании тезисов оппонента…
Нет. Первое упоминание слова "лапша" идет в ответ на комментарий DistortNeo, который отвечал на комментарий SergeyGalanin, который уже отвечал вам. То есть связь с вашими тезисами если и есть — то очень косвенная, дискуссия ушла в сторону.
И в том комментарии ничего не говорилось про оптимальность, просто заявлялось что разным людям удобнее по-разному. А в следующем комментарии он привел факт: два качественных (с его точки зрения) продукта — Turbo Vision и GCC, которые написаны в разных стилях.
В какой момент в ветке появилась умная оптимизация — не могу сказать, потому что в половине ваших комментариев я не вижу тезисов.
Согласен, и признаю вину – действительно слегка занесло в пылу спора.
А с тезисами всё просто – высказал их ещё в самом начале. Тематика же всех прочих комментариев действительно виляет в разные стороны – но исключительно в русле ответов оппонентов (это уж как водится на форумах, «слово за слово» и всё прочее из этой серии)).
В какой момент в ветке появилась умная оптимизация — не могу сказать, потому что в половине ваших комментариев я не вижу тезисов.Умная оптимизация появилась примерно здесь, когда было заявлено, что настоящий
После чего я ответил: если алгоритм, реализуемый в коде, неизменен (да, это самое главное, конечно, тут не поспорить), то его скорость — редко когда оказывается максимальной у пропогандируемого сегодня «лапшеобразного» подохода.
Каким местом нужно это читать, чтобы решить, что я выступаю за «простой», «понятный» код, где каждая функция состоит из трёх строк — мне неведомо.
В тех местах, где эффективность не так важна — можно и так писать. Turbo Vision, кстати — тот ещё тормоз, если сравнить работу Turbo Pascal 5.0 и Turbo Pascal 7.0 на машинке с 1GHz процессором, то это легко заметить (достался мне такой раритет во время обучения в какой-то момент… ему лет было чуть ли не больше, чем мне… но тогда у меня не было выбора — и мне он не казался чем-то устаревшим). Однако его гибкость и малая (по сравниени со всякими GEMами и GEOSами, не говоря уже про Windows) потребность в ресурсах обеспечили ему заслуженную популярность.
Я даже пример привёл, чтобы показать как популярный сегодня подход «ни в одной функции не должно быть больше трёх строк кода» может привести к проблемам на примере
is_binary_search_tree… но оказалось, что рассуждать о «профессиональной этике» — веселее, чем что-то делать практическое, так что дискуссии не получилось…Умная оптимизация появилась примерно здесь, когда было заявлено, что настоящий шотландец программист должен каким-то мистическим способом добиваться одновременно читабельности кода, его простоты и эффективности.
А вы всё ещё считаете это якобы «недостижимым результатом»???
Я даже пример привёл, чтобы показать как популярный сегодня подход «ни в одной функции не должно быть больше трёх строк кода»
Я вот не слышал вообще ничего про такой «якобы популярный» подход (особые сомнения вызывает его якобы «популярность», но не будем уже вдаваться в эти дрязги)))))). Но если б даже услышал – то все авторы данного «подхода» сразу же отправились бы нах…
Если вы перечитаете всю ветку полностью – то сразу же обнаружите, что именно этот «тезис» моего оппонента я и опровергаю уже несколько постов подряд.
Зачем мне-то приписывать эту ересь – против которой я же первым и стал спорить? )))
Вот же:
… разве разработка более оптимального алгоритма как-то непременно способствует появлению «лапши»?
И далее:
… вопрос был совершенно в другом – каким образом «лапша» связана с оптимизацией?
Либо вы просто запутались в комментаторах (что бывает), либо мы говорим о каких-то разных вещах, не понимая друг друга (что также бывает)…
Напомню, на первый ваш вопрос вам русским языком ответили:
она [лапша], как правило, препятствует написанию оптимального алгоритма
И дальше с этого момента вы начали этот тезис зачем-то оспаривать. И до сих пор спорите...
Более того – вторая цитата в моём предыдущем комментарии как раз и была адресована тому автору, ссылку на комментарий которого вы дали. )))
И все мои ответы конкретно по данной теме – были исключительно о том, что действительно умная оптимизация вовсе не обязательно порождает ту самую «лапшу» (на чём почему-то настаивали оппоненты)…
Видите – я же говорил, что всё просто.
Вы, видимо, действительно запутались (что немудрено, комментариев тут тьма тьмущая). В любом случае, с моей стороны оспаривался вовсе не тезис о том, что «лапша препятствует оптимизации» (с которым я, внезапно, полностью согласен)), а совершенно обратный – что оптимизация якобы (!!!) порождает «лапшу».
Поэтому, простите уж, но это именно вы сейчас сами придумали какое-то мнимое «расхождение» в моих постах – и сами же его упорно доказываете. Зачем-то… ((
А вы, всё же, воспользуйтесь советом. Либо, уже после пользования оным советом – объясните, всё же, максимально подробно суть своих претензий (которые пока не вызывают у меня совершенно ничего, кроме искреннего недоумения).
Лично я пока вижу в ваших «претензиях» (да, тут в кавычках) – всего лишь какую-то недопонятость, либо же вообще полное непонимание.
Если претензии действительно обоснованы – будьте добры, приведите все (вообще все) относящиеся к теме комментарии со всеми вашими выводами из них.
Раз:
увидев недавно исходники Turbo Vision, нашинкованные в мелкую лапшу, понял, что нет — это таки не так, во все времена были как люди, для которых один метод на 100 строк иметь комфортнее, чем 100 методов по 5 строк, так и наоборот
Где тут хоть слово про оптимизацию? Нету! И по второй ссылке тоже про оптимизацию ни слова. Так с чем же вы спорите тогда?
Раз, два. И это ещё как минимум…Это как раз как максимум. Ибо вы с упорстовом, достоным лучшего применения, пытаетесь приписать мне то, чего я не говорил.
В частности к вашим раз, два стоит добавить три — и сразу станет понятно, что к чему.
Да — Turbo Vision хорошая, качественная библиотека. Гибкая, достаточно удобнам… и в меру тормознутая. По меркам 90х, конечно. Её нашинковка в пятистрочные функции — для меня несомненный минус, который, впрочем, часто перекрывается другими её плюсами.
Сегодня её, пожалуй, томознутой назвать не получится — но это просто потому что точка отсчёта уехала: то, что считалось «жирным» и «тормозным» кодом в 90н по сравнению с тем, что порожают UI-творители сейчас — это просто образец стройности.
Дано: некоторый дифур
Найти его решение
А если написано про пулю и барабан — то это не упражнение на дифуры, а задача. Которую можно решать разными способами.
Это упражнение на решение диффура. А речь идет о составлении. Взять задачу про барабаны и составить по ней диффур (ну и решить, конечно, тоже, потом, раз уж составлен). Это тоже очень важный навык.
> Которую можно решать разными способами.
Я вам открою секрет, но даже если вам дан, например, диффур (даже не задача с барабанами) и есть много способов его решить (обычно диффуры можно решать по-разному), то обычно следует решать вполне конкретным способом. И подобное верно для задач практически любого типа — любые нормальные задачи пишутся с учетом того, каким именно способом будет ее решать ученик. При этом задача (если она хорошая) часто намеренно формулируется так, чтобы ученик при использовании данного способа в этой задаче, например, встретил какие-то подводные камни. Увидел некоторые особенности данного метода и смог их «пощупать» на праактике, и так далее. При этом часто решение данным методом только усложняется и возникает еще больший соблазн пойти легким путем — но тогда вы просто выкидываете в мусор всю работу авторов задачи и не получаете от решения дОлжной пользы.
Конечно же, это всегда ответственность преподавателя — донести до ученика информацию о правильном выполнении утверждения. И цимес в том, что в 99% случаев она как раз доносится. Но каждый любой ученик ведь мнит себя умнее всех, чо ему какие-то рекомендации? Будет решать, как хочется. И пофиг, что эффективность такой тренировка кратно падает.
Превосходно. У вас есть GPU (или любой другой специализированный вычислитель) и необходимо решить задачу через матричные вычисления, но у вас же есть "свои" методы, которыми вы успешно решаете на CPU.
Это провал Карл! Ваше решение не оптимально!
Дифуры и физика — это всего лишь инструменты, так же как CPU и GPU. И нужно уметь пользоваться ими, а не показать, какой вы молодец. И замечу — способность видеть множество решений — это только плюс вам. Но решение обязано подпадать под ТЗ. Иначе вы подставляете человека.
Просто подумайте, у вас попросили отмерить 1 метр оптоволокна, но вы решили, что отмерить 2 фута будет проще. Как потом быть заказчику? Смысл именно в инструментах и стандартах.
У вас есть GPU (или любой другой специализированный вычислитель) и необходимо решить задачу через матричные вычисления, но у вас же есть «свои» методы, которыми вы успешно решаете на CPU.
Если оптимальнее будет на GPU – решаем на GPU. Если оптимальнее на СPU – решаем на СPU. Просто же… ;)
Но решение обязано подпадать под ТЗ. Иначе вы подставляете человека.
Какого человека?
Если того, кто пишет ТЗ – то прежде всего проверяется само ТЗ на предмет компетентности составителя и актуальности поставленных задач. Затем проводится анализ всех методов. Затем, если у вас появляются замечания по ТЗ и если вы считаете, что результата можно и нужно достичь иными способами – проводите переговоры с заказчиком, аргуметированно формулируя ему свою точку зрения.
Да, это намного больше возни, чем просто «отработать по ТЗ». Но только так и становятся настоящими профессионалами – думая не только об исполнении, но и о результате.
Просто подумайте, у вас попросили отмерить 1 метр оптоволокна, но вы решили, что отмерить 2 фута будет проще. Как потом быть заказчику?
Если «вместо» 2 метров заказчик получит 6,5617 фута – он получит именно то, что просил. Но если мне удобнее мерять в футах – он получит свои 2 метра быстрее. Что уже есть оптимизация. Просто же… ;)
Ну и где тут «подстава человека»? ))
Уже в том месте, где изначальный метр превратился в 6,5617 фута.
Из-за вот таких вот приколов самолеты падали, потому что заправляли-заправляли, а топлива на половину пути. То что вам кажется некомпетентным может на деле оказаться необходимостью конкретного случая.
Мы не говорили по поводу написания ТЗ. Так же как и на том уроке по дифурам — вам уже дали ТЗ, оно уже существует. Обсуждать его нечего.
Вы пытаетесь дать себе больше степеней свободы, что бы не напрягаться и сделать побыстрее, в то время как иногда ваше "побыстрее" может стоить млрд баксов при внедрении, и все из-за того, что вы сочли, что заказчик некомпетентен. Угадайте, будут ли вас нанимать?
Я вижу вы спорщик знатный, поэтому откланяюсь. То, что до вас пытался донести я и еще один человек до меня — вы понять отказываетесь. Все время на "заказчиков-идиотов" указываете, только вот мир немного иначе устроен. Не ч/б.
Желаю вам успехов.
Из-за вот таких вот приколов самолеты падали
Самолёты падали как раз из-за других приколов – что некие особи не удосуживались перевести футы в метры. Как раз всецело доверяясь «всемогущему» (в вашем понимании) ТЗ, даже не удосужившись его осмыслить и перепроверить…
вам уже дали ТЗ, оно уже существует. Обсуждать его нечего.
Вновь слепое поклонение ТЗ…
Мой пример именно против этого и был направлен. Любое ТЗ надо перепроверять самому. Поскольку с вероятностью как минимум 90% – пишет его человек, гораздо менее компетентный в данных вопросах, чем вы (не унижая этого человека, а просто указывая на тот факт, что он в этом разбирается априори хуже вас).
в то время как иногда ваше «побыстрее» может стоить млрд баксов при внедрении, и все из-за того, что вы сочли, что заказчик некомпетентен. Угадайте, будут ли вас нанимать?
Поверьте, ваше «строго по ТЗ» порой может стоить намного больше миллиардов баксов – просто потому, что специалист в этой ситуации именно вы, и вся ответственность за приёмку заведомо левого ТЗ лежит именно на вас (см. выше)…
А если работать со сложными сущностями, то IDE, по типам данных, может выдавать полезные советы и помогать анализировать код, в языках со статической типизацией.
При написании любого кода умным программистом учитывается использование кода в следующих контекстах:
— решение текущей задачи самим программистом (контекст – только я);
— модификация кода самим программистом по прошествии времени, когда смысл кода уже подзабыт (контекст – я и мое будущее);
— использование и/или модификация кода другими программистами (контекст – я и другие люди).
С другой стороны, всех отличников можно разделить на две большие категории:
— «умные», обладающие гармонично развитым интеллектом, способные не только к усвоению учебного материала, но и к пониманию, как его можно применить в будущем, при этом учитывающие свои предпочтения и навыки в общении с другими людьми;
— «ботаники», способные только к усвоению учебного материала, при слабой развитости к видению своего будущего и слабых навыках социализации.
С учетом предложенной классификации проблему написания длинного кода можно сформулировать следующим образом — «непонятный код пишут ботаники», так как они игнорируют свое будущее и проблемы других людей.
Если же ботаник действительно талантлив и может писать работоспособный код, то для оптимизации и (само-)документирования кода ему нужно просто приставить помощника, не сильно талантливого, но дисциплинированного и добросовестного. И такая команда сможет работать гораздо эффективнее, чем два отдельных умных программиста. А это уже проблема и сфера ответственности руководителя такого ботаника.
Пример с дифференцированием не показателен — все же дифференцирование — это строго определенный процесс.
С программированием лучше проводить аналогию взятия интегралов, а лучше решение дифференциальных или интегральных уравнений.
То есть вначале надо определить способ решения задачи, а потом его реализовать.
В таком случае трудно говорить о пропуске шагов — удобный (оптимальный) способ нужно знать — не знаешь такой способ (например, фреймворк), придется долго и мучительно писать килобайты кода.
А знание — это долговременная память.
Насчет кратковременной памяти — современные среды разработки можно сказать ее заменяют
Давайте просто честно скажем, что чаще всего мы пишем плохой код не потому что бла-бла-бла куча серьёзных, важных причин и независящих от нас обстоятельств. Всё намного проще: мы ленивы и эгоистичны.
Нам лень потому, что это дольше и сложнее.
Нам плевать потому, что с этим кодом потом будет работать кто-то другой.
В большинстве случаев диагноз этого такой: человек некомпетентен как разработчик.
В общем, не нужно слепо винить отличников, бывают и обстоятельства.
сделать, чтобы работало и было понятно среднему индусу
Вы видели код библиотеки из какого-нибудь Facebook? Для работы, например с распределенными графами? Или что-то иное? Как средний индус будет писать тесты для вот этого:
github.com/facebook/rocksdb/blob/master/db/compaction_job.cc#L683
Мы задумывались на несколько секунд и записывали готовый результат…и не получали полное количество баллов за задание, если учителю было важно не одно лишь (неизвестно откуда взявшее) нетривиальное решение.
Умение (и желание!) быть понятным — такая же профессиональная компетенция, как и умение решать проблемы.
Учитель должен давать не только задачу, но и критерии оценки результата.
Задач про бучении бывает всего две:
1. тренировка навыка
2. проверка навыка
Ни ту, ни другую голый ответ не решает.
Как проверить, что она работала, и отработала именно нужные навыки?
Я думаю, учитель всегда прекрасно знает каждого ученика: его способности и меру ответственности. И если способный и ответственный ученик записывает готовый ответ, учитель, как правило, будет ему доверять (хотя, наверное, будет вздыхать при этом). С таким учеником можно быть уверенным, что если записал ответ без шагов — значит, справился с решением в уме.
А к не очень ответственным и не очень способным — к тем да, возникают вопросы.
А как проверить, что она работала, когда все шаги записаны? Можно ведь и списать?
Против этого наработан ряд стандартных приёмов, начиная с переименования переменных и сдвига коэффициентов :) Если ученик справляется с таким — он достаточно разбирается в теме, даже если отдельные элементы где-то подсмотрел.
Но для случая голого ответа это не работает в принципе.
Я думаю, учитель всегда прекрасно знает каждого ученика: его способности и меру ответственности.
Я вижу, что даже в мелких группах вроде 10-15 человек, как в наших вузах, это не так, погрешность очень велика. Кто-то учит в последнюю ночь, но сдаёт потом с блеском. Кто-то вдруг влюбился и в голове что угодно, кроме дифуров. И так далее. Чтобы это контролировать, надо иметь ежедневное плотное общение с каждым. Такое только в фантастике или при индивидуальном обучении.
Исключения есть, но чем выше уровень предмета, тем они меньше.
не очень монструозный, чтобы не на полчаса времени
Полчаса на одного студента для такого теста это, мягко говоря, дофига. В этом и проблема — автоматизация позволяет и время сэкономить, и сделать задачу в достаточно разнообразном виде.
Имхо, Вы ищете сложные пути решения для простой проблемы)
Ни капельки. Как раз вызвать к доске и тщательно вникать в подробности… ну, при нашем стиле обучения можно один раз на студента в семестр такое позволить, но не больше.
задавались вопросы, если где-то логика перехода была преподу не ясна.
И наверняка половина наобум просто не проверялась — не успевал.
Для начала сообщить обучаемому какие навыки должна вводить, закреплять и проверять данная задача. Каковы функциональные и нефункциональные требования к процессу решения.
Для начала сообщить обучаемому
Это не то. Это требование поставки результата в конкретном виде, а не метод проверки результата, который уже оказался в несоответствующем виде.
Разумеется, проще всего не принять формально несоответствующий результат. Но это 1) как раз то, что обсуждается в формате "а почему вообще не принимать?", 2) отвратит наиболее умных и ленивых — которые как раз потенциально самые интересные для будущего развития.
Если нам требуется тренировать и проверять навык решения задач определенного типа, то нам достаточно результата. Если нам требуется тренировать и проверять навык документирования процесса решения, то достаточно документации с итоговым, пускай и неверным, ответом. Если нам требуется тренировать и проверять навык решения задач определенного типа определенным способом, то нам нужно и документирование процесса решения, для усиления гарантий того, что задача решалась определенным методом, и соответствие результата ожидаемому, для гарантий того, что задача решена.
Нет, не достаточно. Доказательством наличия навыка является процесс решения, а не результат.
> определенным способом
«определенным способом» — это и есть навык. Если у вас задача «есть три мальчика, у каждого по два яблока, сколько вместе» — то это, почти наверняка, задача на умение умножать. И если вы написали «6» путем сложения 2+2+2=6, то вы ни черта не продемонстрировали, кроме того, что до вас медленно доходит.
Доказательством наличия навыка является процесс решения, а не результат.
Не согласен. Многократно получены правильные результаты на задачах одного типа — вероятность наличия навыка много выше случайного угадывания.
«определенным способом» — это и есть навык.
Навык решать задачи определенного типа является суперпозицией навыков решать задачи данного типа разными способами, но необходим и достаточен только один. Навык выбора наиболее оптимального в данном контексте способа — отдельный навык. Навыки определения контекста и метрик оптимальности в данном контексте — тоже отдельные навыки.
то это, почти наверняка, задача на умение умножать.
"Почти" не считается. Например в первом классе и на втором, кажется, курсе, мои решения "зарезали" за использование умножения на подобных задачах.
Но наличие навыка это не демонстрирует.
> Навык решать задачи определенного типа является суперпозицией навыков решать задачи данного типа разными способами, но необходим и достаточен только один.
Необходим и достаточен для чего? Учебные задачи дают не для того, чтобы научиться решать учебные задачи. Их дают для того, чтобы освоить именно тот или иной _способ решения_. Который вы потом будете применять на _других_ задачах. А школьные задачи вы нигде кроме как в школе решать не будете.
Это как этюды в музыке, направленные на выработку конкретного технического приема. Их смысл не в том, чтобы научиться играть (как-то) этюд, а в том, чтобы отработать прием и использовать его уже на другом (не обязательно уже учебном) материале. А если вы играете этюд каким-то особенным читерским способом, то и толку от него нет, просто трата времени в никуда.
> «Почти» не считается.
К счастью, в реальности (а не в модельной ситуации) у ученика есть стопроцентное знание, без почти.
Но наличие навыка это не демонстрирует.
Ну как не демонстрирует?! Навык решения задач определенного типа как раз и демонстрирует выдача правильного результата на достаточно большой выборке задач этого типа.
Учебные задачи дают не для того, чтобы научиться решать учебные задачи. Их дают для того, чтобы освоить именно тот или иной способ решения.
Это обычно не сообщается ученикам перед решением задач. Об этом чаще сообщается при отказе принять решение за верное на основании "ну и что, что ответ правильный. этот пример в главе про умножение, а значит решать его надо умножением, а не сложением или взятием интеграла". В лучше случае ученикам сообщается об ожидаемом способе решения и форме его оформления: "учитель сказал надо таким способом решать и так оформлять — на "отлично" не рассчитывай при ином подходе". Цель этого не доводится до учеников.
Навык решения школьных задач никому не нужен. В школе не учат решать школьные задачи. Школа не для этого.
> Это обычно не сообщается ученикам перед решением задач. Об этом чаще сообщается при отказе принять решение за верное на основании «ну и что, что ответ правильный. этот пример в главе про умножение, а значит решать его надо умножением, а не сложением или взятием интеграла».
Даже если предположить, что заранее не сообщается, после первого (окей, пусть второго-третьего) «этот пример в главе про умножение, а значит решать его надо умножением, а не сложением или взятием интеграла» даже до дятла дойдет, в чем тут дело. И проблема в итоге не в непонимании, а в лени.
Навык решения школьных задач никому не нужен. В школе не учат решать школьные задачи. Школа не для этого.
Нужность или ненужность навыков, прививаемых де-факто в школе — отдельный большой разговор. Но речь шла о демонстрации владении навыка решения задач.
И проблема в итоге не в непонимании, а в лени.
Слишком категорично, чтобы быть правдой. Во-первых, может быть недостаточно быть развит навык использования неполной индукции. Во-вторых, может быть неприятие (инстинктивное или специально воспитанное — не суть) авторитарных методов управления типа "Делай так, как я сказал, потому что я лучше знаю, что тебе нужно". В-третьих… Множество может быть причин, включая психические расстройства различных спектров.
Нет, не шла. Ученику не требуется демонстрировать навык решения задач. Ему требуется демонстрировать наличие наличие навыков использования определенных методов.
> Слишком категорично, чтобы быть правдой. Во-первых, может быть недостаточно быть развит навык использования неполной индукции.
Это все замечательные рассуждения, но к реальности они отношения не имеют. В реальности в 99 случаях из ста все ученик прекрасно понимает, но не делает как дОлжно из-за лени и собственного ЧСВ.
Даже в сегодняшней школе вида 2018 года не бывает такого, что до учеников данная информация не доводится во вполне понятном и однозначном виде. Другое дело, если ученик — дятел, и упорно не захотел эту информацию воспринять. Даже после того, как ему нный раз снизили оценку, и объяснили, в чем дело, _лично_.
А с чего вы взяли, что не тренирует? Раз речь шла об оценке, то в нашем случае речь не о тренировке навыка (тренировка, очевидно, не может оцениваться), а о его проверке. Записав голый ответ, вы навык не продемонстрировали. Преподаватель ведь должен исходить из фактов, а не из вашего честного «ну я учил»? Вот он и исходит.
Есть задача — даю её ответ. Какая ещё демонстрация навыка решения задач нужна?
Какая разница, если почти всегда я даю верный результат в приемлемое время?
Основа проблемы что не можешь разобраться в собственном коде полгода спустяА мне вот что интересно. Я слышу про эту проблему постоянно, но на личном опыте её не наблюдал.
Она вообще — реально существует? Потому у меня возникали проблемы только с пониманием кода, в который полгода кто-то другой втыкал костыли, не пытаясь разобраться в том, что там происходит, но никогда — с пониманием моего собственно кода, написанного что полгода, что 10 лет назад.
То есть да, я вижу места, где я сделал «некрасиво» и сегодня, наверное, сделал бы «красивее», но понятнее… это же мой код — как он может быть непонятным?
Существует, особенно если напрямую работаешь с неформализованными требованиями бизнеса.Ok, будем знать.
А потом долгое время не используется и выветривается из памяти, пока, как минимум, не возникнет сильная ассоциация.Ну не весь же вы код так пишете!
То есть, да, могу допустить, что среди всего написанного мной кода найдутся несколько процентов, которые мне самому будет сложно понять. Но пока — такое не попадалось, так что особенно заморачиваться на эту мне кажется странным.
так что особенно заморачиваться на эту мне кажется странным.
Это вовсе не «странно». То, что понятно лично вам, как автору – далеко не факт, что будет с ходу понято всем остальным (кто, возможно, продолжит работу после вас).
Простейшие ведь «отраслевые правила», не, ну ёж же ж, ну хоть плачь вот на таких комментах… (((
Это вовсе не «странно». То, что понятно лично вам, как автору – далеко не факт, что будет с ходу понято всем остальным (кто, возможно, продолжит работу после вас).Более того — почти факт, что понятно не будет… и это — нормально.
Простейшие ведь «отраслевые правила», не, ну ёж же ж, ну хоть плачь вот на таких комментах… (((Плачьте. Потому что я не вижу смысла в этих правилах. Они призваны упростить работу бухгалтерии (дать ей возможность перекидывать разработчиков с проекта на проект, особо не задумываясь), а не мне.
При этом, открою вам маленький секрет, при «дёрганном» развитии проекта (когда разработку то ускоряют, то замораживают, людей постоянно «тасуют» и так далее) — совершенно неважно какого размера у вас в проекте функции — всё равно будет криво и ненадёжно.
Наоборот — при аккуратном подходе, когда проект разрабатывает слаженная команда, разработчиков которой не «перебрасывают» на затыкание различных дыр каждый месяц, результат будет вполне вменяем — опять-таки: независимо от средней длины функций.
почти факт, что понятно не будет… и это — нормально.
Это как раз НЕнормально. Хороший код должен быть понятен почти сразу – как минимум человеку, обладающему уровнем компетенции не меньше вашей. Если же в вашем коде порой трудно разобраться даже человеку с более высоким уровнем компетенции (а такое случалось, как это ни парадоксально, особенно на всяких «спи… стиснутых» участках) – тогда проблема именно в вашем коде.
Потому что я не вижу смысла в этих правилах. Они призваны упростить работу бухгалтерии (дать ей возможность перекидывать разработчиков с проекта на проект, особо не задумываясь), а не мне.
Ну вот, уже и банальный эгоизм проснулся. Скажите честно – вы просто таким образом пытаетесь сделать себя «незаменимым».
Но, глубочайше ИМХО – это просто махровейший непрофессионализм. Вы просто делайте работу как нужно. Без таких вот «мелочных подлян» коллегам – которые совершенно невиновны в том, что работу перекинули с вас на них. А вот разгребать это дерьмо потом именно им…
Если работаете действительно хорошо, вам и так ничто не грозит. А такие вот «грязные трюки» – это просто лютое малолетство какое-то, но никак не профессионализм. Вновь – трижды ИМХО…
Хороший код должен быть понятен почти сразу – как минимум человеку, обладающему уровнем компетенции не меньше вашей.Кому должен? Почему должен? Зачем должен?
У любого требования всегда есть некоторая цель. Так вот: ответьте зачем «хороший код» должен обладать этими качествами… и сразу станет ясно — они вам действительно нужны или это просто блажь, желание сделать красиво… за чужой счёт.
Скажите честно – вы просто таким образом пытаетесь сделать себя «незаменимым».Зачем же «незаменимым-то»? Покажите человека, который меня заменит — и я его с удовольствем научу меня заменить. Мне не жалко. А вот тратить время и силы на решение задачи, которой, по хорошему, не должно возникать в принципе — мне лень.
А такие вот «грязные трюки» – это просто лютое малолетство какое-то, но никак не профессионализм.Понимаете какая история. Всё на свете — имеет свою цену. И написание кода, который «понятен почти сразу» — особенно. И эта цена — примерно трёх-четырёхкратное замедление времени разработки. В некоторых случаях — это просто приводит к тому, что вы тратите втрое-вчетверо больше ресурсов. Но когда идёт «гонка на выживание» — это разница между «ох-каким-ужасно-кривым-Android'ом» (стоящим на 80% смартфонов) и «правильной архитектурой UWP» (которая, скорее всего, так и останется историческим курьёзом).
Вот и всё. Кого из разработчиков считать «профессионалами» — разработчиков Android или Windows Phone… вопрос сугубо философский…
Так вот: ответьте зачем «хороший код» должен обладать этими качествами…
С лёгкостью отвечу – ради того, чтобы в вашем коде мог разобраться разработчик, принявший ваш проект.
Это уже даже не просто «правила написания» – но и банальнейшая профессиональная этика (не к ночи будь упомянута)…
А вот тратить время и силы на решение задачи, которой, по хорошему, не должно возникать в принципе — мне лень.
Как программист – вы обязаны (!) по максимуму учитывать вообще совершенно все «типовые» ситуации, которые могут возникнуть в будущем, даже гипотетически.
Если же вы не можете учесть даже настолько бытовые-типовые вопросы как банальная передача проекта – то, миль пардон, тогда вы просто не программист, меняйте профессию…
И эта цена — примерно трёх-четырёхкратное замедление времени разработки.
Нет. Эта цена – N дней раздумий над реальной оптимизацией и прочими «компромиссами». Дней нерабочих, да. Но которые затем обернутся вполне рабочими для проекта в целом.
Но готовы ли вы за это платить трёх-четырёхкратным увеличением цены и, главное, аналогичным увеличением времени, потраченным на оную разработку?Так вот: ответьте зачем «хороший код» должен обладать этими качествами…С лёгкостью отвечу – ради того, чтобы в вашем коде мог разобраться разработчик, принявший ваш проект.
Ответ далеко не так однозначен, как вам кажется.
Эти красивые песни я слышал много раз. Возможно нам не повезло и «настоящих» профессионалов нам найти не удалось. Но… факты — вещь упрямая: то, что человек в виде прототипа для себя неделю преобразовалось в то, что можно залить в основную кодобазу, пройдя код-ревью пару месяцев (и нет, речь не идёт только про меня, это общая тенденция).И эта цена — примерно трёх-четырёхкратное замедление времени разработки.Нет. Эта цена – N дней раздумий над реальной оптимизацией и прочими «компромиссами». Дней нерабочих, да. Но которые затем обернутся вполне рабочими для проекта в целом.
Иногда — это было критично, иногда — нет. В нескольких случаях я знаю точно, что из-за этой «банальной профессиональной этики» код пришлось просто выкинуть, так как к моменту, когда он было готов он был просто никому не нужен.
Но готовы ли вы за это платить трёх-четырёхкратным увеличением цены и, главное, аналогичным увеличением времени, потраченным на оную разработку?
Во-первых, увеличение цены будет гораздо менее «кратным» (примерно прикидывая, сколько получает за это контора и сколько разработчик))…
Во-вторых – нехрен косить под «люкс», если это не так. Во всём мире есть конторы, которые работают реально под «люкс» (ну, или хотя бы максимально правдоподобно имитируют)). Но реальное бабло сшибают лишь те, кто реально же доказывает слово действием, ну хоть на чуточку. В «третьем эшелоне» пасутся те, кто, возможно, обладает какими-то реально знаниями, но тупо не в силах их реализовать (именно тупо, да). Простите, жестоко. Но правда.
код пришлось просто выкинуть, так как к моменту, когда он было готов он был просто никому не нужен.
А вот тут уже совместный косяк. Не только ваш, но и заказчика (даже в большей степени, наверное). Если вы действительно в теме – то должны прекрасно понять, о чём речь…
Во-первых, увеличение цены будет гораздо менее «кратным» (примерно прикидывая, сколько получает за это контора и сколько разработчик))…Совершенно неважно сколько получает контора. Разработчик получает, плюс-минус, стандартную ставку, так что если что-то вместо недели требует месяц — то это увеличение затрат в 4 раза.
А вот тут уже совместный косяк. Не только ваш, но и заказчика (даже в большей степени, наверное). Если вы действительно в теме – то должны прекрасно понять, о чём речь…Простите — но не понимаю. Видимо потому что на заказчика, в общем-то, никогда не работал. Работал в стартапах (где было важно выпустить продукт быстрее других стартапав), в больших компаниях (где разные отделы выпускали разные продукты и зачастую выигрывал не тот, кто лучше соблюдал «профессиональную этику», а тот, кто банально предлагал работающее решение раньше).
С заказчиками — не работал, из миров Сольски я сталкивался только с ширпотребом.
И эта цена — примерно трёх-четырёхкратное замедление времени разработки.
Я считаю, что тут Вы чересчур драматизируете. Чистый и правильный код появляется благодаря выработке относительно небольшого количества навыков. Чтобы их выработать, действительно требуется время. «Тяжело в ученье», как говорится. А потом хороший код будет писаться «на автомате», просто по привычке. Причём сразу же. Время, затрачиваемое на каждое «микро-улучшение» кода в процессе написания, может начинать приносить дивиденты сразу же. Так что общее время, затраченное на «чистый» код, может быть таким же, и даже меньшим.
Сравнение андроида и UWP, мне кажется, за рамками дискуссии. Мы же не архитектуры обсуждаем, а всего лишь код.
Чистый и правильный код появляется благодаря выработке относительно небольшого количества навыков.Нет, этого недостаточно.
А потом хороший код будет писаться «на автомате», просто по привычке. Причём сразу же.Если бы так. Я ещё не видел ни у кого красивого кода, написанного «на автомате», «по привычке». Как правило для того, чтобы привести код в состояние, когда его можно назвать красивым, требуется несколько итераций. Во всяком случае мне. Есть люди, которые на ревью отсылают код, который сразу не вызывает почти никаких нареканий — но вот беда, люди, его порождающие, не порождают его быстрее, чем я, со своими 3-5-10 итерациями. Так что они либо его пишут дольше, либо делают несколько итераций, которые никому не показывают.
И всё это занимает время.
Так что общее время, затраченное на «чистый» код, может быть таким же, и даже меньшим.Это песню я слышу регурярно, но… не вижу. Увы. Вижу обратное.
Сравнение андроида и UWP, мне кажется, за рамками дискуссии. Мы же не архитектуры обсуждаем, а всего лишь код.Мы технологии обсуждаем, а не, собственно, код.
Я шапочно знаком с людьми, которые писали Андроид и, надо сказать, местами он написан просто кошмарно — что даже они признают. Именно потому что при его написании не было всяких попыток написать всё «красиво» и правильно. Общий дизайн обсуждался, но в деталях — кто во что горазд.
UWP же — результат попыток всё сделать «правильно», «по фен-шую». Всё орефакторив и переделав столько раз, сколько будет нужно. Результат — в то время как Андроид завоёвывал рынок разработчики Windows Phone 7, потом 8, потом UWP… делали «красиво».
Результат, возможно, даже и красив, даже почти наверняка красив… вот только нафиг никому не нужен. Кстати разработчики всяких WebAssembly увязли в той же фигне: если бы они «наступили на горло собственной песне» и реализовали 7-8 лет назад кривую поделку, а потом бы её расширяли — сейчас бы внушительный процент приложений и на десктопе и на мобильниках работал бы в браузере. Но они решили всё сделать «как надо».
P.S. Впрочем сейчас сторонники WebAssembly получили-таки свой очередной шанс: после того, как Энди турнули (из-за его «неправильных» подходов) разработка Андроида стала вестись со скоростью улитки, так что, возможно, конкуренты смогут-таки их догнать… как несложно догадаться одна из причин — желание сделать всё «правильно»… Есть шанс, что в борьбе двух улиток выиграет Web…
Спасибо за статью.
Исходные положения в статье близки к моим собственным представлениям о предмете.
Пропускают промежуточные выкладки и записывают результат тогда, когда им не нужно думать, потому что знают .
Много кода пишут, когда не знают, но настойчивы.
Хороший программист может писать много кода, который может выглядеть неряшливым…
А вы видели что пишут математики или физики-теоретики на салфетках в ресторане?
Это потом хороший программист отрефакторит, до такой степени, чтоб даже сопливому "духу" показалось, что он тоже так может.
А физик запишет окончательное:
E=m*c^2
А физик запишет окончательное E=m*c^2А физик, знакомый с TeX, аккуратное:
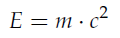
;)
:) Хотел.
Я дописывал формулу уже когда редактировал свое сообщение, после того, как случайно сабмитнул раньше времени. Не увидел значка формулы и не стал исследовать, возможно ли это в режиме редактирования.
Markdown при этом почему-то не кликнулся.
А режим редактирования Хабр включает на очень короткое время (на что я напоролся раньше), посему спешил.
Можно я здесь попробую? :)
$$display$$E=mc^2$$display$$
Ну вот же — не сработало… :(
Автор тем умнее, чем больше сложных задач он может решить.
Комфортный для человека способ достижения одной и той же цели может различаться для разных людей.
Одни летят самолетами, вторые плывут пароходами…
Длина/объем кода, сгенерированный в процессе разработки и потом убитый — одна вещь.
Неструктурированный, с кучей мусора код в продакшене — другое.
Учился в МРТИ, пропускал целые цепи интегральных вычислений (что было понятно только преподавателю, но не отличникам), в итоге — гуманитарий и филолог.
Что-то в вашей логике не так.
По пальцам могу пересчитать гуманитариев, ставших отпетыми технарями даже сейчас, когда технарем вроде как проще выжить.
Ваш случай только показывает, что множества, на которые мы лепим ярлыки «технарь», «гуманитарий», «длинная память», «короткая память» — это нечеткие множества.
//На самом деле изучение русского языка — главный и огромнейший вызов в моей жизни и я не уверен, что ее хватит на то, чтобы освоить его в должной мере//
"Специалист подобен флюсу" (с)
// BEGIN $RawMaskBlit(WriteByte1, WriteByte2, WriteByte3, WriteByte4)$. Do not change this line!
void ZXRawMaskBlitCopy(ZXBitmapRef bitmap, int x, int y,
ZXBitmapRef src, int srcX, int srcY, int srcWidth, int srcHeight, ZXData maskData)
{
/* dest and src */
ZXData pScan, pSrcScan, pMaskScan, pScanEnd;
ZXData p, pSrc, pMask;
unsigned char b, m;
int scan, srcScan;
/* offsets, flags, etc */
int offset, srcOffset, endPixels;
int fullBytes, endLine;
int compRealOffset, realOffset;
int isRegular;
/* calculate the sizes of scan lines */
scan = BitmapScanSize(bitmap);
srcScan = BitmapScanSize(src);
/* get pointers to a byte corresponding to a pixel */
pScan = BitmapPixelPtr(bitmap, x, y);
pSrcScan = BitmapPixelPtr(src, srcX, srcY);
pMaskScan = PixelPtrData(maskData, srcScan, srcX, srcY);
/* calculating end vertical line */
endLine = y + srcHeight;
/* bitmap offset */
offset = x % 8;
/* src offset */
srcOffset = srcX % 8;
/* get information about how much pixels should be shifted, */
/* important: when (offset < srcOffset) one byte is completely absorbed when outputting the left byte */
if(offset >= srcOffset)
realOffset = offset - srcOffset;
else
realOffset = 8 - (srcOffset - offset);
compRealOffset = 8 - realOffset;
/* count of full-size bytes */
fullBytes = CalcFullBytes(x, srcWidth);
/* offset end pixel */
endPixels = (x + srcWidth) % 8;
/* regular draw or not */
/* a) snap to right colum */
/* b) snap to left colum */
isRegular = (offset + srcWidth >= 8) || (offset == 0);
/* main loop y */
for(; y < endLine; y++) {
p = pScan;
pSrc = pSrcScan;
pMask = pMaskScan;
/* take care of left byte */
/* xxxxxxxx XXXXXXXX xxxxxxxx */
/* ^ we here */
if(offset != 0) {
if (offset >= srcOffset) {
b = *pSrc >> realOffset;
m = *pMask >> realOffset;
/* need next byte if we haven't real offset */
if(realOffset == 0) {
pSrc++;
pMask++;
}
}
else {
b = (*pSrc << compRealOffset) |
(*(pSrc + 1) >> realOffset);
m = (*pMask << compRealOffset) |
(*(pMask + 1) >> realOffset);
/* we completely used a byte, take a new */
pSrc++;
pMask++;
}
/* combine dest and src */
if(isRegular) {
b = (*p & rByte[offset]) | (b & lByte[offset]);/* $WriteByte1$ */
*p = (*p & ~m) | (b & m);
}
else {
b = (*p & ~(rByte[srcWidth] >> offset)) | (b & (rByte[srcWidth] >> offset));/* $WriteByte2$ */
*p = (*p & ~m) | (b & m);
}
p++;
}
/* main loop x */
/* xxxxxxxx XXXXXXXX xxxxxxxx */
/* ^ we here */
pScanEnd = p + fullBytes;
if(realOffset != 0) {
for(; p < pScanEnd; p++) {
b = (*pSrc << compRealOffset) |
(*(pSrc + 1) >> realOffset);
m = (*pMask << compRealOffset) |
(*(pMask + 1) >> realOffset);
/* combine dest and src */
b = b; /* $WriteByte3$ */
*p = (*p & (~m)) | (b & m);
pSrc++;
pMask++;
}
}
else {
for(; p < pScanEnd; p++) {
b = *pSrc;
m = *pMask;
/* combine dest and src */
b = b; /* $WriteByte3$ */
*p = (*p & (~m)) | (b & m);
pSrc++;
pMask++;
}
}
/* take care of right byte */
/* xxxxxxxx XXXXXXXX xxxxxxxx */
/* ^ we here */
if(isRegular && endPixels) {
if(realOffset != 0) {
b = *pSrc << compRealOffset;
m = *pMask << compRealOffset;
/* .. end pixel is double byte src */
if(endPixels > realOffset) {
b |= *(pSrc + 1) >> realOffset;
m |= *(pMask + 1) >> realOffset;
}
}
else {
b = *pSrc;
m = *pMask;
}
/* combine dest and src */
b = (*p & lByte[endPixels]) | (b & rByte[endPixels]); /* $WriteByte4$ */
*p = (*p & (~m)) | (b & m);
}
pScan += scan;
pSrcScan += srcScan;
pMaskScan += srcScan;
}
}
// END $RawMaskBlit$. Do not change this line!почему бы не использовать inline чтобы выделить какое то поддействие?
Если есть желание, можно переписать то же самое на C++ — будет компактнее.
А еще в «функциях»-макросах не создать локальных переменных(про C)
Вполне можно. Например,
#define mamarama(r,x,y) \
do { \
int z1, z2, z3; \
z1 = kumar1(x, y); \
z2 = kumar2(x, y, z1); \
z3 = kumar3(x, y, z2); \
r = z1 + z2 - z3; \
} while(0)здесь do{}while(0) — стандартный трюк для вложенного блока.
В GCC/Clang, кроме того, можно за счёт typeof делать такое без завязки на конкретные типы, а за счёт statement expressions — давать им выглядеть как функции с возвращаемыми значениями. Но и без этого уже есть возможность не пачкать внешнее пространство.
Определять переменные в начале любого блока до первого исполняемого оператора допускается и в C89, и ранее (от ANSI-85 и вплоть до исходного K&R, в той версии, как он попал в книгу), они будут существовать в пределах этого блока.
Вообще, это называется unconscious bias. В крупных компаниях один из первых тренингов о том, как не быть предвзятым к чему-либо. В данном случае «отличник», «троечник» — ненужные категории, они привели к холиварчику в комментариях, приведут и на работе. Пишите понятный код — вполне себе вывод без всяких предрассудков.
Следовать DRY, SOLID и какой-то осмысленной архитектуре сложнее на порядок, чем впихивать невпихуемое в один составной оператор. Именно поэтому длинные раздутые контроллеры пишет каждый второй вкатившийся в айти, а до проектирования нормальной архитектуры дорастают единицы.
Когда я вижу функцию из 300 строк, последнее о чем я могу подумать, так это о том, что этот код писал отличник.
Писать длинные функции легко и с хорошей памятью это никак не коррелирует. Это, несомненно, очень энергозатратный процесс, но не более.
Столько умных фраз для описания различия между опытным разработчиком специалистом и малоопытным...
Пример с математикой считаю не совсем корректным — в зависимости от постановки задачи требуется либо показать последовательность действий (требует записи по шагам), либо предоставить результат (требуется только конечный результат — так зачем заморачиваться?).
В программировании же все несколько иначе — код пишется для других программистов, которые будут читать или даже модифицировать решение через некоторое время. И скорей всего автор исходного кода не будет присутствовать при его чтении чтобы дать объяснения почему так а не иначе код был написан.
А уж работа компилятора — сделать из исходника оптимальный набор инструкций. Да, иногда приходится писать хитровыдуманные извращения с целью помочь компилятору сделать более оптимальный бинарник.
И вот понимание факта, что твое решение будут читать другие люди, не всегда оперирующие теми же понятиями и разбирающимися в специфике области и проекта, и отличает опытного специалиста от малоопытного. Комментарии, тесты и прочие изголения выглядят излишней тратой энергии и времени в глазах джуниора (сам таким был), но они-то и были придуманы затем, чтобы решение не требовало приложенного автора, который объяснял бы ход своих мыслей всем читающим.
Второе имя гениальности — краткость, первое — новизна.
Может умение держать в памяти много обьектов и дает какое то преимущество в программировании, но НЕ ключевое, меньшее кол-во багов при первом запуске и вроде того.
Имхо талантливого программиста отличает умение быстро находить оптимальное решение проблемы, стабильно, раз за разом. Некая способность к инсайту, способность видеть суть так как не могут видеть другие. Возможно это более мощная концетрация, чем у среднего человека, воображение, мотивация но точно не обьем оперативки, так как иногда допускают банальные ошибки которые любой джуник сразу заметит. Некое внутренее чутье которое помогает им смотреть почти всегда сразу в нужную сторону.
В детстве мне казалась скучной алгебра и я пребывал "на своей волне" на уроках, благодаря чему имел по ней "3". Во время контрольных я решал задачи исходя из моей логики не зная того как преподавали решение, мое решение не засчитывали так как ход его был не правильный но результат правильный. Вот от куда берутся "троечники" у которых потом бизнес и все в жизни отлично)).
Ученики послабее записывали решение по шагам и тратили существенно больше времени.
Нам, отличникам, всё это ни к чему. Зачем писать столько ненужных промежуточных действий, когда можно сразу готовый ответ? Мы же хотим поскорее разделаться с этим примером, чтобы перейти к следующему!
Гипотеза. Чем умнее программист (чем более объёмной рабочей памятью он располагает), тем более длинные методы и функции он пишет.
Какой-то странный для меня вывод.
Имхо как раз логичнее будет что троечник привыкнув расписывать все по шагам будет так же писать длинные методы. К тому же писать код в одном большом методе на много проще чем разбивать его на меньшие.
Троечнику сложнее думать абстрактно чем отличнику, а что бы писать короткие методы надо держать в голове код других методов вынесенных из текущего, а в идеале держать в голове весь код, что бы повторно использовать уже существующий код.
А портянки можно писать особо не запоминая даже что делалось на 10 строк выше.
Я проводил такую аналогию. Тот, кто привык решать задачу, записывая каждый маленький шаг, тот и машину будет программировать так, чтобы она продвигалась к решению маленькими шагами. А тот, кто привык получать сразу готовое решение «из головы», и машину запрограммирует так, чтобы она тоже выдавала готовый результат без фиксации промежуточных шагов.
Разумеется, такая индукция не может претендовать на полноту. Не всякий «отличник» будет писать исключительно готовые решения, и не всякий «троечник» будет придерживаться принципа единственной ответственности.
А тот, кто привык получать сразу готовое решение «из головы» (замечу, короткое решение!), и для машины сразу напишет готовое решение «из головы». И оно тоже будет короткое.
Самый главный вопрос, который не увидел в комментариях — откуда такие умозаключения?
Для подобных выводов необходимо изучить довольно большое количество людей, их код и корреляцию с их уровнем интеллекта.
Брайан Фитцпатрик и Бен Коллинз-Сассмэн в книге «Идеальная IT-компания» в первой же главе утверждают и доказывают, что любую идею нужно выносить на обсуждение. Иначе высока вероятность наделать ошибок в самом начале пути, когда их цена особенно высока. Кому интересно — пункт «Скрываться вредно».
Подтверждение гипотезы — вопрос времени и будущих усилий. Наблюдения, эксприменты, анализ кода, плотное изучение когнитивной теории, наконец.
Просто комментарии расставляешь и пишешь попроще, а если где-то применяешь изящную магию — сам себе оставляешь пометку «как это работает» (через несколько месяцев возвращаешься, читаешь, удивляешься и думаешь — да, черт возьми, красиво же).
Что для меня проблема — так это удержать в сознании несколько (>3 в среднем) уровней абстракции. Особенно если промежуточные слои не несут никакого практического смысла, а сделаны ради «красивого кода», «красивого оформления методов» итп.
Когда начинаются слои абстракции ради абстракции в стиле «я сделал еще один слой абстракции бикоз ай кэн» — это больно. Потому что приходится удерживать в памяти слой трансляций из одного представления в другое, при этом практического смысла эти трансляции не несут.
P.S. К примеру, разбираясь с библиотекой аутентификации Laravel/Sentinel, я чувстововал реальную боль.
Абстракции для того и создаются, чтобы не держать в голове уровни под ними. Другое дело, что бывает, что абстракции текут, или задачи ставят сразу на нескольких уровнях, типа "в столбце N отчёта "агрегированные показатели подразделения за отчётный период" должна быть сумма столбца К из таблицы T базы данных D отнесённая к средневзвешенной численности подразделения".
Нет, я понимаю необходимость абстрагирования. Но у этого должна быть цель, а не «вводим два слоя абстракции ради красивой реализации геттера и сеттера».
Если приходится удерживать именно иерархию, значит очень дырявые абстракции. Наверное, являются абстракциями синтаксически (класс, интерфейс), но ничего по факту не абстрагируют.
Надёжная доставка — это не доставка всегда и везде, это чёткое понимание доставили или нет.
На ревью мы не тратим время на борьбу мнений, — обычно проблему можно классифицировать по одному из известных каталогов Code Smells (обычно используем каталог Роберта Мартина), или же проблема основана на субъективном мнении и может быть проигнорирована.
Мы не указываем как и что исправить, — мы просто даем линку на нужный метод исправления по каталогу www.refactoring.com/catalog. Если разработчику требуется дополнительная информация — он просто смотрит номер страницы книги по ссылке (каждый метод рефакторинга имеет номер страницы), открывает книгу на нужной странице, и получает всю необходимую информацию.
В корпоративной культуре у нас 5 книг являются обязательными для прочтения каждым разработчиком:
- «Design Patterns: Elements of Reusable Object-Oriented Software» by Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides
- «Patterns of Enterprise Application Architecture» by Martin Fowler, David Rice, Matthew Foemmel, Edward Hieatt, Robert Mee, Randy Stafford
- «Refactoring: Improving the Design of Existing Code» by Martin Fowler, Kent Beck, John Brant, William Opdyke, Don Roberts
- «Clean Code: A Handbook of Agile Software Craftsmanship» by Robert C. Martin
- «Code Complete» by Steve McConnell
Кроме перечисленного, инструкторы и менеджеры должны освоить несколько книг Бека по XP. Это как минимум. На практике, для опытных разработчиков, список литературы намного шире.
Мне кажется, что размер метода в первую очередь связан не с уровнем знания предметной области (назову это так, терминология «отличник — троечник» сомнительна), а с особенностями мышления. Т.е. есть конкретные люди, которые при любой возможности пишут большие методы.
Да, борьбу за байты помню как сейчас. Был у меня тогда самодельный набор хакера. В zeus assembler написал утилитку, которая позволяла делать разнообразные дампы, а потом и дизассемблировать код. Утилитка «жила» в экранной памяти, в средней и нижней трети, чтобы остаток от 48К ОЗУ был свободен для подопытных программ. Когда писал дизассемблер, дозволенные 4 Кб закончились, и пришлось переписывать весь дизассемблер с нуля. Получилось, да ещё несколько сот байт дополнительно освободилось.
Много чего в той утилитке было: к полному дизассемблеру Z80 — дампы памяти в десятичном, шестнадцатеричном и символьном видах, в виде спрайтов, поиск байтов и слов, плавная попиксельная прокрутка рабочей области экрана, потом собственный загрузчик добавился и ещё что-то там — не помню.
Сам zeus я тоже дизассемблировал. Хотел стырить код для парсинга команд, и нашёл внутри команду «What is the meaning of life?», которая всегда выдавала какие-то «42» и ничего больше не делала. Тогда я ещё не читал Дугласа Адамса и не понял прикола.
В статье под отличниками понимаются отличники-математики?
Если при разработке ПО действовать как математики, то код действительно может получиться "непонятным".
Сократили дроби (убрали вывод формулы и получили итоговое решение) — точнее, сократили число слоев абстракций, а где то еще для "упрощения модели" сделали и протечку абстракций.
Но разработка это прежде всего технология, и уже потом — искусство и наука.
Сокращать и протекать абстракции тут нельзя.
Тут важна не готовая "формула", а прослеживаемость ее вывода и масштабируемость — получение новых "формул" путем небольшого подкручивания параметров в слоях абстракций.
Если же имеет место готовая "формула", то при изменении требований ее придется полностью переписывать, точнее, с нуля выводить новую формулу.
На примере:
Пусть у нас есть Web API, реализованное в виде MVC.
Если кому-то придет идея "а давайте упрощать модель — пусть к слою данных напрямую обращается контроллер, а то этот контроллер сейчас какой пустой", то в этот момент проект "приехал".
Точно так же, необходимость следить при визуальной верификации за тем, что результаты предыдущих этапов не портятся до их использования в результате коллизий имён, сильно усложняет визуальную верификацию. (Программную — не рассматриваю, в силу её редкости и дороговизны, но визуальную — вплоть до простого код-ревью — необходимо учитывать и способствовать ей.) Тут ещё и не было необходимости, как мне кажется, экономить на вызовах подфункций.
Как отличники, так и троечники могут обладать высокой внимательностью к деталям, а могут не замечать на ровном месте ошибки типа anspk вместо anpsk (пример реальный с точностью до букв — я с таким боролся в старом фортрановском коде). В крупных неразделённых блоках кода гарантированно следить за целостностью (через длительное развитие и изменение) могут только люди с определёнными классами отклонений (например, аутизм). Таких, увы, сложно найти, большая редкость — чтобы ещё и программировали; но если и найти — их невыгодно использовать из пушки по воробьям.
Допустим, программист уложил необходимую работу в 150 строк кода. Что улучшится от того, что он разобьёт этот код на пять функций по тридцать строк? Добавятся имена функций? Ну так можно вписать эти имена в виде комментариев в исходные 150 строк и не париться.
Т.е. задача сводится к подробному комментированию кода, и всё.
Ну, функции обладают полезной возможностью использования локальных переменных. Ну так и линейный код тоже может использовать локальные переменные внутри фигурных скобок.
И ещё:
Похоже, автор полагает, что код надо написать так, чтобы его мог прочесть и понять слабый программист. Причём с малым расходом сил.
Хм-м-м… А может, надо поднимать планку и не пускать в профессию слабых программистов?
Допустим, программист уложил необходимую работу в 150 строк кода. Что улучшится от того, что он разобьёт этот код на пять функций по тридцать строк?
Пусть первая часть функции считает, чему равны foo и buka. Вторая — чему равны bar и zuka. Третья использует foo и bar, четвёртая — buka и zuka. Пятая (вы говорили про пять) их как-то обобщает, заодно логгируя.
Чтобы грок (на всякий случай — осознать во всех деталях) всю 150-строчную функцию, читатель должен, в частности, убедиться, что вторая часть не меняет значения foo и buka, а третья — buka и zuka. А то мало ли, что происходит на 4-м уровне вложенности цикла в этих частях и под каким хитрым условием? Защиты ведь от этого нет, нельзя временно навесить const на переменную, а потом его снять. А в случае раздельных функций это выполняется примитивно и прямолинейно — foo и buka просто принимаются как результат 1-й подфункции (неважно, как часть возвращаемого значения, по указателю, по ссылке, как-то ещё) и не передаются во 2-ю, а в 3-ю и 4-ю передаются только по значению (копируются).
Вы можете сказать, что можно их назначить const и они будут таковыми до конца жизни функции. Да, но не в Ruby (в нём нет таких констант), и не в чуть-чуть более сложном случае (пусть эти 5 частей выполняются ещё раз в цикле… не принять изменение из отдельной функции — банально, не разрешить менять — уже серьёзные затраты на изучение каждый раз).
Это был первый аспект. Второй — обеспечение доверия к качеству реализации через тестирование. Про тестирование я уже высказался, повторю чуть иными словами: функция в таком виде слишком неудобна для автоматического тестирования. Нет возможности получить промежуточные результаты, неудобно подавать разные входные данные и контролировать результаты каждого этапа. Для динамически типизированного языка такое тестирование критично; большинство возможных проблем, типа опечаток в именовании полей мап, могло бы быть выловлено в языке типа C++ на стадии компиляции, здесь же этого нет и вся надежда на тесты.
Ну так и линейный код тоже может использовать локальные переменные внутри фигурных скобок.
Но там нет возможности запретить видимость переменных внешнего блока. Ни в одном языке программирования, насколько я видел, такого нет; такой запрет делается уже структурированием на функции/процедуры/назови-как-хочешь. И тем более этого нет в Ruby.
Вы можете вспомнить про лямбды в C++, но они фактически отдельные вложенные функции.
Хм-м-м… А может, надо поднимать планку и не пускать в профессию слабых программистов?
Невыгодно. Если требовать от программистов абсолютно высокого внимания ко всем деталям, то придётся выкинуть 99% тех, кто сейчас успешно работает. Повторюсь — в отрасли останутся аутисты и безумные гениальные счётчики в уме. Вы тоже будете выкинуты на мороз, аутисты не пишут такие комментарии на хабр :)
нельзя временно навесить const на переменную, а потом его снятьВы что-то не сообразили:
В каждой части я могу объявить локальными переменные, которые в ней вообще не используются. Это значит, что даже если внутри этой части что-то делается с этими переменными — наружу последствия этих действий не вылезут.
Это я чисто на тему «можно или нельзя» — но не на тему «надо или не надо так делать».
А в случае раздельных функций это выполняется примитивно и прямолинейно — foo и buka просто принимаются как результат 1-й подфункции (неважно, как часть возвращаемого значения, по указателю, по ссылке, как-то ещё) и не передаются во 2-ю, а в 3-ю и 4-ю передаются только по значению (копируются).А вот это уже серьёзный аргумент.
Второй — обеспечение доверия к качеству реализации через тестирование.Тоже хороший аргумент.
Но там нет возможности запретить видимость переменных внешнего блока.Гы! В классическом Pascal даже выделение кода в функцию не спасает от возможности поменять глобальную переменную.
Если требовать от программистов абсолютно высокого внимания ко всем деталям, то придётся выкинуть 99% тех, кто сейчас успешно работает.А может, станут меняться программисты и система образования?
В каждой части я могу объявить локальными переменные, которые в ней вообще не используются. Это значит, что даже если внутри этой части что-то делается с этими переменными — наружу последствия этих действий не вылезут.
Вы имеете в виду вариант: чтобы не менять внешнюю foo, мы объявляем свою foo, но не используем её?
Если нет, то какое это имеет отношение к тому, как защититься от изменения этой переменной кодом, которому не положено это делать?
Если да… ну, возможно, в качестве очень грязного и очень странного трюка это можно рассмотреть. Но тогда надо подавить все варнинги на тему затенения и неиспользования переменных… вред от этого подавления может быть даже больше.
Гы! В классическом Pascal даже выделение кода в функцию не спасает от возможности поменять глобальную переменную.
Для глобальной — так это точно так же и в C, C++. Это один из недостатков глобальности.
Но в классическом Pascal можно делать у процедуры несколько блоков var, и если вложенная процедура объявлена после первого, но до второго, она не увидит переменные охватывающей процедуры из второго var. Этим можно активно пользоваться. (Вместо процедуры Pascal тут везде могут быть и функции.)
Для C аналога такой вложенности не существует, если не смотреть на расширения GCC; для C++ это лямбды с явным заданием используемых переменных.
А может, станут меняться программисты и система образования?
На какую? 90% будет занимать дрессировка внимательности к тончайшим мелочам и точного воспроизведения одних и тех же действий? Самим превращаться в компьютеры?
Я понимаю делать такое там, где людям самим интересна точность и воспроизводимость результата (например, в живой музыке). Но при анализе кода… не буду возражать, но выражу очень плотные сомнения. Если пока что движение в основном было в противоположном направлении — завлечь разнообразием и качеством средств и подходов тех, кто не был готов писать на предыдущих поколениях (например, не хотел мучаться с управлением памятью в unmanaged средах) — наверно, к этому есть не только рыночные причины.
Вы имеете в виду вариант: чтобы не менять внешнюю foo, мы объявляем свою foo, но не используем её?Да. Это очень грязный хак — просто чтобы показать, что так можно.
Но тогда надо подавить все варнинги на тему затенения и неиспользования переменных…Добавить комментарий про варнинги.
Кстати, я не знаю, можно ли в препроцессоре написать «при компиляции выдать сообщение про то, что варнинги тут будут, но это так и надо».
Для глобальной — так это точно так же и в C, C++.В Си для доступа к глобальной переменнной — её надо объявить глобальной в каждом модуле (процедуре, функции — хотя в Си это одно и то же) как глобальную.
В Fortran были именованные «глобальные блоки», и модуль мог импортировать определённый блок. Импортируемые блоки надо было перечислять поимённо.
На какую? 90% будет занимать дрессировка внимательности к тончайшим мелочам и точного воспроизведения одних и тех же действий?Нет. Надо давать широкое фундаментальное образование.
Например, я не учился на программиста специально, да и не работал программистом — это было скорее хобби. Обучался я по книгам, и очень долго не мог найти внятное объяснение тому, что такое «транзакции/мьютексы», и зачем они вообще нужны.
Поэтому, когда я читал студентам курс «Сети и архитектуры ЭВМ» — я чётко обозначил, что курс обзорный, и не даёт возможности работать ни по какой из охватываемых тем. Более того: я не столько даю ответы (знания), сколько объясняю вопросы (рассказываю, откуда вообще берётся проблема, и почему её нельзя решать проще).
Менять систему образования надо примерно в такую сторону:
* Уменьшить количество профессиональных преподавателей (которые зависли в глубоком прошлом) в пользу работающих по совместительству и имеющих практический опыт работы.
* Уменьшить количество обязательных предметов в пользу элективных. Заодно быстро отсеются негодные преподаватели, не умеющие преподавать интересно.
* Уменьшить количество гуманитарной фигни типа философии. Ну или хотя бы вынести её на элективную систему — чтобы тупые гуманитарии не могли сношать мозги беззащитным студентам.
* Усилить интеграцию образования с производством, т.е. интеграцию ВУЗа с потенциальными работодателями. В частности — дать работодателям возможность определять набор предметов и критерии оценки знаний.
* Сделать обязательной систему производственной практики — как в МФТИ, где студент примерно с третьего курса начинает работать в НИИ.
* Начинать образование как можно раньше. Т.е. школа д.б. лет пять или семь, дальше — обязательный колледж со специализацией.
В целом согласен, но:
Сделать обязательной систему производственной практики — как в МФТИ, где студент примерно с третьего курса начинает работать в НИИ.
Практику лесом. Получится узаконенное рабство.
Начинать образование как можно раньше. Т.е. школа д.б. лет пять или семь, дальше — обязательный колледж со специализацией.
Большинство людей и в 20-25 лет ещё не могут определиться со специализацией, а вы предлагаете 12-14-летним детям решать вопросы о будущем.
В 14 лет уже примерно ясно, физик это или лирик; абстрактно рассуждает или работает руками. Так что специализация д.б. не точная, а приблизительная — и это намного лучше, чем пичкать учеников знаниями, коорые вообще не усваиваются.
Практику лесом. Получится узаконенное рабство.Почему рабство? Отработка кредита. Государство на вас денежку тратило — так отработайте на него 2-3-5 лет.
Не хотите? Платите за обучение и делайте что хотите.
Но ситуация, когда налоги собирают со всех жителей страны, а обучаются избранные, да ещё, после этого, зачастую уезжают из страны, не проработав в ней ни года — в корне неправильна.
Либо платное обучение, либо отработка.
Есть страны, типа Германии, которые пытаются к себе завлечь иностранцев бесплатным обучением на «национальном языке». Но у России как-то не очень выходит: обучаться — обучаются, а работать всё больше на Запад стараются уехать.
Почему рабство? Отработка кредита. Государство на вас денежку тратило — так отработайте на него 2-3-5 лет.
Добро пожаловать в Советский Союз! Метод кнута в современном мире работает плохо.
Большое количество квалифицированных специалистов положительно влияет на экономику. Специалист окупает себя, платя больше налогов с более высокой зарплаты. Будет платное образование — будут меньше учиться, будет плохо всей экономике.
Не хотите? Платите за обучение и делайте что хотите.
Представьте себе, многие государства обучают даже иностранцев бесплатно. Эти иностранцы потом уезжают и никому ничего не должны. И все равно обучение в этом случае получается выгодным.
Добро пожаловать в Советский Союз! Метод кнута в современном мире работает плохо.Серьёзно? Что там применяют в самой большой экономике мира — не подскажите?
Большое количество квалифицированных специалистов положительно влияет на экономику.Согласен.
Специалист окупает себя, платя больше налогов с более высокой зарплаты.Только не в том случае, когда учился он в одной стране, а работает в другой.
Представьте себе, многие государства обучают даже иностранцев бесплатно. Эти иностранцы потом уезжают и никому ничего не должны. И все равно обучение в этом случае получается выгодным.За счёт чего? За счёт того, что часть всё-таки остаётся — так ведь? Как с этим у России?
Вот когда отучившиеся не будут массово уезжать — можно и бесплатное обучение устраивать. Всему своё время и не бывает рецептов, одинаково хорошо работающих везде. Потому и законы всё время меняются, однако.
А кто тут заикался о США? Самая большая экономика мира — это, вы уж извините — Китай. И там — обучение устроено ровно так, как я сказал: обучение платно, но если едешь «куда партия сказала» — кредит за тебя покрывает государство. А если хочешь за границу… выплати кредит — и езжай спокойно!Серьёзно? Что там применяют в самой большой экономике мира — не подскажите?Не слышал про отработки в США.
Можно ещё, кстати, подискутировать, что выгоднее для экономики и государства — отработка на предприятии по неразрывному контракту этак спустя рукава, или работа за рыночную зарплату с рыночной конкуренцией и прочими рыночными условиями.Да легко! Возьмите, опять-таки, две крупнейшие экономики, обратите внимание какая из них была крупнейшей лет 20 назад, а какая — сегодня.
А вы как считаете?Это не я считаю, а Bloomberg.
Интересно только, чего китайцы потом едут во всякие Штаты, а не наоборот.И эти сведения — тоже устарели.
Один из немногих показателей, по которым США пока что безусловно опережают другие страны — это количество и качество войск. Но их уже не хватает для того, чтобы «доставить демократию из бомболюка» во все страны, которые не хотят платить за хорошую жизнь жителей США… а ведь в последние лет 10 — только за счёт этого и удавалось поддерживать иллюзии о том, что у США — самая большая экономика, самые эффективные рабочие и прочее.
А можете объяснить, каким именно образом и в чем эти все страны платят за хорошую жизнь США? Это получается, что были какие-то блага в стране Х, и эта страна оп! И отдала эти блага США. Можете описать такие ситуации?
А можете объяснить, каким именно образом и в чем эти все страны платят за хорошую жизнь США?Всё тот же Китай, например. Если Китай отправил в США товара на 100 миллиардов, а взамен получил только долговые расписки — то как раз и получается, что «эта страна оп! И отдала эти блага США».
Но Ланнистеры всегда платят свои долги. Единственная причина, по которой США дают в долг — это тот факт, что США самый надежный заемщик в мире и исправно обслуживают все свои долговые расписки. Так что никакой отдачи благ нет, все эти расписки конвертируются в деньги, а те — в свою очередь, в блага. Или же расписки могут быть проданы напрямую.
Оставлю просто как альтернативное мнение.
Ошибся уровнем, ответ на habrahabr.ru/post/349336/#comment_10682332
Или потому что они уже(или пока еще) Too Big To Fail.И «уже» и «пока ещё». Когда долларовая пирамида рухнет (рухнет ли при этом США — неизвестно, может быть, что и нет), то накроется вся существующая система мировой торговли.
Долгое время попытки выстроить алтернативу приводили к тому, что у тех, кто пытался это сделать обнарживали острый недостаток демократии и зашкаливающее количество нарушений прав человека, но… после того, как «Акела промахнулся» в Сирии (почти все чиновники, заявлявшие «Ассад должен уйти» уже ушли… а Ассад — ещё нет) процесс сдвинулся с мёртвой точки и, наконец, Китай решился. АБИИ и выключение доллара (а значит и тережерис) из процесса торговли нефтью — это фактически работа над тем, чтобы США не были Too Big To Fail.
Устроить панику на биржах и коллапс экономики США Китай мог уже лет 10 как — но проблема была в том, что при этом сколлапсировала бы и экономика самого Китая тоже. Вот над этим сейчас и ведётся работа…
Оставлю просто как альтернативное мнение.
Извините, но пока это только гипотеза. При том ничем не подкрепленная. На данный момент нету никаких предпосылок к тому, чтобы что-то случилось с долларом и США. Более того — если что-то и случится, правительство США уже доказало, что может в кратчайшие сроки с минимальными потерями выходить из крупнейших кризисов.
Качество заемщика определяется не только тем, как он в прошлом обслуживал свои долги, но и будущими рисками. На данный момент, вложения в госдолг США — общепризнанно самое низкорисковое вложение из в принципе существующих вариантов. Госдолг сша на данный момент крепче золота, недвижимости, любых материальных и не материальных активов.
На данный момент, вложения в госдолг США — общепризнанно самое низкорисковое вложение из в принципе существующих вариантов. Госдолг сша на данный момент крепче золота, недвижимости, любых материальных и не материальных активов.Серьёзно? Рейтинг BBB- — это у нас уже «крепче золота»? Или если агенство контролируется не должником, а кредитором — то к нему уже меньше доверия? Обычно считается наоборот, как бы.
На данный момент нету никаких предпосылок к тому, чтобы что-то случилось с долларом и США.Серьёзно? Когда в прошлый раз кредитором было заявлено: кому должен — всем прощаю они это проглотили. Так как деваться было некуда. Но почему у вас такая уверенность, что то же самое случится и в этот раз?
Более того — если что-то и случится, правительство США уже доказало, что может в кратчайшие сроки с минимальными потерями выходить из крупнейших кризисов.А уж сколько столетий Рим выходил из всех кризисов! Аж до IIIго века. А Англия — до XIVго. Всё когда-то случается первый раз.
Очень забавляет, когда люди не читают свои же линки. Не BBB-, а топовые ААА/АА+:
> International ratings agencies Fitch and Moody’s Investors Service both give the United States their top AAA ratings. S&P Global has put the U.S. on a slightly lower grade of AA+ since 2011.
> Серьёзно? Когда в прошлый раз кредитором было заявлено: кому должен — всем прощаю они это проглотили.
Кто кому и что простил, уточните? По вашему линку ничего такого нет.
> А уж сколько столетий Рим выходил из всех кризисов! Аж до IIIго века. А Англия — до XIVго. Всё когда-то случается первый раз.
Конечно же, случается. Просто с США случится последними, в самом маловероятном сценарии (никто не говорит, что вероятность равна нулю).
> Серьёзно? Рейтинг BBB- — это у нас уже «крепче золота»?Ещё больше забавляет, когда люди не читают заголовков, которые не поддерживают их точку зрения. Я специально ошибся — мне было интересно: придерётесь вы к тому, что я написал BBB-, а не BBB+ или просто проигнорируете мнение не-американцев. Вы выбрали второе. Притом что даже из заголовока статьи — видно, что речь-то не про них.
Очень забавляет, когда люди не читают свои же линки. Не BBB-, а топовые ААА/АА+:
> International ratings agencies Fitch and Moody’s Investors Service both give the United States their top AAA ratings. S&P Global has put the U.S. on a slightly lower grade of AA+ since 2011.
Скажите, вы, когда кредит берёте в банке, тоже убеждаете его принять во-внимание мнение своего племянника, сестры и близкого друга? Или банк, в первую очередь, выслушает мнение своего кредитного комитета?
Fitch Ratings, Moody’s и S&P — это американские компании, краха доллоравой пирамиды они, скорее всего, не переживут, зачем им говорить о ней правду? Напомнить вам, что ваш любимый Fitch давал Lehman Brothers оценку A+ за два месяца до того, как Lehman Brothers обанкротились?
Статья же в целом говорит о том, что Китайцы (а они, вообще-то, как раз и являются крупнейшими кредиторами США) оценивают американские облигации уже на BBB+ — а это далеко не «самое низкорисковое вложение из в принципе существующих вариантов», извините.
> Серьёзно? Когда в прошлый раз кредитором было заявлено: кому должен — всем прощаю они это проглотили.Ну если вы вашу собственную историю так плохо знаете… Вначале французов послали с их мешком долларов, потом и всех остальных. Вообще-то — это полновесный дефолт, такой же, как и у Барди.
Кто кому и что простил, уточните? По вашему линку ничего такого нет.
> А уж сколько столетий Рим выходил из всех кризисов! Аж до IIIго века. А Англия — до XIVго. Всё когда-то случается первый раз.Сценарий, во-первых, не маловероятный, а, фактически, неизбежный. Вопрос только «когда». Барди продержались 6 лет, а у них ни армии, ни флота, ни ядерной бомбы не было. И варианта «напечатать хрениллион „фантиков“ у них тоже не было» (тогда кредиты в золоте брались).
Конечно же, случается. Просто с США случится последними, в самом маловероятном сценарии (никто не говорит, что вероятность равна нулю).
Странно, что все кругом, и внутри и снаружи Америки, об этом говорят — а вы всё то же самое талдычите.
Конечно, нет, но это то же самое, что выслушивать мнение племянника должника.
Ангажированные американцы, которым выгодно ставить высокий рейтинг, ставят высокий рейтинг. Ангажированные китайцы, которым выгодно ставить низкий рейтинг, ставят низкий рейтинг.
Вы, вроде, продемонстрировали сейчас, что сами понимаете эту нехитрую истину. Тогда зачем вы приводили этот «пруф», который, сами же понимаете, ни с какой стороны не пруф? Потроллить?
> Ну если вы вашу собственную историю так плохо знаете… Вначале французов послали с их мешком долларов, потом и всех остальных.
Я еще раз задам вопросы: кто, кому и что простил? Назовите эти Х, Y и Z. По вашей ссылке никаких «прощений» кого-либо кому-либо чего-либо не было.
> Сценарий, во-первых, не маловероятный, а, фактически, неизбежный.
А еще мы все рано или поздно умрем. Совершенно бесполезное утверждение.
Но Ланнистеры всегда платят свои долги.До тех пор, пока не решат, что больше они этого делать не хотят. Барди тоже по своим долгам платили… до поры до времени.
Единственная причина, по которой США дают в долг — это тот факт, что США самый надежный заемщик в мире и исправно обслуживают все свои долговые расписки.А тот факт, что как только кто-то что есть долгодатели и понадёжнее получают полный заряд демократии из бомболюков — это таки случайность? Неважно — любите вы Евро
или золото, если вы вдруг решите, что США не самый надёжный заёмщик — вы будете демократизированы по полной.
Так что никакой отдачи благ нет, все эти расписки конвертируются в деньги, а те — в свою очередь, в блага.С этого моментьа поподронее. В 2017м году США отдали Китаю бумажек на 100 миллиардов и получило взамен товаров на эти же 100 миллиардов. Что произшло после этого, и что именно Китай получил взамен?
Или же расписки могут быть проданы напрямую.Кому? Если даже от слухов о том, что Китай начнёт покупать меньше бумажек биржи начинает лихорадить и Китайю приходится говорить нет-нет, нас неправильно поняли?
А как они могут не захотеть? Это ведь такой синоним массового самоубийства.
> А тот факт, что как только кто-то что есть долгодатели и понадёжнее получают полный заряд демократии из бомболюков — это таки случайность?
Что за надежные долгодатели? Кто и какой заряд из бомболюков получал?
> Кому?
Да кому угодно. Спрос на столь надежный инвестиционный инструмент есть всегда.
> > С этого моментьа поподронее. В 2017м году США отдали Китаю бумажек на 100 миллиардов и получило взамен товаров на эти же 100 миллиардов. Что произшло после этого, и что именно Китай получил взамен?
Китай получил доллары по этим долговым распискам и купил товар на эти деньги. Что тут непонятного?
> До тех пор, пока не решат, что больше они этого делать не хотят.Да ладно вам. Сколько правительств уже обьявляли дефолт — в том числе недавно. Всё что происходит в краткосрочной перспективе — им перестают давать товары в обмен на бумажки. Какое ж это самоубийство?
А как они могут не захотеть? Это ведь такой синоним массового самоубийства.
> > С этого моментьа поподронее. В 2017м году США отдали Китаю бумажек на 100 миллиардов и получило взамен товаров на эти же 100 миллиардов. Что произшло после этого, и что именно Китай получил взамен?Если бы произошло так, как вы говорите, то их бы на балансе — не было. А они — есть. Можно было бы предположить, что вместо того, чтобы трежерис просто обменять на доллары эти доллары был взяты в долг… но нет: было закуплено 126 миллиардов трежерис, а долг увеличился меньше, чем на 40 миллиардов. Я потому и спрашиваю о конкретном механизме препращение трежерис в товары, что его, как бы, не очень-то наблюдается.
Китай получил доллары по этим долговым распискам и купил товар на эти деньги. Что тут непонятного?
Что за надежные долгодатели? Кто и какой заряд из бомболюков получал?Там ссылочки, в общем-то были. До того, как Китай попробовал отказаться от американской «крыши» по этой же «запретной тропе» прошлись Иран, Ирак, Ливия и Сирия. И в них всех — оказывались через некоторое время после этого американские войска. Когда с разрешения ООН, а когда и без. В последнем случае, впрочем, и другой серьёзный повод.
> Кому?Ну уж нет. «Кому угодно» — это не ответ. В мире, в общем, не так много стран и/или огранизаций, способных вдруг вложить вдвое больше, чем они вкладывали ранее.
Да кому угодно. Спрос на столь надежный инвестиционный инструмент есть всегда.
Для США — конечно самоубийство. Это государство просто на следующий же день с лица земного шара в этом случае исчезнет.
> Там ссылочки, в общем-то были.
Я думал, это шутка. Вы реально рассматриваете Саддама и Каддафи в качестве хоть сколько-нибудь «надежных долгодателей»???? Давайте еще Ким Чен Ыну в долг надаем, он-то точно отдаст!
> Ну уж нет. «Кому угодно» — это не ответ. В мире, в общем, не так много стран и/или огранизаций, способных вдруг вложить вдвое больше, чем они вкладывали ранее.
Конечно, немного. Но это уже проблема Китая, что ему некому продавать свои товары, по-этому _приходится_ продавать за долги. Вы полагаете, если бы эти товары остались на китайских складах — кто-то бы там выиграл?
> Всё что происходит в краткосрочной перспективе — им перестают давать товары в обмен на бумажки. Какое ж это самоубийство?Да ладно вам. Не они первые, не они последние. Ну да, какое-то количество бездельников на велфере без денег останутся, кто-то обанкротится, кто-то без работы останется. Но не они первые, не они последние.
Для США — конечно самоубийство. Это государство просто на следующий же день с лица земного шара в этом случае исчезнет.
Развал США в результате возможне, но «на следующий день» это точно не случится.
Вы реально рассматриваете Саддама и Каддафи в качестве хоть сколько-нибудь «надежных долгодателей»???? Давайте еще Ким Чен Ыну в долг надаем, он-то точно отдаст!Вообще-то ни тому, ни другому, кредиты были не нужны. Ливия вообще была одной из богатейших стран на континенте. Но они совершили «кощунство»: предложили отказаться от торговли нефтью за доллары… а ведь только торговля товарами за доллары в рамках всего мира и позволяет США не особенно заботится о том, кто будет покупать их бумажки! Ирак и Ливию быстренько «демократизировали», а вот Сирию — уже не смогли… после чего страны, наконец, смогли начать строить альтернативу.
Но это уже проблема Китая, что ему некому продавать свои товары, по-этому _приходится_ продавать за долги. Вы полагаете, если бы эти товары остались на китайских складах — кто-то бы там выиграл?Америка бы точно проиграла. А в долгосрочной перспективе — да, Китай бы выиграл. Вы тут поёте ту же песню, что и абразийцы.
Собственно про это я уже говорил: Китай уже давно мог бы «убить дракона», но не факт, что уцелел бы при этом сам… но он работает над этим: Начали с Азиатского банка (ага — очень азиатский с Великобританией, Францией и Бразилией в списке членов), потом — нефть за юани (вернее, на самом деле, за золото), дальше будут постепенно отходить от «драконьей экономки» всё дальше и дальше.
А как к своему «переходу на самообеспечение» готовится «дракон»? Пока незаметно, чтобы вообще какая-либо подготовка шла. Кроме песен на тему «если должник сказал, что он надёжный заёмщик — то так оно и есть, мнение кредитора можно не учитывать»… ничего и нету…
Тогда в чем смысл примера? Вы следите, пожалуйста, за ходом разговора.
> а ведь только торговля товарами за доллары в рамках всего мира и позволяет США не особенно заботится о том, кто будет покупать их бумажки!
Нефть/газ составляют около 5% всего ввп, и это нефть/газ в целом. Так что у вас дебет с кредитом не сходится.
> Америка бы точно проиграла. А в долгосрочной перспективе — да, Китай бы выиграл.
Америке было бы без разницы — вместо Китая устроили бы экономическое чудо где-нибудь в Индии. А Китай так и болтался бы в хвосте развитых стран вместо того, чтобы стать первой экономикой мира.
Нефть/газ составляют около 5% всего ввп, и это нефть/газ в целом. Так что у вас дебет с кредитом не сходится.Вы тут рассуждаете как бухгалтер — что глупо. Подобный подход в политике ничего хорошего не даёт. Пока основные, жизненно важные, товары торгуются с иcпользованием доллара, а платежи проходят через американские банки — разрушать долларовую систему мировой торговли никому не выгодно.
Просто потому, что как только поставки нефти в Китай или в Европу прекратятся — им будет уже не до экономической войны, ему будет нужно думать о том, как выжить. И вот пока это так — Америка может спокойно печатать свои бумажки и на них всегда найдётся покупатель.
Та же самая история, что и человеком: в «обычной жизни» вы можете тратить на хлеб 5% или 1%, но если вдруг случится серьёзная катастрофа и еды просто не будет — вы будете готовы отдать всё, что у вас есть, чтобы с голоду не подохнуть!
А вот если удастся наладить торговлю нефтью и сельхозпродуктами, не включающую в себя США… вот тогда-то и наступит пора «убить дракона».
Америке было бы без разницы — вместо Китая устроили бы экономическое чудо где-нибудь в Индии. А Китай так и болтался бы в хвосте развитых стран вместо того, чтобы стать первой экономикой мира.Совершенно верно. Если бы Америка думало о том, что ей придётся воевать (вначале экономически, а потом, может быть, и «по-настоящему») с той страной, в которую она вывезла производство — то она бы этого не сделала. Но она купилась на те самые размышления о процентах и потому сейчас уже с неизбежностью движется к банкротству.
Дело в том, что мир — изменился. Если в прошлом века главное было «ноу-хау» и было, в общем-то, не так важно, кто владеет «сырыми» материалами, то в этом веке — важно у кого сырьё и фабрики… а «ноу-хау»… «ноу-хау» можно купить.
Да и остался ли тот «ноу-хау» в принципе? Возьмите любимицу публики — Теслу. Она всё ещё выпускает свои электрокары на Литий-Кадмиевых батареях в то время, как китайский BYD (кстати, мировой лидер в производстве электромобилей) уже переходит на LiFePo — которые хуже по многим показателям, но превосходят в главном: доступности исходных материалов.
Так вот в XX веке поведение Теслы — можно было бы понять, а в XXI… ну посмотрим, может через год-два ей Тесле ещё кредитов удастся взять, чтобы в авральном порядке на LiFePo перейти.
Конечно, это так. Но при чем тут нефть? У вас в голове все смешалось.
> Просто потому, что как только поставки нефти в Китай или в Европу прекратятся
Еще раз, нефть — это всего лишь 5% мирового ввп. Вся нефть.
> Но она купилась на те самые размышления о процентах и потому сейчас уже с неизбежностью движется к банкротству.
Америка уже не одно десятилетие движется к банкротству а доллар — загнивает. Но что-то живее всех живых.
> Дело в том, что мир — изменился. Если в прошлом века главное было «ноу-хау» и было, в общем-то, не так важно, кто владеет «сырыми» материалами, то в этом веке — важно у кого сырьё и фабрики…
Вот именно, что мир изменился. Сырье и производственные мощности сейчас не влияют ни на что. Мы живем в 21 веке, а не в 19-20, и единственный значимый ресурс 21 века — это человеческий капитал. Рынок услуг стремительно растет и долгосрочно выигрывает тот, кто инвестирует в людей. А нефть — это всего лишь ядовитая черная жижа, которая сама по себе (в отличии от человеческого труда) никому не нужна.
> Так вот в XX веке поведение Теслы — можно было бы понять, а в XXI… ну посмотрим, может через год-два ей Тесле ещё кредитов удастся взять
Тесла на данный момент — вполне прибыльное предприятие. Просто вся прибыль тратится на НИОКРы.
Еще раз, нефть — это всего лишь 5% мирового ввп. Вся нефть.Вы в баки самолётов что будете заливать? Проценты ввп? Или всё-таки керосин? А трактора у вас на чём ездят? А танки?
Если бы речь шла только о процентах ВВП, то США вряд ли бы озаботились созданием стратегического резерва.
Не пытайтесь предстать глупее, чем вы есть, пожалуйста.
> Пока основные, жизненно важные, товары торгуются с иcпользованием доллара, а платежи проходят через американские банки — разрушать долларовую систему мировой торговли никому не выгодно.Это у вас в голове всё смешалось. Представьте, что случилась катастрофа: метеорит разбмобил Тайвань, отрикошетил в Корею и на крыльях перелетел и разбомбил все заводы Intel'а в США. Заметит это мир? Да, заметит. Будет ли это катастрофой? Нет, не будет: за 3-4-5 лет заводы отстроятся, а всё это время можно работать на уже существующих компьютерах.
Конечно, это так. Но при чем тут нефть? У вас в голове все смешалось.
А если подобное произойдёт с нефтью? О, тут проблемы начнутся немедленно: весь тренспорт (ну хорошо, почти весь) немедленно встанет и хорошо если удастся путём массовых расстрелов установить достаточный порядок для того, чтобы люди элементарно с голоду не передохли.
Америка уже не одно десятилетие движется к банкротству а доллар — загнивает. Но что-то живее всех живых.Ну так большие дела быстро не делаются. Если бы СССР в 90е не развалился, то Америка бы крякнула… но не судьба. Это отодвинуло проблему — но сейчас она вернулась.
Мы живем в 21 веке, а не в 19-20, и единственный значимый ресурс 21 века — это человеческий капитал.Не стоит путать XX век и XXI. Как XX век не начался в 1900 году (полтора десятилетия до первой мировой скорее по укладу и повадкам относились к XIX), так и XXI век ещё не вступил в свои права. Но он вступит, не беспокойтесь. Отчаянная борьба Apple и Tesla за остатки месторождений Кобальта (остатки, потому что Китай, не верящий в «экономику услуг» размеется, озаботился этим гораздо раньше) — это только начало.
А нефть — это всего лишь ядовитая черная жижа, которая сама по себе (в отличии от человеческого труда) никому не нужна.Вот только почему-то там, где она есть — туда завозят демократию из бомболюков (Ливия и Иран, Сирия и Ирак), а там где её нет — ограничиваются громкой риторикой (ни на Северную Корею, ни даже Кубу «демократию из бомболюков» не завезли… странно, не так ли?).
Рынок услуг стремительно растет и долгосрочно выигрывает тот, кто инвестирует в людей.Посмотрим. Недолго ждать-то осталось уже. Так как вы по ссылкам ходить не хотите, то самое существенное я процитирую:
Ни один из сценариев не приводил к «концу цивилизации» или «вымиранию человечества». Даже самый пессимистичный сценарий показывал рост материального уровня жизни до 2015 года. По расчётам, снижение среднего уровня жизни может начаться с 2020-х годов, вследствие превышения экологических и экономических пределов роста населения и промышленного производства, исчерпания легкодоступных запасов невозобновляемых ресурсов, деградации сельхозугодий, прогрессирующего социального неравенства и роста цен на ресурсы и продовольствие в развивающихся странах
Вот собственно где-то с 2020-х, когда ресурсная база начнёт оказывать определяющее влияние на развитие человечества — и наступит XXIй век. Когда размышления о «рынке услуг» и о «выигрыше тех, кто инвестирует в людей» станут такой же сказкой, как и вечный мир, установление которого ожидалось в конце XIX — начале XX веков. Что восполедовало за этим — мы, теперь, знаем.
А что, нефть, продаваемую не за доллары, заливать в баки нельзя?
> Будет ли это катастрофой?
Конечно же, будет.
> Нет, не будет: за 3-4-5 лет заводы отстроятся
Нет, не отстроятся.
> А если подобное произойдёт с нефтью?
Вы вообще о чем? У вас точно в голове какая-то невнятная мешанина. Какое отношение разговоры о метеоритах в тайване и исчезновении нефти имеют к обсуждаемому вопросу? Ваш последний пост выглядит откровенной шизофазией.
> Это отодвинуло проблему — но сейчас она вернулась.
Какую проблему? С чего вы взяли, что есть какая-то проблема?
> так и XXI век ещё не вступил в свои права.
Уже давным-давно вступил. Природные ресурсы не волнуют никого уже где-то с 70-х.
> Посмотрим. Недолго ждать-то осталось уже. Так как вы по ссылкам ходить не хотите, то самое существенное я процитирую:
Вы цитируете ничем не подтвержденные гипотезы. Даже простые модели, подобные тем, что описываются в статье, кардинальным образом могут менять свое поведение при малейших изменениях констант. А вычислить ряд используемых констант даже с точностью до порядка на данный момент весьма сложно. Так что когда там идут тезисы вида «стабилизации на 10-15 миллиардах населения», то 10-15 — это _примерные_ числа. С той же вероятностью там может быть 100-150 миллиардов. Или 1-1.5 миллиарда. А 2020 год может оказаться 20200 годом. Большей точности модели такого вида дать не могут принципиально.
Так что вместо «в 2020 году мы все умрем» следует читать «в следующие два десятка тысячелетий может случиться что-то плохое, при условии, что устройство человеческого общества за это время не изменится».
> Вы в баки самолётов что будете заливать? Проценты ввп? Или всё-таки керосин? А трактора у вас на чём ездят? А танки?Скоро — будет можно. Но очень долгое время путём «демократизации» США удавалось добиваться того, чтобы такой нефти просто не было.
А что, нефть, продаваемую не за доллары, заливать в баки нельзя?
> так и XXI век ещё не вступил в свои права.С 70х годов какого века? XXI? Или всё-таки XX?
Уже давным-давно вступил. Природные ресурсы не волнуют никого уже где-то с 70-х.
XXIй век — первый век «малой» Земли, когда не только не осталось свободных территорий (это-то как раз случилось к началу XX века, в связи с чем он и получился таким, каким получился), но также и полезных ископаемых.
Кстати первый звоночек как раз в 70е прозвенел — но то был лишь бледный предвестник XXI века: кризиз был локальным и был относительно легко преодолен. В XXI веке подобные вещи — станут глобальными и именно они (а не какая-то там «экономика услуг») будут определять и развитие США и развитие мира в целом.
> Посмотрим. Недолго ждать-то осталось уже. Так как вы по ссылкам ходить не хотите, то самое существенное я процитирую:Нет, я понимаю, что верующим «в свободный рынок» считать не положено, но вроде как мы на Хабре, тут собрали люди, знающие про то, как оценки делаются.
Вы цитируете ничем не подтвержденные гипотезы. Даже простые модели, подобные тем, что описываются в статье, кардинальным образом могут менять свое поведение при малейших изменениях констант.
В том-то и дело, что точные коэффициенты не нужны! Двукратная ошибка в оценке нафтяных запасов сдвинет момент кризиза лет на 10. А десятикратная — лет на 30. Всё равно он окажется в весьма обозримом будещем.
Так что вместо «в 2020 году мы все умрем» следует читать «в следующие два десятка тысячелетий может случиться что-то плохое, при условии, что устройство человеческого общества за это время не изменится».Ну если вам так удобнее — считайте так. Но, боюсь, время, когда Америку поставят перед фактом: больше «дармовых завтраков» не будет — ближе, чем вам кажется.
Собственно Трамп — это был как раз «кризисный управляющий», который должен был подготовить США к этому периоду. Однако… ему не дают работать. Так что шансов на то, чтобы участвовать в переходе в XXI век осмысленно у США почти что не осталось. Но переход — обязательно будет. Тут вариантов нет, вопрос только в форме.
А сейчас — нельзя?
> С 70х годов какого века?
20-го, конечно.
> В XXI веке подобные вещи — станут глобальными
Это вам кто сказал?
> Нет, я понимаю, что верующим «в свободный рынок» считать не положено, но вроде как мы на Хабре, тут собрали люди, знающие про то, как оценки делаются.
В отличии от вас, я в вопросе разбираюсь и о таких моделях знаю не из статей на википедии. На данный момент нету ни одной адекватной модели даже для прогнозирования численности населения, хотя это, казалось бы, элементарная задача (т.к. сам процесс нам понятен и его аналоги известны и хорошо изучены). Уже этот факт гарантирует, что любая модель, которая включает оценку численности населения, не может быть хоть сколько-нибудь точной — а ведь там есть еще много других вещей. И эти вещи оцениваются еще менее точно. Тот же прогноз потребления нефти — там ошибка в один-другой десятичный порядок считается и не ошибкой вовсе, а практически идеально точным расчетом.
Кривые, подобные логистическим, в принципе очень сильно реагируют на входные параметры, а мы тут имеем дело именно с ними. И подобрать кэффициенты (в рамках погрешности) так, что ваш 2020 отодвинется на пяток тысячелетий — не проблема вообще.
> Всё равно он окажется в весьма обозримом будущем.
Да нет это не так, конечно же. Вы просто никогда с этими моделями не работали и потому не знаете, как они себя ведут.
> Но, боюсь, время, когда Америку поставят перед фактом: больше «дармовых завтраков» не будет — ближе, чем вам кажется.
О каких дармовых завтраках речь? Ее раз — пока что Америка за все завтраки платила.
> Скоро — будет можно.Пока — нет, процесс всё никак запустить не могут.
А сейчас — нельзя?
А ведь это только первый шаг к созданию системы мировой торговли, способной пережить крах долларовой пирамиды.
Тот же прогноз потребления нефти — там ошибка в один-другой десятичный порядок считается и не ошибкой вовсе, а практически идеально точным расчетом.Для отдельно взятого месторождения или небольшой страны — да, конечно. Стихийные бедствия, неверные исходные данные и прочее. А вот в масштабах мира — уже разница с самыми ранними, самыми грубыми моделями и реальностью — уже раза в два, ни о каком десятичном порядке и речи не идёт.
На данный момент нету ни одной адекватной модели даже для прогнозирования численности населения, хотя это, казалось бы, элементарная задача (т.к. сам процесс нам понятен и его аналоги известны и хорошо изучены).Модели, которые были применены полвека назад и дающие ошибку, опять-таки, меньше, чем вдвое — в рассчёт не берём?
И подобрать кэффициенты (в рамках погрешности) так, что ваш 2020 отодвинется на пяток тысячелетий — не проблема вообще.Попробуйте. Учтите только, что это только усложнит переход от «большого мира» неограниченного роста к «малому миру».
> Но, боюсь, время, когда Америку поставят перед фактом: больше «дармовых завтраков» не будет — ближе, чем вам кажется.Выпадение памяти? Вот тут вы уже вроде как признали что это уже проблема Китая, что ему некому продавать свои товары, по-этому _приходится_ продавать за долги — а теперь опять пошла песня на тему, что Америка «за все завтраки платила».
О каких дармовых завтраках речь? Ее раз — пока что Америка за все завтраки платила.
Если считать пустые обещания оплатой — то да, платила. Если считать только товары и услуги, то — «нет» и давно-таки «нет».
Вы это серьезно? Нефть, купленная за доллары, обладает особыми химическими свойствами?
> Для отдельно взятого месторождения или небольшой страны — да, конечно. Стихийные бедствия, неверные исходные данные и прочее. А вот в масштабах мира — уже разница с самыми ранними, самыми грубыми моделями и реальностью — уже раза в два, ни о каком десятичном порядке и речи не идёт.
Все как раз наоборот. Можно достаточно точно рассуждать об исчерпании конкретного месторождения, но начнется облом-с при попытке агрегирования.
> Модели, которые были применены полвека назад и дающие ошибку, опять-таки, меньше, чем вдвое — в рассчёт не берём?
Таких моделей нет. Тот факт, что данные, предсказанные моделями какого-то там года не отличаются от того, что получилось в реальности, на порядок — лишь в том, что коэффициенты моделей были подогнаны под результат, «прикинутый на пальцах» (каковой и оказался близким к реальности).
> Выпадение памяти? Вот тут вы уже вроде как признали что это уже проблема Китая, что ему некому продавать свои товары, по-этому _приходится_ продавать за долги — а теперь опять пошла песня на тему, что Америка «за все завтраки платила».
Так «купила в долг» != «дармовые завтраки». «Дармовые завтраки» — это когда просто так, за бесплатно.
> Если считать пустые обещания оплатой
Пустые обещания — это обещания, которые не выполняются. Америка прекрасно на данный момент свои обещания выполняет и ничего менять в этом плане не собирается.
Только не в том случае, когда учился он в одной стране, а работает в другой.
Глобализация? Нет, не слышали. Для мировой экономики без разницы где учился, а где работает.
Для мировой экономики без разницы где учился, а где работает.Серьёзно? На расскажете на досуге — как налоги, уплоченные в США, попадают в закрома МГУ?
А так как западный бизнес не любит конкурентов, то выбора для интеграции всего два: либо сырьевая, либо демографическая колония.
Как представитель страны — сырьевого придатка, я завидую странам Восточной Европы, ставшим демографическими колониями. Почему это плохо-то?
Почему это плохо-то?
Плохо это или хорошо, сказать сложно так как критерии оценки довольно субьективны. Но можно представить процессы после интеграции.
Стоит уточнить что интеграция будет экономической, а не политической и социальной, ибо налогоплательщики запада не хотят тратить деньги на улучшение жизни новых колоний, у них и свои заботы есть. То есть ништяков в виде равенства и демократии не будет, по крайней мере просто так и задаром.
При экономической интеграции местное производство загнется — не выдержит конкуренции, останется только добыча ресурсов которых у метрополий нет и сфера обслуживания.
Параллельно население интегрированной территории разделится на три группы:
1) Те кто нужен метрополии внутри нее, ученые и прочие тех специалисты, им будет клево.
2) Те кто метрополии нужен на местах в колонии, «шахтеры» и их обслуга, им будет не плохо
3) Все остальные, кто не вписался в экономику, не конкурентные, более ненужные люди, пенсионеры и прочие.
Управлять же добычей ресурсов и распределением товаров произведенных в метрополии — будут заняты экспаты из метрополии.
После гибели промышленности и уезда дорогих спецов, налоговые и прочие поступления в бюджет будут ничтожны, не достаточны для поддержания социальных обязательств. Оставшийся бизнес и государство начнут брать кредиты. Отсутствие работы и перспектив для «ненужных» людей увеличит криминал и соц напряженность. 3 группе людей начнет становится не очень. Расходы будут снижены и далее начнутся просрочки по взятым кредитам.
Рано или поздно метрополия скажет пора платить по счетам. Государство обьявит дефолт. И тогда все кто остались будут должны поколениями выплачивать долги и проценты по ним и врятли когда нибудь получат хотя бы похожие условия жизни как жители метрополии.
Поэтому хорошо это или плохо, зависит от того к какой категории населения относит себя оценивающий перспективы интеграции персонаж к 1 или 3.
Примеры вышеописанного Греция и прибалтика.
Большинство людей и в 20-25 лет ещё не могут определиться со специализацией, а вы предлагаете 12-14-летним детям решать вопросы о будущем.
В этом возрасте уже в основном понимают общее направление (например, кому физмат, кому танцы и музыка). Внутри общего направления, да, можно потом уточнять ещё долго.
А хорошие оценки по определённым предметам ещё ничего не значат.
Этот же контингент наполнит собой зрительные залы, стадионы, казармы и избирательные участки.
И только поэтому о нем такая теплая забота определившихся вовремя, а не по причине абстрактного гуманизма.
Да. Это очень грязный хак — просто чтобы показать, что так можно.
Ну вот то, что это грязный хак, и не радует, когда альтернатива — вынести часть кода в функции и не хакать.
Кстати, я не знаю, можно ли в препроцессоре написать «при компиляции выдать сообщение про то, что варнинги тут будут, но это так и надо».
В некоторых компиляторах есть #warning, или аналог.
В Си для доступа к глобальной переменнной — её надо объявить глобальной в каждом модуле (процедуре, функции — хотя в Си это одно и то же) как глобальную.
Достаточно включить что-то.h, в котором ещё 100500 объявлений, а данное прибежало за компанию. Такое контролировать нереально, не разбив на те же 100500 маленьких медвежат отдельных заголовков.
Более того: я не столько даю ответы (знания), сколько объясняю вопросы (рассказываю, откуда вообще берётся проблема, и почему её нельзя решать проще).
Обычно это и так даётся, тут у вас не появляется никакой rocket science. Например, иерархию Хомского дают в контексте парсингов всех видов, мьютексы — в контексте синхронизации независимых параллельных агентов. Этого достаточно, чтобы зацепиться за общую тематику. А что вы предлагаете — разом с одним правильным путём показать 10 неправильных?
Уменьшить количество профессиональных преподавателей (которые зависли в глубоком прошлом) в пользу работающих по совместительству и имеющих практический опыт работы.
С этим категорически согласен. Но чтобы практики пошли в преподавание, хотя бы временно, без усиления материальной стимуляции никак не обойтись.
Уменьшить количество обязательных предметов в пользу элективных. Заодно быстро отсеются негодные преподаватели, не умеющие преподавать интересно.
И тут да (хотя, как обычно, дьявол в мелочах, а именно — в наборе предметов).
Уменьшить количество гуманитарной фигни типа философии. Ну или хотя бы вынести её на элективную систему — чтобы тупые гуманитарии не могли сношать мозги беззащитным студентам.
По-моему, её и так не очень много. Хотя не знаю, что у вас.
Сделать обязательной систему производственной практики — как в МФТИ, где студент примерно с третьего курса начинает работать в НИИ.
Немного делают. Только интересные задачи надо искать днём с огнём.
Начинать образование как можно раньше. Т.е. школа д.б. лет пять или семь, дальше — обязательный колледж со специализацией.
У нас к этому активно идут.
А что вы предлагаете — разом с одним правильным путём показать 10 неправильных?Ну, как минимум, надо показать пару простых неправильных путей. Просто для того, чтобы студенты знали про эти пути. Ну и объяснять, что там неправильного.
Если этого не сделать, то студент (м.б. — бывший студент, а уже специалист) наверняка сам додумается до простого неправильного пути — ведь этот путь простой, т.е. до него легко додуматься самостоятельно. И вовсе не факт, что студент додумается, что там неправильного.
В курсе архитектур я рассказывал примерно так:
"Нам надо при каждом объекте данных, к которому может случиться коллективный доступ (коллизия) создать флаг занятости, а перед тем, как что-то делать с объектом — установить блокировку:
if ( flag == свободен ) {
flag = занят;
делаем что нам надо;
flag = свободен;
} else {
тут возможны варианты: спин-блокировка или иной вид ожидания;
}
" Идеально — если студенты сами догадаются, что так делать нельзя, и почему нельзя.Примерно по той же причине я рассказывал про разные устаревшие системы и протоколы — чтобы студенты понимали, как это можно сделать просто, и почему сейчас от этого отказались.
Но чтобы практики пошли в преподавание, хотя бы временно, без усиления материальной стимуляции никак не обойтись.Ой, как же Вы отстали от жизни! Сейчас взят курс на вытеснение практически работающих специалистов из образования — в пользу «глубоко дипломированных» (т.е. с диссертациями и регалиями). Из образования вытесняют даже тех, кто готов преподавать без материальной стимуляции.
И тут да (хотя, как обычно, дьявол в мелочах, а именно — в наборе предметов).Дело даже не в наборе предметов, а в том, что и как там рассказывают. Т.е. курс «компьютерные архитектуры» можно читать десятком разных способов. И тут элективность рулит — однако, только если студенты сами хотят учиться. А если не хотят — то они выберут тех преподавателей, которые ставят халявные оценки. Впрочем, если студенты не хотят учиться — их вообще никак не заставишь знать предмет.
По-моему, её и так не очень много. Хотя не знаю, что у вас.Всё, что больше нуля — много. По кр.мере, если оно не елективно.
У нас к {начинать образование как можно раньше} активно идут.Хм-м-м… А мне кажется — детей стараются отдавать в школу попозже, уже не в семь лет, а в восемь. И школьное образование затягивают — в СССР было 10 лет, сейчас — 11, и думают сделать 12.
Похоже, автор полагает, что код надо написать так, чтобы его мог прочесть и понять слабый программист. Причём с малым расходом сил.
Хм-м-м… А может, надо поднимать планку и не пускать в профессию слабых программистов?
Что, в общем случае, значит "не пускать"? Ввести строгое госурегулирование типа как у врачей? С одной стороны, а кому это надо? С другой, результат всё равно будет далёк от ожидаемого.
Полно аналитики, показывающей, что рынок испытывает большой дефицит разработчиков. Огромные ресурсы тратятся на то, чтобы его ликвидировать и заметная их часть тратится на уменьшение порога входа в разработку.
Что, в общем случае, значит "не пускать"? Ввести строгое госурегулирование типа как у врачей?
Думаю, имелось ввиду — наплевать на их существование и делать всё так, как будто их нет. Таким образом вы поставите свою долю преград на их пути, по крайней мере к вашему коду.
Критические приложения надо расписывать? Или сами знаете?
Я не знаю, как именно «не пускать». Это можно обсудить здесь.
Но как минимум — надо вводить ответственность программистов за косяки. Например, когда BIOS зависает, если размер HDD превышает 32 гигабайта (олдфаги помнят) — то такого программиста совершенно точно надо репрессировать. Ну или репрессировать того, кто допустил их до написания BIOS. Репрессии отпугнут долбоклюев и фуфлогонов. А вот угроза увольнения — не отпугнёт, это вполне очевидно.
Мне кажется, Вы не понимаете, что тупой программист создаёт потребность в программистах.
Тупой криворукий дебил пишет любую программу — и на сопровождение этой программы приходится бросать армию тупых программистов, т.к. приличный человек не способен вынести тот треш, угар и содомию, которую налепил моральный урод. А на рефакторинг, как всегда, нет денег и времени.
Тупой криворукий дебил пишет Windows — и на борьбу с косяками Windows требуется бросить армии прикладных программистов.
Надо не понижать порог входа в программирование, а повышать уровень специалистов. Увы, но повсеменстно деградирующая система образования на это не способна — благодарите толерастов, которые добились запрета дискриминации альтернативно одарённых и добились пропорционального представительства разных национальностей в профессии. Тьфу, срамота!
Upd: А что качается «обрушить свою профессиональную репутацию до уровня „волшебника“, которому лучше ничего не доверять, потому что всё работает на базе непонятной магии» — так надо прямо в коде писать комментарии с указанием нужной потребности в квалификации. Например, «эту функцию имеет право редактировать только тот, кто освоил предитикативную алгебру» (и хорошо бы указать список литературы).
А программистов — не контролируют
Потому что контролировать надо не программистов.
Программирование — это не непосредственное выполнение потенциально опасных действий, это создание средства, которое эти действия выполняет. Индиректность воздействия устраняет свойства самих программистов и выводит в значимое их результат. Именно результат и должен контролироваться.
Для оптимизации контроля за результатом нужен контроль за процессом разработки. И только для обеспечения контролируемости и эффективности процесса разработки нужен контроль за свойствами самих программистов.
То, что в "бытовом" рассмотрении эту цепочку зависимостей упрощают, не устраняет её существования.
Например, когда BIOS зависает, если размер HDD превышает 32 гигабайта (олдфаги помнят) — то такого программиста совершенно точно надо репрессировать.
Плохой, негодный пример. В истории с прохождением размерами дисков цепочки барьеров — косячили все: и производители дисков, и авторы BIOS, и авторы OS, и авторы служебных средств. Но ситуация втыкания нового диска это никак не обычный ход работы критичной системы; это то, что надо было предварительно много раз отработать на стендах.
Тупой криворукий дебил пишет Windows — и на борьбу с косяками Windows требуется бросить армии прикладных программистов.
90% проблем Windows это таки не проблемы тупости кодеров, а происходят из дизайна и идеи сохранения наследия. Все непредвзятые источники пишут, что уровень самих людей там очень высокий — но дальше начинают ругать систему, которая приводит их к такому результату, или явные запросы руководства (например недавние 1, 2). Так что не пинайте исполнителей, пинайте Гейтса, Баллмера и тэ дэ.
Надо не понижать порог входа в программирование, а повышать уровень специалистов. Увы, но повсеменстно деградирующая система образования на это не способна
Уровень специалистов достаточен. Где недостаточен — они способны дообучиться.
Недостаточны — отражения этой проблемы в других общественных институтах. Заказчики, которые вместо нормального ТЗ способны только сказать "сделайте мне красиво" и потом выдать что-то в духе "7 красных линий зелёным прозрачным цветом". Вендоры, которые обеспечивают vendor lock за откат. Стандартизаторы, которые выбирают не то, что работает, а то, что понравилось 10 старперам, оставшихся мышлением во времена появления COBOL (вспоминаем появление iso-8859-5). А вы просто ищете стрелочника.
Например, «эту функцию имеет право редактировать только тот, кто освоил предитикативную алгебру» (и хорошо бы указать список литературы).
Список литературы — да, полезно. Но требование знания предикативной алгебры не нужно, например, для выполнения требования coding style. И что — отвлекать ценного спеца для выравнивания отступов в коде?
Потому что контролировать надо не программистов.Контролировать надо отрасль в целом — и программистов, и менеджеров, и систему образования.
Программирование — это не непосредственное выполнение потенциально опасных действий, это создание средства, которое эти действия выполняет.Правильное программирование — это создание средств, которые не позволяют оператору/пользователю выполнить опасные действия.
В истории с прохождением размерами дисков цепочки барьеров — косячили все: и производители дисков, и авторы BIOS, и авторы OS, и авторы служебных средств.Давайте примеры.
Я знаю, что у DOS'3.* и ранее было ограничение на размер раздела = 32 мегабайта. Но это был не косяк, т.к. система на диске любого размера создавала разделы только приемлимого размера; и даже если кто-то (например, DOS'4.* или позже) создавал раздел типа «BigFAT», то DOS'3.* не зависал, а просто не «видел» этого раздела.
А косяков от производителей HDD я вообще не помню.
Но ситуация втыкания нового диска это никак не обычный ход работы критичной системы; это то, что надо было предварительно много раз отработать на стендах.Ситуация наплевательства на стандарты — весьма серьёзный показатель положения дел в отрасли.
90% проблем Windows это таки не проблемы тупости кодеров, а происходят из дизайна и идеи сохранения наследия.Когда я говорю «Тупой криворукий дебил пишет Windows» — имеются в виду и кодеры, и архитекторы, и Гейтс с Баллмером.
Стандартизаторы, которые выбирают не то, что работает, а то, что понравилось 10 старперамА кто дальше принуждает заказчиков и исполнителей следовать этим стандартам?
И что — отвлекать ценного спеца для выравнивания отступов в коде?Написать скрипт для выравнивания отступов в коде — религия не позволяет?
Контролировать надо отрасль в целом — и программистов, и менеджеров, и систему образования.
Это уже косвенно достигается по цепочке влияния. Я же говорю про исходные посылы — можно достигать хорошего качества с отвратительным уровнем самих программистов, и наоборот. Дороже, да, но не невозможно, и практически неизбежно в ряде мест и ситуаций.
Правильное программирование — это создание средств, которые не позволяют оператору/пользователю выполнить опасные действия.
Вас уносит в сторону от темы. Всё ограничить в принципе невозможно, и неэффективно, но я не хочу тут и сейчас это обсуждать.
А косяков от производителей HDD я вообще не помню.
Если говорить именно о геометрии: были. Для начала, во времена дисков до ~200MB детект был неустойчивым, диски могли тупо отвечать через раз, и задание параметров через BIOS совсем вручную, или через несколько попыток ручного детекта, было нормой. Это явление ушло окончательно уже где-то во времена 1GB дисков. Далее, уже сильно позже (где-то от, возможно, тех же 32GB) было несколько инцидентов, когда запросы именно в геометрической адресации отрабатывались неправильно самим диском. Точных марок и моделей уже не помню, мне лично не попадались. При том, что тогда подавляющее большинство BIOS и драйверов уже работали через LBA, большинство этого не заметило. Третье — не могу назвать это явным нарушением, но на косяк тянет — по переходу через 32GB некоторые диски стали отдавать в якобы-геометрии 255 секторов, при том, что BIOS были к этому не готовы; тут больше вопрос, было ли тут отраслевое соглашение, или нет. У меня это привело к ситуации "при загрузочном разделе с началом ниже 32GB система не стартует" и я писал problem report во FreeBSD "перестаньте делать геометрические вызовы, если сектор якобы укладывается в геометрию, сейчас EDD чуть ли не в каждом утюге".
Со стороны BIOS и OS, да, косяков было больше (в целом в списке около десятка границ, по переходу которых что-то ломалось).
Ситуация наплевательства на стандарты — весьма серьёзный показатель положения дел в отрасли.
А никогда нельзя, увы, опираться только на стандарты.
Почему, например, LBA-assist геометрия имеет до 255 "головок", а не 256? Решили, что так лучше, чем сломать несколько неназванных программ, которые при 256 начинали делить на ноль.
А прочее — см. выше про возможное соглашение. Я не знаю, обещали ли производители дисков, что они не будут рапортовать более 63 секторов. Можете подкинуть тему репортёру какого-нибудь THG :)
Когда я говорю «Тупой криворукий дебил пишет Windows» — имеются в виду и кодеры, и архитекторы, и Гейтс с Баллмером.
OK, ясно.
А кто дальше принуждает заказчиков и исполнителей следовать этим стандартам?
Наверно, другие такие же "криворукие дебилы" © в других комитетах, в вендорах, с которыми надо сотрудничать, и т.п.
И не всегда их можно обойти или отодвинуть.
Написать скрипт для выравнивания отступов в коде — религия не позволяет?
Естественно. Потому что скрипт тем более не обладает знанием про предитикативную алгебру, и кто его знает, что он там накосячит?
А если вы позволяете скрипту редактировать код в таких условиях, почему не позволяете человеку?
По поводу влияния памяти автор сказал совершенно верно, в основе качественного кода лежит магическое число семь.
Кстати, слово refactoring происходит от математического слова факторить (фактор), т.е. декомпозиция. Декомпозиция — как способ управления сложностью, чтобы детали реализации рассматриваемой обязанности не превышали это число 7.
Но… проблема умных людей в программировании действительно существует. Хорошо раскрывает эту тему Кент Бек в книге «Экстремальное программирование». Особенно это хорошо заметно в России, где алгоритмический аспект программирования часто превосходит коммерческий аспект сопровождаемости программы.
На самом деле, если «умному человеку» дать немного знаний по экономике разработки ПО, а книга Бека является лучшим пособием по этому вопросу, то проблема исчезает.
Промежуточные шаги никто не накапливает и не сохраняет, они _пропускаются_. Условный отличник из примера отличается не тем, что выполняет действия в уме, а тем, что он их вообще не выполняет. В принципе. Он сразу знает (из опыта) что в случае Х результат Y, без декомпозиции задачи на подзадачи.
А размер кратковременной памяти у всех людей практически одинаков, так что никакого существенного влияния он не оказывает. Оказывает та самая способность «пропускать шаги».
Само слово «технология» происходит от древне-греческого τέχνη — искусство, мастерство, умение. И фантазии, и смелых решений в нашей работе предостаточно. Иногда смотришь на чей-нибудь хороший код — и реально эстетическое наслаждение получаешь: насколько человек всё изящно и виртуозно сделал!
Вообще, нет. Упражнения вроде n-back не развивают кратковременную память, они развивают умение выполнять n-back за счет «склеивания» стимулов. То есть «профессиональный» n-back'овец просто в итоге запоминает стимулы парами (тройками, етц.), а не единичками, как новичок (ну так же как вы слова запоминаете целиком, а не в виде набора букв). А самих таких пар-троек у него остается, как и было. Кратковременная память прошита в генах, и если бы ее можно было натренировать — то можно было бы такой тренировкой сделать человека из обезьяны, т.к. недостаток кратковременной памяти — это и есть основная причина, из-за которой обезьяна не может в reasoning (в голове не хватает места для пары силлогизмов, по-этому последовательность выводов не выстраивается).
Горе от ума, или Почему отличники пишут непонятный код