Comments 297
Но вообще, конечно, это необязательно для языка. Просто хорошая традиция
Чтобы отладить все нюансы есть достаточно реальных задач кроме собственно компилятора, в то время как написание компилятора не обязательно затронет все нюансы которые нужно отлаживать, но вот времени займёт просто уйму (особенно если язык сильно отличается от того на котором пишут первый компилятор).
Задачи, к тому же, необязательно должны быть такими сложными во время разработки языка — к примеру, для отладки рекурсии хватит чисел Фибоначчи, для отладки многопоточности или асинхронной обработки — web-client/server.
Но разумеется, если у разработчиков свободного времени вайлом — тогда да, почему бы и нет, собственно, пишут же эмулятор Z80 на bash…
Для интерпретируемых языков больше характерна реализация на более низкоуровневом языке (C или C++, как правило). Или наличие трансляторов в C/Javascript.
Формально, PyPy — это не компилятор Python на Python.
PyPy — это реализация интерпретатора Python на подмножестве языка RPython (валидный код на Python не обязательно является валидным для RPython).
Сам PyPy написан на RPython, который уже является компилируемым языком. Но при этом компилятор RPython уже по большей части написан на Python.
— Машина работает с маш. кодами операций и аргументами в виде ячеек памяти и регистров.
— Асемблер даёт имена маш. кодам и регистрам, делая их человекочитаемыми и наворачивает немного синтаксического сахара по оформлению операций. Но всё это приводимо к маш. кодам практически 1:1
— С и иные системные языки — реализуют некоторые базовые конструкции алгоритмизации в своём синтаксисе, а также организуют среду программирования, состоящую из процедур и методов их написания. Что-то из данных процедур можно написать на асемблере и, используя соглашение о вызове процедур, внести её в среду программирования.
И так далее. То есть язык более высокого уровня добавляет некоторое количество абстракций над языком более низкого, которые в основном представляют из себя просто часто повторяемые конструкции нижележащего языка приятно оформленные в некоторый синтаксис. Когда компилятор языка пишется на самом компилируемом языке возникает ощущение, что языка в этом месте быть и не должно. Возможно нужно спуститься ниже и переписать язык более низкого уровня. Компилятор может частично быть написан на своём языке, но ядро компилятора должно быть написано на языке, в который данный компилятор программу и перегоняет… По другому смысла в компиляторе не видно.
И вообще это языковое безумие заставляет всё чаще вспоминать историю о Вавилонской башне если честно…
Компилятор — программа переводящая...Если говорить только о самом переводе в исполнимую форму, без уточнения момента перевода, то есть более обобщающий термин — транслятор.
А уже в зависимости от того, выполняется ли трансляция целиком всей программы до выполнения, или по кусочку во время исполнения — получаем деление на компиляторы и интерпретаторы.
И вообще это языковое безумие заставляет всё чаще вспоминать историю о Вавилонской башне если честно
Вот дозахватят нас роботы, тогда и bip bop bop bop bop bip bip bip bip bip bip bip bop bop bop bop bip bip bip bip bip bop bip bop bop bop bop bip bip bop bop bip bip bip bop bop bop bop bip bip bip bip bip bop bip bop bop bop bop bip bip bop bop bip bop bip bop bop bop bop bip bip bip bip bip bop bip bop bop bop bip bop bop bop bop bop bop bip bop bop bop bop bip bip bip bop bop bop bip bop bop bop bop bip bip bip bip bop bop
"Традиция" — это довольно сырой аргумент. Нужно понимать, что такие вещи делаются чтобы деньги зарабатывать напрямую, либо использовать наработки в других местах. Это ведь не Вася из 9 класса, который написал свой первый парсер и "потому что так принято" делать никто не будет.
Раскрутка компилятора позволяет разработчикам на языке, для которого создается компилятор, этот язык и развивать. Достаточно прагматичная цель, интуитивно выглядит разумным, что разработчики, которым что-то нужно от языка, будут охотнее в него вносить изменения и им не нужно будет вникать в особенности низкоуровневой разработки на втором языке (на котором написан компилятор).
Окружение уже развёрнуто, знай себе только патчи отправляй.
Правда, если язык незрелый — для него нет никаких инструментов. Для TS куча линтеров-чекеров, поддержка в редакторах, миллиарды статей и много разработчиков, поэтому в данном случае от этого нет никаких преимуществ.
Вполне возможно, что через год-полтора сам язык торжественно передадут в сообщество (читай: забьют на разработку), а наиболее интересные решения войдут в TypeScript.
- Разработчики языка сами пишут на нём — хорошо для понимания проблем и развития языка.
- Пользователям проще участвовать в разработке и в крайнем случае смотреть на детали реализации.
Пример когда другой язык реализации мешает — Java. Отчасти поэтому сейчас есть проект VM на самой Java — GraalVM.
В том смысле, что разработчики должны сами есть ту «собачью еду» что производят, чтоб лучше понимать какова она на вкус.
Так вот, новые ЯП как правило нужны для введения и демонстрации новых техник программирования, ЯП никто не релизит ради синтаксиса. И есть концепция en.wikipedia.org/wiki/Eating_your_own_dog_food которая говорит что нужно использовать свой продукт. И вот вы как разработчик языка начинаете на нём писать его — же. Понимать как на самом деле работает то что вы придумали. В случае в TS изначальная архитектура пришла из старых JS подходов, и она откровенная слаба в TS мире. Вот поэтому я считаю что нужно писать ЯП на нём самом, не если это не DSL какой-нибудь.
const compilerOptions = host.getCompilerOptions();
const languageVersion = getEmitScriptTarget(compilerOptions);
const moduleKind = getEmitModuleKind(compilerOptions);
const allowSyntheticDefaultImports = getAllowSyntheticDefaultImports(compilerOptions);
const strictNullChecks = getStrictOptionValue(compilerOptions, "strictNullChecks");
const strictFunctionTypes = getStrictOptionValue(compilerOptions, "strictFunctionTypes");
const strictBindCallApply = getStrictOptionValue(compilerOptions, "strictBindCallApply");
const strictPropertyInitialization = getStrictOptionValue(compilerOptions, "strictPropertyInitialization");
const noImplicitAny = getStrictOptionValue(compilerOptions, "noImplicitAny");
const noImplicitThis = getStrictOptionValue(compilerOptions, "noImplicitThis");
const keyofStringsOnly = !!compilerOptions.keyofStringsOnly;
const freshObjectLiteralFlag = compilerOptions.suppressExcessPropertyErrors ? 0 : ObjectFlags.FreshLiteral;
const emitResolver = createResolver();
const nodeBuilder = createNodeBuilder();
const globals = createSymbolTable();
const undefinedSymbol = createSymbol(SymbolFlags.Property, "undefined" as __String);И эти константы замыкаются и юзаются из кучи функций, отдаются колбеки и тп. Чтобы разделить стейт, грамотно его пробросить и всё такое нужно огромное количество усилий. И я вижу только два пути, автоматом конвертнуть типа как я предлагал и потом начать разводить по наследованию, и второе, сказать что у нас теперь есть новый компилятор tsc 2.0 и в нём написать всё это заново с новой архитектурой. Пока же эта штука продолжает расти.
const context = {
compilerOptions: host.getCompilerOptions(),
languageVersion: getEmitScriptTarget(compilerOptions),
moduleKind: getEmitModuleKind(compilerOptions),
// ...Во всем коде использовать этот объект как Service Locator, а потом начать передавать всем, кто его хочет как зависимость?
Кроме того, усовершенствование компилятора (добавление новых оптимизаций и проверок) помогает улучшать его собственную работу.
Вроде был язык, в котором только 3 функции, первая печатает "Hello world", вторая выводит текст программы, а третья генерирует компилятор этого языка. Так что возможность написать компилятор языка на самом языке не является доказательством полноты по Тьюрингу.
Разница только в том что кто-то это делает публично, а кто-то «тайно» — в первом случае об отсутствии спецификации в начале разработки известно всем, а во втором об этом может никто и не узнать (поскольку её выложат вместе с языком) — хотя принципиальной разницы нет.
В конце концов, это ж не мостостроение, где опасно начинать строить пока нет проекта и расчётов, особенно с учётом того что нигде в продакшн это не используется.
Сначала накодят что-то, а потом задним числом сочиняют спецификацию
Называется Agile. И внезапно это удобно и эффективно, хотя и не везде.
Не в том ли идея чтобы он сразу мог бы параллелится?
Кстати, fun fact: Я был так много наслышан о том, как Хаскелл хорошо параллелится, ещё когда начал учить первый язык, что когда я схватился за Хаскелл, был поражён, что параллелить надо через монаду, что накладывает не одно ограничение на мой код, т.к. я ещё не понял их и трансформеры. Итог: не один десяток малых параллельных проектов на С++ и ни одного на Хаскелле.
Вот тебе и «easy parallelism by design».
Ничего не устарело, просто я открыл для себя с изучением Хаскеля, что недостаточно просто «сказать» программе, что я хочу её раскидать на десять кластеров, а надо-таки раскидывать этот лёгкий-для-параллелизма из коробки по парам и секам.
Написать-то можно, если задаться, но к многопоточности приходишь, как набираешься чуть опыта и видишь, где от неё профит словить.
если мы можем передать Map по ссылке, и фунция ее намутирует.
Не зная как устроена Map, это сложно понять. Не исключено, что в Map метод добавления элемента генерит новый Map просто (как в Scala).
Мне кажется, я даже мгновенно перестал ненавидеть JavaScript после того как увидел это. Серьёзно, ещё пол-часа назад я хотел любыми силами избежать JavaScript в моей жизни, а сейчас JavaScript уже не кажется чем-то сильно плохим.
Я про другое. Если взглянуть на этот код, то можно увидеть следующие «интересности»:
1) в классе (который назвали entity) есть const поля, а есть field. Казалось бы и то, и другое — поля класса, но к первым в коде обращаются через явное указание типа и двоеточия (
Board::playerX), а ко второму через точку и this (this.cells). Нужно ли было делать такую разницу для данных в одной области видения?2) стрелочка используется и для вызова методов класса, и для пайпинга. Нет, конечно, можно подвести эти вещи под один знаменатель, если представить что каждый метод неявно принимает параметр this (вроде того, как это сделано в Питоне). Но нужно ли?
3) потом мы видим, что через двоеточия мы по сути можем обращаемся к статическим const полям (
game = game->makeAutoMove(Board::playerX, 0);). При этом само поле не помечено как static, хотя спецификатор этот есть (factory static createInitialBoard()). Кстати к этому статичному фабричному методу мы обращаемся уже через указание класса и собаку (field board: Board = Board@createInitialBoard();). Зачем надо было делать такое различие — не ясно.Да, может всему этому есть объяснение и сложно судить по куску кода о языке. Но серьёзно, как отметили выше, ощущение такое, что ребята просто на ходу сочиняют разрозненные куски, а потом под это подведут кривую спецификацию. В то время как лучше было бы начать с другого конца.
Ну и вот, например, тут достаточно о разнице между function и "=>". Помимо того факта, что для этих стрелочек обычно надо ещё какой-нибудь Babel городить.
(особенно с подсветкой современных редакторов),
Скорее в древних блокнотах. Современный редактор умеет в семантическую подсветку. А подсветка уровня кейвордов — это про древний блокнот.
Соответственно — function является лишним синтаксическим шумом, т.е. редактор умеет красить функции в уникальный цвет. И современно без разницы какие они.
Что конкретно?
Зачем?
В итоге команда, которой удалось реализовать этот паттерн, надолго становится незаменимой — их становится очень сложно уволить, не завалив разрабатываемый продукт, потому что спецов по новой технологии в ближайшее десятилетие будет исчезающе мало.
Именно поэтому программистам очень выгодно реализовывать этот паттерн. А вот для менеджера, допустившего такое, например переписывание половины браузера на принципиально новый язык — признак профнепригодности, особенно когда компания испытывает финансовые трудности.
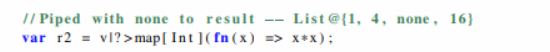
Давайте вы её еще под углом сделаете и мигающей, вдруг ещё остались люди, которым удобно читать это уг?
EDIT: Оказалось, что блурилось из-за масштабирования в браузере, но это всё-равно камень в огород автору статьи
function internString(ref env: Map<String, Int>, str: String): Int {
if(env.has(str)) { //use the ref parameter
return env.get(str);
}
env = env.add(str, env.size()); //update the ref parameter
return env.size();
}Можно разве что побольше сделать картинку, чтобы читалось получше
Вместо function вставили method
Я так понял, что это означает, что функция виртуальная. Или нет?
Языки все больше становятся похожи на какие то клиновидные записи или древнеегипетские иероглифы
Ну почти все языки полны всяких «иероглифов», в заблуждение они вводят разве что новичков, со временем они запоминаются и проблем с их пониманием нет, конечно если не городить всяких заумных конструкций. Есть другая крайность — когда язык очень похож на естественный, как например SQL или COBOL, читать вербозный код не очень-то легко, а писать на таком языке вообще мрак и уныние.
вместо if нужно было еще что нибудь придумать
Ага, как в Red, if с одной ветвью, either — с двумя.
whatever(false condition)
а еще лучше вообще язык поменять на русский
Тсс, тихо! А то ещё призовёте дьявола в 1С 8.4 в виде:
#РасходнаяНакладная↑Conclude(СуммаСовсемБез НДС).Подобно()
программы на Bosque являются детерминированными… Если программа выдала какой-то результат, то такой же результат будет и потом, никаких сюрпризов
Вот эта формулировка меня очень и очень смущает. То есть… скажем, если программа использует БПСЧ… или обращается к жесткому диску / сетевому адресу… результатом будет синий экран?
Или вот это:
алгоритмы сортировки только стабильные
под стабильными, наверное, понимаются устойчивые алгоритмы? А если я напишу на Bosque алгоритм Шелла (неустойчивый) — будет исключение рантайм? Ошибка компиляции?
Поясните, пожалуйста. Взрывает мозг…
Thus, Bosque does not have any undefined behavior such as allowing uninitialized variable reads and eliminates all under defined behavior as well including sorting stability and all associative collections (sets and maps) have a fixed and stable enumeration order.
As a result of these design choices there is always a single unique and canonical result for any Bosque program. This means that developers will never see intermittent production failures or flaky unit-tests!
Больше информации нет никакой.
Возможно, я что-то не так понял. Готов исправить статью
Вот мне нужен ЯП, смесь из ассемблера(доступ к флагам и регистрам процессора), С и С++(классы, виртуальные функции) и при этом достаточно простой. Думаю развивать идею ассемблера MASM'а(UASM), кодогенерирующие макросы .if, .while, .for, и т.п.
А по этому ЯП(назовём его Боська), в упор не вижу каких либо достоинств. Да, у меня память не очень хорошая, и очень не хочется её перегружать лишней инфой, изучая кучу очень сложных ЯП. Надо проще делать, чтобы простой как Lua и достаточно функциональный как С++.
Поясните свою мысль.
Желтизна сегодня — она именно такая. Написать абсолютную правду, но так, чтобы сформировать ложное впечатление. «Новый язык от Microsoft» — это явно про какой-то продукт, который распространяет компания Microsoft. Не эксперимент в Research, а конкретный продукт с поддержкой в Visual Studio.
Так может быть вам как автору новости стоило бы всё выяснить, прежде чем торопиться писать?)
Если бы я знал о таких нюансах, я бы конечно выяснил.
Выглядит как первоапрельская шутка.
Главная миссия дизайна языка — чтобы он был прост и понятен как для человека, так и для компьютера.
Взаимоисключающие параграфы? Языки программирования созданы так, чтобы быть понятными человеку. Для компьютера лучше всего понятен ассемблер.
рекурсия считается злом, которое может усложнить программу, поэтому рекурсивные фунции надо помечать словом rec
Почему? Многие алгоритмы наоборот в рекурсивном виде выглядят просто и естественно. А нерекурсивный вариант выглядит куда более громоздко.
А как нужно помечать потенциально рекурсивные функции, т.е. такие, которые могут вызывать сами себя, но опосредованно?
программы на Bosque являются детерминированными. Другими словами в языке нет неопределенного поведения. Например, нельзя использовать переменные, пока они не были определены; алгоритмы сортировки только стабильные и т.д.
Какие-нибудь современные языки являются недетерминированными? Вспоминается только C++. Записывать это в плюсы — все равно что писать, что в языке можно использовать не латинские идентификаторы.
Если программа выдала какой-то результат, то такой же результат будет и потом, никаких сюрпризов
Что это за чушь вообще. А что если используется функция генерации случайных чисел?
Также хочется задать авторам вопрос: чем их не устроил собственный же язык F#?
Также хочется задать авторам вопрос: чем их не устроил собственный же язык F#?NIH в масштабе локальной команды?
Для компьютера лучше всего понятен ассемблер.
Программа на машинном языке тогда уже. Программа на мнемокодах (языки ассемблера) — тоже понятнее для человека.
чем их не устроил собственный же язык F#?
Тоже возник такой вопрос. А вообще лучше бы они Nemerle поддержали.
Вместо классов и интерфейсов в языке есть понятия entity и concept.
Но это те же интерфейсы и классы, просто названы по-другому.
M$ изобрели Erlang только TypeScript
Хотя… возможно, это очередная попытка от MS создать Java.
Разве MS не создала свое виденье Java создав C#?
корпоративные решения… никакой крос-платформенности
Вы что-нибудь слышали про Unity?
А прибитость его к .net вообще не ясна, потому, что никакой крос-платформенности он не дает.
Я просто оставлю это здесь

Несмотря на существование Mono, C# тесно привязывает разработчиков к платформе Microsoft (включая ОС, офисные решения). Таким образом, пользователь программного обеспечения, написанного на .NET, часто не имеет выбора в использовании различных компонент системы. Это приводит к так называемому vendor-locking, при котором производитель стороннего ПО может диктовать покупателю практически любые условия на поддержку внедрённого проекта. В то время, как пользователь приложения Java, как правило, может сам выбрать поставщика дополнительного ПО (такого, как БД, ОС, сервера приложений и т. д.).
Это указано на вики. И копипастю сюда не как пруф, а как текс с которым Я согласен. И имею то же мнение.
К кросплатформенности я отношу не просто исполнение кода на чем-то ином, а развитую экосистему продукта, адаптированную под платформу. MS же тянет все свое с собой. И… пфффф… Ну и повторюсь еще раз — это лишь мое мнение.
А в общем, вы процитировали глупость, с которой согласны лишь потому, что не имеете представления о ситуации так же как ее не имеет автор этого опуса. Кроме этого вашего mono вообще-то есть .net core.
это лишь мое мнение.
Оно какими-нибудь фактами подкреплено? На прошлых двух работах писал на дотнете совсем не под windows — мобильная разработка на Xamarin(Android, iOS) и тяжелый бэк на .NET Core(Linux) — есть вполне конкретные контрпримеры к утверждению, что оно прибито к MS-экосистеме / кроссплатформенность недостаточного качества для энтерпрайза.
К кросплатформенности я отношу не просто исполнение кода на чем-то ином, а развитую экосистему продукта, адаптированную под платформу. MS же тянет все свое с собой
nuget? Если взять топ-100 пакетов оттуда по популярности(не стал проверять дальше), все они работают на *nix без проблем.
Подкреплено личным опытом, в период с момента его первого релиза до 2014г.
Подкреплено личным опытом, в период с момента его первого релиза до 2014г.
Слушайте, ну вы вроде как тим лид, да еще и с таким большим опытом работы с .net. Кому как не вам понимать что за 5 лет в современной индустрии меняется вообще все и ваш опыт .net пятилетней давности имеет мало общего с тем что мы имеем в 2019 году.
Или… или как тимлид с некоторым опытом, который наблюдал многострадания MS подвинуть Java, а еще и Delphi (че к нему то привязались, вообще не ясно) одним махом. При этом, завезя все, что было в VB и прибив гвоздями к своему любимому OLE. Наблюдая конвульсии шарпа с первой презентации (с криками — долой самодержавие Java!) до отказа от всех внедрений на нем в крупных компаниях и переход на Oracle.
Я таки (за 10 лет) сложил свое мнение и об языке и о его перспективах и сделал свой выбор, в свое время. И ни разу о нем не пожалел.
Вот как завезут .net на хотя бы 30% устройств как предустановленную машину, так и поговорим. А то в свое время визгу было, что мир теперь изменится, про java забудут и везде будет .net. А я как отъехал от MS так за все время, даже случайно не встретил .net на чем-то отличном от винды.
А на смартфонах предустановленный .net и не нужен: mono прекрасно распространяется вместе с приложением.
Ровно также, как только появилась Java, тут же скукожилось и съехало в небытие. Причем скукоживаться начало уже тогда, когда простые мидлеты появились на простых телефонах. Заметьте не .net, а Java машина туда ставилась. Почему бы?
С выходом первого андройда WindowsMobile был приговорен. Вялые попытки что-то там пропихнуть через покупку Nokia увенчались тоже полным крахом. Сейчас MS приторговывает… Nokia 3110 (или какого они там мамонта возродили) в оригинальном исполнении. Смешно? По мне так очень.
А на смартфонах предустановленный .net и не нужен: mono прекрасно распространяется вместе с приложением.
Возможно. Только приложения такие никому не нужны. В лес со своими дровами…
и тяжелый бэк на .NET Core(Linux)
Не вброса ради а любопытства для: в качестве ОС для разработчика на этом проекте вы использовали Windows или таки Linux?
Windows — до VS кроссплатформенным IDE не дотянуться ещё.
IIRC, ни в Rider, ни в VSCode, ни даже в Monodevelop a.k.a Xamarin Studio a.k.a VS for Mac нет edit-and-continue до сих пор.
В общем, как по мне, так акая-то хрень вышла.
Какая-то аргументированная критика C# в сравнении с Java у вас есть?
Именно. И проект, в общем-то оказался провальным.
С вашей стороны весьма глупо называть провальным язык, который уже давно занял неплохую долю в своей нише и очень крупное сообщество.
Какая-то аргументированная критика C# в сравнении с Java у вас есть?Лично я скажу, что в Шарпах в сравнении с Джавами просто прекрасные Дженерики
А в чем отличие, можете в двух словах рассказать?
var text = GetComponent<Text>();
var image = GetComponent<Image>();
В Java невозможно так сделать — информация о дженериках теряется на этапе компиляции и этот код скомпилируется во что-то такое:
Text text = GetComponent();
Image image = GetComponent();
Естественно, работать не будет. В Шарпах информация о типах сохраняется и её можно использовать не только как подсказки, но и в коде.
Вот это как раз без особых проблем работает, просто вместо угловых скобок надо использовать class:
Text text = GetComponent(Text.class);
Image image = GetComponent(Image.class);1. статические поля и методы также могут использовать типы-параметры;
2. можно без хитрых извращений и без тонн автогенерированного кода взять и использовать контейнер, параметризованный примитивным типом.
String[ZipCode]Чего только люди ни придумают лишь бы не делать алгебраические типы…
Вообще конечно выглядит пока сомнительно. Особенно комбинация заявленной иммутабельности с ref — то ли авторы сами толком не определились, чего они хотят от языка, то ли не очень понимают, что immutability это совсем не то, что делает const в javascript. Вообще изрядно отдаёт какой-то фиксацией на javascript-е. Как будто авторы даже с наработками "родного" майкрософтовского F# не вполне знакомы, хотя пайп |> явно оттуда потянули.
Ну вообще говоря можно сначала отобразить объект в пару (объект, индекс) и потом делать всё остальное. В идеале компилятор может всю цепочку вызовов превратить в обычный цикл, но на практике, кмк, такого ещё нет.
Меня несколько смущает, что ничего не сказано про ленивость вычислений. Если уж отказываться от циклов, то это must have.
За процессами и каналами — в go, в Erlang, или в Java и её библиотеку Akka, или в .NET и в библиотеку Akka.NET. Но там очереди, почему-то, есть. Как и стек. Не согласна почему-то реальность с вашими фантазиями…
Уважаемый, вы путаетесь в показаниях.
Во-первых, зачем так проектировать систему, что она не справляется с нагрузкой и приходится ждать в очереди?
Вот за этим:
Единственно, что я могу признать как вариант нормального использования очереди — это выравнивание пиков нагрузки. Но тогда очереди должны быть хотя бы ограничены по ёмкости.
С одним дополнением — вы не всегда можете так просто ограничивать очередь по емкости. У вас может быть требование от бизнеса "обработать все входящие запросы".
Во-вторых, а если мы не дождемся освобождения ресурсов, либо их таки не хватит на разгрузку очереди, то что делать?
Вы опять отвечаете на свой вопрос самостоятельно:
То есть мы должны осознавать какую нагрузку мы должны принять и выравнять.
Такие ситуации нужно отслеживать и предотвращать. Ждать когда мощностей даже с очередями не хватит — глупо. Нужно с самого начала собирать статистику нагрузки, экстраполировать тренд и масштабироваться с учетом будущей нагрузки. Если ресурсов внезапно не хватит, то это ЧП и отказ в обслуживании части клиентов.
На первый вопрос ответ понятен: просто не умеем нормально проектировать.
Если вы где-то встретили решение, которое использовало очереди не по назначению, то это проблема не "очереди", а решения.
Про второй вариант ответ так же прост: мы просто сбросим содержимое очереди.
Что вы будете делать, если у вас требование от бизнеса "обработать абсолютно все входящие сообщения"? "Просто сбросить" далеко не всегда так просто, как хотелось бы. Это вы видите запросы в очереди, а другие видят в них деньги и время.
Озвучьте, пожалуйста, аксиому, которую вы пытаетесь превратить в теорему?
Не помню, чтобы кто-то всерьез заявлял "нужно везде использовать очереди".
Зачем? Функциональный, типизированный, иммутабельный, но с возможностью обойти.
Есть же F#, Clojure и Haskell (первый и третий при поддержке Microsoft)
С типом будет ещё больше мусора, а именно let/var name: type, а не type name;
К тому же, := — является таким же кейвордом, о котором я говорил. И абсолютно неважно в каком он будет виде. Т.е. мой тезис это никак не опровергает.
К тому же, это вообще находится за рамками контекста т.к. контекстом является а) синтаксис принятый в обсуждаемом языке, б) синтаксис принятый в си.
Так же, := — избыточен для ситуаций, где тип не выводится, а задаётся. Вам придётся либо использовать избыточность, либо вводить два типа операторов, что опять же — избыточность и синтаксический мусор.
К тому же, это локальные го-заморочки не присущи ни паскалю, ни всему тому, что используется его стиль.
А так же, самое важное — это вообще никак не зависит от стиля. Это работает в любом случае. Т.е. смысла приводить это в контексте разделения стилей нет — т.к. это не относится к одному из — это относится к обоим.
Основная из них заключается в том, что как звучал тезис? «имя: тип что-то там позволяет». := — опровергает этот тезис,
Если по сути, а не формально, то тезис звучал как «имя сначала, тип потом Vs тип сначала, имя потом». Далее спор шел о ключевом слове auto для авто-вывода против якобы необходимого var для обычного объявления. Двоеточие это только пример реализации первого подхода. Пример го показывает, как можно иметь имя сначала, не имея «синтаксического мусора» перед именем.
У вас простое взаимное недопонимание.
Пример го показывает, как можно иметь имя сначала, не имея «синтаксического мусора» перед именем.
Нельзя. := — это синтаксический мусор, который, к тому же, писать сложнее нежели =, либо auto.
К тому же, как я уже говорил — мы либо вводим :=/=, либо мы имеем не только := в качестве синтаксического мусора, но и аннотацию при которой := избыточно.
Двоеточие это только пример реализации первого подхода.
Это так же неверно, т.к. двоеточие не имеет никакого отношения к подходу.
Я больше скажу — в си вообще аннотация типа ненужна. Она используется только для в одном случае — определение. Да и то нужен просто какой-то флаг для выражения намерения. Подойдёт вообще что угодно. const/auto/register. Всё это уже придумано и давно. Го просто взял эту логику из си.
Нельзя. := — это синтаксический мусор, который, к тому же, писать сложнее нежели =, либо auto.
Во-первых, не мусор, а однозначность синтаксиса как для парсера, так и для человека. Во-вторых, писать это несравнимо проще auto. В-третьих, таки ничего лишнего перед именем переменной нет.
Подойдёт вообще что угодно. const/auto/register
Это ли не тот синтаксический мусор. Вместо типа мы пишем вещи, которые вообще не имеют никакого отношения к делу. Модификаторы доступа и устаревшие ключевые слова, которые нынче ничего не значат.
Го просто взял эту логику из си.
В этом нет логики, это синтаксические извращения. В Го однозначный синтаксис, которые имеет четкие правила — либо :=, либо var. Все. Пример тут не с кого брать было.
Во-первых, не мусор, а однозначность синтаксиса как для парсера, так и для человека.
Мусор. Вы как бот повторяете один и тот же набор шаблонных фраз.
Во-вторых, писать это несравнимо проще auto.
Основания этим заявлениям.
В-третьих, таки ничего лишнего перед именем переменной нет.
Есть после имени. До оно, либо после — это ничего не значит.
Это ли не тот синтаксический мусор.
Нет, вы действительно бот. Какое отношение эти рассуждения имеют к теме? Никакого. Абсолютно неважно что они значит — они значат тоже самое, что и :=, только ещё больше.
Вместо типа мы пишем вещи, которые вообще не имеют никакого отношения к делу.
Чушь какая. Они имеют отношения к делу и никто их вместо не пишет. Вам лишь сообщили, что подобная логика объявления без типа существовала и существует в си.
Модификаторы доступа и устаревшие ключевые слова, которые нынче ничего не значат.
Вы опять где-то что-то услышали и начали повторять? Ну расскажите мне про то какой бесполезный статик, либо const, либо volatile. Или это, как обычно, пустой трёп?
В этом нет логики, это синтаксические извращения.
Опять же, когда нечего сказать — пиши херню.
В Го однозначный синтаксис, которые имеет четкие правила — либо :=, либо var. Все. Пример тут не с кого брать было.
Мне надоело с ботом разговаривать.
Хотите поиграть — хорошо, я жду эквивалента кода:
int a;
На го.
я жду эквивалента кода: int a;Это не код, это говно (неинициализированная переменная).
А что касается того, что опровергает Go, то Go опровеграет два ваших утверждения: 1) необходимость мусора в виде двоеточия, отделяющего имя переменной от типа, 2) необходимость мусора в виде ключевого слова типа let, var или auto.
Двоеточие в := не является отдельным элементом/ключевым словом. Два символа := являются одним, единым оператором, поэтому никакого мусора при его использовании уже нет. (Не будете же вы настаивать, чтобы присвоение значения переменной выполнялось вообще без единого оператора?)
Это не код, это говно (неинициализированная переменная).
Т.е. ответа нет и адепт го порвался?
А что касается того, что опровергает Go, то Go опровеграет два ваших утверждения:
Фантазии брызжущих слюной адептов го.
1) необходимость мусора в виде двоеточия, отделяющего имя переменной от типа
Я уже отвечал на эту ахинею. Эта ахинея никак не связана с темой и с моим утверждением, т.к. она применима не только к паскаль-стилю.
Т.е. я могу использовать := в любом из стилей. Это просто сахар, костыль. Определяются переменные го не так.
2) необходимость мусора в виде ключевого слова типа let, var или auto.
Что за нелепая попытка врать. Читаем мой коммент:
Ни от какого auto паскаль-стиль не уходит, а наоборот требует ввод кейворда для обозначения декларации переменной. Таким образом вы всегда будите писать синтаксический мусор вместо типа. Всякие там var, let и прочее.
Т.е. брызжущий слюной адепт го врёт, утверждая, что говорил «необходимость мусора в виде ключевого слова типа let, var или auto.», но я приводил это лишь как пример.
Двоеточие в := не является отдельным элементом/ключевым словом.
Является.
Два символа := являются одним, единым оператором, поэтому никакого мусора при его использовании уже нет.
Два символа в if «являются одним, единым оператором». Опять методичка потекла.
Два символа := являются одним, единым оператором, поэтому никакого мусора при его использовании уже нет.
Он и есть мусор, т.к. есть уже оператор =. А это другой оператор, который является костылём для решения избыточности паскаль-стиля.
(Не будете же вы настаивать, чтобы присвоение значения переменной выполнялось вообще без единого оператора?)
Опять чушь. Именно те, кто рассказывал про «проблему auto» утверждали, что переменную можно объявлять без избыточности.
Я же сообщил, что это неверно и нужен механизм отделения. В ситуации же си-синтаксиса механизм ненужен — он уже есть.
В ситуации же с паскаль-синтаксисом он нужен. Это var/let и прочая фигня. Именно с var сделан ваш го. А далее закостылено := — которая является таким же механизмом, лишней сущностью она повторяет уже существующие функционал.
Вообщем, вы, насколько я погляжу, особо вменяемостью не блещете. Спорить о чём-то с ботами бесполезно, поэтому я вернуть к сити, а именно.
Я отвечал изначально в контексте преимущества паскаль-стиля, т.е. я это опровергал. Теперь вам нужно сообщить — каким образом := относится к паскаль-стилю? Я заранее отвечу — никаким. Новы там можете попытаться что-то придумать.
Т.е. ответа нет
Вы требуете перевести незаконченный кусок кода с одного ЯП на другой. Это не всегда возможно: нужен контекст, более-менее осмысленный кусок кода. Если воспринимать приведённый код как цельный, то получается переменная, которой не присваивается значение. Это бессмысленный код, переводить нечего.
Является.
Враньё. Ни в описании языка, ни в восприятии текста программистом двоеточие не воспринимается как отдельный элемент. Ну и уж тем более оно не является ключевым словом.
Он и есть мусор, т.к. есть уже оператор =.
Это не мусор. Это важный элемент, позволяющий отличать объявление новой переменной от переприсваивания. Без него читаемость программы ухудшилась бы.
каким образом := относится к паскаль-стилю
Речь шла о том, что новые ЯП используют "паскалевский стиль". Го — один из этих новых ЯП, и именно такой, что является контрпримером к вашим тезисам.
А что касается преимущества, то речь шла совсем о другом: о том что "let/var" нужен в обоих вариантах, но в паскалевском стиле он используется единообразно во всех ситуациях, а в C является в некотором роде костылём, подпирающим конструкцию, из которой убрали необходимый элемент — тип обявляемой переменной.
о том что «let/var» нужен в обоих вариантах
Пруфы.
но в паскалевском стиле он используется единообразно во всех ситуациях
var v1 int = 100
v1 := 100Единообразно, да. Объясняйтесь.
а в C является в некотором роде костылём, подпирающим конструкцию, из которой убрали необходимый элемент — тип обявляемой переменной
Обоснования этому набору слов. Что именно является костылём, что там и где и что подпирает.
И ответа на самое главное нет — каким образом := относится к паскаль-стилю? Это просто костыль, который можно впилить в какой угодно стиль. Причём тут паскаль-стиль? Как это выступает за паскаль-стиль, но против си-стиля?
Есть синтаксис var name type =, базовый. Данный пациент утверждает, что никакой избыточности нет. Но авторы го с ним несогласны.
Именно поэтому вводится var (), это есть ещё со времён паскаля. Потому что все очевидно, что объявление с аннотацией через var — это избыточно. Т.е. пациент спорит с объективной реальностью.
Аналогично с := — это синтаксический сахар, который был добавлен специально для решения проблемы var name auto =.
Т.е. мы имеем как минимум два варианта объявления переменных, но что же там нам сообщал пациент:
В Go объявление функции, объявления типа указателя на функцию, передача функции как объекта первого порядка — все это идентичные синтаксически вещи
Он заявлял, что проблема С++ в том, что синтаксис разный. В целом эти базовая методичка го «делаем что-то одним способом», но.
Как мы видим, что тут эта методичка ломается. Потому что способов как минимум 2(3). А почему? Потому что общий случай избыточен и добавлен специальный сахар для решения проблемы.
Аналогично с := — это синтаксический сахар, который был добавлен специально для решения проблемы var name auto =.
А это (существование какой-либо проблемы с var name =) опровергает Rust, где конструкции, аналогичной := нет. Если бы упоминаемая вами проблема реально существовала, её пришлось бы решать не только в Го, но также и в Расте.
А это (существование какой-либо проблемы с var name =) опровергает Rust,
Опять поток шизофрении. Чего он там опровергает? Там есть let, который такая же подпорка для синтаксиса. И есть избыточность let name: type, когда как в си это type name.
Если бы упоминаемая вами проблема реально существовала, её пришлось бы решать не только в Го, но также и в Расте.
Как же быстро лозунги меняются. То := меня опровергает, то уже меня опровергает раст.
Каким образом из отсутствия решения следует отсутствие проблемы? Вы вообще в логику можете?
Нельзя. := — это синтаксический мусор
Можно. Я повторю еще раз тезис, на который вы категорично ответили «нельзя»:
можно иметь имя сначала, не имея «синтаксического мусора» перед именем.
Вы же отвечаете на другую реплику, которую я не писал и которая звучит как «можно обойтись без синтаксического мусора».
Это так же неверно, т.к. двоеточие не имеет никакого отношения к подходу.
Имеет; таким образом список идентификаторов синтаксически отделяется от типа, задавая однозначную грамматику. Это нужно именно при подходе «идентификаторы перед».
Я повторю еще раз тезис, на который вы категорично ответили «нельзя»:
можно иметь имя сначала, не имея «синтаксического мусора» перед именем.
Мне без разницы кто там и что говорил. Я говорил а) в рамках контекста определённым начальным комментом, б) я отвечаю только за свои тезисы.
С чего вдруг вы решили, что вы можете в любой момент подменить начальный тезис и что-то мне предъявлять? Ваши манёвры меня волнуют мало.
Имеет; таким образом список идентификаторов синтаксически отделяется от типа,
В го? К тому же мы говорим про двоеточие в :=, а не о том что вы там себе напридумывали. Этот костыль можно впилить в какой угодно синтаксис — хоть в си. Он вообще никак не привязан ни к чему.
Активно пишу на scala, где аргументы описываются как имя: тип.
На мой взгляд, такой стиль побуждает думать сначала о смысле переменной, а потом уже выбирать подходящий тип.
Допустим пишу функцию "calculate". Например для вычисления баланса по множеству операций. Сначала есть код:
function calculate(
Эта функция принимает в себя множество операций. Добавляю
function calculate(operations:
Какую лучше коллекцию сюда передавать? Сортированный список или set. Продумываю оба варианта и выбираю список. Тогда добавляю в код
function calculate(operations:SortedArray){
Мелочь, но позволяет думать в первую очередь о бизнес-логике, а потом уже о инструментах для ее реализации.
На мой взгляд, такой стиль побуждает думать сначала о смысле переменной, а потом уже выбирать подходящий тип.
Тип и определяет смысл.
множество
Тут ваша логика дала течь. Множество уже тип, вы подумали о типе до.
Опять же, существует два варианта — от данных, либо от операций. От данных — это когда у вас уже есть логика, которая генерирует данные и типы их уже выбраны. Тогда вы в первую очередь должны писать тип.
От операции. Ты вы пытаетесь реализовать какую-то операцию и в процесса выводите тип. Очевидно, что этот процесс находится в теле функции и с какой он находится — неважно. Абсолютно.
Странно использовать слово "обычный" в этом контексте. Парсерт непротиворечимой грамматики написать легче в этом случае, только и всего.
В си-стиле выражается void(a, b, c); В паскаль стиле нет. В том же TS приходится эмулировать сишный стиль через (a, b, c) => void, т.е. семантика потекла. Нужно два синтаксис для определения типа и функции.
И таких примеров масса. К тому же не стоит сравнивать скриптуху, где одни ссылочные типы и си. Это разные весовые категории. Это как сравнивать С++-лямбду и js-лямбду.
жс-лямбда мало того, что дырявая(вы не сможете там определить тип возврата), дак ещё и десятой долей функционала не обладает. Конечно, манипулировать и сравнивать несравнимое удобно. Но не стоит так делать.
struct building //Создаем структуру!
{ char *owner; //здесь будет храниться имя владельца
char *city;
…
Мы сначала говорим, что это структура, потом даём имя типа, а потом уточняет.
А логично делать наоборот
building =record и дальше уточнение.
Вообще с порядком в С++ но очень.
Например логично закодировать. Указатель на хрю-хрю как ^hru_hru. Или Хрю-хрю указывает на — hru_hru^. А если сделать обратный порядок, получиться чтение справо налево.
А логично делать наоборот
Почему? К тому же везде и всюду сделано аналогично и здесь:
function update
entity Foo {И так далее.
Например логично закодировать. Указатель на хрю-хрю как ^hru_hru. Или Хрю-хрю указывает на — hru_hru^. А если сделать обратный порядок, получиться чтение справо налево.
Распарсить это решительно невозможно. Это какой-то набор слов. Напишите что-то более адекватное типа «в крестах так: бла-бла, а нужно так: бла-бла».
К тому же везде и всюду сделано аналогично и здесь:
function update entity Foo
Это как раз ближе к var foo, потому что слева от имени стоит не тип, а ключевое слово, категория имени (функция, структура или переменная), а тип как раз стоит справа: параметры и возвращаемое значение для функции, список членов для структуры и имя типа для переменной:
category | name | domain | codomain
-----------------------------------------------------------
function update (id: int, data: string) : bool
entity Foo {id: int, data: string}
var foo : FooЭто как раз ближе к var foo
Это какие-то попытки подменить изначальный тезис. Был пример со sturct — я показал, что в этом языке используется такая же форма определения объектов. Она используется везде, в том же тайпскрипте.
потому что слева от имени стоит не тип
Где тут: struct name — стоит слева тип? Нигде.
Начнём с того, что сишный sturct под неё подходит, а говорилось именно о нём. Так же никакое положение в таблице не обосновывается, никак. Т.е. на каком основании "(id: int, data: string)" является «domain», а bool не является. К тому же, ваша табличка игнорирует override method, ref env.
Ну и на самый главный вопрос нет ответа. Почему? Можно нарисовать какую угодно табличку, но вопрос заключается в том — почему так должно быть? Зачем строить свои рассуждения на догматах?
Ок, прошу прощения, проглядел пример building = record от nmrulin и почему-то решил, что вы всё ещё про запись "тип имя", так что действительно вышло не в тему.
на каком основании "(id: int, data: string)" является «domain», а bool не является
(id, data) — это "вход" функции, область определений (domain), а bool — выход, область значений (codomain). Запись f(int, string) => bool или f(int, string): bool вполне математична: "f есть отображение множества кортежей типа (int, string) на значение во множестве bool".
А как прочесть запись bool f(int, string) в парадигме "тип имя"? "Функция типа bool с именем f"? Но беда: тип этой функции не bool, а вовсе даже bool (int, string).
А как прочесть запись bool f(int, string) в парадигме «тип имя»? «Функция типа bool с именем f»? Но беда: тип этой функции не bool, а вовсе даже bool (int, string).
У вас дара в логике.: — семантически отделяет тип. Вы игнорируете сей факт и свободно подменяете семантику: во имя подбития реальности под свою модель.
К тому же, вы взяли какую-то логику и каким-то образом определили её за правильную, а далее исходите из того, что всё что иное — неправильное. Ведь любая другая логика — неправильная.
С таким же успехом можно сказать про ref и про override и прочее. Вы говорите о каком-то примитивном обрубке, а не о каких-то общих правилах.
В общих правилах определяющим является имя, а уже далее что-то там из него следует. Но если имя является определяющим, то на каком основании оно должно быть вначале? Да ни по каким — это догмат.
Начнём с того, что сишный синтаксис создан как f(a, b) {} — изначально все типы были auto(из крестов). Правда там не было вывода типов, а универсальный тип просто был интом.
Всё что слева/справа ничего не значит. При этом в си есть прямое разделение на право и лево. Есть тип, а есть объект. То, что написано справа — относится к объекту, а всё что слева — к его типу.
В примитивных языка такого разделения нет — на то они и примитивные. В том же bosque разделение уже появляется — там есть тот же ref, т.е. то, что относится к самому объекту.
Можно, конечно, делать это делать слева до :, как многие и делают. Но, очевидно, что получается полный треш. Всякие там name?: type.
Правда в Си всё не совсем так. Там тип не может быть массивом, потому что массив — это объект. Так же как типом не может быть функция.
Хотя, конечно, в си есть и тип-функция и тип-массив, но только в рамках тайпдефа. Так же, есть (int[]){} — это логика исходит из того же. По такому же принципу работает using в С++.
Если проще. Объект может переменной — это просто тип. Если мы видим просто тип — это тип какого-то объекта/переменной.
Но, в случае с [] — типом будет массив. Объект будет массивом. А типом указывается тип возврата операции/тора [], аналогично и с () — скобочки уже из объекта делают функцию. А всё остальное к делу отношения не имеет. Тип, который слева — это не тип объекта — это тип возвращаемый (). Потому что свободный тип — это всегда объект(какого-либо значение).
Поэтому си читается следующим образом. void f(); f — это идентификатор/имя. Вы без проблем можете писать void f()[] — функция будет возвращать массив. Тоже самое с [][], вы можете написать int arr[10]() — тоже без проблем.
И это бы всё работало круто, но в си есть фундаментальное разделение. Есть объекты как значения(которые могут быть значениями), а есть которые не могут. Вот [] и () значениями быть не могут.
Таким образом сишный синтаксис и его семантика куда строже и логичнее, нежели упомянутая вами. Где вы как угодно трактуете каждую закорючку.
Описать его можно так. Есть база, которой вы даёте тип. Тип задаётся как справа так и слева. Причём есть два типа типов. Тип самого объекта(массив/переменная(значение)/функция), который пишется справа. И всякие расширения — это слева.
f() — это функция, тип объекта. Слева накидываются всякие свойства, свйоства накидываются ИМЕННО на объект(это упомянутая мною база). f тут уже вообще не при делах.
() — расширяется параметрами. Так же, он возвращает какой-то объект. Тип объекта справа не написан — значит это обычный объект/значение. Этот объект является базой. Ему можно задать тип и всякие там квалификаторы.
* — это тип. Никаких «на» там нет. Это просто упрощение. * — такая же база. Правила те же, но она слева и приоритет у неё меньше. Именно для этого там скобочки — они выделяют новую базу.
И теперь, я думаю, вы сами сможете прочитать bool f(int, string)
База по умолчанию — идентификатор. Идентификатор имеет тип-объект функция. f — это функция, () — имеет семантику «аргументы и „возвращаемое для операции () значение“(по-колхозному возвращает значение)». Читаем аргументы. Аргументы типа инт и строка. Далее эта функция что делает? Возвращает значение(справа ничего нет). Далее, слева могут стоять уточняющие, а именно тип значения и его квалификаторы.
Так же там могут стоять «квалификаторы», которые воздействуют на сам базовый объект.
f — функция с аргументами инт и строка, возвращающая(по-колхозному) значения типа bool.
У вас дыра в логике: — семантически отделяет тип
Это скорее у вас дыра в понимании. Семантика двоеточия зависит от контекста: для переменных отделяет тип, для функций — тип возврата. Полный тип может включать в себя больше чем то, что после двоеточия, но правило то же:
- справа от имени — всё, что про тип, т.е. про область всех возможных значений. Для скаляров — просто имя уже имеющегося типа (встроенного или определённого). Для агрегатов — перечисление типов членов агрегата. Для функций (которые есть мост между двумя областями, входом и выходом) — как типы аргументов, так и тип возращаемого значения.
- слева от имени — то, что про сам объёкт. Например категория (var/const/enum/function/struct/class), видимость объекта (public/private), модель хранения (static/const/readonly), модель передачи параметра (in/out/ref), модель вызова метода (virtual/static) и прочee. Всё это не является частью типа.
В результате первого правила функции получают настоящий тип, а не несовместимый "тип-объект с расширениями", становятся гражданами первого сорта, могут быть присвоены переменной, проверяются при присваивании как по параметрам, так и по возвращаемому значению, иначе будет ошибка типа.
И, заодно, массивы теперь получают полноценный тип, как и любой другой агрегат или строка (массив символов), а не "тип-объект", чей тип при передаче в функцию внезапно протухает и разлагается до указателя.
Но, очевидно, что получается полный треш. Всякие там name?: type.
Но очевидно, что name?: type — это просто сахар для каноничной записи name: type | undefined, который слишком часто встречается и слишком длинно писать каждый раз. Правило 1 выполняется: ?:type находится справа от name.
всякие расширения — это слева.…
() — расширяется параметрами.
Параметрами тоже слева? Упс, строгая логика поломалась — параметрами расширяем таки справа, т.е. внутри (). И теперь у нас расширения то слева, то справа.
Вы без проблем можете писать void f()[] — функция будет возвращать массив.
Вы уверены? Я плюсовик, не голый сишник, но насколько мне известно, ANSI C не позволяет функциям возвращать массив, только указатель, и объявление будет примерно таким монстриком: void (*f())[N]. В высшей степени интуитивная конструкция.
Претензию про ref и override так и не понял: что конкретно вам не нравится, и как именно они ломают логику?
Это скорее у вас дыра в понимании. Семантика двоеточия зависит от контекста: для переменных отделяет тип, для функций — тип возврата.
С чего вдруг она меняется? Основание.
Полный тип может включать в себя больше чем то, что после двоеточия, но правило то же:
Т.е. двоеточие не имеет никакого отношения к типу. Из этого прямо следует, что тип не только справа от двоеточия, либо только. Третьего не дано. Либо двоеточие ничего не значит.
Что самое интересное — эти манёвры следствие попытки оправдать неоднозначность, которой там, на самом деле, нет. Т.к.: там там же отделяет тип. И типом является именно возврат, ведь тип возврата и определяется. Аналогично работает и для ?:type. Когда? является признаком опциональности и точно так же относится к имени, а не определяет ?:type — новый синтаксис для типа. Потому что тогда нужно было ?type, либо type?..
справа от имени — всё, что про тип, т.е. про область всех возможных значений. Для скаляров — просто имя уже имеющегося типа (встроенного или определённого). Для агрегатов — перечисление типов членов агрегата. Для функций (которые есть мост между двумя областями, входом и выходом) — как типы аргументов, так и тип возращаемого значения.
Вам не нужно мне перечислять те случаи, где его семантика потекла — я и так это знаю. Нужно отвечать на вопрос а) зачем оно нужно. б) почему у него изменяется семантика.
слева от имени — то, что про сам объёкт. Например категория (var/const/enum/function/struct/class), видимость объекта (public/private), модель хранения (static/const/readonly), модель передачи параметра (in/out/ref), модель вызова метода (virtual/static) и прочee. Всё это не является частью типа.
Всё это хорошо, но без интеграции в предыдущие рассуждения — это просто перечисление не относящиеся к теме. Интегрируйте его в изначальную вашу модель. public — это категория? Что это?
К тому же, вы так и не обосновали разделение в таблице. На каком основании часть после двоеточия вынесена, а список параметров остался.
В результате первого правила функции получают настоящий тип
Какие критерии для «настоящий»? Почему меня должен волновать какой-то фентезийный «настоящий тип».
а не несовместимый «тип-объект с расширениями»
У вас опять рассуждения потекли. Вы там забыли про ref/const и прочее. Это такие же «расширители» и без ник никакая аннотация типа не определяет объект, а является лишь частью определения.
, становятся гражданами первого сорта, могут быть присвоены переменной, проверяются при присваивании как по параметрам, так и по возвращаемому значению, иначе будет ошибка типа.
Ну во-первых это наивные манипуляции, когда сравнивается несравнимое. Т.е. берётся скриптуха и её примитивная модель и сравнивается с более сложной моделью, при этом примитивность и её следствия превращаются в следствия синтаксиса/«настоящих типов».
И, заодно, массивы теперь получают полноценный тип, как и любой другой агрегат или строка (массив символов), а не «тип-объект», чей тип при передаче в функцию внезапно протухает и разлагается до указателя.
Опять же. Сравнение примитивной скриптухи и более сложной модели.
Но очевидно, что name?: type — это просто сахар для каноничной записи name: type | undefined, который слишком часто встречается и слишком длинно писать каждый раз. Правило 1 выполняется: ?:type находится справа от name.
Я не понимаю две вещи. На каком основании вы дёргаете куски фраз и отвечаете только на удобное. Зачем вы мне повторяете то, что я уже до вас вам сообщил?
Можно, конечно, делать это делать слева до :, как многие и делают. Но, очевидно, что получается полный треш. Всякие там name?: type.
Здесь именно говорится о том, что ?: — справа от name. И именно поэтому этот пример называется трешем.
При этом это я говорил про этот: [Int, ?:Bool], никакого name тут нет. А вот лево есть. Тут, конечно, можно пытаться задним числом опять изменять семантику для :, но очевидно — что это эквивалент name?:type и значит это не type|undefined, а именно опциональный аргумент. Мне лень читать и искать это в мануале, но любо это дыра в логике языка, либо действительно так.
Параметрами тоже слева?
С чего вдруг? Опять нелепая попытка дёргать фразы. Расширения — это квалификаторы, в разных контекста это понятия значит разное.
Упс, строгая логика поломалась
То, что вы увидели где-то два похожих слова и вам показалось, что вы что-то там нашли — это лишь вам показалось.
— параметрами расширяем таки справа, т.е. внутри (). И теперь у нас расширения то слева, то справа.
С чего вдруг она справа, если они внутри? Отсчёт идут от () — очевидно, что внутри никаким образом не может быть ни справа ни слева.
Вы уверены? Я плюсовик, не голый сишник, но насколько мне известно, ANSI C не позволяет функциям возвращать массив,
Я уверен. К тому же у вас опять какие-то проблемы с восприятием. Мы говорим о синтаксисе, а не о том, что си позволяет/не позволяет делать. Синтаксис это позволяет.
только указатель, и объявление будет примерно таким монстриком
Основания в студию.
: void (*f())[N]. В высшей степени интуитивная конструкция.
Да, куда более интуитивная, чем рандомный набор символов и дыр, который существует в скриптуха-паскаль-языках.
Конечно, куда там этим конструкциями до *[N]void f(); — вот оно, чудо человеческой мысли.
Или это: []int{1000, 2000, 12334} как перепаста с сишного (int[]){1000, 2000, 12334}. struct{f int}{50} — вот оно, удобство.
Претензию про ref и override так и не понял: что конкретно вам не нравится, и как именно они ломают логику?
Я уже обозначил выше проблему — как это интегрируется в вашу табличку.
С чего вдруг она меняется? Основание.
Я же написал: у переменных тип — это одно множество значений, а у функции тип — это два множества: множество входов и множество выходов. Поэтому семантика и разная.
Т.е. двоеточие не имеет никакого отношения к типу.
В принципе, тип можно было бы записывать и без двоеточия, просто var x int = 10 или function foo (a int, b string) bool {}, двоеточие скорее декоративное, чем семантически нагруженное.
Когда? является признаком опциональности и точно так же относится к имени, а не определяет ?:type — новый синтаксис для типа. Потому что тогда нужно было ?type, либо type?..
Нет, ?:type в Typescript означает как раз алгебраический тип type | undefined, что означает "имя определено, но значение может быть не известным". Можно спорить, относится ли опциональность к объекту или типу, но в Typescript это сделано типом, т.е. "значение неопределено" тоже является частью области значений, имеет свою метку, возвращается typeof.
type? мог бы означать type | null как в C#, но в Typescript этого не стали вводить, скорее всего из-за борьбы с null и нежелания облегчать синтаксис для null.
Интегрируйте его в изначальную вашу модель. public — это категория? Что это?
Вроде ясно было написано: public — это область видимости имени/объекта. Она не меняет тип значения объекта, а только доступность имени — значит записывается справа от имени.
ref и override… как это интегрируется в вашу табличку.
Табличка изначально была иллюстрацией к типам (то, что справа от имени), а не про квалификаторы объекта (то, что слева от имени), и в ней указано всего 3 категории имён — свободная функция, свободная переменная и структура. Как вы хотите вкосячить туда ref и override? Это нужно новую таблицу рисовать, со всеми видами объектов. Если у вас есть время и желание, сами нарисуйте себе расширенную табличку, я в вас верю.
Какие критерии для «настоящий»?
Читать умеем? Русским же по фоновому было написано: "функции… могут быть присвоены переменной, проверяются при присваивании как по параметрам, так и по возвращаемому значению, иначе будет ошибка типа".
Вся проверка типов вращается вокруг совместимости переменных разных типов. Тип функции (int,string): bool не совместим по типу с функцией (string, int): bool, хотя возвращаемый тип одинаков. Потому что тип функции — это не только тип возврата, а также и тип и порядок аргументов. Вы не можете переменной одного типа присвоить значение другого типа, и это относится так же к функциональным типам.
Ну во-первых это наивные манипуляции, когда сравнивается несравнимое. Т.е. берётся скриптуха и её примитивная модель и сравнивается с более сложной моделью,
Ну во-вторых, это наивная манипуляция, когда для аргументации одна модель типов беспричинно объявляется "примитивной скриптухой", а другая "более сложной", хотя эта "более сложная" модель была рождена в языке с практически отсутcтующей проверкой типов, а в "примитивной" есть и алгебраические типы, и настоящий null (а не наколенное поделие из #define NULL (0)), и вывод типов.
Как вы любите повторять: где основания вашим словам? Вы тут часто требуете оснований, но сами не брезгуете просто накинуть на вентилятор безо всяких оснований.
Давайте я дальше буду отвечать в вашем же непринуждённом стиле:
Мы говорим о синтаксисе, а не о том, что си позволяет/не позволяет делать. Синтаксис это позволяет.
Синтаксис позволяет, а язык не позволяет. Шизофрения. Обоснуйте.
Да, куда более интуитивная, чем рандомный набор символов и дыр, который существует в скриптуха-паскаль-языках.
Обоснования в студию.
куда там этим конструкциями до *[N]void f(); — вот оно, чудо человеческой мысли.
С чего вдруг? Это лозунги и догматизм какой-то. Где обоснования?
На каком основании вы дёргаете куски фраз и отвечаете только на удобное.
А почему на каком основании вы спрашиваете? Если отвечать на весь трэш и вкусовщину, которые вы тут вываливаете, то я потрачу намного больше времени, чем хотел на вас потратить.
С чего вдруг? Это лозунги и догматизм какой-то. Где обоснования?
Хорошо, поиграем.
только указатель, и объявление будет примерно таким монстриком: void (*f())[N]. В высшей степени интуитивная конструкция.
С чего вдруг? Это лозунги и догматизм какой-то. Где обоснования?
какой_то (*это())[ЛОЗУНГ][ДОГМАТИЗМ]
Пока что я вижу в вас не оппонента, а нервного адепта С, который бегает и требует у всех обоснований, при этом сам только бросается хлёсткими эпитетами, без оснований. Извините, второго Луговского из вас не получается, а другие тролли мне не интересны.
Для начала обоснуйте, почему void (*f())[N] — это зашибись и красиво, и единственно верно, а всё остальное — дерьмо. Иначе вы точно такой же религиозный догматик, каким всех выставляете.
Для начала обоснуйте
Не, такое не работает. Вы первый начали что-то там болтать про си — обосновывайте. Пока не обоснуете разговаривать с вами нет смысла, т.к. вы болтун.
Луговского из вас не получается, а другие тролли мне не интересны.
Меня мало волнуют заявления кого-то в интернете. Ну и да, тут заметно как адепт пытается, крайне наивно и нелепо, прокладывать путь к отступлению.
Ведь я просто тролль, это не ему ответить нечего, а просто он не будет мне отвечать потому что тролль. А тролль я потому, что он сам так сказал.
а всё остальное — дерьмо.
А тут видно как адепт пытается в очередной раз врать, ведь он нигде не покажет моих подобных тезисов. Все мои тезисы на тему «лучше» имели обоснования и ни этот адепт, ни какой-либо другой их никогда не оспорит.
А вот его тезисы я могу показать и показал выше, как и тезисы подобных ему.
Это базовая методичка болтуна в интернете. Использовать схему «всё говно, кроме того, что я считаю не говном», а когда кто-то приходит оспаривать эти заявления — болтун обвиняет оппонента в том, что делал сам.
Иначе вы точно такой же религиозный догматик, каким всех выставляете.
Это ещё одна тактика болтунов. «иначе вы» — абсолютно неважно кто я, будь я хоть трижды хоть кем — это никак не отменяет ничего. Схема уровня детского садика «а Вася тоже в штаны насрал».
Но самое интересное тут то, что всё эти рассуждения уровня начальной школы не работают, т.к. не я прихожу и не я всем доказываю, что «сишный синтаксис говно» — этим занимаетесь вы. Мне вообще насрать на то, что там у вас и как.
Это у вас есть желание бежать везде и проповедовать. У меня его нет. Я просто вижу «неправильно» и отвечаю на него.
По поводу сравнения. Даже если бы я захотел что-то сравнивать — вы не покажете мне объекта сравнения и его нет. Все сравнения адептов — это сравнение какой-то скриптухи и языков на порядки более сложных и фичастых. За примерами ходить ненужно — рассуждения фанатиков про лямбды.
Хотите, что-бы можно было что-то сравнивать — создайте синтаксис в котором можно выразить аналогичную семантику. Кто же вам не даёт? А я знаю кто не даёт. Потому что тогда нельзя будет врать и выдавать лёгкость более слабого синтаксиса за преимущество перед тяжестью тяжелого.
Запомните раз и навсегда. Си всегда было насрать на все рассуждения маргинальных элементов. Си ненужна защита, его ненужно проповедовать везде и всюду.
Фанатизм, аргументация уровня «у меня лучше синтаксис» — это паскалятская зараза. Именно его адепты постоянно всё засирают и рассказывают всем о том «какой же сишный синтаксис говно».
И почему все адепты паскаля везде бегают и орут — ясно и понятно. Потому что они мечтают сделать свои веру главенствующей. А вот адептам си этого делать ненужно — они итак главенствуют.
Повторю ещё раз. Когда сделаете на паскаль-синтаксисе не-скриптуху. Приходите и поговорим. А пока мне говорить не с кем и сравнивать не с чем.
Хотя даже в этом случае меня это будет волновать мало. Это вам нужно доказывать, что вы не хуже. Моя(условная) вера уже всё доказала.
Вы первый начали что-то там болтать про си
Вы бредите. Я вообще-то начал с того, что стиль "имя тип" ничуть не менее логичный, чем стиль "тип имя" — если конечно понимать что такое тип вообще, а не докапываться до двоеточий и их местоположения, и не триггериться от якобы "синтаксического мусора".
не я прихожу и не я всем доказываю, что «сишный синтаксис говно»
Конечно не вы. Вы пытаетесь доказать, что "паскалевский стиль говно". Ровно с той же степенью обоснованности.
ведь он нигде не покажет моих подобных тезисов.
Т.е. вы не называли паскалеподобный синтаксис мусором?
Я просто вижу «неправильно» и отвечаю на него.
Не обосновывая своё "неправильно" никак, кроме субъективных эпитетов, при этом яростно требуя обоснований и разбрасываясь ad hominem-ами.
Но когда вам указывают на неоднозначности си-подобного синтаксиса, вы просто отмахиваетсь. "Ой, most vexing parse уже починили". Ну да, добавив ещё кучку неоднозначностей с разными видами плохо различимых скобок (int foo{} vs int foo()), разных видов инициализации и т.п.
Я лично не имею ничего против сишного синтаксиса — пусть цветёт сто цветов, я спокойно пишу и на C++, и на C#, и на TS, и уважаю и использую их и их фичи, не забывая о косяках. Но вот вас, похоже, конкретно бомбит по поводу якобы "синтаксического мусора" в других языках, и от критики в сторону C. Это просто комично, вы пытаетесь быть святее K&R, что-ли?
паскалятская зараза. Именно его адепты постоянно всё засирают
Какие сволочи. Ну ничего, если вы будете продолжать кидать в них какашками, они обязательно поймут, как они неправы, и как правы вы.
они мечтают сделать свои веру главенствующей.
Эту теорию вам лучше обсудить с вашим лечащим врачом, он лучше знает, что делать с заговорами пасквилянтов о захвате мира.
Хотите, что-бы можно было что-то сравнивать — создайте синтаксис в котором можно выразить аналогичную семантику.
Чего именно принципиально нельзя выразить в паскалеподобном синтаксисе? Голые указатели на голые указатели на массивы, которые под капотом тоже голые указатели? Ещё в паскакале был оператор ^, но теперь даже в плюсах голый указатель — моветон.
Что ещё?
Когда сделаете на паскаль-синтаксисе не-скриптуху. Приходите и поговорим.
Для вас "не-скриптуха" — это что конкретно? Ручная работа с памятью? Макропроцессор для исправления недостатков встроенного синтаксиса?
Моя(условная) вера уже всё доказала.
Ой, не скромничайте, ваша вера совершенно абсолютна.
Конечно не вы. Вы пытаетесь доказать, что «паскалевский стиль говно». Ровно с той же степенью обоснованности.
Где пруфы? Насколько я понял тот факт, что вы ненавидящий си религиозный паскаль-фанатик вами уже признан? Теперь вы хотите оправдать себя через «а Вася тоже в штаны насрал»? Ну хорошо, пытайтесь. Только пруфы где?
«Ой, most vexing parse уже починили».
Опять адепт врёт. В чём тут суть. Есть некий условный сектант, который вещает «зелёный — плохо, непонятно». Мой ответ звучит так: «с чего вы взяли, что зелёный — это плохо? Это ваши религиозные проблемы и меня ваша классификация не волнует. Да и оно уже давно не только зелёное».
Далее, условный сектант начинает вещать «вы аргументируете то, что „оно уже не только зелёное“», что является враньём. Но.
Что пытается сделать условный сектант? Он пытается разрушить основную линию защиты, как и любого человека, которого атакует какой-то адепт секты — отрицание его классификации и мировоззрения. Он пытается врать и болтать эту чушь именно потому, что из неё прямо следует «ты принял, что зелёный — это плохо», но.
Сектант врёт. Я ничего не принимал. Мне насрать на его классификацию и на то, что где и чем называются адепты какой-то секты.
В этом то вся и проблема. Некоторые последователи С++ именно, что могут только «парсить» текст. А забыли, что 99% текст не парсят, а читают. Так вот напоминаю вам что чтением в отличие от «парсения» является процесс восприятия информации слева направо. Поэтому можно написать только лишь предложение «Указатель на переменную хрю-хрю». И это будет для всех текст, только для вас набор слов. И наоброт, предложение «Хрю-хрю на укаказатель переменную » -будет для вас текстом, а для 99% людей набором слов.
И расшифруйте выражение "^hru_hru" — так, чтобы каждому обозначению соответствовало слово.
Дак вы должны это сделать — как я буду читать непонятно какие, придуманные вами, символы?
а теперь прочитайте как все обычные люди слева направо
Как нам разница — как и кто читает? К тому же нужно отличать чтение от понимания. Читать можно как угодно. К тому же, прочитайте мне 123.123. Прочитай мне a + b * (c + d).
Я могу читать как угодно, как и любой другой человек. И все именно так и читают. Читают таблицы сверху вниз, либо таблицы нужно запретить? Ищут ключевые слова в текста. Запоминают контекст.
А теперь попробуйте сделать это c выражением hru_hru*. У вас это не получиться.
Указатель — это тип *, T — это тип возврата операции разыменования. Слева всегда стоит конечный тип. Сишные определения читаются как математические выражения. Вот паста, где я разбирал «как читать».
// Нужно понять фундаментальную вещь - есть база, это некий контекст который расширяют расширятели типов.
//по дефолту база - это то, что справа. Базой любого типа является определение(имя).
typedef int f_t();//функция. База - имя. () - расширяет имя, делая его функцией. Функция теперь является базой.
// Для этой коснтрукции с лева пишется тип возврата:
f; //имя
f0();//функция.
int f1();//функция с типом возврата.
* f2();//функция с типов возврата "указатель".
int * f3();//для int базой является * - определение типа операции *(разименования) у указателя.
typedef int f0_t();//правила аналогичны. Функция.
//хотим сделать указатель на функцию
typedef int * fptr_t();//базой является функция - определяется тип возврата. Указатель.
//нужно как-то определить базу для *, чтобы она была именем. Ведь имя должно быть не функцией(как сейчас), а указателем.
typedef int (* fptr0_t)();//база для * имя. Далее скобки выступают базой.
//определяется тип операции * у указателя. Указатель является базой.
typedef int (** fptr1_t)();//мы определил тип операции * для указателя(который слева от fptr1_t).
// Базой является тип операции * для указателя, которая является типом операции * для указателя, который является типом для fptr1_t
typedef int (** fptr2_t[])();//fptr2_t теперь является массивом. Массив - база. Слева у массива определяется тип элемента массива.
typedef int (** fptr3_t[][7])();//здесь можно просто упростить до "fptr3_t - двойной массив". Двойной массив - база. Свйоства аналогичным одинарному.
typedef int * (** fptr4_t[][7])();//базой является функция. Для неё определяется тип возврата. Мы определили тип возврата - указатель. Далее мы уже знаем. int тип операции * для указателя.
typedef int * (** fptr5_t[][7])()[];//базой является функция. Типом определён указатель. Это не то, что мы хотели.
//мы хотели определить тип не для функции, а для типа операции * у указателя. Нам нужно сделать базой указатель.
typedef int (*(** fptr6_t[][7])())[];//база указатель. Типом для базы определяется массив. Массив база - для базы(массива) определяется тип элемента - int
typedef int * (*(** fptr7_t[][7])())[];//база массив. Для массива определяется тип элемента - указатль. Для указателя определяется тип операции *.
//тут можно вывести два правила. Право имеет приоритет. Для лева - базой является то, что справа. Для права - лево.
int a[1];//имя - база. Справа - массив. База массив. Для него определён тип - инт, как тип элемента массива.
int ((a)[1]);//можно руками определить базы, как это делается по-дефолту.
int * b[1];//b - база. Для неё определён массив. Для массива определён тип(элемента) - указатель. Для указателя определён тип операции* - int.
int (*c)[1];//c - база(имя). Для неё опредён тип - указатель. Для указателя определён тип операции* - массив. Для массива определён тип элемента - int.В этом то вся и проблема. Некоторые последователи С++ именно, что могут только «парсить» текст.
Лозунги такие лозунги.
А забыли, что 99% текст не парсят, а читают.
Я вам привёл примеры — почитайте их. Не нужно путать чтение и интерпретирование. Читать можно что угодно и как угодно, но понимать вы будите так как нужно.
Так вот напоминаю вам что чтением в отличие от «парсения» является процесс восприятия информации слева направо.
Пустые заявления. Да и расскажите это арабам.
Поэтому можно написать только лишь предложение «Указатель на переменную хрю-хрю».
Вы ничего не знаете о си и эта формулировка — полная чушь. Ну и я жду срывов покровов на тему number[], жду чтения () => {}. Ваши рассуждения глупы и догматичны. Во-первых указатель ни на какие переменные не указывает. На этом уже можно закончить и признать вашу несостоятельность, полную.
И это будет для всех текст, только для вас набор слов.
Вы попросту хейтер, который придумал какую-то чушь и ему кажется, что его объяснения что-то объясняют, но нет. Хейтер просто услышал где-то про «паскаль читается, а си нет» и начал выдумывать чушь. Назвав набором слов всё, начиная от математики заканчивая каким-нибудь тайпскриптом.
И наоброт, предложение «Хрю-хрю на укаказатель переменную » -будет для вас текстом, а для 99% людей набором слов.
Это и есть набор слов. Вы пытаетесь рассуждать на тему, в которой ничего не понимаете, приводя идиотские примеры(это даже не примеры, а полный треш). Я отказываю даже читать этот набор слов пока там не будет нормальных примеров с объяснениями — что вообще этот набор слов значит и как он следует из тех же сишных определений.
Потому что если мы принимает порядок "тип имя" для аргументов функций, то для единообразия придётся применять этот порядок везде: при объявлении переменных, членов структур, возвращаемого типа у функции и т.п. И получаются приколы с неоднозначностью типа most vexing parse. Ну вот, например:
Foo foo();
— это объявление и инициализация переменной foo типа Foo, или объявление функции foo() без параметров, возвращающей значение типа Foo?
то для единообразия
Паскаль-стиль не может быть единобразным — он слишком слабый даже для языков уровня js.
И получаются приколы с неоднозначностью типа most vexing parse.
И в чём проблема?
Расскажите мне про прикол с:
(a, b) => c — что это?
А про [a, b, c]?
К тому же, очень наивно ссылаться на проблему, которая вообще не проблема и которую уже решили. И об этом написано по ссылке.
Тем, что таким образом упрощается парсинг языка и исключаются неоднозначные ситуации
Кому, кроме студентов, интересна сложность парсинга? Язык должен быть мощным и удобным, а насколько его сложно парсить — никому не интересно.
исключаются неоднозначные ситуации
Пустой лозунг, который я уже опровергал выше.
Первым всегда идет или ключевое слово или идентификатор.
Опять лозунг. Хорошо оно идёт — дальше что?
упрощает парсинг и делает адекватным использование функций первого порядка.
Парсинг никому не интересен. Чем это использование более адекватно? Что вообще это значит. Опять какой-то лозунг без примеров/объяснений.
В отличие от упомянутых С/С++, где это пытка сплошная.
Опять же, в чём заключается пытка?
Кому, кроме студентов, интересна сложность парсинга? Язык должен быть мощным и удобным, а насколько его сложно парсить — никому не интересно.
Всем, кто потом будет работать с инструментами, которые язык парсят и что-то делают с AST. Таких для Go множество и именно благодаря его однозначному и простому синтаксису. Это ускоряет и сам процесс парсинга, что полезно вообще всем.
Пустой лозунг, который я уже опровергал выше.
Никакого опровержения не заметил. Отсутствие неоднозначности в синтаксисе языке несет за собой далеко идущие преимущества. И Go этому яркий пример.
Опять лозунг. Хорошо оно идёт — дальше что?
То, что парсить легко. Дальше логику сами можете достроить.
Опять же, в чём заключается пытка?
В том, что в С/С++ синтаксис указателя на функцию ужасен, нечитабелен, сложен для написания и полностью отличается от того, как функции объявляются. Чего стоит только необходимость включения имени переменной в сам тип вроде int(*foo)(). В Go объявление функции, объявления типа указателя на функцию, передача функции как объекта первого порядка — все это идентичные синтаксически вещи, что значительно упрощает чтение и написание кода. Авторы Go к этому стремились, делая такой синтаксис, и они своего добились. Помимо этого, С++, будучи заложником своей извращенной грамматики, придумал тот ужас, которым называют лямбды в этом языке. Тоже самое в C# том же, хоть и не настолько ужасно.
Вы уперлись в какие-то ваши странные представления о том, какой должен быть язык, не понимая, что С/С++ и им подобные это одни из худших примеров с точки зрения синтаксиса. Поэтому не случайно языки нынче выбирают совершенно иную логику, в том числе «идентификатор: тип», func/fun перед функцией и прочее и прочее. Люди наелись проблем этих языков и не хотят тащить теже самые проблем себе, только потому что все привыкли и вроде как все в порядке уже.
Всем, кто потом будет работать с инструментами, которые язык парсят и что-то делают с AST. Таких для Go множество и именно благодаря его однозначному и простому синтаксису. Это ускоряет и сам процесс парсинга, что полезно вообще всем.
Попросту враньё. Инструментов по статическому анализу С++-кода больше и они куда как мощнее и качественнее, чем для го. Никакой С++ парсить ненужно.
К тому же, это враньё ещё и тем, что в го нужны парсеры потому, что язык крайне примитивен и ничего не может. От того и нужнается в кодогене и тысячах костылях, для обхода отсутствия тех же генериков.
Никакого опровержения не заметил. Отсутствие неоднозначности в синтаксисе языке несет за собой далеко идущие преимущества. И Go этому яркий пример.
Т.е. у вас ничего, кроме лозунгов, нет? Где преимущества, в чём преимущества? Го в сравнении с тем же жаваскриптом/тайпскриптом — пыль. Я уж не говорю про С/С++. Что мне показывает пример го? Да ничего.
То, что парсить легко. Дальше логику сами можете достроить.
Ну то, что ваши тезисы — глупые лозунги я понял уже давно. Вы не на баррикадах и лозунги в данном случае котируются мало.
В том, что в С/С++ синтаксис указателя на функцию ужасен
Примеры. Зачем мне лозунги? Конкретно. Берёте идентичный код и пишите его на го и на С++.
нечитабелен
Опять лозунги?
сложен для написания и полностью отличается от того, как функции объявляются.
Вы ведь ничего не знаете. Функция объявляется так же.
Чего стоит только необходимость включения имени переменной в сам тип вроде int(*foo)().
У вас явно лозунги плывут. Функции в си записывается как int(foo)(); Указатель записывается как int(* foo)(); То, что вы этого не знаете — это проблему. Узнайте/спросите перед тем, как делать далеко идущие заявления.
В Go объявление функции, объявления типа указателя на функцию, передача функции как объекта первого порядка — все это идентичные синтаксически вещи, что значительно упрощает чтение и написание кода.
Опять лозунги. Приведите пример.
Авторы Go к этому стремились, делая такой синтаксис, и они своего добились.
Это настолько нелепые заявления. Синтаксис го не может и 10% того, что может синтаксис си в С++, в том же C#. Зачем сравнивать несравнимое?
Это примерно как рассказывать, что у мышки 3 кнопки, а у клавиатуры 100. Вот ведь какая клавиатура плохая — кнопок много. Авторы мышки стремились сделать такое кол-во кнопок(малое) и они добились этого.
Все ваши рассуждения — пустые общие слова, которые ничего не значат.
Помимо этого, С++, будучи заложником своей извращенной грамматики, придумал тот ужас, которым называют лямбды в этом языке. Тоже самое в C# том же, хоть и не настолько ужасно.
Она извращённая лишь потому, что вы где-то это услышали? Сильная аргументация.
И да, у вас опять лозунг потёк. Покажите мне эквивалент С++-лямбды на го, либо на другом языке.
Есть другой подход: compiler as a service, как это сделано в C#/TypeScript.
Именно этим и занимается clang уже 10лет. Да и уже лет 20 есть gcc-xml, которого для базовых вещей вполне хватит. Причём лучше, чем упомянутые выше случаи.
Тут двойной факап. И упоминания С++, который находится в авангарде «compiler as a service» и догматическая уверенность в одном избранном случае.
function<void(int,float)> func_ptr;
Главная миссия дизайна языка —… чтобы он был прост и понятен как для человека, так и для компьютера.
Паскаль же вроде давно придумали, зачем снова разводить «зоопарк»???
Крайне занятная задумка со стринг-типами, хотя слишком сыро и конкретно – надо расширить на систему типов по возможности (я вижу отличное применение такому функционалу – он вполне может
Также интересно отсутствие UB, но это не гарантирует, что программа будет себя вести, как задумано. Более того, никто ещё не видел ошибки реальных программ, а это очень важно – всегда придерживался и придерживаюсь мнения, что максимум ошибок надо ловить в компайлтайме.
Общее впечатление: симпатичный синтаксис (а больше пока ничего и нет), вангую проприетарный майкрософтовский F# x переRust.
function foo(var ref bar/*Тип указан только для второй переменной, в то время, как тип первой выводится*/, ref strategy: Int) /*Тип возвращаемого значения выводится сам*/
{
bar += 1;
//Ошибочный код:
//strategy += 1;
return bar;
}
Что в принципе миленько – возможность контроля типов получаемых и возвращаемых значений функции, как и их модификаторов.
А в чём смысл дублирования слова ref словом var? И почему нельзя написать просто strategy: Int, без ref?
Я провожу аналогию в меру своих знаний, а именно:
На плюсах можно написать:
/*void foo*/
(int a)
(int& a)
(const int& a)
Что будет значить три разных вещи. 1 – int скопируется новой переменной. 2 – будет передан мутабельный параметр по ссылке. 3 – передастся ссылка на константную (то есть, неизменяемая, она же мутабельная) переменную (константную ссылку на переменную, но не суть).
Имеем:
ref strategy: Int –> const int& strategy
strategy: Int –> const int strategy
var ref bar –> template T& bar
ref bar –> template const T& bar
Почему я использую ref для strategy – привычка, больше скажу, я консты не всегда пишу, и потому всеми конечностями за иммутабельность по умолчанию
В том же C++ константные ссылки используются, как правило, для оптимизации; но в современном языке такую оптимизацию лучше поручить компилятору.
Таким образом, константные ссылки — не нужны, и остаётся всего два типа передачи параметра: по значению и по изменяемой ссылке. Именно второй способ и достигается при помощи слова ref.
Т.е. если у меня на руках «тяжелый» константный объект, который хочется отдать как параметр в функцию, то константные ссылки — это хорошая вещь.
int main(void)
{
const int i = 0;
++i;
//Всё как мы и ожидали, ошибка компиляции «expression must be a modifiable value»
}
Const – имхо не самая сложная тема при изучении С-подобных языков.
объект «иммутабельный» внезапно из стула не превратится в верблюда, потому что кто-то снаружи что-то внутри него дернул
Вы апеллируете к многопоточному программированию?
В таком случае, это вопрос организации взаимодействия и разделения данных между потоками.
Решил продемонстрировать, как я это вижу:
#include <thread>
#include <chrono>
int func(const int& x)
{
std::this_thread::sleep_for(std::chrono::seconds(1));
if (x < 1)
return -1;
else return x;
}
int main(void)
{
/*const*/ int i = 1;
std::thread thr(foo, i);
++i;
thr.join();
}В такой ситуации закомментированный const как раз снимает вопрос.
Если он 1 – то программа выполняется построчно, и пока поток выполнения находится в функции, объект назван его формальным параметром, то есть условно const int& x.
Если же их более, чем 1 – переменная действительно может измениться, ну тут уже смотрите, чтоб не было гонок.
Мы обсуждаем странное понятие иммутабельности – позвольте уточнить, что иммутабельные данные – это не коробка байт, которые не изменятся, даже если подача тока прекратится/коротнёт. Это коробка байт, которую можно открыть и посмотреть, но не трогать байты руками.
Если же мы обсуждаем изменение данных «извне» (напр., тупую ассемблерную подмену данных тем же артмани), то для того, чтоб программа корректно(?!) обрабатывала такие изменения, придётся использовать продвинутые техники.
И чего вы к потокам привязались. Потоков может быть один, но код асинхронным. И запросто получишь ситуации, когда у тебя под ногами изменился объект. В современных языках с async/await и всеми этими вашими горутинами это обычное дело.
Потоки тут ни при чём. Берем функцию add_mul, с сигнатурой void add_mul(big_number &s, big_number const& a, big_number const &b) // s += a*b (на олимпиадах я такую любил, ибо элементарная операция), пишем add_mul(x, x, y) // x += x*y и приплыли. Поток всего один, но это не помогло.
В такой ситуации закомментированный const как раз снимает вопрос.
А хотелось бы ошибку компиляции при "не снятом" вопросе...
// 5.15 Merge
var t = @[ 1, 2, 3 ];
t<+(@[5]) //@[1, 2, 3, 5]
t<+(@[3, 5]) //@[1, 2, 3, 3, 5]
var r = @{ f=1, g=2, k=true };
r<+(@{g=5}) //@{f=1, g=5, k=true}
r<+(@{g=3, k=false}) //@{f=1, g=3, k=false}
r<+(@{g=5, h=0) //@{f=1, g=5, k=true, h=0}
var e = Baz@{ f=1, g=2, k=true };
e<+(@{g=5}) //@{f=1, g=5, k=true}
e<+(@{g=3, k=false}) //@{f=1, g=3, k=false}
e<+(@{g=5, h=0) //error field not defined4) Вызов функций можно делать с указанием названия аргументов из сигнатуры функции, например: myfunc(x=1, y=2)Я правильно понял: вызов myfunc(x=1, y=2) полностью эквивалентен вызову myfunc(y=2, x=1) и вызову myfunc(1, 2), но не вызову myfunc(2, 1)? Кажется такое было в ассемблере OS 360/370 и то в макро. В каких других ЯП есть такое?
Чувствуется, MS решили запилить свой K# (как они запилили С# в ответ на Java). По мне — так лучше бы F# развивали, «отвязав» его от необходимости быть «совместимым» с С#.
function myfunc(x: integer=1; y : real=2.0) : real;myfunc(y =3.16);myfunc(3.16);для параметра с уникальным типом в данной функции.
Все значения в Bosque являются неизменяемыми (immutable)
Ну наконец-то они создали такой язык (F# не в счет).
Язык Bosque — новый язык программирования от Microsoft