Comments 715
>Сложно
Да ладно, правда что-ль? Ну вот серьезно, неужели упомянутые вами же статьи типа … монады в картинках не дали вам никакого практического понимания? Что вы книги по теории категорий не поняли (не сразу) — охотно верю (сам такой), но есть же разные тексты, и их много хороших. Или вы хотите чтоб все и сразу, и в одном тексте?
Я это не ради критики, если что. Мне скорее мотив автора хочется понять. Ведь было уже много текстов, и таких тоже (на мой взгляд таких).
Ну, да. Хотя на мой взгляд это не все детали отражает. Тут еще важно, что такое контейнер… что он владеет информацией о своей структуре, а функции из map этого знания не дают, и главное что ей его иметь и не нужно. Только контейнер знает, что он дерево — или список.
Это же вроде вполне естественно? Ведь у вас же было понимание и ленивости, и контейнеров?
Да ладно, правда что-ль? Ну вот серьезно, неужели упомянутые вами же статьи типа … монады в картинках не дали вам никакого практического понимания?
Лично мне — возможно какое-то и дали, но назвать это пониманием можно лишь с натяжкой. Точно так же, как прочтение про абстрактный паттерн фабрика позволяет понять, что «ну он что-то там создаёт», но не позволяет прочувствовать, где, как и когда его полноценно применять, особенно если сложность проекта выше, чем манипуляции с числами и вводом пользователя.
До сих пор не могу сказать, что понимаю монады с математической точки зрения, но как условный паттерн программирование начал их понимать исключительно после того, как сам написал несколько примитивных и на практике посмотрел на разницу кода с ними и без них. Возможно, это мне не хватает воображения и абстрактного мышления, но я всячески приветствую подобные статьи и очень надеюсь, что со временем ФП будет всё больше и больше проникать в индустрию.
Правда, не могу сказать, что всё так радужно, ведь ФП приносит новые проблемы. К примеру, иммутабельные структуры (поправьте, если не прав) требуют наличия линз или схожих механизмов для удобной работы с ними. В языке, где их изначально нет, получается интересная ситуация, когда вроде как иммутабельные структуры это хорошо и все согласны, но вот фреймворк сериализации с ними не работает, ОРМ — не работает, генератор фейковых данных для юнит и интеграционных тестов — не работают.
Пишу 20 лет на ФП и никаких проблем ФП мне не принес. И сериализация и ОРМ все отлично работает.
Вы пишете 20 лет на языке, в котором изначально не было полноценных иммьютабл структур данных и средств работы с ними, и у вас ни один из компонентов экосистемы не имеет с ними проблем? Искренне завидую, у меня всё не так просто. Не подскажете, что за язык?
Фреймворки работают, но вот удачи обновить поле другого поля структуры, находящейся в каком-нибудь дереве или списке.
Что ни говори, без линз работать с иммутабельностью — больно.
data Foo = MkFoo Int String String String String String
data Bar = MkBar Foo Int String Int String Int String String
fixNthFoo :: [Bar] -> Int -> Int -> [Bar]
fixNthFoo xs position value = undefinedКак реализовать функцию fixNthFoo чтобы в i-м Bar поменять у Foo значение на value? Ну то есть то, что мы на расте каком-нибудь могли бы написать
fn fix_nth_foo(bars: &mut Bar, position: usize, value: i32) {
bars[position].foo.int_value = value;
}Ну запишите на чем угодно. Немного проспойлерю с линзами будет вот так:
fixNthFoo :: [Bar] -> Int -> Int -> [Bar]
fixNthFoo xs position value = xs . ix position . foo . intValue .= valueПокажите, как без линз на любом языке на ваш выбор на иммутабельных структурах это можно написать в одну строчку.
Я так понимаю, что-то вроде этого:
newBars = bars.With(
pos, bars[pos].With(
foo: bars[pos].foo.With(
int_value: newValue
)))
Да, линзы это и есть реализация этих With. Если у вас есть фреймворк который в общем случае позволяет такое записать, то это и будут линзы. Как вы сами при этом их называете — не важно.
Ну уж нет, эти With с линзами рядом не стояли. Обратите внимание как приходится дублировать префиксы: bars, bars[pos], bars[pos].foo...
К слову, в Хаскеле тоже With есть, притом с языковой поддержкой, но линзам существовать это не мешает.
Да, в правы. Но в принципе какое-то переиспользование кода такой подход даст.
With, а их обобщение.Ну вот как пресловутая полугруппа — это обобщение операции
+ (причём если вы про понятие знаете, то у вас уже не будет вызывать отторжение тот факт, что этот оператор сильно по разному ведёт себя со строками и с целыми числами… и, внезапно, станет понятно — что именно «не так» с «плавучкой»).Людей нужно учить ФП идя от примеров к общем понятиям. А не спускаясь от теории категорий к реальному миру.
Ну уж нет, эти With с линзами рядом не стояли.Стояли-стояли. Именно что рядом.
Вот пока монады начинающим будут описываться не на разнице между
a().b().c() и a()?.b()?.c(), а на языке теории категорий — до тех пор ФП и будет являться, с точки зрения «непосвящённого», такой особой религией, а не чем-то практически полезным.Ну нельзя учить дошкольника арифметике, стартуя с аксиом Пеоно!
Человек сначала должен понять почему
-1 * -1 = 1 — это удобно и естественно (на примерах типа: если вам «простили» долг в один рубль, то теперь это сэкономленный рубль можно отнести в магазин) — а уже потом можно и про аксиоматику рассказать.А часто и вообще можно и без аксиоматики…
do
a <- getData
b <- getMoreData a
c <- getMoreData b
d <- getEvenMoreData a c
print dПриводится как универсальный ответ на все кейсы.
Разумеется не все в мире задачи записываются в виде монад… но те что записываются — выглядят вот именно так.
Ну вот рассмотрите более простую вещь: аппликатив.
Сложить 2 и 2 (и получить 4) — это через "+". Сложить «2» и «2» (и получить «22») — это тоже через "+".
От чего зависит «разница под капотом»?
Это тогда получается, что сначала проект должен был быть написан на не-ФП-языке, а потом всё выкинули и переписали на ФП-языке. Такие случаи мне неизвестны.Всё гораздо хуже. Спуститесь на ступеньку вниз и подумайте над другим примером: переходе с ассемблера на языки структурного программирования (неважно даже: BCL, C или Pascal).
Даже если проект и переписывается с ассмеблера на C — это, всё равно, выглядит как написание нового проекта с нуля… и человеку не умеющему в структурное программирование бывает очень сложно объяснить «зачем».
Вот встроить в проект высокого уровня кусочек на ассемблере — обычно без проблем. А вот «поднять» проект на более высокий уровень — нужно переписывать почти всегда…
Ну вот вы работаете с интами, которые приходят по сети по текстовому протоколу (HTTP)? Вот как вы гарантируете, что строки которые вам приходят — это числа?
Просто в какой-то момент парсите строки где надо, но везде в программе у вас статически проверяются что там где ожидаются инты передаются инты.
replacenth(L,Index,NewValue) ->
{L1,[_|L2]} = lists:split(Index-1,L),
L1++[NewValue|L2].
1> replacenth([1,2,3,4,5],3,foo).
[1,2,foo,4,5]
Вот пример со списком в Erlang.
Это вы сделали bars[position] = foo. А вас просили заменить поле на третьем уровне вложенности.
Так у вас тут список целых чисел, а у нас речь про список объектов, причем нам нужно заменить поле одного из подобъектов. Можете полный пример привести? Причем конечно надо учесть, что у обьетов есть и другие поля, которые трогать не надо (У Foo ещё 5 стринговых полей каких-то, у Bar тоже разные другие есть)
Что со списками, что с tuple идея та же самая, конструируете новый элемент с нужными полями.
Объект — структура с полями, поля можно доставать через проекции. Ну или просто HList фиксированного размера с проекциями на каждый элемент, если вам так больше нравится. Или рекорды, если нравится больше именно так. В общем, как ни говори, суть одна.
Что со списками, что с tuple идея та же самая, конструируете новый элемент с нужными полями.
И что, это не займет километр кода? Если не займет, то можно пример? Если займет, то это неюзабельно и является пресловутыми проблемами ФП без линз
Если займет, то это неюзабельно и является пресловутыми проблемами ФП без линз
Тут важно, что значит «без линз»? В том же Elang «нарисовать» линзу (как пару fget/fset) — вообще не проблема… вот только пользоваться ей не сильно удобней (в смысле синтаксиса). «Объектов»-то нет… все честно :-) И record'ы, в этом смысле, это просто «сахарок» над кортежами…
В том смысле, что в случае хоть какой-то вложенности цепочка «линзовых» get/set'ов настолько же «удобна», как и спец. синтаксис record'ов.
А для того чтобы иметь возможность писать более менее «по-человечьи» — что-то типа dot notation с «присваиванием» (его, кстати тоже нет… все по взрослому :-) ) на конце — уже нужен parse transform. А во что именно «разворачивать» pt — дело, внезапно, десятое… в спец. синтаксис даже проще :-)
Вот и получается, что lens-фреймворков в Elang «очень даже есть», но, на практике, пользуют — если уж прям так «ломает» от спец. синтаксиса — pt либы, а не их.
Так сила линз как раз в том, что это просто функции и там не нужен отдельный синтаксис
Так сила линз как раз в том, что это просто функции и там не нужен отдельный синтаксис
Ф-ции для работы с кортежами (element/setelement) в Erlang и так есть. И от того, что ты сделаешь какой-нибудь
-record(lens, {get, set}).
make_lens(N) ->
#lens{get = fun(R) -> element(N, R) end,
set = fun(V, R) -> setelement(N, R, V) end}.
Пользоваться ими сильно удобнее не станет. И даже если где-нибудь «рядом» будет какой-нибудь
compose(Fs) ->
lists:foldl(fun(F, G) -> fun(X) -> F(G(X)) end, fun(V) -> V end, Fs).
это мало что изменит в плане «удобства использования» :-)
уже нужен parse transform
Так не нужен. Вон в хаскелле никакого parse transform и всё работает. Причем это не сахар к которому не подкопаться, а функции, которые можно дальше расширять/композировать/...
А записывать «в столбик» и в Erlang никто не запрещает. Но оно… как там… «неюзабельно» практически. Что с линзами, что без.
Т.е. тут «рулят» не столько линзы — сами по себе, сколько синтаксис композиции.
Вы пытаетесь повторить свой опыт из процедурных языков в ФП, сделать кальку. На практике такой необходимости нет. Мне еще ни разу не приходилось по индексу обращаться к полю записи.
А кто тут говорит про обращение к полю записи по индексу?
Индекс в массиве/списке/где-то ещё. Это не индекс поля записи.
Нет, не идёт.
Тем, что он не полный.
Смысл тут ещё как меняется. Напоминаю, что вы ответили на комментарий о сложностях с обновлением вложенных структур данных. Никто не спорит же, что простые структуры данных и обновлять просто.
Но вы не можете опровергнуть сложности с обновлением вложенных структур демонстрируя обновление простой структуры.
Фреймворки работают, но вот удачи обновить поле другого поля структуры, находящейся в каком-нибудь дереве или списке.
Что ни говори, без линз работать с иммутабельностью — больно.
Я не говорил что это просто, я говорил что не понимаю проблемы обновления иммутабельных структур. Все программы которые вы пишите — это про работу с данными, структурами какими-то сложными, если бы так просто было все, зачем тогда такие развесистые программы писать. Вы в процессе написания сложность стараетесь спрятать куда-то внутрь, упростить манипуляцию с данными.
Ну вот и напишите как выглядит обновление вложенной иммутабельной структуры с тремя уровнями вложенности.
Однако, то, сколько усилий вы прилагаете чтобы ни в коем случае не показывать никому этого кода, как раз и доказывает, что там всё далеко не так просто.
Писать фигню, не проверив на работоспособность, я не хочу
Ну это косвенно доказывает мою правоту, ведь в том чтобы написать однострочник на расте или хаскелле много времени не понадобилось, и его корректность тоже не вызывает сомнения хотя бы потому что кода мало и ошибиться в нём негде.
Зато можно ошибиться в 10-строчном сниппете, который вручную пытается восстановить record неизвестной структуры на третьем уровне вложенности.
Обращение к полю происходит по имени, а не по индексу. foo, int_value из примера на Rust — это как раз имена полей.
index(FiledName, record_info(fields, RecordName)) + 1
На всякий… в Erlang — «по честному» есть только кортежи… у полей которых, понятно, имен нет. Имена полей есть у т.н. record'ов.
А как же maps?
with(L, Predicate, Map) ->
fold(fun(Index, Elem, Acc) ->
case Predicate(Index, Elem) of
false -> [Elem|Acc];
true -> [Map(Elem)|Acc]
end
end, [], L).
P.S. Позор на мои седины… стандартный fold же без индекса.
Но это поправимо:
fold(F, Acc, Index, [H|T]) ->
F(Index, H, fold(F, Acc, Index + 1, T));
fold(F, Acc, _, []) -> Acc.
fold(F, Acc, L) ->
fold(F, Acc, 1, L).
Вроде так :-)
Что-то в вашем примере я не вижу ни foo, ни bar. Да и вообще код делает настолько не то, что просили, что не даже отличий найти не получается.
with([1,2,3,4,5], fun (Idx, _) -> Idx == 3, fun(_) -> foo).
Так понятней?
Это вы к первому примеру вернулись. А дальше-то что?
Это вы к первому примеру вернулись.
В смысле?! Реализация with — это больше ответ на:
Как реализовать функцию fixNthFoo чтобы в i-м Bar поменять у Foo значение на value? Ну то есть то, что мы на расте каком-нибудь могли бы написать
Оно — конечно — чуть более универсальнее получилось, чем… но, суть от этого не поменялась. Т.е. этот with делает — в том числе — и то, что replacenth. По сути — вся разница в том, что NewValue — это ф-ция от (чтобы можно было кортежами/рекордами рабоать)… ну и «индекс» задается через предикат… чтоб не только по числовому индексу можно было заменять.
Согласен Erlang не такой уж и функциональный.
?! В каком смысле, если не секрет? Или это какая-то такая хитрая ирония?
ETS реализует видимость глобального состояния и параллельного доступа, но на самом деле очередь запросов синхронная, а данные хранятся локально в памяти потока, порождающего ETS.
Глобальное состояние — это когда два и более потоков могут одновременно что-то записать в одну область памяти (переменную). Тут этого нет, потому что все операции поверх ETS синхронные, атомарные и изолированные (в силу того, что несмотря на всю свою асинхронность, Erlang строго синхронный язык)
Mnesia же такое же глобальное состояние, как и любая DBMS или обертка для хранения данных на диске. Формально да, для приложения Mnesia хранит данные глобально, но каждый процесс все равно получает свою копию данных, и все еще не может интерферировать с данными других процессов.
Я не исключаю, что могут быть какие-то неизвестные мне особенности языка, которые позволяют стрельнуть другому потоку в ногу (кроме бинарников, про них в курсе)
Erlang параллельный, когда работали на одном процессоре, была псевдопаралельность, планировщик распределял очередь заданий, а сейчас много ядер, много процессоров, и параллельность реальная.
Функции не чистые, тут я не спорю.
О параллельности. Тут все просто и изящно. Да, приложение, запущенное на двух и более процессорах, способно выполнять потоки Erlang параллельно. Но каждый поток при этом работает последовательно.
Потоки взаимодействуют через посылку сообщений, и мейлбокс каждого процесса обрабатывается процессом последовательно, сообщение за сообщением.
Поэтому даже в мультипроцессорной среде запросы в ETS остаются атомарными и изолированными, а ETS все больше превращается в bottleneck (с ростом количества запросов)
Да, в Erlang разделение, но не времени, а единиц выполнения. Вот тут неплохо вкратце описано: jlouisramblings.blogspot.com/2013/01/how-erlang-does-scheduling.html
В Erlang есть глобальное состояние ETS,Mnesia.
Ни ETS, ни уже тем более Mnesia — которая лишь «фасад» для DETS, не являются «глобальным состоянием». Это отдельные процессы, со всеми вытекающими…
А «глобальное состояние» в Erlang действительно есть… это т.н. «словарь процесса». Но его использование — на практике — весьма ограничено. В первую очередь, безмерной радостью неизбежной «отладки в уме» :-) В то смысле, что — на практике — оно используется только если «действительно надо», выносится в отдельный процесс и «есть не просит».
Сам Erlang не накладывает на вас каких-то обязательств по его использованию, не используйте ETS, пишите чистые функции.Ф-ция, использующая внешний — по отношению к вычисляющему её — процесс (будь то ETS/Mnesia, или какой-либо ещё), вполне себе чистая ф-ция. С чего вы взяли, что нет?!
Ф-ция, использующая внешний — по отношению к вычисляющему её — процесс (будь то ETS/Mnesia, или какой-либо ещё), вполне себе чистая ф-ция.
Нет, это уже совершенно точно не чистая функция. Любое обращение к внешнему процессу — побочный эффект, и, как следствие, никакой чистоты.
Обычно рассматривают категорию типов
Ключевое слово тут «обычно». Если бы я стремился написать статью «как обычно», то я бы ее не писал, а просто поставил ссылку на одну из сотни статей по теме. Моя цель была в том, чтобы дать привязку к понятным «сишнику» терминам и примерам. Категория типов — на одну ступеньку абстракции выше, чем категория-тип. Поэтому этот пример понять намного проще. А от него уже двинуться дальше по ступенькам абстракций.
У сишника/джависта, боюсь, после этих объяснений будет очень неправильное представление о том, что такое теоркат и что он изучает.
Дайте сишнику потрогать шарики и кубики, а потом задвигайте про обобщения.
Только это две разных и совершенно неэквивалентных функции. map куда слабее, и функтор умеет map, но не умеет bind. И существуют типы, которые являются функторами (и даже аппликативными функторами), но не являются монадами — ZipList как пример.
Еще раз: не надо объяснять, что бочка — это не цилиндр, а куб — это не ящик. Вы просто уже перебрались через эту пропасть непонимания. Я же строю мостик для тех, кто еще не по «ту сторону».
Пожалуйста, объясняйте не как обычно, но "функтор" тогда в вашем объяснении это не тот "функтор", который используют все остальные люди. Ваш функтор между категорией Int в категорию Double это всего лишь функция, возможно от этого и остальное недопонимание того, чем что является.
Ну вот вы пишете:
Функтор – обработчик данных в контейнере-монаде. Функтор без монады – деньги на ветер.
Какой обработчик данных в контейнере-монадке в эндофункторе в категории Int?
Или второй вопрос, из вашей фразы следует, что функтор обработчик ДЛЯ монады, в то время как между ними не отношение ВКЛЮЧАЕТ, а отношение ЯВЛЯЕТСЯ, то есть наследование, а не композиция. Определение запутывает и дает неправильное представление, в итоге.
между ними не отношение ВКЛЮЧАЕТ, а отношение ЯВЛЯЕТСЯ, то есть наследование, а не композиция.
Да, верно. Но функтор в реальности — это одна функция map в классе. Поэтому я позволил себе вольность применить аналогии композиции, т.к. конечный результат одинаков в любом случае.
Какой обработчик данных в контейнере-монадке в эндофункторе в категории Int?
Соответственно, на этот вопрос можно ответить, если рассматривать функтор — как функцию map внутри монады (т.е. как ее поведение), а не как предок монады. Это не совсем корректно, признаю. Но для понимания на начальном этапе, мне кажется проще их отделить друг от друга. Я пока не придумал более корректной аналогии их отношения при сохранении интуитивности.
Да, верно. Но функтор в реальности — это одна функция map в классе. Поэтому я позволил себе вольность применить аналогии композиции, т.к. конечный результат одинаков в любом случае.
Функтор в реальности — это тайпкласс, и для типа его реализуют. В чем разница между функцией и интефрейсом (тайпклассом), в котором есть такая функция, думаю, объяснять не надо.
Соответственно, на этот вопрос можно ответить, если рассматривать функтор — как функцию map внутри монады (т.е. как ее поведение), а не как предок монады. Это не совсем корректно
Совсем некорректно *
.
У сишника/джависта, боюсь, после этих объяснений будет очень неправильное представление о том, что такое теоркат и что он изучает.А и не пофиг ли? Задача ведь не «посвятить в тайну», а «научить этим пользоваться»!
Уверяю вас: очень малый процент разработчиков на C++ или, тем более, JavaScript способны описать на строгом математическом языке что они, всё-таки, делают.
Тем не менее библиотеки они пишут и обновляют… а на Haskell — сплошной Жванецкий: «телевизор прекрасный, подпаяй там какой-то пустяк и отдыхай, смотри»…
Знаете, я вот монады понимаю, даже трансформеры вроде осилил, но картинки вроде этой
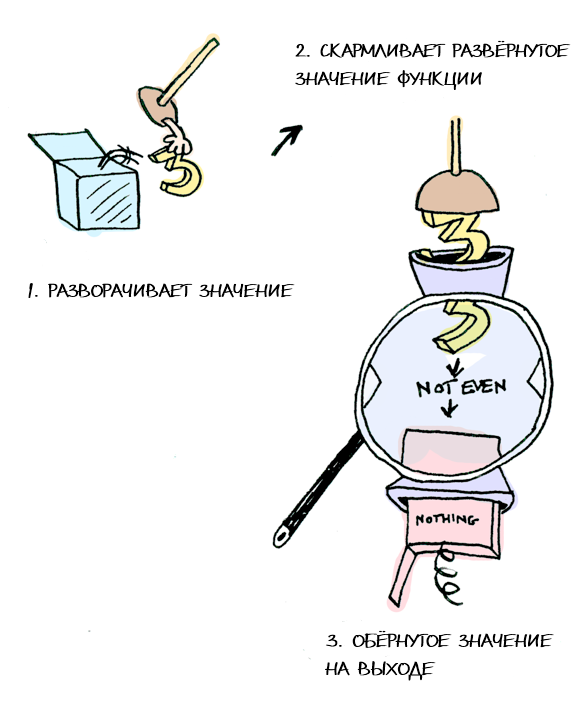
Даже мне читаются с трудом
После прочтения ряда статей:
- Функторы, аппликативные функторы и монады в картинках
- Монады как паттерн переиспользования кода (Очень понятная и вдохновляющая статья)
- Understanding map, apply, bind
я думал, что я понял. После прочтения этой статьи я уже нихера не понимаю.
Категория – любой примитивный или составной тип данных...
Я, как очень плохо учивший математику, понял категорию как некое обобщение над множествами, а сами множества являются одной из категорий (Set). А тип, вроде как, как раз укладывается в теорию множеств, как множество всех его допустимых значений. Так тип категория или нет?
Честно говоря, объяснение в порядке "функтор — аппликативный функтор — монада" понятнее, хотя, возможно, я его понял неправильно.
Функтор — отображение морфизма из одной категории в другую. Кстати, о map. После некоторых размышлений мне стало казаться, что название функции означает не то, что она применяет некую функцию к контейнеру (как мы привыкли во всех языках, где есть map), а именно отображение функции в другую категорию. Например, отображает морфизм "+" в категории чисел, в категорию "Maybe чисел". Мне это (либо очень очевидное, либо очень неправильное) понимание пришло в голову, если рассмотреть сигнатуру не как привычную функцию с двумя аргументами map(f, container) -> container, а как каррированную:
fmap:: (a->b) -> fa -> fbЯ прав?
Аппликативный функтор. А вот тут непонятно. Не, смотришь на картинки, на код, это, вроде, тоже самое, но для двух аргументов в контейнерах. Но что-то непонятно. Ладно, вот еще картинки с описанием. Это когда функции в контейнерах и аргументы в контейнерах. Понятнее не стало, да еще и не совпадает.
Монада. Такая штука, которая, в отличие от функтора, умеет работать не только с функциями a -> b, но и a -> m b:
bind :: m a -> (a -> m b) -> m bВроде бы, понятно, зачем оно нужно. И понятно, какую проблему (по сравнению с функтором) решает эта сигнатура, на примере тех же Maybe очень понятно. Вот мы имеем цепочку каких-то функций, каждая возвращает Maybe, их друг с другом биндим, все очень круто. А вот почему монада — контейнер? То, что условный Maybe/Option/Nullable итп контейнеры — понятно. Зачем bind при работе с контейнерами — понятно. Но что-то интуитивного понимания нет. И еще почему "монада позволяет описать последовательность" (или что-то в этом роде)?
З.Ы. Монада — тайпкласс. "Что-то" реализующее некие определенные методы является монадой. И "что-то" имеет какие-то данные, реализуем "интерфейс" (в курсе, что это очень грубая аналогия) монады (имея знание о структуре данных), чтобы функции, работающие с монадами, могла работать с нашим типом. Окей. Но с таким же успехом и функтор — контейнер, нет?
После прочтения этой статьи я уже нихера не понимаю.
Потому что автор ничего не понял, и пытается запутать остальных, давая намеренно некорректные утверждения, лишенные какой-либо логики.
Так тип категория или нет?
Нет. То, что вы написали до того, верно.
Мне это (либо очень очевидное, либо очень неправильное) понимание
Это очевидное и правильное понимание. Вы правильно поняли смысл функторов. Вы лифтите функцию int -> string, чтобы она работала с Maybe int -> Maybe string. Вы можете записать fmap как fmap (a -> b) -> (f a -> f b).
Аппликативный функтор. А вот тут непонятно.
Обычный функтор берет чистую функцию и преобразовывает ее так, чтобы она принимала обернутые значения.
Аппликативный функтор берет обернутую функцию и преобразовывает ее так, чтобы она принимала обернутые значения. Т.е. аппликативный функтор лифтит функции, не разворачивая их.
А вот почему монада — контейнер?
А она и не контейнер. Она, как вы верно заметили, вычисление. То, что некоторые монады могут быть представлены как операции над контейнерами (хоть это, имхо, и сбивающая с толку аналогия, приносящая больше вреда), не делает саму монаду контейнером.
Но с таким же успехом и функтор — контейнер, нет?
Если рассматривать неверные аналогии, то функтор куда ближе к контейнеру, чем монада.
Благодарю за разъяснения
А она и не контейнер
Тоже об "контейнер споткнулся". Если уж так хочется обобщений, то конвейер, а не контейнер.
Конвейеры бывают разные, со своими правилами — но одном, к примеру, бракованные машины сразу снимаются и направляются в зону обработки исключений. На другом — проводят операции только над полными машинами, пустые игнорируют. И т.п.
Вот только не уверен, что такая аналогия будет проще и правильнее, чем "абстракция последовательных вычислений".
Я, как очень плохо учивший математику, понял категорию как некое обобщение над множествами, а сами множества являются одной из категорий (Set). А тип, вроде как, как раз укладывается в теорию множеств, как множество всех его допустимых значений. Так тип категория или нет?
Категория — это класс (про себя неформально можно считать "множеством") объектов, между которыми есть морфизмы. Строго говоря, сами объекты можно заменить на id-стрелки, тогда получится, что категория состоит только из морфизмов. Пример категории — Set, объекты категории — разные множества, морфизмы — отображения между этими множествами.
Другой пример — категория типов с плавающей точкой, объекты — {Float, Double}, морфизмы — все возможные функции вида Float -> Double и Double -> Float между ними.
Мне это (либо очень очевидное, либо очень неправильное) понимание пришло в голову, если рассмотреть сигнатуру не как привычную функцию с двумя аргументами map(f, container) -> container, а как каррированную:
Ну так и есть, можно посмотреть на картинки бартоша, они так и рисуют:
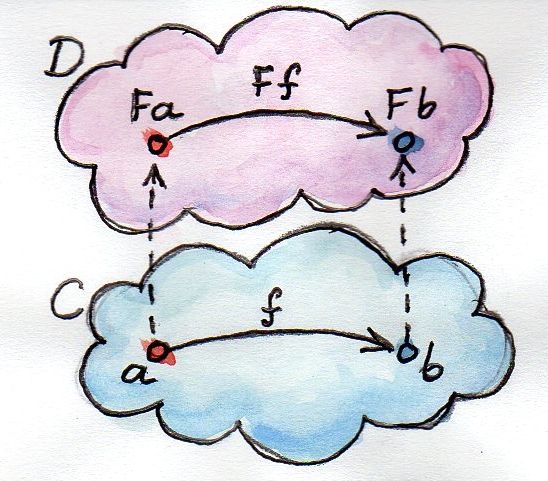
Недаром слово "функтор" похоже на слово "функция".
Аппликативный функтор. А вот тут непонятно. Не, смотришь на картинки, на код, это, вроде, тоже самое, но для двух аргументов в контейнерах. Но что-то непонятно. Ладно, вот еще картинки с описанием. Это когда функции в контейнерах и аргументы в контейнерах. Понятнее не стало, да еще и не совпадает.
Аппликативный функтор — это тот же обычный функтор (правда, закрытый), но для которого опрделена натуральная трансформация из функции a -> b в функцию (f a -> f b). Формально можно почитать здесь.
То есть с точки зрения теории, аппликативный функтор ничем не выделяется, это всё тот же функтор, но для которого заданы небольшие дополнительные ограничения. Но вот с точки зрения программирования эта разница очень большая, потому что если у вас есть два функтора то вы без LiftA2 их вместе никак не сцепите. А вам часто нужно из (A?, B?) получить (A, B)? или из двух списков получить множество их комбинаций, ну и прочие подобные вещи.
Классическую вещь, которую можно сделать на аппликативах (но нельзя на обычных функторах) — контекстно-независимый парсер (контекстно-зависимый требует уже монаду).
Вроде бы, понятно, зачем оно нужно. И понятно, какую проблему (по сравнению с функтором) решает эта сигнатура, на примере тех же Maybe очень понятно. Вот мы имеем цепочку каких-то функций, каждая возвращает Maybe, их друг с другом биндим, все очень круто. А вот почему монада — контейнер? То, что условный Maybe/Option/Nullable итп контейнеры — понятно. Зачем bind при работе с контейнерами — понятно. Но что-то интуитивного понимания нет. И еще почему "монада позволяет описать последовательность" (или что-то в этом роде)?
К сожалению, тут уже такой уровень абстракций, который примерно равняется всей банде четырёх вместе взятой. Поэтому тут лучше уже просто пописать код в таком стиле, тогда интуитивное понимание придет. Цитируя классиков

То есть я могу тут долго расписывать, но особого понимания это не даст. Куда лучше будет самому потыкать и получить представление, что это такое.
Попробуйте объяснить человеку, что такое точка. "Ну, точка это… Точка!". Потому что все остальные геометрические фигуры — линии, квадраты, треугольники определяются как "множество точек, которые ..." (дальше подставить для каждой фигуры своё ограничение). А сама точка никак не определяется, она просто есть, и чтобы понимать геометрию нужно представлять, что это. Так и тут, слишком базовый блок, чтобы определения давали много смысла.
Категория — это класс (про себя неформально можно считать "множеством") объектов, между которыми есть морфизмы
Ну нет, это вы малую категорию описали.
Аппликативный функтор — это тот же обычный функтор (правда, закрытый), но для которого опрделена натуральная трансформация из функции a -> b в функцию (f a -> f b). Формально можно почитать здесь.
Это вы обычный функтор расписали. А для аппликативного определена трансформация из f (a -> b) в (f a -> f b).
Вас смутили приведенные в статье примеры потому что вы уже хорошо усвоили абстрактные определения, но пока не видите, как их применять (зачем их люди придумали). Отсюда непонимание аппликативного функтора.
Монада — это такой функтор, который немного извлекает излишне упакованный аппликативным функтором контекст. Каждый аппликативный функтор при применении упаковывает данные в очередной слой. Монада позволяет устранить эту излишнюю упаковку чтобы можно было построить цепочку вычислений, не потонув в скобочках.
Напомню, зачем нужен аппликативный функтор: обычный функтор не позволяет нам гарантировать отложенного исполнения эффектор (извлечения данных) при всех видах компоновки.
З.Ы. Монада — тайпкласс.
Тайпкласс — это способ предоставить монадическое поведение для типа, который такого поведения не имеет. Если ваш тип изначально реализует «интерфейс» монады, то тайпкласс не нужен.
«Что-то» реализующее некие определенные методы является монадой. И «что-то» имеет какие-то данные, реализуем «интерфейс» (в курсе, что это очень грубая аналогия) монады (имея знание о структуре данных), чтобы функции, работающие с монадами, могла работать с нашим типом.
Реализация интерфейса в классе — это из ООП, которое не совсем относится к ФП. Когда вы реализуете некий интерфейс чтобы ваш класс считался монадой, вы просто подстраиваете ваш класс под определенную библиотеку (которая просит от вас этот интерфейс, например ScalaCats). Объект может вести себя как монада и безо всяких интерфейсов.
Окей. Но с таким же успехом и функтор — контейнер, нет?
Да, он тоже способен работать как контейнер, но в практической работе менее удобен.
Тайпкласс — это способ предоставить монадическое поведение для типа, который такого поведения не имеет. Если ваш тип изначально реализует «интерфейс» монады, то тайпкласс не нужен.
Нет, тайпкласс — это не способ предоставить поведение. Это способ потребовать определенного поведения.
- Функция map функтора как преобразование функции сигнатурой (a -> b)
в функцию с сигнатурой (f a -> f b); - Функция bind монады как преобразование функции с сигнатурой (a -> m b)
в функцию с сигнатурой (m a -> m b); - Функция apply аппликативного функтора как преобразование значения (f (a -> b))
в функцию (f a -> f b). Суть аппликативного функтора в том, что он решает проблему, когда в функцию map передают функцию с несколькими параметрами и на выходе получается функция, обернутая в контекст.
"Но «правильный» объект — это, то что должно само производить действия над другими участками кода"
Фигня полная. Логику должен проверять перед запуском компилятор.
Мне кажется, ООП в исполнении Егора по сути очень близко к ФП. Такая вот смычка парадигм. Я далеко не всегда с его логикой согласен, но мне кажется, он суть ООП в целом чувствует верно, и в идеале (в голове Алана Кея) действительно разница между ООП ФП куда меньше, чем думает средний программист.
Ага, ага. Я помню предложение реализовать if в виде java объекта. Только знаете в чем проблема — что на тот момент в Java не было ленивости. А if — он по большому счету ленивый, потому что пока предикат не вычислили, ни then, ни else не вычисляются.
Поэтому сказать, что человек с такими воззрениями «верно чувствует в целом»… ну это такая, гм, натяжка.
И последний оставшийся шаг
В итоге имеем два типа акторов — объекты-состояния и функции.
Первые — это просто чистые функции ФП, вторые — это те самые мутабельные объекты, обменивающиеся сообщениями в духе Smalltalk.
Но что может сделать чистая функция с объектом, вся структура которого скрыта внутри, и он, по сути, имеет только какой-нибудь метод acceptMessage? Где-то должны жить ещё и значения, причём с API доступным для таких чистых функций. Да хоть те же количества, которые можно складывать между собой. Возможно, что я просто не до конца понимаю идею про обмен сообщениями.
Также у объекта есть список переменных, доступных для записи извне — так другой объект может передавать в наш необходимую информацию.
Объект, получив на свой вход какие-то новые данные, определяет, что с ними делать дальше и вызывает необходимые для этого внешние функции. Конечный результат может быть возвращен в наш объект или передан на вход другом объекту.
Можно на этом строить реактивное программирование, указав что в объекте его «входное поле» зависит от «выходного поля» другого объекта.
То есть здесь получается сообщения в духе обычных геттеров и сеттеров, но они не нарушают инкапсуляцию (в широком смысле) любого объекта.
А внешние чистые функции — это обычные методы объекта в ООП, только чистые и вынесенные за пределы объекта. Плюсы: они чистые, их можно переиспользовать (вместо наследования), можно делать их композицию, они могут быть полиморфными (тогда как внутри объекта всё может быть строго статически типизировано).
Так объект высушивается до хранителя стейта, защищенного внутренним «поведением / характером», которое выглядит как переключатель «if-else-if-else...», зависящий от входных данных и внутренней логики.
upd
В статье столько ошибок, что даже и не знаешь, с чего начать.
Категории — это не типы. Это, если уж пытаться натянуть сову на глобус, системы типов. Или не типов. В категории Set объектами (базовыми элементами категорий) являются множества разных элементов, которые в каком-то смысле могут быть типами (множество всех целых чисел, множество всех строк и т.д.). В категории Hask (которая не совсем категория, но это вопрос практического свойства) базовыми элементами являются типы хаскеля. Конечно, можно создать категорию Double, где объектами будут литералы, а морфизмы будут задавать преобразования между этими литералами, но что это даст?
Эндоморфизмы — это не "тип в себя", это морфизм в пределах одной категории. Преобразование из string в int вполне себе эндоморфизм. Преобразование из Maybe в Maybe тоже эндоморфизм.
Монады — это не контейнеры. Как пример, есть монады IO и Reader не являются "контейнерами", в которые можно что-то положить. Монады — это абстракция вычислений в контексте. Если уж хотите использовать аналогии, то ближайшее к монаде, что можно придумать из "обычного" мира — это Promise. Вы связываете промисы в цепочки вычислений, и каждое вычисление находится в контексте того, что оно случится когда-то. И, как забавное следствие, вы не можете просто взять и избавиться от Promise, если уж вы начали его использовать.
На самом деле Promise не монада, но вполне могла бы ей быть.
Функтор — это не обработчик данных. Функтор — это способ задать контекст вычислений для значения. С т.з. теорката — это функция над объектами и морфизмами, которая преобразовывает их из текущей категории в, возможно, новую категорию. Или в ту же, если это эндоморфизм. Если брать промисы как пример, то функтор на промисах работает так:
- берет
Promise<int>, - неявно извлекает int,
- применяет к нему
intToStr(x: int): string(чистая функция) - оборачивает в Promise
- возвращает
Promise<string>.
Если бы это была монада, то это выглядело бы так:
- берет
Promise<int>, - неявно извлекает int,
- применяет к нему
intToStr(x: int): Promise<string>(монадическая функция, может делать внутри async/await) - возвращает
Promise<string>
Аппликативный функтор просто рассчитывает, что функция, которую нужно применить к значению в контексте, тоже находится в контексте.
Т.е., опять же, используя промисы как пример, у нас есть Promise<(x: int) -> string> и Promise<int>. Аппликативный функтор дает возможность применить Promise<(x: int) -> string> к Promise<int> и получить Promise<string>.
Что касается использования List как примера функторов и монад, и вытекающие отсюда неправильные представления о том, что это контейнеры, а монады и функторы работают с контейнерами. Нет. List не является массивом, List является абстракцией недетерминированных вычислений. То, что List можно вычислить, представив как массив, это лишь "ложный друг переводчика". Значение List[1,2,2,3] на самом деле описывает недетерминированное значение, которое с вероятностью 25% равно 1, с вероятностью 25% равно 3 и с вероятностью 50% равно 2.
Суммируя: вы ничего не поняли, но уже пошли объяснять остальным.
List это уж скорее похоже больше на итератор, чем на структуру данных.
Опять же, нет. В ФП достаточно много перегруженных терминов.
List — это алгебраический тип данных. Какие-то упорядоченные данные в лениво вычисляющемся списке с произвольным доступом.
List — это функтор. Какие-то недетерминированно размазанные данные, реализованные поверх алгебраического типа данных List.
List — это монада. Цепочки вычислений над функтором List.
List не является массивом, List является абстракцией недетерминированных вычислений.
Я бы List считал абстракцией полного перебора. Для недетерминированных вычислений ему не хватает явных вероятностей.
Лучше не брать промисы как пример, потому что для них не выполняются монадические законы, потому что then в ЖС это и map и bind одновременно (вот так вот). Поэтому a.then(b) может означать либо map, либо bind, поэтому написать на жс a.map(function_returning_promise) чтобы получить Promise<Promise<T>> не выйдет. А раз не выполняются законы, то всё плохо.
О том, что теория без практики мертва, вещают тысячи практиков со всех сторон.
А вот этот пример с Promise — это отличный пример, когда практика без теории слепа.
Потому там можно сразу показать — и что такое монада и почему работать с промисами неудобно… и, внезапно, неудобно с ними работать именно потому, что они — не монада…
Я говорил про то, что промисы не надо брать как пример монады, потому что они не монады.
Чтобы показать, почему законы — полезны, они довольно хороши.
Я говорил про то, что промисы не надо брать как пример монады, потому что они не монады.Это как раз неважно.
Понимаете, у людей, которые «не понимают» монады основной вопрос — это не «что это», а «зачем это». Какие-то ящики на ножках, стрелочки, бог знает что… вот это вот всё… зачем?
Человек вопит «что это», хотя на самом-то деле как раз «что это» — примерно понимая. На самом деле ему непонятно другое: нафига эти завязанные в узлы стрелочки ну хоть кому-то ну хотя для чего-то нужны! Что они могут облегчить и кому? Вот тут, как раз, «несостоявшаяся монада» — даже лучше «состовшейся». Потому что человек, если с ней работал, наверняка уже много раз упирался в то место, где это «не совсем монада».
Вот вы же там показывали пример про липкую ленту.
Где объясняется, что, типа «понять что это такое глядя на применения не удастся». Как раз удастся!
А вот если вы будете рассказывать что липкая лента — это такая длинная полоска материала, с одной или двух строн клей, причём незасыхающий… а если широкая — то только по краям… и ещё она может быть на бобину намотана… то вы никогда ни до какого понимания не доберётесь.
Вы можете сколько угодно рассказывать что такое липкая лента папуасу в джунглях — и не получите ровным счётом никакого понимания. Но покажите как этий лентой заклеивают ящик или хотя бы сматывают палки — и понимание наступит. И станет понятно и почему клей нужен незасыхающий и куча ньюансов.
Но для этого нужно, чтобы человек уже немного пообщался с коробками или хотя бы палками! А изобретение всё более красочных описаний этого предмета без того, чтобы показать — куда его можно применить… ничем хорошим не окончится.
Ну я написал ту самую статью на которую линк был выше, лучше чем там объяснить и "что" и "почему" я наверное и не смогу.
Про то, что и то и то надо объяснить — не спорю. Просто обратил внимание, вдруг кто не знал, что промис — не монадка. Кто-то, как видите, этого не знал.
Но для этого нужно, чтобы человек уже немного пообщался с коробками или хотя бы палками! А изобретение всё более красочных описаний этого предмета без того, чтобы показать — куда его можно применить… ничем хорошим не окончится.
Ну то что практика даст понимание я не сомневаюсь. Вопрос, чтобы человек этой практикой занялся.
Вот все эти бесконечные промисы Option'ы,
err, ok в Go и and_then в Rust… это всё попытки «закатить солнце вручную».Изобретение монад без введения понятия монада.
И если человек осознаёт, что, условно говоря, он «всегда говорил прозой» (только корявой и неграмотной) — то понимание приходит быстрее, чем если он пытается прорваться через категории и картинки с коробками…
Вы написали эту статью?
В статье столько ошибок, что даже и не знаешь, с чего начать.
Наверное вы недостаточно внимательно прочитали вводную часть. То, что вы считаете «ошибками» — это умеренный отход от общности к конкретным примеры использования.
Моя цель дать частные примеры чтобы читающий сам понял общий принцип.
Категории — это не типы.
Категории — это не типы, а типы — категории. Категория — это очень широкое понятие.
Моя цель — см выше.
Это, если уж пытаться натянуть сову на глобус, системы типов. Или не типов. В категории Set объектами (базовыми элементами категорий) являются множества разных элементов, которые в каком-то смысле могут быть типами (множество всех целых чисел, множество всех строк и т.д.). В категории Hask (которая не совсем категория, но это вопрос практического свойства) базовыми элементами являются типы хаскеля. Конечно, можно создать категорию Double, где объектами будут литералы, а морфизмы будут задавать преобразования между этими литералами, но что это даст?
Это даст понятный новичку пример.
Эндоморфизмы — это не «тип в себя», это морфизм в пределах одной категории.
Это будет самопротиворечивым высказыванием, в категории «Тип Integer». ;)
Преобразование из string в int вполне себе эндоморфизм.
Вы забыли указать, что это верно только категории Hask. А категорий ух как много!
Монады — это не контейнеры.
Википедия с вами не согласна от слова «совсем». Монада — это функтор с дополнительной структурой. Эта структура позволяет инкапсулировать вычислительный контекст функтора. Без данной структуры нам бы не получилось локализировать контекст. Поэтому монада — это контейнер. Не отдельного значения, не массива, а контекста. Но в начале обучения это определение слишком абстрактно, а потому вредно, имхо.
Пользуясь случаем, хочу прорекламировать одну очень хорошую книжку по теории категорий: F. Lawvere, Conceptual Mathematics: A First Introduction to Categories. Она очень понятно написана для тех, у кого есть базовое представление о теории множеств. Именна эта книга в своё время позволила мне перестать прятаться под диваном от одного вида коммутативных диаграмм и понять, наконец, что же означает "моноид в категории эндофункторов".
Проблема с теорией категорий в том, что если её сразу не к чему прицепить, то все понятия быстро выветрятся. В идеале, при вдумчивом ознакомлении с очередным понятием в голове должна выстраиваться связь в духе "Так это же [xxx]! Что ж сразу не сказали!" Конечно, лучше всего для этого подойдут познания в высшей алгебре и алгебраической же топологии. Но многие ими не обладают. Следующий по худшести вариант тоже почти очевиден: хорошее знание какого-нибудь ФП. Но если и этого нет, то, как ни странно, понимание ООП или реляционных баз данных тоже вполне сгодится, чтобы связать абстрактные понятия с чем-то очень знакомым. Книжка Ловера хороша тем, что там много примеров на базе категории множеств (Set), причём с иллюстрацией на конечных множествах, и многие из этих примеров можно почти сразу перевести на язык классов и объектов.
можем умножить его содержимое на «2»
На «2» мы умножить не можем. Вот на 2 (без кавычек) — другое дело: все-таки проверка типов — она и с Option'ами делается (не знаю, как в хаскеле, но в скале точно).
Ошибки и бездоказательные утверждения в каждом абзаце, разбирать это все нет никаких сил. Боюсь представить, что с автором будет если он статьи 70-80х голов прочитает про логическое программирование. Когда-то считалось, что оно решит все проблемы, но воз и ныне там. С ФП аналогичная история, есть здравые идеи, но не более того. Все нормальные языки уже давно большую часть ценных идей впитали.
В статье много про монады, как будто в этом вся соль ФП. Но в реальности монады активно используются только в Хаскеле, 99% языков, которые мы бы назвали «функциональными» обходятся без них.
Монады можно успешно заменить много чем. Например макросами и call/cc в scheme. Или async/await в C# или операцией [^] в smalltalk. Монада нужна теоретикам, что доказать некоторые свойства языка. А программисту до фонаря как это теоретик называет.
Если мы хотим в типизированном языке сделать механизм вроде async/await нам нужен тип, в котором мы спрячем продолжение. Теоретики увидели сходство с математической структурой, именуемой монадой и понеслась. Но смысл остаётся все тем же — нужна штука, в которой будет жить continuation и механизм вызова этого continuation.
Монады можно успешно заменить много чем. Например макросами и call/cc в scheme. Или async/await в C# или операцией [^] в smalltalk.
Фрукты можно заменить много чем. Например сухофруктами или яблоками. Или апельсином красным или апельсиновыми дольками.
Я к тому, что семантически это практически одно и тоже, но без лишних математических ассоциаций.
Очень странно слышать, что семантически монады IO, Async и Cont — это одно и тоже.
Мой отсыл к фруктам был призван продемонстрировать логическую ошибку: отношение между монадами и, например, call/cc, — это отношение между общим и частным, и конечно же частное не заменяет общее.
Если бы вы сказали, "монады — это абстракция над вычислениями в контексте, независимая от вычислителя", а потом добавили, что мол "на практике сама абстракция не нужна, а пользу приносит в-основном конкретная монада async/await и отлично работает", и с этим можно спорить (и я постарался бы этот тезис оспорить :-)), а в исходном виде фраза просто некорректна.
Очень странно слышать, что семантически монады IO, Async и Cont — это одно и тоже.
Вы меня неправильно поняли или я неточно выразился. Основная функция монады это что-то вроде
Monad<T> MonadStepFunction(T value, Func<T> continuation)— Maybe — не будет вызывать continuation если value == None
— List — работает только если value это список и будет вызывать continuation для каждого элемента списка
— Async — работает для чего-то вроде Promise и вызовет continuation когда Promise завершится.
Тут ключевое то, что у нас в распоряжении есть текущее значение и продолжение. call/cc тоже нам дает продолжение, а макросы позволяют сделать что-то вроде do нотации. Аналогично async/await + TaskBuilder + Awaitable дают нам продолжения в C#. Если напрячься, то можно на C# изобразить maybe. Выглядеть будет так
async Maybe<int> Func1() => 1; //наш TaskBuilder построить Maybe.Just(1)
Maybe<int> Func2() => Maybe.Nothing; //а тут мы сами строим Maybe
int Func3i() => 2;
Func<Maybe<T>> LiftMaybe<T>(Func<T> f) => //можно трансформировать функции
() => try { return Maybe.Just(f); } catch { return Maybe.Nothing; };
Maybe<int> Func3 = LiftMaybe(Func3i);
async Maybe<int> MyFunc() {
var myMaybe1 = await Func1();
var myMaybe2 = await Func2(); //тут закончится вычисление
var myMaybe3 = await Func3();
//если бы сюда попали, то TaskBuilder построил бы нам
//Maybe.Just(myMaybe1 + myMaybe2 + myMaybe3)
return myMaybe1 + myMaybe2 + myMaybe3;
}
Maybe<int> b = MyFunc(); //без await
if (b != Maybe<int>.Nothing) Console.WriteLine(b.Value);
— «await Maybe» имеет тип T.
— любая функция, которая хочет делать «await Maybe» должна возвращать Maybe.
Можно извратиться еще больше и сделать что-то аналогичное с помощью LINQ. Опять же, все что нужно это продолжение.
Если бы вы сказали, «монады — это абстракция над вычислениями в контексте, независимая от вычислителя», а потом добавили, что мол «на практике сама абстракция не нужна, а пользу приносит в-основном конкретная монада async/await и отлично работает», и с этим можно спорить (и я постарался бы этот тезис оспорить :-)), а в исходном виде фраза просто некорректна.
С учетом того, что сказано выше я бы сказал «монады вместе с do-нотацией — это механизм, который позволяет получить и удобно работать с продолжениями, окружающая эта понятие математика не имеет значения». А потом бы я добавил — «на практике не важно как называется и чем обоснован механизм получения продолжения, значением имеет удобство синтаксиса. В C# удобно только для async/await, в scheme и smalltalk все шикарно».
Ну и давайте спорить :)
Извините мне вот стало „легко и понятно“, когда я для себя понял
При этом: „монада это просто такой способ“ — тут слово просто обманчиво, поскольку в него запихали много чего, позволяющие получать интуитивно понятный результат при цепочках вычислений, и использовать IO как `контекст`(и наверняка вы добавите много чего ещё в это „просто“).
Так вот вопрос: интуитивно-удобное для меня понимание довольно близко к тому, с чем вы могли бы поспорить. Есть какая-то конкретная проблема в этом (удобном для меня) понимании?
Все нормальные языки уже давно большую часть ценных идей впитали.
Ради интереса, какие это идеи и какие языки? Я работал с C#, VB, Java и там не хватает очень многих вещей, которые есть даже в примитивнейших F#/Scala, не говоря уже про более развитые языки.
Дабы не быть голословным, несколько примеров из C# (часть этих вещей уже есть, но появились очень-очень недавно):
1. Non-nullable types by default (Optional, Maybe, etc) — огромное количество ошибок у нас возникает как раз по причине NPE. Наконец появилось в последнем C#, Java не смотрел.
2. Exhaustive pattern matching and discriminated unions — очень помогают для описания раздельных состояний. Пока не завезли.
3. Records (Scala's case classes) — в разы уменьшают количество бесполезного кода при описании структур. Также не завезли, есть 3P решения.
- всё ещё отстой, потому что функцию
T? MaybeSomething<T>()написать не получится. компилятор потребует навесить констрейнт struct/class. Поэтому у меня в коде лапша подобной прелести:
public static IEnumerable<T> WhereNotNull<T>(this IEnumerable<T?> source)
where T : class =>
source.Where(x => x is {})!;
public static IEnumerable<T> WhereNotNull<T>(this IEnumerable<T?> source)
where T : struct =>
source.Where(x => x is {}).Select(x => x.GetValueOrDefault());
public static T? FirstOrNull<T>(this IEnumerable<T> source)
where T : class =>
source.FirstOrDefault();
public static T? FirstOrNull<T>(this IEnumerable<T?> source)
where T : struct =>
source.FirstOrDefault();
public static T? FirstOrNull<T>(this IEnumerable<T> source, object? _ = null)
where T : struct =>
source.Cast<T?>().FirstOrDefault();
... тысячи ихОчень больно без Either, очень часто нужны, пока делаем на эксепшнах и надеемся, что никто не выкинет недокументированный (потому что swagger документация требует явно описывать все возможные ошибки и их модели).
В шарпе скоро будет, доведя количество возможных паттернов инициализации до шести. Угадайте, в чем разница между:
public class Person(string FirstName, string LastName)
public class Person { string FirstName; string LastName; }
public data class Person { string FirstName; string LastName; }
public class Person { string FirstName {get;set;} string LastName {get;set;} }
public class Person { string FirstName {get;init;} string LastName {get;init;} }
public class Person(string firstName, string LastName)Welcome, C# 9.0 Семимильными шагами догоняет плюсы.
Насколько я понимаю, способов инициализации для потребителя всё ещё два, а с точки зрения CLR — так и вовсе один; всё перечисленное вами — всего лишь разные реализации.
В плюсах же как раз внутри есть всего три разных варианта, а вот снаружи один и тот же объект можно инициализировать кучей разных способов и с разными результатами. Так что нет, не догоняет.
Соглашусь, лично мне местами изменения кажутся сомнительными, особенно сравнивая с Scala, где те же case classes выглядят как-то попроще. С nullability вообще грустно, но что поделать, наследие.
Насчёт синтаксиса было смешно: data class решили упростить до просто record, таким образом в ближайшее время планируют public record Person. На структуры не работает, но если таки допилят и для них, то обновят и надо будет писать public record class Person. В обсуждении этого дела успели набрать ~50 комментов .
- Higher order functions
- Closures
- Map/reduce и прочая
- Вывод типов
- Generics в противовес c++ templates
То, что вы упомянули это приятные вещи, но ни одна из них и они все вместе не станут причиной выбрать язык для нового проекта. Скорее этими причинами будет рантайм, стандартная библиотека и фреймворки, тулинг в виде IDE, систем сборки, мониторинга и где-то в конце будет синтаксис и языковые фичи.
Скорее этими причинами будет рантайм, стандартная библиотека и фреймворки, тулинг в виде IDE, систем сборки, мониторинга
Именно так. Как раз поэтому в индустрии доминируют языки, в которых, на мой взгляд, и нет очень даже ценных фич именно в плане языка.
То, что вы упомянули это приятные вещи, но ни одна из них и они все вместе не станут причиной выбрать язык для нового проекта
Это применимо и к функциям, и к замыканиям, и к остальным фичам. Язык со всеми этими фичами, но без рантайма, библиотеки и т.п очень вряд ли будет выбором, если только не нишевым.
Собственно, не понял вашу линию рассуждений. Давайте вы приведёте пример нормальных языков, а мы посмотрим, какие в них есть полезные из ФП фичи и каких условно бесполезных нет.
Собственно, не понял вашу линию рассуждений.
Линия рассуждений простая — ФП когда-то было очень хайповой темой. Академики и энтузиасты сделали кучу языков, часть из них стала немного популярна. В этих языках обнаружились фичи, которых в мейнстриме нет. За 15 лет самые полезные из них заимствованы мейнстримом. Упомянутые уже higher order functions, type inference и т.п.
Вы оппонируете и приводите пример несколько фич, которых в условном C#, Java, Swift нет. На это я могу сказать, что а) всегда есть к чему стремиться и мейнстрим подтягивается и б) с учётом всех фич, которые уже перетекли в мейнстрим, ФП просто нечего уже предложить. В каком-нибудь OCaml есть куча всего, но 50% наиболее ценного из этого уже есть в C#. А оставшиеся 50% никак не перевешивают проблем с IDE, рантаймом и прочим.
Резюмируя — у ФП не осталось киллер фич, можно сказать, что оно устарело.
Резюмируя — у ФП не осталось киллер фич, можно сказать, что оно устарело.Ну… можно и так сказать.
На самом деле тут вот в чём беда: ФП, так-то, изначально решает проблему, про которую кажется, что она нужна всем — а на самом деле не нужна почти никому.
Написание корректного, работающего, кода. Внезапно. Есть люди, которые прямо заявляют — корректность не нужна, главное убедить заказчика в том, что вот та куча дерьма, глючная и падающая регулярно — это вот то, о чём он «всю жизнь мечтал».
Ещё больше людей — которые это не произносят явно, но чувствуют интуитивно.
А в тех редких случаях, где корректность, всё-таки, важна и нужна — мы можем посадить 100500 экспертов и выверить каждую строку кода (это неверно, на самом деле, но считается что так оно должно и будет работать).
И вот в этой парадигме — ФП действительно нечего больше предложить мейнстриму. Но будет ли так всегда?.. Как ни странно ответ на этот вопрос — «не знаю». Честно. Я действительно не знаю.
Но если, вдруг, люди реально захотят сделать так, чтобы их программы были корректными и работали надёжно… о, в этом случае ФП вполне ещё может выстрелить.
Ни для C++, ни для Python, ни для Haskell у меня такого ощущения в разных IDE не было.
Ну поставьте и сравните. Не все рефакторинги которые есть в шарпе есть в хаскелле, конечно, но не все рефакторинги нужны — многие вещи решаются языковыми средствами, а не "решарпер, сгенерируй мне, пожалуйста IEquitable, IComparable и десяток операторов сравнения, потому что язык не умеет в дерайвы".
А что ещё от IDE требуется?
Благодаря очень удобному повсеместному автодополнению можно с самым базовым знанием языка писать и править блоки кода, которые даже будет работать.
В те редкие моменты, когда мне приходится что-то править и дописывать на C#, получается достаточно быстро разобраться, как это сделать. Методом тыка в автодополнение в разных местах быстро находятся нужные методы. Конечно, дополнение есть во многих IDE для разных языков, но в VS + C# лично мне оказывается удобнее всего, что видел.
Так автодополнение даже в идрисе есть, который 1.5 студента пилят, в хаскелле — тем более.
Я бы сказал, что автокомплит и подсветка это абсолютный минимум, без которых язык вообще рассматривать смысла не имеет. Конечно же, в хаскелле оно есть.
Конечно, дополнение есть во многих IDE для разных языков, но в VS + C# лично мне оказывается удобнее всего, что видел.
Так в чем это удобство заключается, можно узнать? По пунктам?
Потому что необходимость нажать 2 кнопки 1 раз после установки ИДЕ это явно не та сложность которая хоть на что-то влияет.
Так в чем это удобство заключается, можно узнать? По пунктам?
Нет, нельзя — разница в удобстве, как обычно, субъективная.
Потому что необходимость нажать 2 кнопки 1 раз после установки ИДЕ это явно не та сложность которая хоть на что-то влияет.
Какие две кнопки вообще? Я про общее удобство и качество автодополнения.
Нет, нельзя — разница в удобстве, как обычно, субъективная.
С трудом могу себе это представить. Я обычно всегда могу сказать, чего не хватает, или наоборот, что круто сделано и полезно.
Какие две кнопки вообще? Я про общее удобство и качество автодополнения.
А в чем это качество заключается? По префиксу находит, нечетко находит, по заглавным буквам — находит. В выдаче описание функций и документация (если есть) рисуется.
Что ещё нужно?
Во-первых, оставшиеся 50 — это ADT, это GADT, это подъём термов на уровень типов, это тайпклассы, это частичное применение, это контроль за эффектами, это отсутствие синтаксического шума, в конце концов.
Если все это в C#/Java окажется завтра я буду только рад. Мой тезис не в этом, а в том, что самое вкусное уже есть, то что осталось это тоже вкусно, но уже не там важно как остальное.
Из перечисленного type class решают важную проблему (expression problem) я чего-то подобного очень жду. Я выделяю эту фичу именно потому, что есть expression problem, часто встречается на практике, решения в C#/Java хорошего не имеет.
Какие проблемы с IDE и рантаймом я, по-вашему, наблюдаю?
В этом смысле Java впереди планеты всей. Хочется что-то подобное JMX, профилировщики, тюнинг GC, remote отладку, отладку core dump, возможность подключить что-то вроде new relic. В какой-то степени это обычно есть, но если вы пользовались отладчиком или JMX в Java, то вы меня поймете — это все не то. Не хватает возможностей, легкости настройки и самое главное — стабильности.
Из чисто runtime фич это хороший JIT, возможность генерить код в рантайме, быстрый reflection. Всякие важные мелочи, вроде lock — который использует CAS когда можно и переключается на примитивы ОС только если потоки начинают за него бороться. Хороший thread pool/work stealing queue тоже не в каждом языке найдется.
Проблем с C++ IDE у меня на порядок больше, и если бы не CLion, то более-менее адекватной IDE не было бы совсем.
Для меня до сих пор загадка как такой франкенштейн как C++ вообще дожил до наших дней. И это при том, что во время его изобретения уже были common lisp, smalltalk, pascal, ada.
Прикольно наблюдать за некоторыми дискуссиями на хабре о том, кто в ООП-мире в игре должен управлять взаимодействием меча и моба — ответственность ли это меча, моба или менеджера боёв. В ФП-мире ты просто пишешь тайпкласс.
Неа, не получится. Там, если делать в лоб, то будет как-то так (но не скомпилируется и правильно сделает):
class (Actor a, Weapon w) => ActorWeapon a w
instance (Actor a, Weapon w) => ActorWeapon a w
instance (Actor a, SwordLike w) => ActorWeapon a w
instance Weapon w => ActorWeapon Frog w
instance Actor a => ActorWeapon a Lance
instance Magic w => ActorWeapon Dragon wПервая проблема тут растёт из предметной области, и заключается в том, что наборы особых случаев перекрываются, и никто кроме программиста и геймдизайнера не придумает как правильно эти "перекрытия" учитывать.
Вторая проблема специфична для ФП и заключается в том, что такие наборы условий просто не работают из-за направления вывода типов. В итоге вместо того чтобы "просто писать тайпкласс", придётся писать кучу неочевидного кода вроде того, который был в вашей статье про Has (я, кстати, так и не нашел набора флагов, который позволил бы то решение собрать).
В этом смысле Java впереди планеты всей. Хочется что-то подобное JMX, профилировщики, тюнинг GC, remote отладку, отладку core dump, возможность подключить что-то вроде new relic. В какой-то степени это обычно есть, но если вы пользовались отладчиком или JMX в Java, то вы меня поймете — это все не то. Не хватает возможностей, легкости настройки и самое главное — стабильности.
Знаете, я в хаскель чате общался с людьми насчет дебага, так вот там есть люди с 10+ годами опыта промышленной разработки на хаскелле, и они не знают как работать с дебаггером. Ну то есть они не слышали что такое watch window, что такое step over и step into. Казалось бы, невозможно, неверноятно, но — факт...
Что до кодогенерации в рантайме — кодогенерация в дизайн тайме куда лучше, но насколько я знаю, в джаве её нет.
Я выделяю эту фичу именно потому, что есть expression problem, часто встречается на практике, решения в C#/Java хорошего не имеет.
По вашему, object algebras — это не хорошее решение?
<A> A parseExp(IntAlg<A> f, String s)
parseExp парсит s и строит операцию или объект с данными типа A.
Когда им нужно расширить иерархию объектов они говорят
interface IntBoolAlg<A> extends IntAlg<A> {...}
Это означает, что в иерархии появился объект тип bool. И тут обман — авторы везде используют exp и exp2, где выражения hardcoded. Но они «забывают» указать, что вместе с IntBoolAlg должна изменится и сигнатура
<A> A parseExp(IntBoolAlg<A> f, String s)
Но parseExp по условию задачи менять нельзя, она может жить в другой сборке, у нас может не быть исходного кода парсера.
В итоге, все что они говорят это «давайте у нас будет метод, который обходит внутренности объекта и строит операцию над этим объектом». Но это можно и без всяких алгебр сделать
T BuildAccountOperation<T>(IOperationBuilder<T> builder, AccountType entity)
{
return entity.Type switch
{
case 1 => builder.Build1(entity),
case 2 => builder.Build2(entity);
};
}
Вот тут прекрасно обходим внутренности аккаунта и строим операции над ним. Как и InBoolAlg если я решу добавить новый тип аккаунта, то эту функцию мне нужно будет изменить.
В итоге они сделали хорошо замаскированный visitor и получили награду за лучшую статью. Все это неплохо иллюстрирует положение дел в ООП как науке.
Мм, да нет, не должно ничего меняться. Неплохая статья на тему.
Весь код который использует BoolExpr меняться не будет, нужно будет только там где нужен BoolExpr будет IntBoolAlgebra
В случае с полиморфизмом клиенты знают о типе Exp и о том, что у него есть метод Eval. Также они знают об операции «Exp Parse(String)» При добавлении Bool клиенты о его существовании даже не догадываются.
В случае с алгебрами клиенты знают о IExpAlg и Parse(IExpAlg, String). При добавлении Bool они должны изменится, так как меняется интерфейс парсера на Parse(IBoolAlg, String).
Ну так Main(3) это новый клиент. А уже существующий клиент ( client.dll) менять не надо. Как и в первом случае. А то почему-то использований BoolExp в пером коде — нигде нет, а во втором BoolEvalAlg — есть. Неэквивлентные вещи.
Ну и у вас в целом неправильно: Parser нельзя трогать, нужно писать BooleanParser и уже с ним всю фигню мутить.
Во втором примере то же самое. Но как только в входной строке появляются bool, мне нужно использовать bool parser, а заодно перекомпилировать клиента. Если я напишу BoolParser, то мой клиент от этого с bool работать не научится.
Как ни крутись, чтобы вызвать произвольную операцию мне нужно а) строка б) алгебра в) парсер, совместимый с алгеброй. Если парсить на каждый чих не круто, то все равно нужно таскать с собой а) AST совместимый с алгеброй б) алгебру в) обходчик AST, совместимый с алгеброй. И все это становится эквивалентно визитору, только тут мы визитор назвали алгеброй.
Так это потому что у вас одна реализация ParserImpl. Добавьте ещё пяток, и внезапно окажется, что их все нужно менять.
У вас единственный ParserImpl : IParser, конечно на одной реализации такое не показывается.
Покажите на более простом примере. Есть у нас классы треугольник, круг и квадрат. У них есть функции вычисления площади и периметра. Покажите, как у вас выглядит добавление трапеции и функции печати имени на экран.
Так это потому что у вас одна реализация ParserImpl.
Так больше одной реализации и не нужно. Ее задача взять строку и построить Exp. А уже у Exp есть метод Eval. В этом заключается разница с алгебрами. Там парсер нужен чтобы построить объект, у которого есть метод Eval.
Покажите, как у вас выглядит добавление трапеции и функции печати имени на экран.
Хватит добавления трапеции, ровно тот случай, когда ломается visitor
interface IAlg1<T> //вам это не напоминает visitor?
{
T Square(int x); //T Accept(Square s);
T Circle(int r); //T Accept(Circle c);
T Rect(int w, int h); //T Accept(Rect r);
}
interface IAlgAlternative<T> //те же яйца вид сбоку
{
T Lit(int x);
T ShapeType(ShapeType t); //Square, Circle, Rect
}
public static class Parser1
{
public static T Parse<T>(IAlg1<T> a, string s);
}
public static class Client
{
public stati void Main(string[] agrs)
{
Console.WriteLine(Parser1.Parse(new PrintAlg1(), args[0]));
}
}
interface IAlg2<T> : IAlg1<T>
{
T Trapezium();
}
public static class Parser2
{
public static T Parse<T>(IAlg2<T> a, string s);
}
//All clients has to use Parser2 or they won't be able to interact with Trapezium shapes.
Так больше одной реализации и не нужно.
Я и говорю, что не поняли.
Больше одной реализации нужно как раз для того, чтобы расширять, не трогая старых клиентов.
Но parseExp по условию задачи менять нельзя, она может жить в другой сборке, у нас может не быть исходного кода парсера.
Верно вот это — все кто хочет использовать алгебры используют функцию parseExp. Сигнатура этой функции меняется всякий раз, когда мы добавляем новые «классы», а значит всякий раз нам нужно перекомпилировать всех клиентов.
Монады позволяют создать очень абстрактную абстракцию, позволяющую унифицировано работать с разными вещами, а не реализовывать отдельный синтаксический велосипед на уровне языка для async/await, Option итп
А программисту до фонаря как это теоретик называет.Как раз нет — и промисы это как раз прекрасный пример. Ибо работать с ними неудобно — и именно потому что их сделали не как монады, а «как смогли».
А там-то какие законы нарушены?
Насколько я знаю, в случае Optional проблемы наблюдаются скорее с тем, что в языке нет ни сопоставлений с образцом, ни do-нотации, ни возможности запретить null-значение для Optional...
Join нельзя определить на нуллябельном Option. А значит и эндофунктора нет.
А что мешает сделать с нуллами то же самое, что обычно делают с боттомами — притвориться, что их не существует?
Если в языке любой пользовательский тип данных неявно расширен значением null — это печально, но это же не означает что теперь недопустимо даже пытаться ввести Optional?
Дело не об этом, дело в том, что вы не можете вкладывать опшны друг в друга. Нельзя сделать Option<Option<null>>. А это уже нарушает законы (потому что должен быть моноид в категории эндофункторов, а эндофунктором он быть не может потому что не на всех значениях определён).

Не знаком с Java. Можете привести пример того, что неудобно?
По первой ссылке пишется явно корявый код (про который по второй ссылке говорится, что он "should never have existed"), а потом демонстрируется, что к нему трудно прикрутить Optional. Вот только к нему что угодно трудно прикрутить, ибо он коряв изначально.
По второй ссылке демонстрируются реальные проблемы, но они никак не связаны с нарушением монадных законов.
Я к сожалению не нашел ссылки на нормальное обсуждение, которое было еще до релиза Java 8 в блоге у разработчиков. Эти два да, так себе.
И вот тут еще про нарушение конкретно. А именно, почему попытки сделать null-safe нарушают например левую ассоциативность.
То что Optional нарушает монадные законы — это ясно. Что это, по-идее, плохо — тоже (я сам дважды имел неприятности из-за отсутствия ассоциативности там, где априори она ожидалась — с другими недомонадами, не с Optional).
Неясно, реально ли это мешает пользоваться Optional. Выглядит так, что конкретно в этом случае нарушение монадных законов не приводит к реальным проблемам.
Ну смотрите, отсутствие ассоциативности приводит к тому, что сделав якобы рефакторинг — то есть такое преобразование, которое не должно бы изменять семантику — мы де факто получим ее изменение. То есть, например, map(f).map(g) и map(f.andThen(g)) может иметь не идентичное поведение — то есть замена двух мапов одним и композицией функций может наш код сломать. А может и не сломать.
Не то чтобы Optional вообще пользоваться было нельзя — это конечно не так, но определенные проблемы оно вызывает.
Частая проблема — написание генерик кода. Например, мы делаем парсинг JSON'а (в общем виде), и у нас есть функция getJsonValueByKey(string key) которая возвращает нам этот Option<TValue>. Вопрос, а что нам делать, если сам TValue — это опциональное поле (например, goods_weight Option<Double>)?
async/await это и есть монады, у них даже интерфейс похож до степени смешения. Нет удобной do-нотации и потому эта фича не используется для реализации штук вроде Maybe.
Функтор – обработчик данных в контейнере-монаде. Функтор без монады – деньги на ветер.

Почему функциональное программирование такое сложноеПотому что его пытаются противопоставлять всем остальным парадигмам и натягивать даже на те задачи, для которых он не подходит. Например на те, которые изначально императивные и state-full в силу своей бизнес-логики.
Точно так же, к ООП становится дико переусложнённым, когда на нём пытаются сделать, например, поточную state-less логику обработки данных.
Помнится, когда я перешел с Бейсика на Си++, я тоже был поражен — возиться с компиляцией куда дольше, но зато работает куда лучше. Лучше, но не идеально.
Уже не так давно юзал Хаскель — да, компилится и работает. Лучше, но не идеально.
Грубо начиная с 1000 строковых программ компиляция перестает гарантировать работоспособность. ООМ из-за ленивости языка, старые хвосты вроде функции head(кидающие исключение на пустой список) в коде какой нибудь либы, баги в коде который работает с битами напрямую из соображений производительности…
И, прежде всего — семантические ошибки, которые пролезают в повышенной дозе как раз из-за того что уже выработалась привычка что скомпилировавшийся код тестировать не надо.
Семантические ошибки тоже можно отлавливать с помощью типов, оборачивать разные семантические типы в newtype, явно формулировать ограничения и эффекты.
И какая-то практика тоже нужна, чтобы заранее избегать ловушек вроде let Just x = ....
Опять же, кто вам запрещает писать тесты?
Как отлавливается ошибка в порядке вызова функций с помощью типов (например rotate, translate вместо translate, rotate в графике)?
Это реальные ошибки, которые я лично делал.
Ну например вот так:
add : Nat -> Nat -> Nat
add a b = a - b
.\.\test.idr:53:13:
|
53 | add a b = a - b
| ^
When checking right hand side of add with expected type
Nat
When checking argument smaller to function Prelude.Nat.-:
Can't find a value of type
LTE b aОшибка говорит о том, что система типов не может гарантировать, что b всегда будет не больше a, а значит может получиться отрицательное число (которое не является валидным натуральным числом). Компилятор не умеет читать мысли, но этой ошибки должно быть достаточно, чтобы вы нашли проблему и исправили её, заменив минус на плюс.
А если без сигнатуры? Вроде же недавно хвастались, что церемоний можно избежать...
Что можно было сделать узнать нетрудно. После того как как факап случился.
Но вот не понятна война адептов ФП с ООП ( именно в таком ключе ). Мне кажется с тем-же ООП можно применять подходы ФП.
Отсюда: https://ru-lambda.livejournal.com/27669.html .
Как-то однажды знаменитый учитель Кх Ан вышел на прогулку с учеником Антоном. Надеясь разговорить учителя, Антон спросил: "Учитель, слыхал я, что объекты — очень хорошая штука — правда ли это?" Кх Ан посмотрел на ученика с жалостью в глазах и ответил: "Глупый ученик! Объекты — всего лишь замыкания для бедных."
Пристыженный Антон простился с учителем и вернулся в свою комнату, горя желанием как можно скорее изучить замыкания. Он внимательно прочитал все статьи из серии "Lambda: The Ultimate", и родственные им статьи, и написал небольшой интерпретатор Scheme с объектно-ориентированной системой, основанной на замыканиях. Он многому научился, и с нетерпением ждал случая сообщить учителю о своих успехах.
Во время следующей прогулки с Кх Аном, Антон, пытаясь произвести хорошее впечатление, сказал: "Учитель, я прилежно изучил этот вопрос, и понимаю теперь, что объекты — воистину замыкания для бедных." Кх Ан в ответ ударил Антона палкой и воскликнул: "Когда же ты чему-то научишься? Замыкания — это объекты для бедных!" В эту секунду Антон обрел просветление.
Спасибо за статью, первая часть очень понравилась, где мотивация расписана, но вот начиная с определений пошла какая-то жара.
Если вам не жалко, то я бы удалил раздел "Прошу к столу", и отложил бы его на вторую статью, чтобы подробнее разобраться во всём этом. Если вообще нужно, потому что как я уже говорил, ФП — это про ссылочную прозрачность, монады и функторы появляются естественным образом, их не надо учить, как не надо учить паттерны GoF для того, чтобы ссделать лабораторку по джаве. Для того чтобы объяснять ФП они вообще не особо-то нужны. Я специально делал две статьи — одна про ФП, другая про монада.
По фактическим ошибкам — многое написали выше, я только повторюсь в одном: категория это НЕ типы. В частности, если вы читали про категории вообще, то в рамках программирования рассматривается категория Hask — то есть категория типов Haskell (ну, она равномощна категории типов любого языка, ведь по сути это просто Set с боттомами, потому что в реальном мире вычисления могут зависать). А объекты этой категории — уже типы. Соответственно, примером морфизма в нашем случае можно взять функцию из Int в Bool. Какую-нибудь одну, ведь множество морфизмов из Int в Bool содержит 2^(2^32) элементов.
Поэтому и теорию категорий для программирования знать не обязательно, ведь мы работаем со всего одной категорией, и все остальные построения теории вырождаются: все функторы с которыми мы работаем становятся эндофункторами, и так далее.
Я бы рекомендовал оставить ту часть статьи, которая корректная и интересна, а кусок который запутывает и дезинформирует читателей скрыл бы и доработал в рамках отдельной статьи с исправлениями.
ведь по сути это просто Set с боттомами
Вообще-то уже без боттомов:
Because of these difficulties, Haskell developers tend to think in some subset of Haskell where types do not have bottom values. This means that it only includes functions that terminate, and typically only finite values.
Буду благодарен за уточнения, иные аналогии в определениях.
в бодром темпе можно добраться до линз.
Чтобы проектировать хотя бы на уровне монад, придется разобраться в монадических законах. А для этого, по моим представлениям, надо осилить примерно четверть теорката
Здесь основная ошибка в логике. Чтобы освоить монады, не нужно не то что четверть теорката, а вообще ничего из него. Достаточно обычного ООПшного опыта минимального. Впрочем, как с оопшной точки зрения оно выглядит я уже оформил в статье, большего к этому мне добавить пока нечего.
Трансформеры и остальное нужны только если у вас ФП язык и вам нужно комбинировать эффекты. В стандартных жабо-тайпскриптах оно не нужно, но при этом использовать монады там можно (было бы, если бы было желание и понимание коммьюнити).
Линзы тоже решают довольно специфическую задачу, в простых случаях они тоже особо не нужны, а где нужны, там давно реализованы, а пользоваться ими можно в стиле "пиши как жабе, только перед точками ставь ещё крышечку".
Трансформеры и остальное нужны только если у вас ФП язык и вам нужно комбинировать эффекты.
Когда у вас только одна монада, то освоить bind/fmap обычно не составляет труда. Но когда монад хотя бы две, то вопрос типа как из `List<Either<e, a>>` сделать `Either<e, List<a>>` появляется почти сразу, а ответ уже не сильно очевиден. Ну или `Right Task List Right Task User a` привести к вменяемому виду.
В следующий раз попробуйте вместо цикла for написать map/forEach
for (let item of [1, 2]) {
alert(item)
}
[1, 2].forEach(alert)
Так действительно лучше.
for (let item of [1, 2]) {
item++
alert(item)
}
[1, 2].forEach(item => {
item++
alert(item)
})
А вот так уже совсем не лучше. Первый вариант мне даже больше нравится.
Только к функциональности это имеет мало отношения. Ближе — писать флатмапы вместо циклов (выдержка из одного моего сниппета):
const orderIdToRouteInfo = routes.reduce((map, route) => {
flatMap(route.routePoints!, (rp) => rp.orderTasks!.map((ot) => ({rp, ot}))).forEach(({rp, ot}) => {
map[ot.orderId] = {route, routePoint: rp};
});
return map;
}, asType<StringMap<{ route: Route; routePoint: RoutePoint }>>({}));И сразу видно, что писать в иммутабельном ФП стиле на ЖС весьма много словно и не очень удобно (впрочем, гарантии предоставляемые иммутабельностью мне важнее в данном случае)
Интересно, о каких гарантиях иммутабельности речь, когда тут иммутабельного кода — всего одна строчка, а остальное — замаскированный мутабельный цикл?
Неужели вот так менее понятно?
const orderIdToRouteInfo = (() => {
let map = <StringMap<{ route: Route; routePoint: RoutePoint }>>{};
for (const route of routes)
for (const routePoint of route.routePoints!)
for (const ot of routePoint.orderTasks!)
map[ot.orderId] = { route, routePoint }
return map;
})();Возможно, я излишне использую это где не надо. Но я много раз обжигался на жсовых for (те же of/in и прочее), поэтому стараюсь ими не пользоваться.
Ну, на in-то понятно где обжечься можно, а с of-то что не так?
Не пишу на JS с 2015 где-то года (вот тут небольшой проектик пришлось на ноде написать, потом что на дотнет либы нужной не нашлось), поэтому я не разбирался во всех нюансах современного жсо-строения, просто ещё тогда выработал привычку не трогать циклы, и с тех пор не было возможности/мотивации переучиться.
[1, 2].map(item => item+1).forEach(alert)А вот так всё же, имхо, лучше чем for.
Правда в JS map не ленивый, поэтому производительность страдает, но это уже не является предметом обсуждения
Правда в JS map не ленивый, поэтому производительность страдает, но это уже не является предметом обсуждения
А почему страдает? И там, и там линейная сложность. Ленивые вычисления должны выполнить столько же работы (плюс ещё немного накладных расходов) и получают преимущество только в некоторых случаях.
Правда в JS map не ленивый, поэтому производительность страдает
Так стоит гуглить же, мне когда понадобилось я довольно быстро нашел решение.
Как пример — классические ОРМ вроде hibernate. Вроде всё просто и понятно, есть таблицы и маппинг. Можно дернуть get для получения значения свойства, set для установки. Но это только в вакууме. В реальном мире сложности начинаются сразу же — как только появляется слой бизнес логики, становится понятно, что полученные красивые объекты невозможно использовать в бизнес логике, а их «красивость» только мешает. Что lazy загрузка ломает всё в самом неподходящем месте. В итоге даже обычный CRUD превращается в головную боль.
всякие монады, стрелки, функторы это всего-лишь отображение сложности предметной области.
Монады, стрелки и функторы это мат. аппарат, который позволяет доказать свойства языка, задать ему семантику. Вас не заставляют эти вещи использовать для моделирования домена приложения.Монады, стрелки и функторы это мат. аппарат, который позволяет доказать свойства языка, задать ему семантику. Моделировать бизнес с помощью монад это прямой путь в дурку.
Математика это язык науки. Хочешь заниматься — учи язык.
А можно пример закона физики, который не записывается в виде формул?
И что значит «любая»? Он пыргает с 1 на другую? У него нет любой, она 1 и постоянно смещается.
Не было никакой проблемы описать орбиту меркурия формулой — даже тогда, когда эта формула не следовала из известных законов физики. Пронаблюдали положение достаточное количество раз, подогнали под точки кривую некоторого разумного вида — вот вам и формула. Величину прецессии его орбиты посчитали до теории относительности, как раз описав движение планеты формулой.
первый закон Ньютона,
… является частным случаем второго для F=0.
Почему не сводится-то?
Вы специально меняете свои комментарии после того как я на них отвечу?
любые газы при одинаковых условиях (объём/давление/температура) содержат одинаковое количество молекул.
А вы не задумывались, что это и есть формула, только записанная в нотации естественного языка?
На самом деле нет, не является. Первый закон утверждает, что всегда, в любой ситации можно найти систему отсчёта, являющуюся инерциальной. Я думаю, если очень надо, то его можно записать в виде формулы, правда смысла в этом большого нет.
Вот этот который?

Который так же является следствием известного F = ma
Это вы записали, что "тела, на которые не действуют силы, движутся равномерно". А первый закон — "существуют СО, такие что в них тела, на которые не действуют силы, движутся равномерно".
Ну я лично формулу взял из википедии, раздел "математическая запись первого закона".
И вопрос "Существуют такие СО" — а какие ещё существуют? Насколько я знаю, в нашей бренной вселенной никаких других и нет.
Наконец, если вам так хочется то допишите ∃world, ...
Ну, википедия она такая. Даже английская. Лучше загляните в хороший учебник. Это не хороший учебник, но здесь есть главная идея первого закона:
Первый закон Ньютона (или закон инерции) из всего многообразия систем отсчета выделяет класс так называемых инерциальных систем.
и собственно правильная формулировка:
Существуют такие системы отсчета, относительно которых изолированные поступательно движущиеся тела сохраняют свою скорость неизменной по модулю и направлению.
А ещё существуют неинерциальные системы отсчёта, в которых второй закон Ньютона не выполняется. И то, что можно всегда найти хотя бы одну инерциальную систему отсчёта — это нетривиально. (А то, что если есть хотя бы одна ИСО, то есть и много других ИСО, уже весьма просто доказывается.)
Мне дописывать не хочется, я не вижу в этом смысла. Но я считаю, что это возможно, хотя немного повозиться придётся.
закон сохранения энергии
Что, простите? В самом простом виде это либо E=const, либо dE/dt = 0.
Какое-то объяснение в плоскоземельном стиле что у понятий есть душа, и при записи не человеческими словами, а строгими формулами эта душа исчезает и что-то теряется.
Какой "частный случай"? Просто постулируется, что F = ma. Если сил нет, то ускорение — нулевое. Или вам не хватает окружения в стиле "наш мир устроен таким образом, что в нём верны вот такие вот формулы"? Ну, это называется контекстом. Вся эта лабуда про "инерциальные системы отсчёта" — это просто словесная шелуха.
"Первый и второй закон" это всё про исторические совпадения, не более того. Полагаю, как раз по причине нелюбви европейцеп к понятию нуля.
Точно также начала евклида рассказывают, хотя всем известно, что аксиома о параллельности там не нужна. Но "никто не собирается убирать из начал этот закон".
Ну так про что угодно можно сказать. Вон, вы говорили что "Бойля-Мариотта сводятся к формулам", но ведь там то же самое:
При постоянных температуре и массе газа произведение давления газа на его объём постоянно.
Ага, но в формулах нет ни слова про "газ", и попытки применить его, к, скажем, твёрдому телу, провалятся. Полуачается, и там к формулам не сводится? Если применить уравнение маятника не к маятнику, то тоже фигня выйдет. Ну и так далее.
Тогда физику вообще математикой описать нельзя, вообще ничего из неё, ведь какую формулу не возьми, там всегда словесный контекст, про что идет речь: газ, твердое тело, что речь идет про планету Земля (с определенными условиями в виде температуры/давления/...), и так далее.
однако всю эту "лабуду" вынесли в отдельный закон и объединять первый и второй законы Ньютона наука вроде как не собирается.
Не собираются, потому что уже никому особо не надо — принцип относительности Галилея ("в инерциальных системах законы механики одинаковы") просто трансформировался в более сильный принцип "для любых систем отсчёта все законы физики одинаковы". Применив это обобщение к электродинамике, получили СТО и КЭД, а применив к гравитации — ОТО.
Вы написали: "мало того, как правило, когда математик лезет в программирование — ничего хорошего не получается"
Я попросил бы развить этот тезис. Кмк это будет интереснее чем рубка на фоне физики, связанная с непониманием разницы между "необходимо" и "достаточно".
Я попросил бы развить этот тезис.Тут уже была длинная дискуссия. Краткая выжимка примерно такая:
1. Самое важное в программировании — документооборот.
2. Документооброт базируется на двух аксиомах: «Заказчик — всегда прав» и «Заказчик — не понимает, чего он хочет».
3. Если пустить в программирование математика, то он сходу же заметит, что эти два утверждения — противоречат друг другу, и потребует что-то с этим сделать.
Ну или, если совсем кратко: «главное в программировании — это не решить задачу, которую можно как-то сформулировать, но породить нечто, что позволит убедить заказчика в том, что всё, что ему нужно — он получил».
Разумеется при таком подходе не только математики, но и грамотные программисты — не нужны и даже, скорее, противопоказаны.
если внимательно её почитать, то «математик» сразу понял что хотят менеджеры,Нет. В том-то и дело, что он нифига не понял — кроме того, кого назначат крайним.
А он вздохнул и сказал «я профессионал».Потому что понял что постановки задачи ему не видать и что бы он ни сделал — он будет крайним.
Если бы он гарантированно знал что задача не имеет решения, он не согласился бы её выполнять ни под каким соусом.Бред какой. Любого человека можно заставить, при желании, делать что угодно. Кому-то нужно дать денег, кому-то — надавить коленом на горло (только аккуратно, да), кого-то — нужно розгами выпороть.
То, что человек берётся решать задачу, которая не имеет решения не означает, что он её понял и знает как решать — а означает всего лишь, что он понимает, что если он откажется её решать, то ему денег не заплатят. И всё. Вот совсем всё.
очень смешно, «гы-гы», но это именно пример плохого сотрудника.Про качество сотрудника там вообще сказать что-то сложно. А вот про менеджмент — легко.
он считал, что заказчик должен был сказать «я хочу чтобы вот там было две монады и четыре промиса»Причём тут вообще заказчик? Это задача менеджеров — переформулировать задачу в понятном и непротиворечивом виде.
а он сказал «хотим параллельные линии в виде котика».Именно так. А посмольку эта фраза — бессмысленна, то требуется уточнение и перевод техзадания в «машинно-читаемый формат».
Если этого не сделано — то вообще неважно какого качества у вас программисты, важно лишь какое качество у вас демагоги.
Потому что задачу вы всё равно не решите, но, при наличии людей с хорошо подвешенным языком, сможете убедить заказчика в том, что она решена.
Причём тут вообще заказчик? Это задача менеджеров — переформулировать задачу в понятном и непротиворечивом виде.
Поправка: это задача аналитиков.
Поправка: это задача аналитиков.Там у них не было аналитиков.
Да и, в данном случае, неважно кто, важно как и что.
Либо вы пытаетесь перевести задачу с языка «линий в форме котят» на что-то, похожее хоть на какую-то формулировку в терминах монад и промисов — с целью потом эту задачу реализовывать (в этом могут участвовать и заказчики и менеджеры и программисты, конечно).
Либо вы ищите «козла отпущения», так как деньги, полученные от заказчика вы уже мысленно (или не совсем мысленно) распределили, сама задача вам неинтересна в принципе… ну а отдуваться, когда заказчик, в конечном итоге, будет метать громы и молнии — кому-то надо же?
Там, собственно, с самого начала всё предельно понятно — когда «взваливают на себя проблемы» и заявляют «мы же это можем» вовсе не те люди, которые потом всё это будут реализовывать.
Ну и дальнейшая вся эта муть с постоянным рефреном «вы же профессионал». Которым этого несчастного Петрова обкладывают, как волка — красными флажками.
Я, в таких условиях, обычно сразу заявляю: нет, я вот нифига не профессионал. Ни разу. У меня и сертификатов-то никаких нету и вообще я по образованию математик. Но функционального программирования не знаю. И про монады — только в общих чертах.
Да, есть десятки завершённых проектов. И код, установленный на миллиарде компьютеров — тоже есть. Но это всё так — случайно получилось. Если хотите, чтобы я вам пообещал, что всё будет в лучшем виде — это не ко мне.
Вот если что-то нужно попробовать сделать — это можно обсуждать. А давать обещания, которые я не знаю смогу ли выполнить (и потом, разумеется, «отдуваться» за их неисполнение) — это не ко мне. Извините. Если «Сидоряхин не видит проблемы» — то путь он и «рисует». Только потом чур — не плакать и не просить починить, когда оно всё «развалится».
я при этом думаю что Ваш сценарий менее реалистичен. ибо в Вашем случае у нас не специалист и рано или поздно он был бы заменён специалистом
Неа, не был бы. Просто потому что проблема тут не в человеке, а в самом месте.
Это если в городе, а то и стране, вообще есть другое место работы. И если он работает не по распределению контракту, приложенному к кредиту на образование. И если он работает не ради стажа работы, без которого его просто не возьмут на нормальное рабочее место. И если он — не мигрант с рабочей визой, которая автоматически закончится при увольнении.
Напомню, что в этой истории нет никакой явной привязки ни к стране, ни к настоящему времени.
я при этом думаю что Ваш сценарий менее реалистичен. ибо в Вашем случае у нас не специалист и рано или поздно он был бы заменён специалистомКак и зачем? Видно же, что задача Петрова — «получать люлей». А задача всех остальных — делить деньги, порождённые его деятельностью.
Что на такой должности, извините, будет делать специалист у которого есть возможность выбора и который, скорее всего, не будет всё это безобразие терпеть?
В данном случае мы не видим — является ли Петров «специалистом с ипотекой» (как mayorovp предполагает) или «неспециалистом» (как его, почему-то, называете вы)… но чётко видно: его роль в этой истории — не кому-то что-то объяснить. Его роль — быть продемонстрированным заказчику… и убедить его в том, что «всё будет хорошо». Больше от него ничего не нужно, на самом-то деле.
Ему активно не дают уточнить задачу и сделать её нормально — потому что это неважно. Не в этом смысл этого совещания и не в этом его цель. Если заказчика вот прямо сейчас не «ублажить», не дать ему почувствовать свою крутизну — то количество денег, которые можно будет поделить… уменьшится.
А поскольку «крайний», тот кто будет виноват и будет, потом, отдуваться — уже известен… то мы и имеем то, что имеем.
Ну ёлки ж палки, как это можно было пропустить! Вот сама эта фраза мы его специально пригласили на совещание, чтобы он высказал свое компетентное мнение в сочетании со всем совещанием, где ему не дают просто высказать никакого мнения — это чёткая картиника: демонстрация заказчику вот именно того человека, наказанием которого, в будущем, заказчик должен будет удовлетвориться. Подготовка будущего «козла отпущения».
А уж как и почему Петров согласился работать на должности «козла отпущения»… история умалчивает, да.
Люди же пишущие код, даже серьёзный, наукой не занимаются, как бы им не хотелось.Ну тогда вообще никто наукой не занимается. В том числе те научные журналы, куда попали статьи с моим соавторством.
А я как раз практические вещи в компиляторе делал, это мой руководитель статьи писал (часто бывает наоборот — руководитель только подписывает… в данном случае я получил статью уже написанную проверить нет ли ошибок в описании той части, которой занимался я).
Если вкратце по итогам, тот как-то так получится:
Можно ли жить в функциональном мире без функторов и монад? Можно.
Но, если мы хотим вовсю использовать всю силу Алгебраических Типов Данных, нам для удобной функциональной композиции различных функций придётся использовать функторы и монады.
Ибо это отличное средство от рутины и путь к краткому, понятному и часто пере-используемому коду!
Является ли Observable из rxjs монадой?
Я сегодня побуду таким «Робертом Киосаки от функционального программирования»Скромность наше все, но статья классная, спасибо
Надо излагать как можно проще, но не проще!!!
Вот в этой таблице "императивно-декларативно" — в колонке "декларативно" указаны императивы! Разница только в том, что в колонке "императивно" сделана декомпозиция до мелочей.
И неправда, что разработка сверху вниз = декларативность.
И неправда, что декларативность — это "скомпилировалось = работает".
Фигак-продакшен всяких эскизов на прологе.
Эрланг с подходом "let it crash".
Я понимаю вашу очарованность хаскеллом, но зачем врать-то?
Самое забавное, что в следующих абзацах вы говорите "ну, я утрировал и крошил батон на императивщиков, так-то и на сях люди сверху вниз пишут".
А можно было не утрировать?
Ведь после этого возникает вопрос: а какие ещё натяжки вы раскидали по статье?
Теоркат вы накидали исключительно в объёме, необходимом и недостаточном для хаскелла. Прямо больно читать.
Конечно же, — нет, вот этот (бес)толковый словарь не является введением в ФП.
Что с того, что какие-то монады являются какими-то контейнерами.
Вы или не поняли главного, или не придумали, как это внятно рассказать.
А главное состоит в том, что… есть в ООП такой паттерн: "Шаблонный Метод".
Когда вы некоторым однотипным способом комбинируете операции, составляющие детали реализации, — и результат ожидаемо обладает какими-то нужными вам свойствами.
Так вот, функции над монадами — это и есть шаблоны, позволяющие минимально учитывать специфику конкретных монад. Почему именно монад — потому что это группа с единицей (и зачастую с нулём), — как бы минимальный интерфейс для комбинирования уже есть, и математически изящный, и жизненный.
ФП вообще держится на функциях высшего порядка, то есть, на всё том же Шаблонном Методе.
И именно математическое изящество подвело к тому, чтобы группу, но с другой бинарной операцией формализовать как аппликативный, а не мультипликативный, функтор.
Ну и, поскольку всякая группа — это группа, то монада — это тоже аппликативный функтор. Вот так-то!
Ключевое:
- как — функции высшего порядка
- зачем — Шаблонный Метод
Потому что сами по себе ФВП — это инструмент. Ну есть и есть, ну лямбда-исчисление… и дальше что?
А то, что через них легче выделять абстракции — те самые аспекты.
Просто ООП в этом деле более многословно.
Я бы добавил, что ФП еще и типах высшего порядка держится, без них не сделать монады обобщенными.
Любую конструкцию можно спроецировать в безтиповое лямбда-исчисление :)
Только тогда — либо гигиену придётся с компилятора переложить на программиста, либо все неявные вещи (например, словари членов модулей и тайпклассов) делать явными — опять же, сделать некоторый рутинный объём работы за компилятор.
И место с монадами — во многих таких статьях описывается похоже и откровенно вводит в заблуждение (я читал похожее, когда ещё не знал ФП, меня обманули тогда и обманули бы вы сейчас).
Я бы хотел, чтобы 6 месяцев назад мне объяснили как-то так (если бы мог объяснить сам — написал бы статью):
1. Есть функциональная парадигма (с чистыми ф-иями и иммутабельными данными. Даст она вам то-то и то-то). В промышленных языках давно поддерживается её имитация (map, reduce, lampda....)
2. Сама по себе функциональная парадигма «вычислительно слабее». Для удобства, краткости кода (и для того, чтобы хоть частично компенсировать «отставание вычислительных возможностей» ФП) прямо-таки напрашиваются вот такие улучшения: ВФП, lambda, Curring. А также вот такие: Functor, Applicative, Monad.
3. Функтор, это просто контейнер (функтор уже контейнер, умеющий помещать в себя значения, да!)
Монада — это тоже контейнер. Зачем нам «ещё контейнер» — у монады можно реализовать достаточно сильную логику, отдельно для обработки элементов, а отдельно для контейнера.
Пример? Пожалуйста? Цепочка вычислений на Maybe (когда нам не нужен «бойлерплейт» код для плохих случаев). Хорошо переписывается с поддержкой логов в виде монады Writer.
Я бы хотел, чтобы 6 месяцев назад мне объяснили как-то так
используйте ФП для заведомо известных неизвестных проведений, не ошибетесь.
Пример 1. Работа с сетью, хочу получить Box.
Известно:
проблема с сетью
проблема с днс
проблема с сервером
проблема с токеном
Неизвестно:
какая проблема и когда.
Функции:
повтор (сколько раз?)
обновление токена (если надо)
Обработка Response в Box
фильтры, сортировки, разворачивание списков? Да.
В статье про борщ это интересно описано.
Всё что выше я написал становится библиотечным и применяется к каждому (по необходимости) запросу.
Сравните это в кодом на уровне ООП.
Пример 2. Память
Не хватает памяти?
Функция очистки.
Всё тоже самое, известное неизвестное поведение.
Пример 3. Хотите закешировать данные? Пф :)
А вот контейнеры/монады и другие штуки это конкретный инструмент.
Вообще примеры типа приведённого в статье «варения борща» ужасны для программирования.
Приведённый вами пример (для удалённого доступа) просто очень неудачен для FP, кмк (для Haskell в частности). Потому, как само по себе ФП очень тяжело ложиться на низкоуровневые вещи (хотя бы потому, что любое обращение к аппаратуре — IO, т.е. завёрнуто в свой слой монадок).
Я бы, на самом деле предпочёл цепочку вычислений из «открыть файл» -> прочитать строки -> преобразовать каждую строку -> вывести.
Всё это завёрнуто в Maybe. Тогда и «бойлерплейта» обслуживающего плохие случаи не будет.
1. Обязательно ли ФЯП должен быть «ленивым»?
2. какая математика нужна понимания ФП? Для Пролога достаточно понимания рекурсии и логики предикатов, а в С можно сразу сесть и начать данные между ячейками памяти перекладывать.
Тогда другой вопрос: достаточно легко понять (ну, с ростом длины программы или из-за урезания сроков разработки) зачем нужны принципы императивного программирования и ООП, почему паттерны — это часто удобно, зачем нужны чистые функции и чем плохо глобальное состояние, но сколько ни читаю про монады и функторы не понимаю, в какой ситуации заорал бы «о, вот тут с монадой было бы гораздно понятнее!». Не поделитесь, как лично вы перестали бояться и полюбили монады?
чем адаптер отличается от фасада и от декоратора
(Знаю, что никому в общем-то неинтересно, но отвечу всё равно)
Адаптер — это приведения API вашего модуля в форму более удобную для клиентского кода. Сам модуль поведения не меняет, меняется формат вызовов. Такое часто делают для библиотек ведения лога, когда приложение заводит себе внутренний интерфейс с теми же методами logError, logWarning, logDebug, и пишут адаптеры для аналогичных типов из библиотек, которые дёргают те же по смыслу методы из библиотеки. Удобно тем, что можно библиотеку сменить, и в коде приложения нужно будет поменять только сам адаптер.
Фасад — это сокрытие части API вашего модуля от клиента (чтобы он мог делать только "безопасные" вызовы, где фасад берёт ответственность за ненарушение каких-нибудь инвариантов). Или же напротив, фасад может объединять несколько модулей под одной крышей, чтобы создать нечто вроде единой панели управления. Ненарушение инвариантов по-прежнему важно.
Декоратор — это изменение поведения объекта без изменения API. Например, unmodifiableCollection в Java, из которого можно только читать, но попытка изменения содержимого (например, вызов add) приведёт к ошибке (да, я прекрасно знаю, почему так делать плохо и что нужен отдельный ReadableCollection). У нашего проекта, например, есть декоратор, который в зависимости от политик приложения делает вызовы некоторых API no-op в строгом соответствии с требованиями — потому что некоторые не хотят оплачивать полный функционал, и тягать проверки политик повсюду в итоге оказалось затратнее, чем сделать и поддерживать один декоратор.
Споры там в основном не что такое сам паттерн, а как обозвать конкретный пример — большинство из них обычно объединяют как минимум два из трёх, иногда все три и ещё парочку дополнительных сверху.
Upd: Если хорошенько подумать, то адаптер и декоратор как шаблоны вполне функциональны, и могут применяться и в ФП. С фасадом сложнее, так как единственная приходящая мне в голову аналогия фасаду в ФП это каррирование, что вообще говоря не совсем то что нужно.
фасад — похож на редьюсер специфический, а вообще бытует мнение, что бОльшая часть той же GoF — ООП костыли для эмуляции функциональных примитивов.
фасад — похож на редьюсер специфический
Чем это он похож на редьюсер?
а вообще бытует мнение, что бОльшая часть той же GoF — ООП костыли для эмуляции функциональных примитивов
Ага, а функциональные примитивы нужны для эмуляции ООП. Причём это не изормормизм: при замене паттернов на "эмулируемые" примитимы туда-сюда несколько раз код превратится в лапшу.
Чем это он похож на редьюсер?
Сводит множество сущностей в одну.
Фасад не сводит множество сущностей в одну, он меняет/ограничивает API 1..n сущностей. Сведение — это только частный случай, и далеко не самый распространённый. Я намного чаще применяю этот шаблон для того, чтобы из M методов API, все из которых нужны моему модулю для внутренней кухни, выделить подмножество M1<M методов, которые я стабилизировал и теперь могу отдать наружу клиентам моего метода, потому что для M1 я предоставляю гарантии, обратную совместимость, предупреждаю об их грядущих изменениях за несколько релизов, и прочие полезные плюшки, тогда как оставшиеся M2 остаются в моём полном распоряжении, и с М2 я творю что мне угодно. То есть если клиент зависит от М1, ему гарантируется работоспособность как минимум на два мажорных релиза вперёд, а вот если от М2 — ССЗБ, могу сломать ему теплицу.
Если вам понятны паттерны ООП, могу привести следующий пример. Приходила ли в голову хоть раз идея комбинатора итераторов, который бы обходил вложенные коллекции?
Если да — то такой комбинатор работает как операция bind, делая паттерн "Итератор" монадой.
А для Ъ ФЯП вообще стратегия вычислений неважна из-за strong normalization theorem
Насколько я знаю, strong normalization theorem не работает в тьюринг-полных исчислениях. То есть как только задача требует тьюринг-полноты (например, написание интерпретатора Javascript) — стратегия вычислений сразу же становится важной.
Ну нет, fuel — это уже изменение наблюдаемого поведения (не говоря уже о дополнительном замедлении, которое вроде как можно игнорировать).
Правильный интерпретатор при выполнении конструкции while(true) { } обязан зависнуть, а не упасть спустя 2^100500 тиков :-)
Правильный интерпретатор при выполнении конструкции while(true) { } обязан зависнуть, а не упасть спустя 2^100500 тиков :-)Только на практике-то это нереализуемо, так как с некоторой вполне себе ненулевой вероятностью реальный процессор откажется ведь исполнять безусловный переход. Космические лучи и всё такое…Это потому-что его не умеют обьяснять нормально. Начинать надо с «что это, использовать вот так, как это всё упрощает», а не копипастить научные работы всяких PhD без опыта промышленного программирования.
Я вот вроде из ЦА статьи, но понимания не добавилось. Разве что мелькнула мысль, что я несколько раз решал схожие проблемы с помощью ООП.
Например, дан метод, принимающий на вход большую декларативную структуру данных (если кому доводилось заполнять огромные анкеты на много листов со вопросами "1. есть А? 2. Если "да" заполните сколько есть, 3. если "нет" — почему нет...), граф, может даже цикличный немного :), и должный вернуть success или fail, произведя кучу сайд-эффектов по определенному флоу, или не кучу, а только запись в логе типа "filed email is required, failed". При реализации в лоб куча if, for и т. п., перемешанная записью в логи — любое изменение логики флоу превращалось в ад. Какая-то декомпозиция, конечно, проводилась, но, в основном, на шаги флоу и сайд-эффекты, а основная логика одним сплошным потокм
Относительно красивое и поддерживаемое решение пришло как-то само собой:
флоу описываем декларативно (yaml например), пошагово. Каждый шаг может быть полноценным flow (типа композит) со своими шагами. "Шаг" — условное название, без явных зависимостей от других шагов шаги могут исполняться условно параллельно-асинхронно
обработчик конфига "компилирует" его в граф "трансформеров", где узлы — функции, либо чистые, либо принимающий на вход некий объект flow state и возвращающие его модифицированный клон, а рёбра — потоки данных от шага к шагу с условиями.
основное ветвление было на уровне вернул "трансформер" null или state и тогда следующий трансформер возвращал null всегда, но были и более сложные, включая рекурсию и циклы и даже разворачивание хвостовой рекурсии в цикл для простых случаев (из любви к искусству)
исполнитель флоу, "интерпретатор" на базе генератора принимает на вход "скомпилированный" граф команд и собственно входные данные и на каждой итерации вычисляет все чистые функции, аргументы которых уже вычислены, или исполняет мутирующие внешние состояния команды, аргументы которых тоже вычислены, такие как запросы к базе данных и к логам или отправка сообщений. Если флоу не сложный, то за несколько чистых итераций получаем по сути набор команд с готовыми параметрами, которые нужно тупо выполнить: insert/update/delete запросы к базе, отправить нотификации, сделать записи в логах, или просто заэмитить событие в шину, а там уже воркеры разберутся
Как-то очень напоминает, по-моему, то, что описано в посте и комментах — все вычисления и, особенно IO откладываются до момента когда без них никак, а сама логика по сути чистая. Я "изобрёл" ФП? :)
А по сути, все мои попытки изучить "настоящее" ФП всегда затыкались на моменте, когда вводится та или иная система типов не просто как типы бизнес-данных и параметров и результатов функций, сигнатуры функций по сути, а специальные "функциональные" типы вроде проимов в typescript. Всё, после этого ступор. Неужели ФП нельзя делать без типов? Пусть без гарантий, ожидаемых от типов, с кучей явных и неявных ошибок в рантайме, но без типов?
Как-то очень напоминает, по-моему, то, что описано в посте и комментах — все вычисления и, особенно IO откладываются до момента когда без них никак, а сама логика по сути чистая. Я «изобрёл» ФП? :)Ещё нет, но вы движитесь в правильном направлении.
Пусть без гарантий, ожидаемых от типов, с кучей явных и неявных ошибок в рантайме, но без типов?Легко. Lisp называется. 1958й год.
Только проблема в том, что если у вас все эти ошибки в рантайме — то вы не так много выигрыша от отделения «чистого» и «нечистого» кода получаете. А дальше, если вы попытатесь «научить» компилятор давать вам гарантии — у вас и типы возникнут и монады и прочее.
Оно всё, на самом деле, возникает как обощение вот примерно подобных конструкций. Десятое правило Гринспена в действии.
Легко. Lisp называется. 1958й год.
Писал на одном из диалектов когда-то. Ну как писал, поддерживал небольшую унаследованную систему. Как-то не появилось ощущение, что прикоснулся к ФП, странная по синтаксису процедурщина и даже ООП.
Только проблема в том, что если у вас все эти ошибки в рантайме — то вы не так много выигрыша от отделения «чистого» и «нечистого» кода получаете.
Я больше про обучение ФП. Чтобы отдельно изучить ФП, а уже потом с типами заморачиваться.
Не знаю, кто лисп считает ФП. Вон, прямо пишут, что лисп НЕ фп. Лисп это скорее язык построенный из одних только макросов, на обычные парадигмы вообще плохо натягивается. Лисп это лисп, имхо.
Я больше про обучение ФП. Чтобы отдельно изучить ФП, а уже потом с типами заморачиваться.
Если формально ФП с типами не особо связано, то практически фп это типы, а типы это ФП. Да и много ли времени надо, чтобы понять концепцию "пишите ссылочно прозрачные функции"?
Ну вот видимо у нас система была построена на макросах, имитирующих ПП и ООП, а не на имитирующих ФП :)
Много времени надо чтобы разбирать малопонятные ошибки типов, когда дело касается чисто функциональных типов, а не типов входных и выходных данных. Не, наверное, можно набить руку или, другими словами, натренировать свою нейронную сеть грубым брутфорсом обходить ошибки типов без их особого понимания, но как-то не хочется.
Ну в хаскелле ошибки слишком общие бывают "вы попытались построить бесконечный тип", в идрисе с этим получше. Там всегда пишут, что не так и как можно поправить.
Вопрос качества ошибок немного ортогонален самому ФП или не ФП. Просто типы надо использовать, чтобы не ловить "Невозможные" ситуации в рантайме.
Ну вот может идрис стоит попробовать, если пишут как поправить. пускай не понимая про типы, но начиная понимать про ФП.
Ну я где-то половину книжки по идрису прочитал, мне очень нравится. В прод такое конечно не напишешь, пройдет лет 10 пока идеи попадут в мейнстрим, но по крайней мере часть идей и подходов можно применить уже сейчас, а когда появится быть человеком, который уже в курсе и может применять. То есть, это не "изучать в стол", а просто подготовиться заранее.
Ну и в целом, компилятором гарантировать что операция конкатенации двух списков всегда закончится успешно списком той же длины, что и переданные, это очень приятное чувство уверенности в своем софте.
Как миниум, конкатенированные строка может превысить максимально допустимую длину строки
Почему невозможно?
append : FixedSizeString n -> String
-> (result : String ** len (result) <= n = True)
...Мы одинаково понимаем слово «доказательство»? Ты заявляешь если А то Б, и доказательство это процесс перехода от А к Б, чтобы показать истинность этого суждения. Ну это мое примерно представлние.
Ты говоришь «есть 2 строки» — А
докажем что «суммарная длина не больше n» — Б
принципиально невозможно этого доказать не зная длину строк и не накладывая на них условий типа, обе строки <n/2
Можно, достаточно написать функцию:
parseFixedString : String -> Maybe (FixedSizedString n)Я ж про это статью переводил.
Данные по сети тоже можно таким образом проверять, про это 0xd34df00d писал свою статью (и комменты)
Это не подмена понятий. Для множества всех строк очевидно это невыполняется, но речь не об этом. Мы можем доказать, что есть множество строк, конкатенация которых меньше n, ну а потом просто проверяем, принадлежат ли переданные нам строчки этому множеству или нет.
Доказывать невозможное — невозможно, я с этим и не спорил
Ну я имел в виду zip. Который из двух списков возвращает список пар элементов на соовтветствующих индексах. Что делать для списков разных длин — непонятно. Стандартным решением является укорачивать его до самого короткого, но не всегда это желательное поведение.
Хаскель не отправляется, скала — в экосистемах не построенных на чистых ИО — да, идут.
В лиспе распространенной ФП экосистемы я не встречал.
Хаскель не отправляетсяЛяпните тоже. Отправляется, конечно.
А то кто-то ещё, вдруг, может и поверить, что "
printf-стайл дебаггинг" в Haskell отменили.В лиспе распространенной ФП экосистемы я не встречал.Что такое «распространённая ФП экосистема»?
А то кто-то ещё, вдруг, может и поверить, что "printf-стайл дебаггинг" в Haskell отменили.
Утверждение из разряда "в расте есть ансейф, так что это те же плюсы".
Что такое «распространённая ФП экосистема»?
Экосистема, на котороый кто-то пишет и можно увидеть существенное количество проектов с пользователями.
Утверждение из разряда «в расте есть ансейф, так что это те же плюсы».Нет. Утверждения из разряда: в Rust, благодаря
unsafe можно писать код, как на плюсах.И да, это утверждение абсолютно верно и если вы скажите «язык, на котором можно писать небезопасный код — небезопасен», то Rust придётся-таки записать в «небезопасные».
Но и заявления типа «в Lisp можно писать функции с побочными эффектами, а значит он нефункциональный» — они из той же опера.
Экосистема, на котороый кто-то пишет и можно увидеть существенное количество проектов с пользователями.Вы тут одно непонятное слово заменили на три непонятных слова. Что такое «кто-то пишет»? На Lisp много кто пишет — но вас это, почему-то не устраивает. Что такое «существенное количество проектов»? 10, 100, 1000? И почему? Что значит «проект с пользователями»? GnuCash — это проект с пользователями или без?
Так можно разговаривать до бесконечности.
Вы тут одно непонятное слово заменили на три непонятных слова. Что такое «кто-то пишет»? На Lisp много кто пишет — но вас это, почему-то не устраивает. Что такое «существенное количество проектов»? 10, 100, 1000? И почему? Что значит «проект с пользователями»? GnuCash — это проект с пользователями или без?
Ну, каких-то измеримых характеристик я не готов давать. Интуитивно: в скале есть ФП коммьюнити, всякие cats/zio/monix/.., в сишарпе, джаве, лиспе и так далее — его нет.
А так то да, любое понятие можно «экспертной оценкой» вводить. Только рассуждать потом плохо получается…
Просто есть дисперсные характеристики, а есть ковариационные. Хорошо, когда можно дать простые и измеримые критерии. В данном случае я не могу, увы. Для ИДЕ это куда проще: какие есть фичи, и что из этого нужно/не нужно.
А тут вопрос из разряда "что такое ООП" — сколько людей, столько мнений.
А тут вопрос из разряда «что такое ООП» — сколько людей, столько мнений.Это-то да. Вон — прямо соседняя же статья про это.
Ляпните тоже. Отправляется, конечно.
У функций Debug.Trace в некотором смысле нет наблюдаемого поведения, а потому они никакой чистоты не нарушают.
Эдак можно константы менять в отладчике или через /proc/self/чтототам, а потом на язык бочку катить.
У функций Debug.Trace в некотором смысле нет наблюдаемого поведения, а потому они никакой чистоты не нарушают.Там целая подсистема есть, на её основе можно развести сколько угодно вполне себе наблюдаемого поведения.
Это помимо того, что собранную трассу можно, в другой части программы, открывать как файлик и вполне себе использовать.
Давайте всё-таки исходить из того, что цель программиста — написать нормальную программу, а не вырезать гладны через задний проход или там написать пост в хаб "Ненормальное программирование"?
Конечно можно, side channel attacks так же работают. В той же криптографии функции выполняющиеся не за константное время считаются бажными, соответственно замеряя время рассчета какого-нибудь хэша (это фичтая функция офк) можно делать какие-то выводы.
А ещё можно температуру ЦПУ к сайдэффектам приписать. Тогда "нетути вашей чистоты нигде, практики опять победили!!1"
Внезапно оказалось, что разработчикам на Python слова вроде «Монада», «Функтор» и уж тем более «Апликативный функтор» – не знакомы совсем.
Потому мы пришли к другому решению: выкинуть все сложные слова. И заменить их более интуитивно понятными. Монада = контейнер. Функтор = Mappable.
А все объяснения «зачем?!» строить через решение понятных практических задач. Например:
— Монады можно использовать для обработки ошибок вместо исключений
— А еще для внедрения зависимостей
— Ну и чтобы писать асинхронный код!
На мой взгляд — сработало отлично! Многие только потом узнали, куда они ввязались.
Имхо, статья только запутывает. Мне вот трудно понять монады и т.д., но в таком изложении тоже трудно, и вдобавок ещё и неправильно теоретически. Лучше уж грызть правильные объяснения, или просто. Начать с практики. Linq, например, помогает хотя бы один пример понять. Второй — монада maybe
В идеале, в разделе Прошу к столу еще бы реальных примеров из промышленных языков, вроде C#. Например, как я понял, List — монада, Select — функтор, предикат — морфизм (Func<T, T> — эндоморфизм). А еще, где может пригодится собственноручное приготовление монады, отталкиваясь от какой-нибудь бизнес-задачи.
Нет, вы неправильно поняли. Автора не просто так критиковали...
List — не монада, у List в C# нет простого аналога операции bind. Зато монадой является интерфейс IEnumerable.
Select — не функтор. Функтором является, опять-таки, интерфейс IEnumerable.
А собственноручно готовить монаду под бизнес-задачу, скорее всего, вам долго не понадобится. Их и на Хаскеле "готовят" крайне редко, чаще комбинируют несколько трансформеров. Но в C# аналогов трансформеров монад нет и быть не может, из-за отсутствия HKT.
Преимущество автора в том, что он объясняет на привычном языке программиста: даже вы, отвечая сейчас, накидали терминов на квадратный см (как и Psyhaste в своих статья, хотя они могли стать эталоном погружения в ФП:) Ведь непонимание теорката не мешает пользоваться LINQ-ом, но хотелось бы и реальных примеров (не использования библиотечных конструкций из ФП): например, как ФП уделывает аналогичный проект на C# с описанием в чем именно (вот бы вместо очередной статьи с азами, переписал бы кто-то из авторов тот же eShopOnContainers на F#). А то обычно в примерах функции с парой циклов :(
Но в терминах, определенных автором, как мне кажется, List подходит
Это лишний повод не читать пост автора. Зачем на пустом месте плодить неоднозначности в терминологии? Чтобы потом новички вроде вас запутывались ещё больше?
Преимущество автора в том, что он объясняет на привычном языке программиста: даже вы, отвечая сейчас, накидали терминов на квадратный см
Вы предлагаете объяснять термины не употребляя терминов? Это как вообще?
вот бы вместо очередной статьи с азами, переписал бы кто-то из авторов тот же eShopOnContainers на F#
А чем бы это помогло пониманию монад? На F# нет монад как абстракции точно так же, как их нет в C#. Да и всё ФП на F# сводится к тому, что там есть функции и синтаксис ML-подобный.
Ожидал примерно такого комментария от «академика» (в хорошем смысле слова, странно что первым был не дедфуд:) Но в терминах, определенных автором, как мне кажется, List подходит, пускай и неверно с научной точки зрения. Конечно, были бы в статье правильные аналогии из мейнстрима, было бы еще лучше.
List — монада ровно в той же степени, как цикл for — инстанс интерфейс IQueryable. Нужно очень сильно напрячь воображение, чтобы эти две вещи считать "Одним и тем же".
В хаскеле функция такой обработки называется bind (>>=), что имеет корни в Теории Категорий. Ведь bind – это «связывание», т.е. функция bind фактически создает ребро в графе категорий (связывает узлы). В большинстве языков «здорового человека» эта функция называется map() («отобразить», «поставить в соответствие»).
bind — это flatMap, а уж никак не map.
К слову, насколько я понял, общаясь в хаскель чате, бинд — это плохое название, и флатмап куда лучше. Но, по историческим причинам (как и return), осталось что осталось.
А почему эту операцию для других монад нельзя тоже назвать flatMap?
Это flatMap для любой монады, потому что оно определяется как
flatMap f x = flatten (map f x))где flatten : m (m a) -> m a логичен для любой монады, ведь он убирает один уровень вложенности

Не соглашусь. flatMap аналог bind и для других монад. Посмотрите как это сделано в Scala.
Изучение ФП делает разработчика профессиональнее. Я даже не буду приводить ссылки на пруфы, потому что в 2020 это уже просто незыблемая истина.
— такая аргументация не очень подходит для взвешенной статьи. Зачем оно всё-таки там, где успешно применяется императивное, так и не объяснили. Обычно в защиту ФП говорят про тестируемость и лёгкую взаимозаменяемость, но у вас об этом практически нет.
И, кстати, редко кто говорит об обратной стороне: плохую читаемость кода, если это большой проект. Больше ФП — нужно больше документации на каждую функцию (читай, на каждую строчку кода). Я из мира JS, тут у нас ФП худо-бедно внедряют, но вот это вот getSomething(one)(two)(three) не сказать чтобы помогает в разработке и как-то упрощает/снижает трудозатраты/понижает порог входа. Просто модно, и всё
В жса особого ФП нет, а читаемость затрудняет не ФП само по себе, а то что в языке ничего нет для упрощения. Для ООП парадигмы в языке тонну всего есть: классы/прототипы/декораторы всякие, и прочая лабуда. Для ФП — ну вот вам стрелочки, пишите. Этого ведь недостаточно.
Обратная стороная ФП это то, что разработчику с 5+летним стажем нужно взять и на полгодика снова очутиться на скамье ничего не понимающего джуна, который постигает неведомые области. Большинству же кажется, что бабки и так мутятся, так чего же напрягаться. А жаль.
взять и на полгодика снова очутиться на скамье ничего не понимающего джуна— для чего, чтобы что?
Большинству же кажется, что бабки и так мутятся, так чего же напрягаться. А жаль— жаль чего конкретно? Разве не суть работы программиста, чтобы у бизнеса бабки мутились? Нет, конечно, вперёд надо смотреть, и вширь тоже, и даже вглубь, но какой конкретно параметр улучшает переход на ФП? Можно как-то объяснить, за что надо платить ценой ломки мозгов? Люди может быть и хотели бы, но нужна какая-то разумная мотивация, что ли
для чего, чтобы что?
Чтобы тратить на задачу на день, а час, и решать её так, чтобы не пришлось в будущем страдать.
жаль чего конкретно? Разве не суть работы программиста, чтобы у бизнеса бабки мутились? Нет, конечно, вперёд надо смотреть, и вширь тоже, и даже вглубь, но какой конкретно параметр улучшает переход на ФП? Можно как-то объяснить, за что надо платить ценой ломки мозгов? Люди может быть и хотели бы, но нужна какая-то разумная мотивация, что ли
Речь не про бизнес, а про программиста. Который может сделать задачу нормально за день, а может за час, а потом ещё за месяц закрыть десяток тикетов с багами и доработками. Мог бы сделать сразу нормально — но не умеет.
Люди часто догадываются, что какие-нибудь базовые архитектурные паттерны вроде MVC или слойной архитектуры или там репозиториев стоит подучить, а дальше — всё, труба, получил молоток в руки — баа, а вокруг всё — гвозди!
Мог бы сделать сразу нормально — но не умеет.— так почему «нормально» — это ФП? Очередная серебряная пуля?
а дальше — всё, труба, получил молоток в руки — баа, а вокруг всё — гвозди!— ну, что-то похожее про адептов ФП можно сказать, во всяком случае, во фронтенде. Даже React не пощадили
так почему «нормально» — это ФП? Очередная серебряная пуля?
Нормально — это будучи вкурсе всего спектра возможных решений. ФПшники в ооп обычно неплохо шарят и применяют где надо концепции оттуда, а вот наоборот — не очень.
ну, что-то похожее про адептов ФП можно сказать, во всяком случае, во фронтенде. Даже React не пощадили
В реакте попытки в фп были только в редаксе, и то не особо удачные.
P.S. Зачем каждое своё сообщение с префиксом "—" писать? Это придаёт веса, круче выглядит или просто глюк клавиатуры?
P.S. Зачем— нравится
В реакте попытки в фп были только в редаксе, и то не особо удачные.
А как же функциональные компоненты? Да и вообще концепция DOM — чистая функция от стейт?
А что значит особый ФП, а что не особый? Есть какой-то минимальный набор характеристик, чтобы сказать, что в JS для полноты ФП не хватает того-то и того-то? Вот уже пару раз в комментах тут упомянуто, что типы для ФП не нужны от слова совсем. Что-то ещё есть, что вроде как считается неотъёмлемой частью ФП, чего нет в JS (и нельзя реализовать императивными средствами внутри чистой функции).
Речь не про практическую применимость типа нельзя пользоваться языком, если он не оптимизирует хвостовую рекурсию, а именно писать идиоматический ФП код.
Ду нотация общего вида и ХКТ как базовый минимум. Впрочем, как уже выше писали, ФП для динамики это вещь такая, а в тайпскрипте уже начинаются проблемы с энкодингом всего этого в рантайме. Большее распространение итераторов вместо того чтобы массивы создавать на каждый чих. Ну, вот это всё..
Если правильно нагуглил, то do-нотация — это сахар для монады, а ХКТ — что-то про типы. Если остаться в русле "безтипового" JS, то нужны только монады? Или монады всего лишь тип, который можно сделать на классах или прототипах, как можно сделать тот же промис.
Ну мне вообще неясен смысл ФП в бестиповых языках. Смысл ФП — вот мы пишем всё в ссылочно прозрачном стиле, это местами не очень удобно, зато у нас функции всегда можно композировать и они дадут ожидаемый результат. А если не композируются, то компилятор выдаст ошибку.
А если нет компилятора, который выдает ошибку, то как это должно работать? Плюс, всё реальное взаимодействие происходит мутабельно со всякими нехорошестями. Что, обтягивать всю стандартную библиотеку в IO? Все лефтпады с npm?
ФП это не только сам язык, но и экосистема. У скалы например есть и ФП экосистема, и ООПшная, все эти спарки/спринги.
Без экосистемы подход не нужен, это ведь вроде всем понятно. Пока под жс есть только awesome-fp-js, который по отзывам что я слышал — не очень.
Ловим ошибки в рантайме, на "проде" или, предпочтительней, тестами, как в любой JS программе — экосистема для этого есть.
Тесты не замена типам. Тесты позволяют показать, что определенное поведение существует, типы — что нежелательного поведения не существует в принципе. Квантор существования против универсальности — это очень сильное различие.
Пожалуйста
add : Nat -> Nat -> Nat
add a b = a - b
.\.\test.idr:53:13:
|
53 | add a b = a - b
| ^
When checking right hand side of add with expected type
Nat
When checking argument smaller to function Prelude.Nat.-:
Can't find a value of type
LTE b aА как вы это тестировать собираетесь?
Nat — натуральное или целое? В исходном коде целое
Ну придется заморочиться и написать что-то в таком виде:
add : (a : Int) -> (b : Int) -> (res : Int ** (res >= a || res >= b) = True) -- или какое-то другое свойство, как мы определяем сложение?
add a b = (a + b ** Refl)Всё еще вопрос — а тестировать как (не копипастя тело функции, которую тестируем)
assertEquals (4, add(2,2))
Это не проверит что функция не делает 2*2.
assertEquals (2, add(1,1))
Эту сужает область возможных значений, но все ещё оставляет бесконечно много имплементаций. Один из возможных вариантов:
assertEqual (a, b) =
match (a, b)
(2,2) => 4,
(1,1) => 2,
_ => doSomethingReallyBad()И если вы думаете что это выдуманный неправдоподобный пример, то вот таких вот ShouldNeverThrowException/ImpossibleStateException/… я навидался достаточно.
Тесты, которые проверяют разворот списка на
rev [1,2,3] = [3,2,1]
rev [] = []Я бы счёл подобную реализацию либо троллингом TDD, либо саботажем.
Оно троллинг или саботаж на таком простом примере, а в чуть более сложном оно примерно так и выглядит.
То есть любой код, который проходит тесты, но не рабоатет как ожидается — это саботаж и расстрел? У вас в трекере багов вообще нет я так понимаю? Или есть, но саботажников уже уволили?
саботаж — это когда програмиисту поставили задачу "сделать X", а он решает другую задачу "написать любой код чтобы тесты проходили".
Я не раз видел код, который вроде должен работать, который проходит тест, в котором пограниченые сценарии, все такое. А потомо казывается, что как код е меняй, тест всегда зеленый.
А ещё бывает, что тест проходит, а в реальной БД нет. Один из запомнившихся случаев, когда у заказа был пустой массив скидок, в тестах всё отлично, потому что сумма пустого массива скидок — ноль, сумма заказа минус ноль — сумма заказа, а в SQL — null, и сумма заказа минус null это null, который дальше преобразуется в 0, и у человека сумма любого заказа — ноль.
Прекрасно, правда?
Типчики частично с этим помогают, неправильный код тупо не скомпилится. Правда, обучать все равно надо, но в меньшей степени, и меньше шансов что что-то уронит где-то прод.
Нет, все наоборот, типы решают б0льший класс проблем. ИХ минус — они иногда дороже тестов. Некотоыре вещи просто непрактично доказывать.
Но доказательствао "для любых Х верно Х" лучше, чем "вот мы написали десять тестов, для этих 10 иксов — выполнятся".
в большинстве случаев современного мира доказательств не требуется, достаточно уверенности.
Ну вот для меня подобная уверенность выглядит так

Нужно стараться быть лучше.
Современному миру достаточно Ньютоновой механики.Нет. Недостаточно. Траекторию ракет приходится считать с учётом релятявистских эффектов. Да вообще почти все рассчёты электрических полей без учёта СТО это игра с огнём, когда у нас движущиеся компоненты в системе есть.
Да, если области, где без этого можно обойтись — никто не спорит. Но говорить «современному миру достаточно Ньютоновой механики» таки нельзя.
если их недостаточно — добавляем тестов.Не поможет. Я видел кучу кода с покрытием тестами в 80%-90% (и их разработчики этим очень гордились), где ошибки были чуть не в каждой второй строчке.
Что самое забавное — тот факт, что когда я эти ошибки находит и правил мне неизменно просили добавить ещё тестов — но предложение добавить типов неизменно натыкалось на отповедь «ну ведь самолёты всё равно падают — а там типы».
То есть если теста нам не помогают — то нужно добавить ещё типов.
А если типы не помогают — то их нужно выкинуть.
Где логика?
(я извиняюсь, что встряю, но вы прямо подставляетесь))
Не знаю. Вы с ней, очевидно, незнакомы… и тут я ничем помочь не могу.Где логика?
Где, Карл?
Нужно стараться быть лучше.Кому нужно? Почему нужно?
Дерьмо проще делается и на нём можно неплохо заработать. Не верите — сходите в магазин и посмотрите на «молочные продукты». Они и так-то неплохо продаются, а когда она молоком назывались — так и ещё лучше продавались.
Программирование тут не является какой-то особой областью.
Моя претензия к rsync и примкнувшим к ним демагогам в другом: они категорически отказываются называть дерьмо дерьмом (как, кстати, и производители «молочного продукта», зачастую).
И даже понятно почему: как только ты признаёшь, что целью твоей работы — является дерьмо… ты уже не можешь «посылать джуна» со словами «твой код дерьмо»!
Если наша цель — выпуск дерьма, то «код — дерьмо»… это не похвала, конечно… но само по себе — уже не проблема.
Приходится вводить градации дерьма, критерии… «задавить авторитетом» уже не получается — и да, для определённого сорта людей это проблема.
дерьмо?С моей точки зрения, как человека ненавидящего водить машину — да. Потому что если вам нужна машина как средство передвижения, то автомобиль, который стоит как ваша зарпата за 10 лет, но ездит лет 50 — гораздо полезнее. Свалок меньше будет, воздух чище.
в каком-то смысле да — дерьмо
а вот то что теперь авто можно за одну две зарплаты купить — это тоже дерьмо?
А ресурсы, которые под выпуска всего этого добра не потрачены — можно было бы на что-то другое потратить. На термояд или там колоннию на Марсе.
Но дерьмо продаётся — потому и выпускается.
Заметьте — с этим тезисом я и не спорил никогда.
а можно и построить на обычном метровом фундаменте, но ведь это кто-то может назвать дерьмом, так?Кроме метрового и 50-метрового фундамента есть ещё много градаций. У моей матери домик — на ленточном, потому что стобчатый — это дерьмо. Даже если вы углубите его на 50 метров — у вас всё равно дом «ходуном ходить будет».
Но для бани или сарая — он сгодится.
Вот это вот примерно — разница между типизированными и нетипизированными языками.
почему бы не залить 50 метров? Можно же?Можно — но не нужно. Останкинская башня высотой 540 метров вполне себе стоит на фундаменте глубиной меньше 5 метров.
Да, глубина фундамента — важная характеристика… но далеко не единственная. И даже не главная.
то есть все-таки стат.типизация полезна, просто неоправдано дорога в разработке?
Так вроде никто и не спорит, что польза от неё есть. Вопрос в том, стоит ли овчина выделки.
Так вроде никто и не спорит, что польза от неё есть.Я бы сказал "теперь — никто не спорит". rsync очень агрессивно отстаивал именно этот тезис, пока не самовыпилился.
Объяснял, что «типы затуманивают понимание алгоритма». Когда ему указывали на то, что «увидеть где ваш алгоритм не работает — это не „затуманивание понимания“, а ровно наоборот» он возбуждался и начинал объяснять, что это именно затуманивание, потому что не позволяет неработающий алгоритм продать заказчику как работающий…
P.S. Но то, что с ним удалось пообщаться — не так плохо, на самом деле. По крайней мере начинаешь понимать откуда «растут ноги» у копроэкономики. Довольно забавно было видеть персонажа, который настолько вжился в роль, что был способен почти искренне говорить о том, что проблема качественного товара — не в том, что его дорого и сложно производить — а в том, что это не говно. Собственно когда его всё-таки довели до признания этого — он и выпилился.
Так это "затуманивание" и есть "выделка", что "овчинка" есть он же не отрицал, насколько я помню.
После «тыкания палочкой», конечно, выяснялось, что под «понять» подразумевалось «написать код и сдать заказчику» (что типизация действительно может мешать сделать и с этим никто не спорит).
Эффекты «второго порядка» не то, что не рассматривались, но активно (и агрессивно) объявлялись вредными.
В общем полное и абсолютное погружение в копроэкономику. Такой себе «переворот в сознании», когда человек начинает искренне верить, что если на предмете A можно «наварить» 100 рублей, а на предмете B — нельзя, то предмет B — это очевидное говно, и все его потребительские качества никого волновать не должны.
Пообщавшись с этим персонажем начинаешь понимать как Америка смогла растерять почти все компетенции (подробнее в книжке «Прибыли без производства»). Не буду даже говорить про Маска и полёты на Луну… возьмите пример, где уж точно нет никакой конспирологии: АЭС и ядерные бомбы… ни первое, ни второе сейчас в США просто не умеют делать. Притом что, в отличие от Сатурн 5, от которого остались только памятники, сами-то «старые» АЭС — стоят, работают, списать их на «Кубрика» никак нельзя… а новые — фиг. Два несчастных энергоблока вымучивают уже сколько лет. И цена там получилась такая, что «мама — не горюй».
На самом деле и люди прославляющие капитализм и люди его охаивающие не понимают одного: вот все полезные вещи и весь его ужас — следствие его прогрессивной и человеколюбивой основы.
Проблема-то у всех видов капитализма (включая и копроэкономику и госкапитализм в духе СССР) — одна: если у вас нет «набегов соседей», «капризов царей» и прочего… и то, что вы строите… не разрушается регулярно — то у вас, во-первых, начинает нарастать неравенство, а во-вторых — получается «перепроизводство».
Заметим: чтобы это произошло — вообще не нужно рассматривать цепочки «товар-деньги-товар» и прочее.
Достаточно того, чтобы в построенном вами обществе уничтожение товара и убийство его владельца — не рассматривалось как норма.
Почему средневековое общество было устойчиво? Потому что производить «слишком много» просто не давали: если ты пытался что-то производить не являсь членом соотвествующей организации — то твою продукцию могли просто уничтожить, тебя убить, а уж деньги отобрать — так это вообще святое. А если ты «делился», то стать уж особо богатым богачём тебе не светило — «в случае чего» с тебя можно и побольше снять, ведь так?
Дальше, в какой-то момент, от этого механизма отказались. Как, почему, что послужило причиной — неважно. Важно, что у людей появилась возможность копить деньги, не ограниченная (как в средние века) тем, что чем больше у тебя этих денег, тем больший процент тебе приходится тратить на их охрану.
И всё. Дальше у тебя — с одной стороны невиданный прогресс, а с другой… расслоение (люди-то разные, кто-то работает, кто-то хуже) и перепроизводство (если уничтожать «лишнее» не дают, то регулярно возникает ситация «тут густо, тут пусто»).
А уж решений как стабилизировать такое общество… вагон и маленькая тележка: тут и попытки ввести «цеха» на новом уровне (как в СССР), тут и мировые войны… ну и копроэкономика тоже…
Все они решают проблему лишь на какое-то время, впрочем.
Так что да: копроэкономика — это очередная стадия развития капитализма, но насчёт последней… я не уверен. Поживём — увидим…
P.S. Мы, в последнее время, кстати, наблюдаем откат ещё по одной оси: если в течении XX века считалось нормой, что за то, что ты кому-то даёщь денег «попользоваться» — тебе доплачивают. То в последние несколько лет — всё стало как в средние века: если хочешь, чтобы твоя кучка с золотом через год не исчезла… за её сохранение нужно платить. Либо охранникам, либо (если закопать) риском, что когда золотишко-то откопаешь… обнаружишь там пустой сундук. Заметим что люди так столетиями жили!
Однако, как известно какая-нибудь страничка на Хабре типа этой дико тормозит в Firefox или просто-таки «кладёт на колени» Chrome.
Притом что подобные же объёмы информации моя мать успешно обратабывала в редакторе Микромир четверть века назад на компьютре, в котором было меньше оперативки, чем в современной сетевой карте и процессор там было тоже слабее, чем процессор в этой самой сетевой карте.
Более того — даже с учётом ограничений платформы (DOM, CSS, JS, вот это вот всё) — ничто не требовало делать эту страничку так, чтобы она потребляла буквально сотни мегабайт памяти.
Обозначает ли это, что «крупные корпорации» отловили разработчиков Хабра и долго пытали их пока те не согласились сделать из своего сайта дерьмо?
Нет, конечно. Просто… дерьмо продаётся… а хорошие вещи — нет. Потому что на них требуется больше затрат, а главное — дольше «выход на рынок».
Но само по себе это бы к построению копроэкономики не привело. Всё-таки всех денег не заработать и если у человека есть совесть, то хотя бы какой-то уровень качества он будет пытаться достичь. А если предоставится возможность — то вместо «полного дерьма» может просто «дерьмо» выпустить, а то и, если его не остановить, даже и «конфетка» может получиться. Со временем.
Но вот появление персонажей типа покинувшего нас rsync — приводит к положительной обратной связи: если вы начинаете порождать дерьмо не потому что это выгодно, а потому что вы искренне считаете что «так и надо»… то тут уже ничто вас не может остановить… кроме развала всего общества (как в 90е в СССР) — что, в общем и целом, слишком высокая цена.
P.S. На самом деле rsync меня вот реально поражал своей незамутнённостью. Ну потому что я, например, так получилось, последние несколько лет работаю над форком Андроида — и переписываюсь с разработчиками этого самого Андроида. Которые, как раз, ну вот совершенно не питают иллюзий по поводу того что они, в этом самом Андроиде, сотворили — и почему. Увы: «полудерьмо» они сделать могли, в нужные сроки, а вот уже на «хорошую», «правильную» операционку — времени не хватало. А если бы они выкатили операционку тогда же, когда Windows 10 Microsoft выкатил — уже было бы поздно. Они искренне горды за какие-то свои решения, которые они всё-таки смогли реализовать — даже в условиях цейтнота (например тот факт, что с самого начала разные приложения были «разделены» и «посажены в песочницу» — в отличие от Windows CE или Symbian) и им обидно, что многими вещами пришлось пожертвовать (напрмер то, что долгое время в Android не было вообще никакой защиты от прямого обращения приватных библиотек — они изводят уже много лет и будут изводить ещё долго). Хотя они и понимают что «так было надо». И тут ещё есть какой-то шанс удержаться от полной копроэкономики. Но когда вы начинаете искренне называть дерьмо «альтернативно пахнущей конфеткой» и говорить, что защищаться от багов — и не нужно вообще, если это может помешать вам свой продукт «впарить»… тут никакой защиты от торжества копроэкономики уже нет и быть не может!
Есть, конечно, и обычные производственные компании, где казалось бы этот принцип не должен работать, но там видно другие основные причины вмешиваются (дешевизна вместо качества и т.д.).
Ну а Хабр уже немного тоже монополист в своем секторе, поэтому тоже подпадает под влияние непривычных для нас (немонополистов) факторов.
Ну вот вы и назвали главную причину копроэкономики — скорость вывода продукта на рынок.Эта причина важная, но она не может быть определяющей, тем более единственной.
Потому что если бы это было так, то мы бы до сих пользовались первым текстовым редактором, первыми эоектронными таблицами, ездили бы на Форд Т и так далее.
Но нет — какое-то время происходит очевидное улучшение: можно сравнивать современные автомобили с автомобилями 50х-60х и спорить о качестве, но и те и другие всё ещё однозначно лучше автомобилей начала XX века.
А Excel таки по массе объективных показателей лучше Lotus 1-2-3, а тот, в свою очередь, лучше VisiCalc.
Однако в какой-то момент качество прекращает улучшаться и, более того, происходит регресс.
А качество уже будет не так важно, если продукт обладает «собирающей» силой: то есть чем больше пользователей пришло вчера -> тем больше их придет завтра (например как у соц. сетей).Но ведь даже у них Facebook вытеснил MySpace и Orkut!
Ну а Хабр уже немного тоже монополист в своем секторе, поэтому тоже подпадает под влияние непривычных для нас (немонополистов) факторов.Вы давно в магазине были? «Молочных продуктов» из пальмового масла и каких-то добавок — там достаточно. А они — нифига не монополисты.
Нормальное молоко, в большинстве магазинов, тоже есть — но его нужно внимательно искать. При этом разница в цене ну не настолько высока, чтобы вот именно и только ею всё оправдать.
А выход на рынок — точно ничего не решает, полвека назад «молочного продукта» просто не было…
Кому нужно? Почему нужно?
Дерьмо проще делается и на нём можно неплохо заработать. Не верите — сходите в магазин и посмотрите на «молочные продукты». Они и так-то неплохо продаются, а когда она молоком назывались — так и ещё лучше продавались.
Мне нужно. Потому что я не получаю удовольствия, когда релизю говно. А вот от хорошего решения которое не уронить так просто и которое шустро работает — получаю. Ну и моё скромное мнение, что в долгой перспективе это оказывается для компании выгодее чем "Херак-херак и в продакшн". Конечно, я допускают трейдофы в стиле "захреначить техдолг потому что заказчику нужно ещё вчера", но это скорее исключение, а не правило.
А про экономику дерьма уже давно всё сказано.
Так граничное же условие, специальное значение.
Ну так и с типами, начинаем типизировать foo, а типы не сходятся, потому что sum не возвращает того, что нужно. То же что с тестами, только ошибка сразу на этапе компиляции.
Давайте прочитаем что на эту тему думает Пирс:

Обратите внимание на "absence of cetrain program behaviors"
Типы позволяют статически сказать, что определенны вещи программа не делает. Например, не передает строки туда, где ожидаются числа. Или не пишет в закрытый файл. Ну и так далее.
Тайп-класс монады — как раз пример того, что "в лоб" на Javascript не перенести. Тут есть аж две проблемы.
Во-первых, многие функции в том же Хаскеле параметризуются по типу возвращаемого значения, а потому их невозможно напрямую представить на языке с полиморфизмом через динамическую диспетчеризацию.
Та же функция return, она же pure, имеет сигнатуру Monad m :: x -> m x, и если тип x определяется по первому аргументу (точнее, его вообще нет необходимости определять), то контейнер m надо передавать как-то отдельно.
То есть у нас кроме, собственно, самой монады, появляется совершенно левый объект — описатель монады, со своим интерфейсом.
Во-вторых, многие хитрые ФПшные способы что-то сделать выглядят довольно сложными для ручной проверки. Рассмотрим функцию traverse :: (Traversable t, Applicative f) => (a -> f b) -> t a -> f (t b), которая на Typescript будет выглядеть, скорее всего, как метод traverse параметрами (ApplicativeType f, (A => any) fn) => any. При вызове этой функции есть огромное число способов накосячить!
Если функция
fnвернёт что-то кроме инстанса типа f — то вызов traverse грохнется где-нибудь на 2-4 уровне вложенности внутри методаf.apply(и это в лучшем случае!). Какой программист, получив подобный стектрейс, сразу поймёт что ошибка — вfn, которая в этом стеке ни разу не будет упомянута?
Возвращаемое значение этой функции должно быть инстансом f, внутри которого будет лежать инстанс this/self, внутри которого будет тот тип, который лежал внутри инстанса f, возвращенного функцией fn. Удачи понять что это вообще такое! Притом тут даже защитных проверок типа толком не написать, ведь оператору
instanceofпофиг на типы элементов массива.
Ну или просто посмотрите реализацию данного метода для массива:
Array.prototype.traverse = function (f, fn) {
return this.reduceRight(
(tail_, x) => f.liftA2((y, tail) => [y, ...tail], fn(x), tail_),
f.pure([])
);
}В хаскеле она "по стрелочкам сходится, а значит всё нормально". А в JS как вообще это всё проверить и отладить?
Как обычно в JS — тестами и по баг-репортам. :)
В целом же, похоже, моё давнее подозрение подтвердилось: ФП без мощной системы типов для промышленной разработки подходит хуже чем ПП и ООП без неё. И статтипизация сбоку от JS (TS, FLow) не особо положение спасает для "особо ФП", хотя и помогает при использовании всяких pipe и compose в "ФП-lite" стиле.
спасибо.
Тестами можно только найти ошибку. Чтобы её отладить, надо сначала понять как этот код вообще работает — а этого я, например, не понимаю до сих пор :-)
Ну как-то живут люди с ФП-lite приложениями, довольно успешными, даже без TS или Flow. Когда меня просят помочь, я использую "хаки" вроде
// было
return compose(
f1,
f2,
f3,
)
// на время отладки
compose(
(..args) => (console.log(...args), f1(..args)),
(..args) => (console.log(...args), f2(..args)),
(..args) => (console.log(...args), f3(..args)),
)просто чтобы понять, что приходит
в TS это всё сделать можно, вопрос — нужно ли это кому-то
И давно в TS появились HKT?
Ну его там сделать можно? Можно. Я не про коммьюнити одно, а про майкрософт в том числе.
Честно говоря, я не представляю как совмещать HKT, структурную типизацию и ограничение на время работы сравнения типов.
То есть у нас кроме, собственно, самой монады, появляется совершенно левый объект — описатель монады, со своим интерфейсом.Можно сделать как в C++ с указателями на функции.
Только там «ленивый тип» (который нельзя присвоить просто переменной без указания её типа, но можно присвоть если тип указать), а у вас будет «ленивый результат функции».
Насколько это будет практически полезно… другой вопрос.
Вот к примеру, стандартная задача в ООП — расчёт зарплаты (веса, и прочего) Института.
Институт состоит из Отделений, Отделения из отделов, отделы из секторов.
В ООП — надо просто:
Институт.getЗарплата();И всё, ООП — далее уже каждый объект(Отделение, отдел, сектор) имеет метод .getЗарплата();
То есть обычная задача обхода объектов и суммирования того, что выдаёт каждый объект по известному методу.
Она конечно имеет место быть в ФП — и там она тоже решается. Наверное.
Но вот ООП тут ясно как день ясный. — А вот также же ясно будет с ФП?
Я даже тогда набросал работающий в броузере пример — ясный как день:
Вот мой примитивный пример — я обошёлся без классов, но с объектами.
Каждый объект имеет и данные и методы. Ну, это же фишка ООП.
Как обычно в ООП — мы только и делаем что дёргаем метод объекта, если у объекта есть метод.
Можно просто кинуть этот код в консоль броузера (или в сниппеты броузера) и… выполнить.
Можно заметить что институт этот это не только отделы, но и директор, сотрудники, мебель, автомобили — то есть довольно разношерстная публика объекты.
Дерево содержит «узлы» и «листья».
«Узлы» всегда имеют методы getName, getSallary, getWeight, getPower.
«Листья» имеют только те методы, значения для которых у них есть. Например автомобиль не имеет метода getSallary ибо зарплаты не получает.
Но это не принципиально. Дерево может быть любое. Главное что это не данные, а это объекты.
var getSallary = function (){
var sallary = this.sallary || 0;
if (this.consist) {
sallary = this.consist.reduce(function(sum, current) {
return sum + (current.getSallary? current.getSallary() : 0);
}, 0);
}
return sallary;
};
var getWeight = function (){
var weight = this.weight || 0;
if (this.consist) {
weight = this.consist.reduce(function(sum, current) {
return sum + (current.getWeight? current.getWeight() : 0);
}, 0);
}
return weight;
};
var getPower = function (){
var power = this.power || 0;
if (this.consist) {
power = this.consist.reduce(function(sum, current) {
return sum + (current.getPower? current.getPower() : 0);
}, 0);
}
return power;
};
var getNames = function (){
if (this.consist) {
this.consist.forEach(function(current) {
current.getNames();
});
} else if (this.sallary) {
console.log(' ' +this.name);
}
};
var institut = {
name : 'NII-CHAVO',
getNames,
getSallary,
getWeight,
getPower,
consist: [
{
name : 'Petrov-director',
sallary: 10000,
getNames,
getSallary},
{
name : 'Ivanova-secretar',
sallary: 1000,
getNames,
getSallary},
{
name : 'Sidorov-vodila',
sallary: 1000,
getNames,
getSallary},
{
name : 'avtomobil for director',
weight: 4000,
power: 400,
getNames,
getWeight,
getPower},
{
name : 'Departament1',
getNames,
getSallary,
getWeight,
getPower,
consist: [
{
name : 'Petrov-ml',
sallary: 5000,
getNames,
getSallary},
{
name : 'Sidorova-worker',
sallary: 500,
getNames,
getSallary},
{
name : 'avtomobil for Departament1',
weight: 3000,
power: 200,
getNames,
getWeight,
getPower},
{
name : 'Otdel-11',
getNames,
getSallary,
getWeight,
getPower,
consist: [
{
name : 'Ivanov-shef',
sallary: 3000,
getNames,
getSallary},
{
name : 'Sidorova-ml-worker',
getNames,
sallary: 500,
getSallary}]}]},
{
name : 'Departament2',
getNames,
getSallary,
getWeight,
getPower,
consist: [
{
name : 'Petrova',
sallary: 5000,
getNames,
getSallary},
{
name : 'Stepanova-worker',
sallary: 500,
getNames,
getSallary},
{
name : 'avtomobil for Departament2',
weight: 2500,
power: 150,
getNames,
getWeight,
getPower},
{
name : 'Otdel-21',
getNames,
getSallary,
getWeight,
getPower,
consist: [
{
name : 'Petrovich-shef',
sallary: 3000,
getNames,
getSallary},
{
name : 'Stepanova-ml-worker',
sallary: 500,
getNames,
getSallary}]}]}],
};
console.log(`Total Sallary: ${institut.getSallary()}`); // 30000
console.log(`Total Weight: ${institut.getWeight()}`); // 9500
console.log(`Total Power: ${institut.getPower()}`); // 750
console.log('List of employees: ');
institut.getNames();
А вот типа «тот же» пример на ФП.
Код был… мощный, но я ничего не понял, и на свой вопрос:
То есть вам чтобы подсчитать totalSallary надо передать в функцию заранее известный состав Института? -> departments, branches, sectors
А если он меняется? Если там нет секторов или есть отделы не входящие в Департамент, а подчиняющие прямо директору?
Ответа так и не получил.
Прошло три года, а… воз и ныне там.
# почти уверен, что такая функция есть в какой-нибудь библиотеке про графы или деревья
function reduce_tree(f_reduce, f_children, f_leafvalue, tree)
cur_value = f_leafvalue(tree)
if isempty(f_children(tree))
return cur_value
else
agg_value = mapreduce(f_reduce, f_children(tree)) do child
reduce_tree(f_reduce, f_children, f_leafvalue, child)
end
return f_reduce(cur_value, agg_value)
end
end
function institute_total(field_name, institute)
reduce_tree(
+,
t -> get(t, :consist, []),
t -> get(t, field_name, 0),
institute
)
end
# посчитаем те же величины, что у вас:
institute_total(:salary, institute)
institute_total(:weight, institute)
institute_total(:power, institute)
reduce_tree(
vcat,
t -> get(t, :consist, []),
t -> haskey(t, :salary) ? t[:name] : [],
institute
)
Нет абсолютно ненужных и запутывающих повторений, меньше кода, все условия на виду. При использовании библиотечной функции обхода дерева можно это всё параллельно запускать — полезно, если зарплата по сложному алгоритму считается например.
Можно ещё рефакторить и улучшать, на даже такой прямолинейный подход приводит к более ясному коду.
function reduce_tree(f_reduce, f_children, f_leafvalue, tree)
mapreduce(f_reduce, f_children(tree), init=f_leafvalue(tree)) do child
reduce_tree(f_reduce, f_children, f_leafvalue, child)
end
endТак разница в длине кода вообще взлетает до небес.
Смотрите — что у вас на входе то?
Дело же не в длине кода, дело в том что я описал решение когда на входе то, входное дерево (назовём его «состав учреждения» или «дерево разузлования» («состав изделия»)
состоит из объектов то!
А у вас из чего?
Смотрите, вот, например, объект типа узел:
{name : 'Otdel-21',
getNames,
getSallary,
getWeight,
getPower,
consist: [...]}Это не функция — это объект!
У него есть свойство «name» и свойство «consist»
и куча методов: getNames, getSallary, getWeight, getPower
Понимаете!
Каждый метод и узла и листа (там где нет свойство «consist») может иметь свою собственную имплементацию то. (В данном случае мы не расматриваем откуда она взялась то — не интересуемся порождением(наследованием) этих объектов)
Вот объект типа лист:
{name : 'Stepanova-ml-worker',
sallary: 500,
getNames,
getSallary}В нашем простом случае getSallary возвращает просто значение свойство sallary объекта равное 500.
Но у этого объекта можно задать совершенно иную имплементацию этого метода — например, метод будет анализировать сколько часов отработала Stepanova-ml-worker в этом месяце.
Я не вижу — где у вас эта информация то? Куда и как вы её можете поместить то, в ФП?
Я то помещаю её в старый добрый объект.
Дело в не функции обхода дерева. Дело в том, куда вы помещаете алгоритмы и величины, которые я логично и привычно помещаю в объект?
Хорошо бы привести пример на ФП, который реально бы работал. (мой то можно в консоли броузера запустить).
PsyHaSTe
Хранить машины вместе с диркеторами — это сильно.
Можно другой пример составить — состав изделия. Конечно состав будет из объектов состоять.
Каждый узел — это блок. А каждый лист — деталь.
Методы — они отвечают на вопросы — покупной ли узел(деталь), сколько содержит золота, каков вес, каков размер, какая цена, какой срок изготовления…
И вот куда это всё в ФП помещать то?
Можно другой пример составить — состав изделия. Конечно состав будет из объектов состоять.
Каждый узел — это блок. А каждый лист — деталь.
Методы — они отвечают на вопросы — покупной ли узел(деталь), сколько содержит золота, каков вес, каков размер, какая цена, какой срок изготовления…
И вот куда это всё в ФП помещать то?
Если набор узлов неизвестен и известен только интерфейс — то тайпклассами (ну или даже интерфейсами, особых проблем тут нет).
Если набор ограничен (например, деталей всего 10 видов и можем их перечислить) То так и пишем
data Part = Type1 ... | Type2 ... | Type3 ...В конце концов можно вообще написать HTree и статически во время компиляции всё про наше дерево знать и че-то с ним крутить.
Хорошо бы привести пример на ФП, который реально бы работал. (мой то можно в консоли броузера запустить).
Извините, на js не пишу. А приведенный пример работает.
Это вы на каком языке то пишите то?
Julia. Уверен, что на условном питоне код будет выглядеть почти ровно так же — просто пишу на чём привычнее/удобнее.
Смотрите — что у вас на входе то?
На входе словарь, описывающий структуру завода. Вроде и у вас в примере так же, но может я не совсем правильно понял — js плохо знаю.
Например так:
institute = Dict(
:name => "Name 1",
:consist => [
Dict(
:name => "Director",
:salary => 123,
),
Dict(
:name => "Not director",
:salary => 1234,
:weight => 56,
:consist => [
Dict(
:name => "A name",
:weight => 78,
)
]
),
]
)Может быть считан из json или откуда там ещё.
Надеюсь вы в реальных проектах не хардкодите структуру завода, как в вашем примере? С кучей повторений, в которых легко запутаться.
Извините, на js не пишу. А приведенный пример работает.Работает где? Где-то его можно запустить было бы? Хотя уже не надо.
Julia. Уверен, что на условном питоне код будет выглядеть почти ровно так же — просто пишу на чём привычнее/удобнее.Julia?
СТОП!
Я же просил: «Но вот ООП тут ясно как день ясный. — А вот также же ясно будет с ФП?»
Каким боком Julia к ФП?
Мне надо, чтобы кто-то показал, как с помощью монад и функторов можно было эту простую в общем то задачу то реализовать на практике на ФП, а не каком-то НЕ ФП языке типа сделать короче код.
На входе словарь, описывающий структуру завода. Вроде и у вас в примере так же, но может я не совсем правильно понял — js плохо знаю.Так да не так — словарь ваш — это структура данных, а у меня структура объектов!
Объект — это то что включает в себя и данные и методы для работы с ними!
Вот куда вы поместите в своём коде эти методы (можете их функциями называть то), если они будут разные для разных объектов то (а не одинаковые как сейчас)?
Например, имплементация метода getSallary у директора будет учитывать бонусы, а имплементация метода getSallary у работника будет обращаться к графику работы (или переработке)?
Ну, это я вас так вот спросил.
В JS (или Java) и данные и методы заключены в объекте. В этом суть объектного программирования.
А суть ФП? — многим неясна. Там как с этим поступать то, куда девать методы и куда данные. Объекты в ФП есть или это и есть… монады? — Но тогда чего огород городить то?
Пока толкового примера решения моей простой задачки на ФП (монадами и функторами) нет.
Вообще, книжка "Паттерны банды четырёх переписанные в функциональном стиле" была бы бестселлером, поди. Но никто не напишет. Почему?
1) некогда
2) незачем
3) некому
4) невозможно
Работает где? Где-то его можно запустить было бы?
Запускать так же, как код на почти любом другом языке (включая js): либо сохраняете в файл и компилируете/запускаете этот файл, либо открываете repl и туда вставляете код.
Julia?
СТОП!
Я же просил: «Но вот ООП тут ясно как день ясный. — А вот также же ясно будет с ФП?»
Каким боком Julia к ФП?
У вас какое-то сломанное понимание того, что представляет собой ФП. Под описание в википедии мой код полностью подходит:

Авторы языка тоже согласны с этим:

Ну и уж ООП в julia напрямую вообще не включено.
Мне надо, чтобы кто-то показал, как с помощью монад и функторов можно было эту простую в общем то задачу то реализовать на практике на ФП, а не каком-то НЕ ФП языке типа сделать короче код.
Как я выше написал, julia относится к ФП языкам, а мой код соответствует функциональному стилю.
Монада — это по сути всего лишь один из паттернов функционального программирования. Просить написать код на ФП «с монадами» — то же самое, что в ООП просить «с паттерном фабрика». Оба варианта возможны, но далеко не всегда являются самыми удобными.
То есть можно писать полезные функциональные программы без монад? а как IO делать?
Пишете чистые функции, вызываете через FFI.
Повторю, что вообще ситуация в некотором смысле близка к паттернам в ООП: в некоторых языках при написании ООП-кода для некоторых задач требуются некоторые «паттерны с названием» (например, синглтон); в некоторых языках при написании функционального кода для некоторых задач требуются некоторые «паттерны с названием» (например, монады). При этом область применимости паттерна часто намного шире, чем случаи когда он именно необходим.
Я не случайно написал именно "программы". Так-то я и на PHP больше 20 лет использую функциональные подходы некоторые. Но вот с IO как быть без монад?
Например, в хаскеле функция main (входная точка программы) имеет тип IO (). В языке есть несколько функций, которые возвращают значения типа IO <что-то> — элементарные блоки, из которых строится затем весь ввод-вывод (в духе «открыть сетевое соединение», «прочитать байт», ...). Сам ввод-вывод при этом остаётся как бы за рамками языка, он производится уже средой исполнения.
Вся эта ситуация эквивалентна гипотетическому языку, в котором функция main получает на вход явным образом список базовых функций (реализованы вне языка, средой исполнения), на которых строится весь ввод-вывод (в духе «открыть сетевое соединение», «прочитать байт», ...). Далее вся программа может быть чистой и просто использовать эти функции, явным образом передавая их из main'а. Всё будет работать ровно так же, как в хаскеле. Монада IO просто позволяет удобно это записывать и не передавать постоянно список нужных функций ввода-вывода.
Как может быть чистой программа, которая вызывает нечистые функции? Элементарная функция вызова колбэка не может быть чистой, если нет гарантий чистоты этого колбэка.
function f(readline, printline)
printline("Enter your name:")
name = readline()
printline("Hello, $name :)")
return name
endОна чистая? Да, конечно. Её даже вызвать можно с аргументами, которые тоже чистые функции:
f(() -> "John", _ -> nothing) # вернёт "John"Однако, среда исполнения может запустить f таким образом, чтобы readline() означало чтение строки из стандартного ввода. Конечно, такой readline() средствами языка создать нельзя, если в нём есть только чистые функции.
Для меня она нечистая, потому что её вызов может производить сайд-эффекты, если нет гарантий, что readline printline их не производит.
Debug.Trace построен)?В таком случае чистые функции у вас окажутся только в учебниках математики (во всех реализациях Haskell есть свой аналог
Debug.Trace — хотя детали могут отличаться).Не понял вас. Вот есть такая функция.
function f(readline, printline) printline("Enter your name:") name = readline() printline("Hello, $name :)") return name end
Она чистая? Да, конечно.
По такой логике любая программа на Джаве чистая.
нет. Эта функция нечистая — одним из требований чистоты является ссылочная прозрачность (referential transparency), т.е. должна быть возможность в любом месте заменить функцию на результат ее вычисления, и наоборот — результат вычисления на вызов этой функции.
Заменить эту функцию на "John" нельзя, т.к. потеряется печать строк на экран и чтение ввода.
Что нужно, чтобы эта функция была чистой? Сделать так, чтобы она возвращала список инструкций, которые нужно выполнить.
Т.е. вот так:
function f(readline, printline)
actions = []
actions.push("call", printline, "Enter your name:")
actions.push("call_and_assign", "name", readline)
actions.push("call", printline, "Hello, {} :)", ref("name"))
actions.push("return", ref("name"))
return actions
endТакая конструкция обладает чистотой — она возвращает список инструкций, которые нужно выполнить для достижения результата, но не выполняет этот список инструкций самостоятельно. Конечно, именно в такой записи это выглядит кошмарно, еще и не очень расширяемо, поэтому и используют концепцию монад, которая позволяет сделать то же самое, но куда проще и строже:
function f(readline, printline)
return printline("Enter your name:").then(=> {
return readline().then(name => {
return printline("Hello, $name :)").then(=> {
return wrap(name)
})
})
})
endЭта функция все еще чиста, и возвращает другие чистые функции, замыкающиеся на чистые функции. Подразумевается, что printline и readline тоже возвращают монаду IO или ее аналог.
Причем если императивный язык поддерживает вещи типа yield или await, то можно записать это так:
function f(readline, printline)
yield printline("Enter your name:")
name = yield readline()
yield printline("Hello, $name :)")
yield wrap(name)
endтакая вещь в функциональных языках называется do-нотацией, и результирующая функция все еще чиста, т.к. не выполняет никаких действий сама, а лишь строит список действий, которые должен выполнить рантайм.
function f(readline, printline)
printline("Enter your name:")
name = readline()
printline("Hello, $name :)")
return name
end
не чистая? А такая функция:
function f(readline)
name = readline()
return name
end? А такая:
function f(g)
return g()
end?
Если в языке чистые функции никак особо не помечены, то рассуждение о «чистоте» или «нечистоте» требует изучения, фактически, всей программы.
Пометить все три функции как pure в C/C++ нельзя — будет UB.
Если сами вызываемые функции не
pure, конечно. А вот то самое с actions и монадами — можно.А ведь, казалось бы, C/C++ максимально далёк от всей этой теории.
Что забавно, что чистыми в полном понимании функциями в C++ являются функции, отмеченные как const, а не как pure, т.к. pure разрешает доступ к глобалам, тогда как const требует, чтобы функция использовала только другие const-функции и const-значения.
f(readline) чиста, если только readline чиста.
f(g) чиста, если только g чиста.
Не вижу странного, я об этом выше и написал. Ссылочной прозрачностью обе функции не обладают, т.к. и readline(), и g() могут быть не заменены на результат своего выполнения для всех возможных readline и g.
Более того, если с g() еще черт его знает, что она делает, то readline(), очевидно, возвращает каждый раз разные результаты, и чистой не может быть по определению.
Более того, если с g() еще черт его знает, что она делает, то readline(), очевидно, возвращает каждый раз разные результаты, и чистой не может быть по определению.
То есть по-вашему от простого переименования аргумента функции ситуация изменяется? Вторая и третья функции из моего предыдущего комментария отличаются только названием аргумента (readline или g), и всё.
То есть по-вашему от простого переименования аргумента функции ситуация изменяется?
Автор ведь объяснил как изменяется. С readline по названию очевидно, что функция — не чистая. С g() — по названию не очевидно. Она может быть как чистая, так и нет. Но вы изначально придумали аргумент, что два примера на самом деле одинаковые и думали, что тут идиоты, которые не заметят этого? И потому применили этот аргумент не к месту.
Прочитайте мой комментарий еще раз. Я процитирую важную часть, которую вы, возможно, пропустили.
f(readline)чиста, если толькоreadlineчиста.
f(g)чиста, если толькоgчиста.
Влияет ли переименование аргумента на чистоту описываемых функций?
Я утверждаю, что вы не сможете средствами плюсов отличить реализацию плюсов, которая по тексту функции строит IO-действия в стиле хаскеля и потом их выполняет, от реализации, которая их выполняет «сразу» (что бы это ни значило).У плюсов всё это через программиста пропущено. То есть функция чистая не тогда, когда компилятор что-то про неё может сказать, а когда выполнено некое утверждение, которое должен обеспечить программист. А если не обеспечит — тогда UB.
Так что даже очень понятно даже что значит та фраза, которую вы написали. На функцию, которая строит IO-действия вы можете повесить аттрибут
pure, а на функцию, которая выполняет действия сразу — нет. На функцию, которая испоняет построенные IO-действия, разумеется тоже аттрибут pure навесить нельзя.Вернее технически-то можно навесить что угодно и куда угодно. Имеется, конечно, в виду «навесить так, чтобы в результате получилась валидная программа на C++».
Вот и весь смысл чистоты и эффектов.Ну в C++ — всё то же самое, только определять — чистая функция или нет… это обязанность программиста, а не компилятора. И с
noexcept тоже. И вообще всё и везде.Ну… такой язык.
Хранить машины вместе с диркеторами — это сильно.
Это, в сущности, те же люди, которые, после того как учёные прочитавши и «проникшись» известным опусом «решили» проблему GoTo придумав ему 100500 других имён (одно из решений, кстати, в Haskell даже есть — исключения)… начали на этих «новых GoTo» активно строить все свои программы и библиотеки.
Самое обидно — что, похоже, совсем без GoTo практические языки «не получаются» (в Haskell есть исключения, в Go и Rust — паника), но сам факт его наличия этих личностей резко возбуждают — и они начинают порождать свой любимый «спагетти-код»… то же самое и с базой данных, где мащины хранятся вперемешку с директорами…
Я как-то не помню употребимого языка, кроме ассемблера, где через goto можно прыгнуть наружу из функции.Любой, где есть исключения.
Аналоги типа longjmp это немного другое, и пользуются ими аккуратнееНе видел. Лапшу намешивают такую густую, что мало не покажется.
Не видел. Лапшу намешивают такую густую, что мало не покажется.Когда пихают логику, не связанную с освобождением ресурсов или иным аккуратным падением, в обработчик исключения мне тоже грустно. Правда, везде, кроме пайтона, за такое по рукам бьют, а в пайтоне почему-то считается хорошим тоном вместо условного
if(exists(filename))
fid=fopen(filename)
else
print("File does not exist")писать
try
fid=fopen(filename)
catch
print("File does not exist")for поверх исключений сделан. Для того, чтобы итератор имел только один метод — next.Скорость работы цикла
for обычно считается достаточно важной… ну в других языках, не в Python…for, обходящих мелкие объектики (какие-нибудь поля в JSON) на 2-3-5 элементов (где это-таки важно) было на 2-3-4 порядка больше, чем «внушительных» for, обходящих что-то монументальное на миллион элементов (где это, действительно, неважно).Ой мамочки. Добавил в коллекцию
Грубо говоря, непонятно куда мне эти монады воткнуть в код игры, или в код сервиса отдачи картинок, чтобы почувствовать ощутимое удобство.
Монады помогут статически гарантировать, что у вас логи пишутся в правильном формате, и только там, где вы ожидаете, что запросы идут на www.mygoodsite.com, но не на evil.org, что вы в горяем цикле не ддосите какой-нибудь удаленный сервер, бесплатно распараллеллить нетривиальную логику… Ну, всякое в таком духе.
Замените "монады" на "функции" или "объекты", и поймете, что вопрос не в инструменте, а что с ним делать.
Может потому функциональное программирование сложное, что обычному современному человеку (по крайней мере "в наших широтах") не свойственно думать в декларативной манёре? Кругом одни наборы инструкций, простые, сложные, но куда ближе к императивным, чем к декларативным.
Может потому функциональное программирование сложное, что обычному современному человеку (по крайней мере «в наших широтах») не свойственно думать в декларативной манёре?Всё, в некотором смысле, хуже. Как я уже говорил: проблема в том, что людей долгое время отучают мыслить в декларативной манере. Совсем недавно одному знакомому, который ну никак не мог понять как писать программы на C++ (какой садист решил, что обучать программировать нужно сразу на C++ — я не знаю) показал книжку на Haskell и сказал, что если он думает что C++ сложный — может взглянуть туда. Через неделю чувак начал писать на Haskell (коряво, но программы работали), через две — что-то уже и на C++.
Если честно — я сам был в некотором офигении, так как мне, в своё время, потребовалось куда больше для того, чтобы ну хоть что-то на Haskell написать.
Но в целом я бы сказал так: функциональные языки и императивные, с точки зрения лингвистики, просто описывают мир сильно по разному. Ну вот так же как с естественными языками. Вы думаете человеку, в котором нет понятий «лево» и «право» (а такие языки вполне себе существуют) — их легко понять и осознать?
Да по сравнению с их мучениями ваши стоны о монадах — детский лепет! Ну вот действительно: зачем вводить понятия, которые только запутывают? Север — он всегда на севере, юг — он тоже понятно где… зачем нужна непонятная хрень, которая меняет своё значение в зависимости от того, кто эти слова произносит и куда он при этом смотрит?
Чем проще правила, тем ниже порог вхождения, но больше свободы чтобы наделать ошибок. Чем правила сложнее, тем больше ошибок может быть отловлено автоматически, но тем сложнее упихать задачу в эти правила. В общем идеальный набор правил это что-то вроде священного грааля.
Разные школы предлагают разные правила, разной степени замороченности. Императивщики постепенно пришли к структурному программированию (по пути избавившись от goto) — это легко и не особо надежно. ООПшники — к шаблонам проектирования, SOLID, domain driven design — чуть сложнее и стабильнее. Функциональщики оказались гораздо продуктивнее: functional composition, combinators, call/cc, continuation passing style, communicating sequential processes, categories и еще куча других умных слов — очень сложно и крайне надежно (в теории).
Не существует языков, которые бы поддерживали такое многообразие подходов. Поэтому при попытке переложить конкретный подход на язык общего назначения приходится идти на различные компромиссы и синтаксические извращения. Это привносит в решение изрядную долю accidental complexity.
необходимостью смены парадигмы императивного программирования на декларативное.
Декларативность vs императивность это противопоставление теплого с мягким. Вы можете писать декларативно в любой парадигме, если вам это зачем-то нужно. Проблема скорее в другом. Всех программистов можно разделить условно на две категории:
Всех программистов можно разделить условно на две категории:Всех ли? Вы самую обширную группу забыли: месильщиков в чане с перловой кашей. А это — как бы не 90% всех программистов. На Хабре, впрочем, поменьше.физиков и лириковалгоритмистов и логиков.
Первые любят считать такты процессора, тыкать носом в complexity и тому подобные вещи.И что самое смешное — они же обычно вполне умеют в ФП и монады и всё такое прочее. Как тот же 0xd34df00d.
Для вторых важнее наличие красивого доказательства корректности решения и абстрактность (sic!) описания предметной области.Это как раз не так важно. Проблема в ФП не с тем, что оно даёт, с тем чего оно не даёт.
ФП ориентированные языки дают чуть больше возможностей для вторых.Да не в этом дело! Проблема в ФП в том, что оно почти не даёт вам возможности рандомно комбинируя код получить что-то работающее.
Особенно строго типизированные языки. Да, если оно соберётся — то почти наверняка заработает. Вот только у любителя «месить чан с перловой кашей» — оно не соберётся. И соответственно, не заработает. И… собственно всё.
ФП не даёт шансов людям, которые не имеют представления что и как они делают — в этом его главная беда.
P.S. Кстати «если соберётся, то заработает» — тоже неправда. Это у нормальных людей оно если собирается, то работает. Потому что у них в программе ну хоть какое-то подобие логики есть. Если вы переставляете куски программы совсем рандомно, то даже ФП не спасает… оно собирается — и не работает.
Вы самую обширную группу забыли: месильщиков в чане с перловой кашейПо-моему это вопрос ожиданий. Ведь решение можно показать только когда знаешь его заранее. А если не знаешь — приходится искать, в творческих муках.
Лично мне на собесах интереснее смотреть как кандидат справляется со вторым. Потому, что если если вдруг задачка попала в зазубренное решение, которое он показывает без запинок даже в гугл доксе — это фейл. Потом на практике таких ситуаций не будет. Ну да, в процессе поиска может случаться разное непотребство: брутфорс, брейншторм — нервным и беременным лучше не смотреть. Пусть так, ведь даже у лучших из нас нормальное решение получается только с третьего раза wiki.c2.com/?MakeItWorkMakeItRightMakeItFast.
Сомневаюсь, что ФПшники в этом смысле какие-то особенные. Вот github.com/xmonad/xmonad на хаскеле — немногим больше 500 живых строк кода и даже не три, а больше тысячи ченьжей. Как же так?
Вот github.com/xmonad/xmonad на хаскеле — немногим больше 500 живых строк кода и даже не три, а больше тысячи ченьжей. Как же так?Не знаю где вы там больше тысячи ченьжей в этих сточках нашли. Я тут вижу пару дюжин (это за пять с лишним лет) из которых существанная часть — реакция на изменения в языке.
Пусть так, ведь даже у лучших из нас нормальное решение получается только с третьего раза wiki.c2.com/?MakeItWorkMakeItRightMakeItFast.Это нормально. То, что хорошее решение — требует усилий это нормально. Ненормально — когда ты в принципе не понимаешь как твое решение работает и надеешься что оно вообще работает только потому что тесты проходят.
И вот тут — ФП подкладывает большую свинью: если в императивном программировании «малые шевеления» обычно не сильно меняют поведение программы и можно постепенно её менять и смотреть что с ней происходит, то в ФП малые шевеления как раз могут привести к кардинальному изменению кода… и иногда это — таки нужно делать.
Этот эффект, кстати, имеет место быть и в таком специфическом языке ФП, как шаблоны С++… но их «месильщики» обычно и «ниасиливают».
Потом на практике таких ситуаций не будет.Почему не будет? Что вы такое творите, что у вас постоянные брейнштормы? В моей практике максимум 5-10% времени уходит на вещи, которые ну вот совсем непонятно как сделать. И их, как бы, нет проблем обсудить и даже попробовать решать совместно, собрав всю команду.
А вот как раз чего резко не хочется — так это тратить время и силы на то, что, как бы человек должен и без посторонней помощи делать — но почему-то не делает…
Не знаю где вы там больше тысячи ченьжей в этих сточках нашли. Я тут вижу пару дюжин (это за пять с лишним лет) из которых существанная часть — реакция на изменения в языке.Просто обратил внимание на «1,346 commits» что на главной. То что вы показываете это изменения в довольно свежем модуле, как и весь 'src/' которые там появились после кардинального рефакторинга. История проекта, проб и ошибок намного глубже.
В моей практике максимум 5-10% времени уходит на вещи, которые ну вот совсем непонятно как сделать.Если продолжать автомобильные аналогии, то типичные задачи чаще представляют собой не подробный план маршрута как для трамвая, а примерное описание того, куда клиент хочет добраться. Потому, что «не дворянская наука — география. «Да извозчики-то на что?.. Дворянин только скажи: повези меня туда, — свезут, куда изволишь» ». И вот здесь между «непонятно как сделать» и «сделать быстро-дешево-качественно — выберите любые две» лежит куча неизвестностей, пробок, ям, тупиков, засад и подводных камней.
Хорошо когда код позволяет делать в нем инкрементальные изменения. Плохо когда с открытием какого-то очередного нюанса (скажем, логирования добавить туда, где раньше не логировалось) приходится переделывать половину архитектуры.
Хорошо когда код позволяет делать в нем инкрементальные изменения.Почему хорошо?
Плохо когда с открытием какого-то очередного нюанса (скажем, логирования добавить туда, где раньше не логировалось) приходится переделывать половину архитектуры.Почему плохо?
Понимаете — программирование это всегда trade-offs. И вот ну я в упор не вижу почему «переделывать половину архитектуры» — это обязательно плохо.
Потому, что «не дворянская наука — география. «Да извозчики-то на что?.. Дворянин только скажи: повези меня туда, — свезут, куда изволишь» ».Вопрос в том, сколько это стоит. Так-то, да, лучше быть здоровым и богатым, чем бедным и больным.
Но я очень хорошо один компонентик. Который, на моей памяти, переписывался четыре раза… причём три раза — мной.
Ибо изначально — это была «развесистая клюква» в «правильном ООП стиле» где я, честно говоря, с трудом мог понять что вообще происходит. И было в ней… не помню сколько, но точно помню что между 50'000 строк и 100'000 строк. Автор этого кода модифицировать его, в нужную сторону, отказался — после чего, собственно, я и занялся его переписыванием.
А после переписываний (каждое из которых как раз порождалось тем, что архитектура не была гибкой — и не планировалась мною быть гибкой, что самое-то интересное) компонент занимал 5'000, 7'000 и, в последней итерации, 10'000 строк.
Причём написание всех трёх итераций заняло меньше времени, чем написание «ультрагибкой» (но при этом, как выяснилось, всё равно «недостаточно гибкой») исходной версии.
Откуда эта невероятная боязнь выкинуть к чёрту написанный вами код? Нет, понятно: если вам за удалённый код вычитают из зарплаты или вообще платят построчно — тогда всё разумно.
Но если ваша задача — это решить какую-то проблему, а не породить XXX строк кода… то почему? Зачем?
И как справедливо здесь заметили, есть еще месильщики.
Все-таки любой ЯП должен учитывать на какую категорию пользователей он направлен.
упс… ответ был на этот коммент
Вы самую обширную группу забыли: месильщиков в чане с перловой кашей. А это — как бы не 90% всех программистов.Ага — а остальные сразу пишут "правильный" код и без багов? Ну, ну.
Это как скульптор, который берёт глыбу мрамора и уверенными движениями молотка и зубила отсекает всё лишнее, получая Афродиту? — зачем ему по сто раз "месить глину" и делать гипсовые копии, прежде чем приступить к мрамору то? Ага.
Или как шахматист, не перебирая варианты, долго не размусоливая, двигает фигуры к победе? — Ведь он вызубрил наизусть все дебюты ведущие к победе? Ага.
Ну, ну. — А хоть понятие «преждевременная оптимизация» вам известно? — Да, вряд ли, если 10% программистов пишут сразу «правильный оптимизированный код».
Ага. ;-)
Это как скульптор, который берёт глыбу мрамора и уверенными движениями молотка и зубила отсекает всё лишнее, получая Афродиту? — зачем ему по сто раз «месить глину» и делать гипсовые копии, прежде чем приступить к мрамору то? Ага.Знаете, вы прекрасный пример привели. Даже не представляете, насколько.
Да, есть скульпторы, которые высекают из глыбы мрамора всё сразу, без глиняных и гипсовых моделей. Есть такие, кому нужно поэкспериментировать.
Но нормальный скульптор не берёт мраморную глыбу чтобы разбить её молотком и потом, пристраивая куски друг к другу сотворить «инсталляцию».
И свои гипсовые прикидки вместо мраморной скульптуры — он тоже не продаёт.
А вот в программировании, почему-то, это — в порядке вещей.
Ну, ну. — А хоть понятие «преждевременная оптимизация» вам известно? — Да, вряд ли, если 10% программистов пишут сразу «правильный оптимизированный код».Мой традицонный ответ — ссылка на оригинал и замечание в нём «в развитой инжереной дисциплине улучшение в 12%, легко получаемое, никогда не рассматривается как несущественное — и я верю, что подобный же подход должен возобладать и в програмимровании» («in established engineering disciplines a 12 % improvement, easily obtained, is never considered marginal; and I believe the same viewpoint should prevail in software engineering»)
То, что сегодня под видом отказа от «преждевременной оптимизации» людям впаривают дурно пахнущее дерьмо под видом конфетки — не имеет никакого отношения к тому, что имел в виду Кнут. 12% — это не 2x и не 10x, извините.
А вот про 1-2% — да, можно, обычно, и забыть, тут нет проблем.
Или как шахматист, не перебирая варианты, долго не размусоливая, двигает фигуры к победе?Вы никогда не играли с профессионалом на сеансе одновременной игры? Да — именно так он и делает, если нужно.
Конечно, если дать ему время подумать — результат будет ещё лучше. Но если вы не знаете дебютов и теории — то вы можете перебирать варианты хоть до морковкина заговения — а у профессионала вы не выиграете.
P.S. Забавно, что все ваши потуги оправдать сегодняший самый распространённый подход приводят к обратному. Не находите, что это… как-то не странно?
все ваши потуги оправдать сегодняший самый распространённый подход"Рубильщики" и "месильщики" — это не определение людей, а определение методов программирования, которые применяют все в то или иное время.
Это как профи шахматист — «рубит» в сеансах одновременной игры, потому что у него просто нет времени, и «месит» играя один на один при обычном регламенте.
Если программист «рубит» код, то это означает что он раньше уже решал эту задачу.
Если программист «рубит» код и при этом он раньше не решал эту задачу, то это странно и его «рубленный» код потенциально опасен ибо он этим «играет в рулетку», не более того.
Если на собесе кандидат не «рубит код» — это означает что ему не дали примеры задач которые от него потребуют при собесе (или он знал их но не удосужился просмотреть заранее и зазубрить).
Если при собесе кандидату вообще не сообщают что от него будут требовать на собесе «рубить», а кандидат не угадает что ему предложат решать задачи по комбинаторике или писать ту или иную сортировку, то это странный собес — точнее идиотский.
И свои гипсовые прикидки вместо мраморной скульптуры — он тоже не продаёт.Гипсовые прикидки и программист не продаёт — ну, если только не в цейтноте — программист «замесит» код до нужной кондиции качества и тогда это пойдёт в продакшен, если, конечно у него не будет цейтнота.
Кстати о гипсе и мраморе. — Жил был американец один. Он поднялся до миллиардера на железных дорогах. И решил он съездить во Францию и прикупить скульптуры Огюста Родена. Поехал и скупил. А вот разрешение на вывоз ему Франция то и… запретила то. Тогда он нанял скульпторов и они вырубили ему копии известных работ Огюста Родена. Вырубили из… мрамора.
И эти мраморные копии американец вывез в Штаты и сейчас их можно посмотреть в музее Огюста Родена в центре Филадельфии.
Парадокс в том, что оригиналы этих работ были сделаны из… гипса. — Огюст Родена был нищим скульптором и на мрамор у него просто не было средств, поэтому он месил гипс для своих работ.
Ну и ещё один «месильшик» — Альберт Эйнштейн — если почитать о том как он «месил» при создании своей ОТО — как ошибался, как подбирал вид основной формулы в своей ОТО — то миф о том, что только «рубильщики» есть гении, этот миф развеется как дым в голове.
"Рубильщики" и "месильщики" — это не определение людей, а определение методов программирования, которые применяют все в то или иное время.Нет.
Это как профи шахматист — «рубит» в сеансах одновременной игры, потому что у него просто нет времени, и «месит» играя один на один при обычном регламенте.Если он будет «месить» при обычном регламенте, то он проиграет даже новичку.
Даже когда профи играет при обычном регламенте он подавляющее большинство ходов даже не рассматривает. В принципе. Из нескольких десятков ходов, которые можно сделать в типичной шахматной позиции он сразу видит 2-3 имеющих смысл — и исследует уже только их.
В этом принципиальное отличие от месильщика. Который тупо перебирает десятки комбинаций — в то числе очевидно бессмысленные.
Если программист «рубит» код и при этом он раньше не решал эту задачу, то это странно и его «рубленный» код потенциально опасен ибо он этим «играет в рулетку», не более того.Знаете какая штука: у шахматистов при любом регламенте действует правило «взялся — ходи». То есть шахматист может что угодно себе воображать — но если он уже что-то делает, то он, соотвественно, принял какое-то решение.
Почему вы считаете, что программист на это не должен быть способен? Между «рубиловом» и «месиловом» есть ещё и промежуточные стадии. Подумать вам обычно никто не запрещает. А вот уже если вы начинаете писать код — то хотелось бы, чтобы вы это уже делали осмысленно, а не с подходом «а вдруг заработает?»…
Если при собесе кандидату вообще не сообщают что от него будут требовать на собесе «рубить», а кандидат не угадает что ему предложат решать задачи по комбинаторике или писать ту или иную сортировку, то это странный собес — точнее идиотский.Нормальный вполне. При реальной работе вам же тоже не предупреждают за полгода о задаче, которую попросят решать…
Гипсовые прикидки и программист не продаёт — ну, если только не в цейтноте — программист «замесит» код до нужной кондиции качества и тогда это пойдёт в продакшен, если, конечно у него не будет цейтнота.Извините, но если вы надеетесь свой код «домесить» до нужной кондиции — то вы таки продаёте «гипсовую модель».
Я, иногда, тоже люблю поиграться с IDE, когда я не понимаю как та или иная конструкция языка работает или библиотека. В C++/Haskell/Rust очень godbolt помогает, для C#/Java тоже, наверное, что-то есть (давно ничего сложного не писал, каюсь).
Но пока я не буду понимать как что-то работает — я не буду даже пытаться писать код, который потом должен пойти в продакшен. Ну потому что… я ж такого могу понаписать, когда не понимаю что делаю.
Да, иногда я делаю ошибки, иногда чего-то не понимаю… но сама идея: написать код, а потом запускать отладчик, чтобы понять что там у меня в коде проиходит… ну дикость же: как я это написал, если я понятия не имею что оно делает и как работает, извините?
К нам недавно новый человек пришёл и обнаружил, что у нас
gdb нельзя использовать так, как написано в инструкции. Ну файлик там потерялся один… и за два месяца об этом так и не узнали… потому что в gdb ничего не исследовали.Из той же оперы рассказы 0xd34df00d о том, что он в Haskell не знает как дебаггером пользоваться.
Вот это — нормальный подход. А когда вы комбинируете куски кода случайным образом в надежде, что оно-таки пройдёт тесты… это другое.
Ну и ещё один «месильшик» — Альберт Эйнштейн — если почитать о том как он «месил» при создании своей ОТО — как ошибался, как подбирал вид основной формулы в своей ОТО — то миф о том, что только «рубильщики» есть гении, этот миф развеется как дым в голове.Не знаю откуда вы этот миф вытащили. «Месильщик» — это человек, который не знает что делает. Он может «намесить» ОТО, а может, как тот же Эйнштейн после ОТО — месить свой чан 40 лет и… не вымесить ничего.
Да, когда вы изобретаете что-то ну вот совершенно новое, когда задачу до вас никто не решал… иногда у вас просто нет выбора. Но с учётом того, что можно месить очень и очень долго и не сделать в результате ничего… такое право, знаете ли, нужно заслужить.
Если программист «рубит» код, то это означает что он раньше уже решал эту задачу.Нет — это значит, что он видел (или знает) как решать похожую задачу. Не обязательно строго эту.
Но ведь 99% программирования — это решение вариаций тех задач, которые уже кто-то когда-то решал. Откуда у вас тут «замес» взялся?
Что приятно — в тело этой функции смотреть не надо, чтобы понимать, что она делает, достаточно типа.ну и где здесь месильщики? Если вы итоге всё равно всё свелось к тому, что вы «понимаете, что она делает»?
Напомню откуда вообще взялся этот термин (потому что, похоже, ссылки никто никогда не открывает):
Разгадку подсказал мне однажды сам кандидат: он объяснил, что обычно, когда пишет код, то сразу же пытается его запускать и редактирует вусмерть, пока хоть как-то не заработает. Вот как это делается! Если достаточно долго месить чан с перловой кашей, в синтаксическом мусоре можно рано или поздно узреть лик Ларри Уолла. Когда удалось нашаманить, чтобы текст компилировался, то можно выпускать бета-версию, а когда программа сможет хоть раз не упасть и не зависнуть — финальный релиз. Остальные баги найдут пользователи.
Можно представить себе и «месильщика-функциональщика». Это будет человек, который случайным образом переставляет куски кода — до тех пор, пока компилятор «не заткнётся».
Вот только есть проблема: представить-то себе можно, а вот увидеть — нет. И вот уже вот эта фраза А тайпчекаться будет
traverse sequence x — что логично — у него не возникнет.Увидев что
sequence traverse x не тайпчекается — он всего лишь с вероятностью 50% переставит местами traverse и sequence. А с вероятностью 50% — решит, что «чегой-то датчик в дырку не лезет… и провода, блин, короткие»… после чего полезет в стандартную библиотеку (или в Hoogle), чтобы эти провода нарастить. И будьте уверены — чего-нибудь он там таки найдёт.Помните ту историю с датчиком на Протоне, который кувалдой забили «вверх ногами», а потом, когда подключить не смогли, нарастили провода (так как конструкторы предусмотрели-таки защиту от незакрученной контргайки и сделали так, что неправильно установленный датчик подключить нельзя — длины провода не хватит). Вот это вот — настоящие «месильщики» и настоящие последствия.
У нормального программиста код, который протайпчекался, хотя не должен — вызывает не меньшее раздражение, чем код, который не протайпчекался, хотя должен. Я в Хаскелле не силён, поэтому C++.
Возьмём такой код:
constexpr Foo foo = {1};
void bar() {
foo.i++;
}
int qux() {
constexpr int baz = foo.i;
return baz;
}bar ни дёргай — а qux всё равно, почему-то, единицу возвращает.Нормальный человек вообще такого не напишет, но даже если и напишет — то «протайпчекает» у себя в голове или проверит нормальным компилятором (MSVC это ж не компилятор С++, а его действующая модель) и увидит в чём проблема.
А месильщик — не увидит. И будет жаловаться, что у него «компилятор не работает». Да, он, в некотором смысле, не работает — но проблема нифига не в том, что он правильную программу неправильно компилирует.
Кроме компилтора и дебаггера у нормального разработчика ещё и свои мозги должны быть! А у месильщика — их нет. Ну или есть, но задействуются под другие задачи, не под программирование, это непринципиально.
И это будет работать.И вот это вот, собственно, принципиальное отличие.
То что вы делаете — очень похоже на то, что делает компилятор, когда он «вымешивает» какое-нибудь x / 97 в инструкции ассемблера.
Обратите внимание: 4 разных компилятора «намесили» 4 разных последовательности инструкций. Существенно разных. Но все 4 включают в себя константу 354224107 и, что более важно, все четыре вариант дают правильный ответ на всех допустимых значениях
x.На каждом этапе мы решаем очень локальную задачу, не думая о каком-то глобальном контексте. Поэтому на типизированном ФП можно тоже месить кашу, пока не намесится (и, кстати, crush strategy в Coq примерно так и делает, только автоматизированно за вас).Вы это можете делать и в типизированном ФП и где угодно только если грамотно ограничите набор допустимых функций, которые можно использовать. Иначе нет гарантий, что то, что этот замес когда-либо остановится, а то, что вы намесили — будет работать.
Просто перломесильщики пытаются запускать, а мне ругань тайпчекера прямо в IDE приходит в виде красной полосочки слева.Это как раз мелкое и нифига не принципиальное отличие.
Принципиальная разница в другом: в том, что когда перломесильщик добился того, что тесты проходят — это ничего не говорит о том, что будет на других исходных данных, а вот данные тайпчекера дают некоторые гарантии. Недостаточные всё равно для того, чтобы код работал во всех случаях.
Да и этот ваш «замеc» — он хорош, когда вам нужен только
fmap и traverse, а если вам потребуется чего-нибудь свернуть? Типы у foldl и foldr достаточно похожие для того, чтобы можно было, во многих случаях, заменить один на другой, а flodl' и foldl — «неотличимы до уровня смешения».Тем не менее их замена может очень сильно результат вам испортить… а уж если мы перейдём к реальным программам, где далеко не все функции имеют принципиально отличные сигнатуры…
Иначе obvious proof search в идрисе или тактики в коке не работали бы.А они всегда работают? Или только если «звёзды правильно встанут»?
То есть, если сесть и раскрутить сахар из всех этих traverse, sequence и fmap, то, наверное, можно сказать, как задача решается, но не более.Ну если вы можете доказать что задача-таки решается, то больше ничего особо и не нужно. Проблемы возникают когда она-таки не решается… а решается что-то другое, не то, чего просили…
Тогда уже придётся думать, да. Ленивость — очень нетривиальная штука.Да и без ленивости можно ведь, практически, любую задачу с собеседования в ФП или даже, если совсем заморочиться, в типы перевести.
Вот вам типична задача с собеседования, переведённая (надеюсь правильно) в Haskell. Изначально она была про JavaScript и DOM-дерево, ну да ладно, выкинем ненужности.
Посчитать расстояние между двумя этементами в двух «объединяющихся списках»:
distanceBetween :: (Eq a, Num b) => [a], [a] -> b
x = 5:6:7:[]
a = 0:1:3:x
b = 2:4:x
-- distanceBetween a b := 5
Решение, в приницпе, тривиально — там строчек 20-30 на императивных языках получается, на Haskell/Python будет чуть покороче (закрывающие скобочки не нужны). Но фиг вы его «намесите», если не понимаете что тут происходит и не можете, прежде всего, придумать алгоритм. А иначе фигня получится. Примерно как тем же Эратосфеном, где «наивная» реализация даёт сложность хуже, чем у тривиальной проверки на делимость без всякой «зауми».
«Месильщик» — это не человек, который использует подсказки компилятора! Она для того и нужны, чтобы их использовать!
«Месильщик» — это человек, которому тесты и подсказки компилятора заменяют голову!
И вот тут-то и возникает вопрос: ребята, а вы, как бы, подумайте. Если бы те задачи, за которые я (или мой работодатель) готов платить решались бы «без применения головы» — стал бы кто-то за них платить?
Ответ, как ни странно, «да»: есть куча компаний, которые продают «ручную работу» программиста. Хотя вместо него можно было бы запустить скрипт и результат будет качественне и будет получен быстрее. Ну вот как аляповатые изделия из золота с биркой «ручная работа» могут стоить дороже, чем более качественная «штамповка».
Но это, по большому счёту, «развод ничего не понимающего заказчика на деньги».
Если же у вас заказчика нет и «разводить на деньги» некого… то «месильщики» вам не нужны. В принципе. Те задачи, который они могут исполнять может либо выполнять сам компьютер (при наличии соотвествующего компилятора/скрипта) — и тогда зачем вам «месильщик»… компьютер повышения зарплат требовать не будет!, либо не не может — и тогда вам «месильщик» всё равно не нужен, так как доверять результату его работы вы не можете!
функций Int → Int счётно бесконечное количество.Тут что-то не так. Если у вас
Int конечен, то таких функций будет конечное число. А если не конечен — то на такие функции можно отобразить действительные числа и потому их количество несчётно. Из чего, кстати, следует, что не все такие функции можно представить в виде программы, но это, как бы, очевидно и без того: в реальном компьютере и с реальными программами никаких «акутальны бесконечностей», конечно, не бывает.Впрочем это уже слишком далёкая от «месильщиков» тема.
Посчитать расстояние между двумя этементами в двух «объединяющихся списках»:
Если честно, я так и не понял, что спрашивается в задаче.

Найти минимальное число шагов, которые нужно сделать для того, чтобы попасть в одну и ту же вершину.
В оригинале было DOM-дерево и нужно было найти минимальное его подмножество, такое, что от одной вершины можно пройти к другой, потому ответом было не 5, а 6… но эти числа, понятно, отличаются на единичку, что непринципиально.
Я думал я один прочитал и ничего не понял, но решил не подавать вида.
Окей, что значит "в одну и ту же вершину"? Шаги откуда? Почему ответ "5" для этого примера?..
Окей, что значит «в одну и ту же вершину»?Вершины считаем разными, для простоты.
Шаги откуда?От начала двух списков.
Почему ответ «5» для этого примера?..Потому что только 5 элементов у нас в одном из списков, но не в другом: 0, 1, 2, 3 и 4. Элементы 5, 6, 7 — общие и мы их не учитываем.
а, я понял. Просто из-за того что изначально вы оптимизировали высказывание, скопировав общую часть в X — понимание что на входе и что на выходе — пропало.
То есть задача по сути найти для каждого списка индекс общего суффикса? Если да то вроде решение очевидно
Если да то вроде решение очевидноНаписать сможете?
Просто из-за того что изначально вы оптимизировали высказывание, скопировав общую часть в X — понимание что на входе и что на выходе — пропало.Ну… извиняюсь «за срезание углов» при объяснении задачи на сайте. Но только X там не зря всунут. Потому что вы же понимаете, что я, перед запуском программы засуну в него [2*N..], а в два «начальных» куска засуну нечётные числа от 1 до 2*N-1, а в другой — чётные от 2 до N… и буду, разумеется, хотеть решение, работающее за время порядка O(N)…И да — решение, разумеется, по-прежнему несложное, только непонятно как его вам «замес» (с типами или без) найти поможет.
Ну решение влоб: сделать реверс обоих списков, через зип найти наибольший общий префикс, посчитать длину хвостов, если я правильно понял задачу.
Или это не то?
И да — решение, разумеется, по-прежнему несложное, только непонятно как его вам «замес» (с типами или без) найти поможет. Можно без явного реверса просто рекурсию написать, но смысл будет схож.
Ну, на простых задачах и типы простые — аппликатив, траверс, всё.
Или это не то?Это примерно то. Первые 10% обсуждения на собеседовании. Кандидата, разумеется, следует похвалить… и изменить
X. Читаем ещё раз:я, перед запуском программы, засуну в него [2*N..]После этого ваша программа станет работать несколько… дольше, чем хотелось бы. Вроде бы даже ленивость Хаскелль не спасёт. Можно себе представить «ещё более ленивый» язык, но дальше — там же уже ограничения на скорость работы этого всего.Ну, на простых задачах и типы простые — аппликатив, траверс, всё.Вот нифига не «всё». Вы сначала задачу-то решили, потом «всё» будете говорить.
После этого ваша программа станет работать несколько… дольше, чем хотелось бы. Вроде бы даже ленивость Хаскелль не спасёт. Можно себе представить «ещё более ленивый» язык, но дальше — там же уже ограничения на скорость работы этого всего.
Так если список бесконечный, то у нас гарантий нет. откуда мы знаем, что после 11111111111 не будет внезапно 2?
Так если список бесконечный, то у нас гарантий нет.Да, именно так: в типах Haskell — такие гарантии не выразить. Но если принципиально отказываться от задач, которые в типах Haskell не выразить, то вы вообще немного чего написать сможете.
откуда мы знаем, что после 11111111111 не будет внезапно 2?Я сказал.
Или вы про исходную задачу из которой была порождена «задача для собеседования»? Там тоже всё просто: изначально, как уже говорилось, речь шла про дерево, элементы — это, собственно, адреса нод, если нода одна и та же, то и предок у неё тот же (если кто-то нам битики в памяти, не переставляет, пока программа работает, конечно… но тут уже и Haskell и Idris бессильны будут).
а, я подумал, что у нас список чисел, и нет гарантий что все уникальные.
Тогда возникает вопрос — отсортированы последовательности или нет. Елси речь про адреса — то явно нет.
Елси речь про адреса — то явно нет.Да, неотсортированы. Пожалуй нужно будет это в начальном примере тоже учесть.
Ну на первый взгляд решение может как-то так выглядеть:
use std::collections::HashSet;
use std::hash::Hash;
fn distance_between<T: Eq + Hash + Copy>(xs : impl Iterator<Item=T>, ys : impl Iterator<Item=T>) -> Option<usize> {
let mut set : HashSet<T> = HashSet::new();
for (x, y) in xs.zip(ys) {
if x == y {
return Some(set.len() + 2)
} else if set.contains(&x) || set.contains(&y) {
return Some(set.len() + 1)
} else {
set.extend(&[x, y])
}
}
None
}
fn main() {
let a = [0,1,2,3,5,6,7];
let b = [2,4,5,6,7];
println!("{:?}", distance_between(a.iter(), b.iter()));
}Взял раст, потому что в хаскелле мапа требует Ord по понятным причинам. Ну и цикл ручной, в хаскелле был бы нормальный фолдр, но тут же не ленивые итераторы.
не уверен, что рабоатет корректно, сейчас убегаю по делам, написал за 5 минут что в голову пришло, мог ошибиться.
Взял раст, потому что в хаскелле мапа требует Ord по понятным причинам.И именно поэтому в исходной задаче таки
Eq, а не Ord.Ну и цикл ручной, в хаскелле был бы нормальный фолдр, но тут же не ленивые итераторы.Ленивость там можно применить, но вообще — она тоже не нужна. Чисто чтобы чуть покрасивше выглядело.
не уверен, что рабоатет корректно, сейчас убегаю по делам, написал за 5 минут что в голову пришло, мог ошибиться.Да нет, всё плюс-минус правильно, только памяти вы тратите много и скорость не та.
Но да — это то, что изобретает хороший кандидат на втором шаге. Не знаю почему — тут на самом деле мапа нужна, как зайцу стоп-сигнал.
Будет время — подумайте, всё-таки, над полным решением — с
Eq, без Хешмапов, «на пальцах». Там всё не слишком сложно, на самом деле.Подсказка: 1 + 2 + 4 +… + 2ⁿ = 2ⁿ⁺¹-1
И именно поэтому в исходной задаче таки Eq, а не Ord.
Ну тут вопрос к хаскеллю. Насколько я видел, на линейных типах которые недавно помёржили сделали мутабельную хэшмапу которой Ord не нужен. Но я пока не такой блидинг эдж использую
Ленивость там можно применить, но вообще — она тоже не нужна. Чисто чтобы чуть покрасивше выглядело.
Без ленивости не будет раннего выхода из foldr, а значит будет зависон если список бесконечный
Да нет, всё плюс-минус правильно, только памяти вы тратите много и скорость не та.
А где скорость не та? O(N), при первом совпадении будет выход. К слову, по-моему оно неправильно будет работать если одна из последовательностей будет сильно длиннее другой, тут уже стоит список пройденных вариантов держать.
Будет время — подумайте, всё-таки, над полным решением — с Eq, без Хешмапов, «на пальцах». Там всё не слишком сложно, на самом деле.
Подсказка: 1 + 2 + 4 +… + 2ⁿ = 2ⁿ⁺¹-1
Если речь про математику на битах, то во-первых на битах считать дольше чем на байтах, а во-вторых не факт что числа влезут в 32-64битные переменные, а делать bitarray произвольной длины это во-первых не очень тривиально, а во-вторых весьма медленно, как я выше говорил.
А где скорость не та? O(N), при первом совпадении будет выход.В хешмапе. Там формально, если просчитать, с учётом необходимости расширения и хеша и хешфункции при увеличинии размера вылезет как минимум O(N log N), а может и больше.
Чудес-то в природе не бывает: задача проверки присутствия элемента во множестве — она O(N log N), на практике
hashmap выигрывает не из-за ассмиптоматики, а из-за константы.К слову, по-моему оно неправильно будет работать если одна из последовательностей будет сильно длиннее другой, тут уже стоит список пройденных вариантов держать.Да, это проблема. Можете «хвостик» потерять — и часть элементов вместе с ним. Но с бесконечными списками работать будет.
Если речь про математику на битахУжас какой. Ну почему все, вот почти буквально все, в этой задаче пытаются даже не из пушки по воробьям стрелять, а прямо баллистические ракеты использовать?
Я когда вас про первый вариант с «разворотом» сказал, что это — полезная часть задачи — ведь не лукавил.
Всё что вам нужно — аккуратно «обкорнать» как-нибудь эти два списка (выкинув «лишний», потенциально бесконечный, хвост) — и тем самым свести задачу к уже решённой.
Уточнённая подсказка: 1 + 2 + 4 +… + 2ⁿ < 2ⁿ⁺¹
Ну, у меня всегда были проблемы с олимпиадными алгоритмами, потому что они решают обычно какие-то странные задачи. Которые, конечно, иногда встречаются, но не так, чтобы часто.
Чтобы "обкорнать" хвост нужно найти элемент, совпадающий в обоих списках, причем помнить его позицию в каждом из них. Я сходу не понимаю, как вы предлагаете это сделать не запоминая все встреченные элементы. Код который я выше написал делает эту самую очевидную вещь — ведем перечень всех встреченных элементов, как только нашли второй похожий, то значит это и есть хвост который мы искали.
Ну и не очень понятно при чем тут 1 + 2 + 4 + ..., если во-первых элементы могут быть и нечётными, а во-вторых вы говорили что в оригинальной задаче это были адреса, и тогда 0xd34df00d, 0xdeadbeef и прочие которые будут лежать в массиве точно не уложатся в подобную формулу.
Я сходу не понимаю, как вы предлагаете это сделать не запоминая все встреченные элементы.Ну все-то нам зачем? Можно поступить, как в Алгоритме Брента: предположим, что ответ в нашей задаче — не больше, чем
2k. Можем мы найти какой-нибудь «общий» элемент? Да раз плюнуть — возьмём 2kй элемент из первого списка, сравним с ним 2k+1 элементов из второго. Если повезло — получим ответ, не повезло — увеличим k на единичку и повторим.Это сильно не лучший алгоритм — но он уже линеен и дальше остаётся уже только думать про константу.
Ну и не очень понятно при чем тут 1 + 2 + 4 + ..., если во-первых элементы могут быть и нечётными, а во-вторых вы говорили что в оригинальной задаче это были адреса, и тогда 0xd34df00d, 0xdeadbeef и прочие которые будут лежать в массиве точно не уложатся в подобную формулу.Ну вообще-то это была попытка вывести вас на классику жанра: ArrayList (в Java) и std::vector (в C++). Да и вообще — тот же подход и в Quickselect и вообще везде, где просто повторение чего-либо для каждого элемента слишком дорого: если каждый элемент мы можем обработать за время порядка
N, но мы будем обрабатывать не все элементы, но только лишь 1й, 2й, 4й,… 2kй… то всё это, вместе взятое, не успеет накопиться слишком большим для того, чтобы сложность стала нелинейной. Это ж классика амортизационный анализа!Зачем же сразу в хешмапы-то?
Ну все-то нам зачем? Можно поступить, как в Алгоритме Брента: предположим, что ответ в нашей задаче — не больше, чем 2k. Можем мы найти какой-нибудь «общий» элемент? Да раз плюнуть — возьмём 2kй элемент из первого списка, сравним с ним 2k+1 элементов из второго. Если повезло — получим ответ, не повезло — увеличим k на единичку и повторим.
Это сильно не лучший алгоритм — но он уже линеен и дальше остаётся уже только думать про константу.
Во-первых насколько я понимаю оно работает только если числа более-менее разные всё-таки. А если они все между 2^30-2^32 — то работает не очень хорошо.
Во-вторых вариант с хэшмапой в таком случае это размен памяти в производительность, потому что с ним мы идём по двум спискам и каждый элемент просматриваем ровно один раз. Ресайз мапы — это опять же трейдоф, мы можем выделить заранее памяти под ожидаемую длину префикса. В итоге константа такого способа будет в районе единицы, каждый элемент смотрим один раз и пихаем в мапу.
Возможно, у меня оперденевский биас, простота восприятия важнее производительности, а производительность важнее памяти.
Во-первых насколько я понимаю оно работает только если числа более-менее разные всё-таки.Какая нам вообще тут разница какие там числа? Мы их только на раверство/неравенство сравниваем, больше нам вообще ничего не нужно.
А если они все между 2^30-2^32 — то работает не очень хорошо.Они накак не могут быть все между 230 и 232, потому что речь идёт не про значения чисел в массиве, а про их позицию. В первом массиве и/или во втором. А позиция — нумеруется с нуля (у некоторых, особо одарённых, с единицы), так что если уж у вас там есть число с индкесом больше 230, то и числа со всеми предыдущими индексами — тоже есть.
Возможно, у меня оперденевский биас, простота восприятия важнее производительности, а производительность важнее памяти.Скорее у нас разные понятия о том, что такое простота восприятия. На C++ то, что я описал будет примерно так:
Node* find_some_common_node(Node1* p, Node2 *q) {
size_t step_size = 1;
for(;;) {
for (int i=0; i < step_size; ++i) {
if (p == q) {
return p;
} else {
p = p->next;
}
}
step_size += step_size;
std::swap(p, q);
}
}
Кроме того, в данном случае, у нас ведь были вполне конкретные требования и к производительности и к памяти…
P.S. Аллокации памяти вообще зло: они хорошо работают, когда вы получаете многомегабайтные массивы на вход, но когда мы работаем с чем-то мелким и аллоцировать приходится часто… не так редка ситуация, когда аллокации памяти уходит больше времени, чем на всё остальное.
Вот если вам дополнительная память вообще, в принципе, нужна и без неё никак не обойтись — тогда уже не так важно сколько именно вы аллоцируете.
Что не выглядит особенно сложным — ну а вторую часть, как мы уже обсуждали, вы уже написали…
Ну если внимательно почитать, то действительно несложно. Просто не знаю как другим, а мне тяжеловато даются алгоритмы где делается swap и переменные сильно меняются ролями. Ну и два вложенных цикла: понятно, что асимптотика остаётся линейной, но во варианте с мапой у нас один линейный проход, где каждый элемент посещается один раз. Но он аллоцирует, да, в этом его минус.
В целом, я вас понял, алгоритм хороший. Придумал бы я его? Почти уверен, что нет.
Ну, как-то умудрились же: https://github.com/tweag/linear-base/blob/master/src/Data/HashMap/Linear.hs#L72
Я, кстати, наверное, что-то упускаю, но я не знаю, как решать эту задачу на хаскеле за линейное от отличающейся части, а не линейное от всего входа время.Я, если честно, тоже.
Чистота и отсутствие указателей не даст вам отличить случай с шарингом от случая без шаринга.Очень хорошее замечание — и по делу. Если кандидат такое говорит, то его тоже следует похвалить, обратить внимание, что там не зря написано
Eq a (такой себе «рояль в кустах») и сказать: «Ok, защитано — пусть все элементы разные».Который простым «намешиванием базовых функций» я, например, получить не умею.
Я решил вашу задачу с дополнительным условием «все элементы разные»?Подловили на неточности, я бы сказал.
То есть да, посмеяться над таким решением, конечно, можно, но имелось-таки в виду не "все элементы первого списка отличаются от всех элементов второго списка", а "все объекты
a, имеющиеся в задаче различны, но при этом, разумеется, поскольку списки объединяются, часть элементов могут быть найдены и в первом списке и во втором"… и ровно на основани того свойства, что часть элементов есть и там и там — их предлагается проигнорировать…и тогда грамотной заячно-черепахоподобной стратегией обхода списков можно решить задачу за линейное относительно различающейся части времяну вы уже почти решили задачу, на самом деле. Только там никаких бит в указателях не нужно, бррр…
Почему все пытаются эту задачу усложнить, блин? Вы не один такой, можете успокоиться — 90% из тех, кто эту задачу, в конечном итоге, решает почему-то стремятся удариться куда-то в какие-то сложные структуры данных, пометки, хеши, бог знает что…
Да, там алгоритм не совсем тривиальный и случайным образом комбинируя функции из стандартной библиотеки он не родится… но он и нифига не «заумный», требующий каких-то хитрых конструкций и сложный структур данных… простые манипуляции «на пальцах».
P.S. Слава богу на функциональных языках никто её не решал. Когда у вас есть ноды в памяти и ссылки — то задача оказывается простой и естественной, но эта же задача в функциональном языке, внезапно, становится несколько… странной. Именно вот формулировка оказывается странной, не решение, конечно.
Но заикаться про это на собеседовании нельзя, так как огромный процент хороших кандидатов (вполне способных эту задачу, с несколькими подсказками, решить) — понятия не имеют про этих двух персонажей.
И да, меня это тоже удивляет.
P.S. Кстати да — зря я, конечно, в эти списки полез: собственно «зайца и черепаху» ведь тоже нифига «исходя из типов» не «намесить».
Подсказки лично мне ничего не дали, но я просто именно похожесть задачи в итоге вспомнил. И долго старался суть понять, что требуется то. Найти первый элемент, который входит в обе коллекции одновременно, так?
Найти первый элемент, который входит в обе коллекции одновременно, так?Да, именно так.
Это довольно сложный приём, который скорее нужно именно знать, где-то прочитать, чем внезапно догадаться на собеседовании.Ну всё-таки это собеседование. Кандидат же не один задачу решает. В крайнем случае я могу даже и сам алгоритм рассказать и даже показать (на доске, фломастерами) — важно же как кандидат это закодирует, а не сможет ли он это придумать.
По сути, чтобы её решить — надо додуматься вести два указателя с разной скоростью.Тут фишка ещё и в том, что тут недостаточно вести два указателя с разными фиксированными скоростями. Тут нужно либо что-то типа алгоритма Брента, либо переменные скорости.
В крайнем случае можно и на хешмапах остановиться и сделать вид, что «всё хорошо, прекрасная маркиза, мы именно это и хотели» — но это если уж кандидат сильно нервничает.
функций Int → Int счётно бесконечное количество
Вообще их больше, но если вы имеете в виду те, которые можно запрограммировать, — тогда, конечно, счётное.
Число состояний управляющего устройства машины Тьюринга конечно несмотря на бесконечную ленту, и это не просто так.
Счётность берется если ограничиться не одним компьютером, а всеми возможными на практике компьютерами и взять нечто вроде предела или точной верхней грани их возможностей.
Счётность берется если ограничиться не одним компьютером, а всеми возможными на практике компьютерами и взять нечто вроде предела или точной верхней грани их возможностей.Тут вы немедленно упрётесь в формулировки «всеми возможными на практике» и «точной верхней грани их возможностей».
Рассмотрите лениво реализованную функцию, которая возвращает то, что у неё уже один раз запрашивали (если такое происходило), но если нет — дёргает RDRAND. При использовании «бесконечной ленты» он может, очевидно, реализовать любую функцию (если повезёт)… но поскольку на практике у вас бесконечной ленты нет, то всё упрётся в кучу философии: конечна у нас вселенная или бесконечна, рассматриваем ли мы модель с множественными вселенными или с детерминизмом… в общем можно знатно поразвлекаться…
При использовании «бесконечной ленты» он может, очевидно, реализовать любую функцию
Вот совсем не очевидно. Когда в дело вступают бесконечные множества, а особенно множества более чем счётные, то приходится быть очень аккуратным — интуиция часто подводит.
Всех возможных результатов RDRAND — конечное число. В лучшем случае счётное. А функций из целых чисел в целые — континуум. Тут нужен генератор случайных действительных чисел, а такой штуки по-всей видимости существовать не может.
Всех возможных результатов RDRAND — конечное число.Нет.
В лучшем случае счётное.Нет. Это не генератор псевдослучайных чисел.
Это аппаратный генератор истинно случайных чисел (во всяком случае так обещает Intel). Если вы запустите его на двух машинах — вы получите двоичную запись двух «истинно случайных» вещественных чисел.
Вернее не получите, так как компьютер, рано или поздно, сломается и выдача нулей и единичек прекратится. Но если предположить, что он будет работать вечно? А имеет ли смысл это предполагать?
Тут нужен генератор случайных действительных чисел, а такой штуки по-всей видимости существовать не может.Вот тут-то у вас и начнётся философия. У нас есть (вернее Intel утверждает, что есть) генератор случайных последовательностей нулей и единиц (не псевдослучайных). Можем ли мы считать что этот генератор выдаст нам, за бесконечное время, случайное действительное число или не можем?
Я боюсь в обсуждении этого вопроса можно увязнуть глубоко и надолго.
Но если предположить, что он будет работать вечно?
Вообще, что-то может и получится. А может и нет. Например, гарантировать получение даже значения искомой функции в нуле нельзя. То есть можно например считать, что пары "10" и "11" кодируют двоичные цифры 0 и 1 значения функции для очередного значения аргумента, а пары "00" и "01" означают конец очередного числа. Но тогда на последовательности из одних нулей мы всё равно навечно зависнем в ожидании.
Но тезис Чёрча (который определяет понятие вычислимости) это, по-видимому, всё же не отменяет. Хотя надо будет поискать, что по этому вопросу умные люди пишут.
P. S. А если прямо вот представить, что реально вечность прошла и мы получили всю последовательность целиком, то там тогда такие гадости полезут из нестандартных моделей арифметики, что всякие остатки интуиции придётся выбросить окончательно.
P. S. А если прямо вот представить, что реально вечность прошла и мы получили всю последовательность целиком, то там тогда такие гадости полезут из нестандартных моделей арифметики, что всякие остатки интуиции придётся выбросить окончательно.Это вы ещё не учли то, что пространство и время квантуется. И не решили — конечна вселенная или бесконечна. Хотя если конечна и состояний у неё конечное число, то тут всё понятно. А вот если бесконечна — то как и в каком именно смысле она бесконечна.
В общем тут можно долго рассуждать на тему… объясните лучше как вы собрались «намесить» решение простенькой задачки с собеседования…
Понимаю, что, но не понимаю, как.Выскажу нессколько еретическую мысль: а оно надо? С одной стороны, это дополнительный слой абстракции, который может потечь или в котором может быть что-то сломано внутри (баг либы или компилятора), но с другой — а понимаем ли мы, как работает код на всех уровнях? Когда я пишу на С, раскрутку макросов я понимаю, преобразование сишного кода в ассемблер понимаю ограниченно (на микроконтроллерах ещё понятно, почему именно так, а на х86-64 уже далеко не всегда), а вот что там на уровне вентилей и схемотехники уже почти для всех, кроме fpgaшников, обычно тёмный лес. Более того, подавляющему количеству разработчиков это ни разу не упёрлось до момента, пока не надо, например, разбираться в подтяжке ног, которые в новый ревизии неустановленные работают входами, ловят наводки и не дают уйти в сон.
Кому-то надо, кому-то не надо. Но вот моя личная практика показывает, что рано или поздно с декларативными описаниями приходится разбираться как они разворачиваются в императивные. Прежде всего HTML+CSS и SQL в моей практике. Наверное, просто потому что компьютеры у нас императивные всё таки.
Наверное, просто потому что компьютеры у нас императивные всё таки.Нет, не поэтому. Обратите внимание:
Прежде всего HTML+CSS и SQL в моей практике.Кто, когда и зачем разбирался с тем, как HTML «разворачивается в императивное описание»? Я таких людей не видел. А вот CSS и SQL — это да. Даже если люди специальные, особо тренированные для последнего.
А никогда не задумывались — почему так?
Ответ: HTML — это декларативное описание проблемы. CSS и SQL — нет. Вот ни разу нет. CSS и SQL — это, извините за выражение, жуть, созданная архитектурными астронавтами с целью, осознанной или неосознанной, обеспечить повышенное потребление ресурсов… ну и Job Security для определённого контингента лиц.
Обычно, когда сталкиваешьс с таким «п@здецом, летящим на крыльях ночи» — совет один: выкинуть этот высер и не использовать. В некоторых случаях (когда абстракция «опасная», но простая — как, например, в случае со сложением строк) — пользоватья приходится, но поскольку абстракция простая, то это, в общем и целом достаточно несложно.
Но CSS и SQL… была бы возможность расстрелять тех, кто это изобрёл (особенно первое) — рука бы не дрогнула. Особенно первое.
Почему эти «декларативные», с позволения сказать, описания — столь ужасны? Нет, не потому что они сложные. А потому что для них в принципе невозможно создать эффективное отображение в императивный код. Такой, чтобы время обработки было O(N) (где N — длина входного потока данных).
Там где декларативное описание удовлетворяет этому ограничению — это позволяет о реализации, о том, что компьютеры у нас, на самом деле, императивные — не думать вообще. Пример, кстати, HTML: пока к нему не прикручивается CSS его разбор — это строго линейная задача и проблемой, в общем-то, не является никогда.
SQL — это, в принципе, «язык программирования для аналитика»: по изначальной задумке SQL-запросы вводятся исследователем и он, «вынув» из базы какие-то данные на них смотрит. Глазками. Тут уже появляются проблемы, но, как и в случае с любым языком программирования, тот, кто пишет программу — решает что с ней делать.
В конце-концов если у вас программа на C++ (или Rust… или Haskell...) долго компилируется, то вы можете либо купить железо помощнее… или переписать её… или подождать… — выбор за вами. Так что тот факт, что задача ответа на вопрос «является ли вот это вот, то что я тут накорябал программой на C++» алгоритмически неразрешима… это плохо — но не катастрофа.
А вот когда SQL вкручивается куда-то как компонент системы большего размера — то тут начинаются проблемы. Так как линейности, предсказуемости нет… и контроля конечным пользователем над процессом — тоже нет. Но SQL, хотя бы в принципе, имеет область применения, где он осмысленен (хотя в 99% случаев он применяется неправильно — что и родило, по большому счёту, парадигму NoSQL). А вот CSS — это вредительство дистиллированное максимально: он всегда, в 100% случаев применятся так, что человек, который пишет CSS и человек, который от него страдает — разные люди.
P.S. Обиднее всего то, что у CSS была вменяемая альтернатива — JSSS. Но «архитектурные астронавты», пользуясь мощью Microsoft, продавили-таки CSS. И теперь из-за этого решения у нас — куча проблем. Впрочем так уж сильно «катить баллоны» на Microsoft не получится, так как почти во всех системах создания UI, даже в каком-нибудь примитивном Tk у вас эта проблема имеется. Однако там она, всё-таки, не является такой катастрофой. А вот CSS — таки является. Потому что когда его создавали, то основным девизом было: давайте отделим работу по стилизации и поручим её дизайнерам, которые про слово «алгоритм» и представления не имеют. Вот когда это произошло — джинн и вырвался из бутылки и начал пожирать все ресурсы, до которых мог дотянуться…
Кто, когда и зачем разбирался с тем, как HTML «разворачивается в императивное описание»? Я таких людей не видел.
Многие разбирались, кому было важно или просто интересно почему страница (даже без CSS) не рендерится одномоментно, в пределах одного видеофрейма, а идёт последовательно, когда браузер решает, что у него уже достаточно информации чтоб хоть что-то показать, пускай и потом перерендерить придётся. И для разных тегов в разных браузерах это "достаточно" сильно разное. А в заботе об UX приходится изучать порядок в котором будет декларативный html интерпретироваться в императивные команды отрисовки и подгонять его в нужную тебе последовательность
Но ведь 99% программирования — это решение вариаций тех задач, которые уже кто-то когда-то решал. Откуда у вас тут «замес» взялся?В анлгоязычной терминологии есть слова manufactoring и development. Первое обозначает промышленное производство, где одинаковые копии изготавливаются снова и снова: шурупы, серийные автомобили и т.д. Это как раз про решение типовых задач, которые уже кто-то когда-то решил. Второе это работа с большим количеством неизвестных, такая как как штучное наукоемкое производство или, например, строительство шахт.
Инженерия в АйТи это development (часто к нему добавляется приставка research &). Занятие, которое сопряжено с новизной и неопределенностью не может быть простым по определению.
Одной из самых затратных по времени статей расходов в АйТи является обучение кадров, которое должно идти постоянно. Желание получить с рынка волшебного персонажа, который все знает, все умеет и имеет опыт решения 99% задач, с чисто бизнесовой точки зрения вполне объяснимо. Но если вы не директор метизного завода, то такие мечты не особенно конструктивны. Навешивание ярлыков это вообще какой-то трэш. Подходит вам или не подходит конкретный кандидат это вопрос, на который можно спокойно ответить без всего вот этого. Разве не так?
Копирование в АйТи практически ни чего не стоит и даже самые дорогие дистрибутивы на рынке стоят сущие копейки, по сравнению с ценниками в иных отраслях. Если задачу уже кто-то решил — покупайте решение, а не инженеров.
Инженерия в АйТи это development (часто к нему добавляется приставка research &). Занятие, которое сопряжено с новизной и неопределенностью не может быть простым по определению.То, что 1% времени вы делает «что-то с новизной и неопределённостью» не означает, что 90% вы не занимаетесь рутиной.
Подавлющий процент времени любой, самые researchуный R&D занимается рутиной. Неважно — перенастраиваете вы микроскоп после замены катода или «пилите», в 100500й раз, копирование данных из одной структуры в другую… вы занимаетесь рутиной, а не какой-то там «новизной и неопределенностью».
Самое смешное знаете в чём? Я никогда не слышал этих баек про «новизну и неопределённость» у настояших учёных. Которые ещё помнят времена, когда Timsort было новинкой.
А в универе, я, в общем, с ними общался достаточно. Когда им нужно написать программу, чтобы что-то про неё сказать — они берут листок бумаги (или подходят к достке с фломастером) и, вы не поверите, её пишут. И у них, почему-то не возникает потребности «долго месить чан с перловой кашей» в IDE.
Да, то, что они пишут — зачастую старомодно и не слишком красиво (однобуквенные имена — норма), но оно, чёрт побери, работает. Не возникает вопроса «а какое вообще имеет отношения этот поток сознания без структуры и формы к обсуждаемой задаче»?
Одной из самых затратных по времени статей расходов в АйТи является обучение кадров, которое должно идти постоянно.Это, возможно, и является самой большой статьёй расходов, записанной отдельной строкой — но это не то, на что уходят деньги. Как это ни удивительно.
Желание получить с рынка волшебного персонажа, который все знает, все умеет и имеет опыт решения 99% задач, с чисто бизнесовой точки зрения вполне объяснимо.Это понятно. Но мне не нужно 99% всех задач (из которых 10% будут, всё-таки, сложные задачи, где можно запутаться). Мне нужно, чтобы быстро, качественно и безошибочно решались 90% простых, рутинных, тривиальных задач.
Потому что весь код проходит код-ревью, но из практики известно — тот код, который реализует интересную, нетривиальную, задачу — будут смотреть внимательно. А вот тот код, который из одного массива в другой байтики копирует — никто рассматривать не будет. Максимум — выскажут замечание, что переменные имеют плохие имена. И всё.
И потому мне важно, чтобы именно такой код — всегда писался грамотно. Не обязательно идеально… но грамотно — так, чтобы его не пришлось переделывать.
А у «месильщиков» — проблемы именно с этим. Не с новомодными, хайповыми, технологиями. А именно с рутиной. Вещами, которые уже 20 лет назад не были чем-то «новым и неопределённым».
Копирование в АйТи практически ни чего не стоит и даже самые дорогие дистрибутивы на рынке стоят сущие копейки, по сравнению с ценниками в иных отраслях.Даже самые дорогие дистрибутивы сами по себе задачу не решают. Когда вы подтягиваете к себе чьё-то чужое решение — вы автоматически получаете ежемесячный счёт. И нет, не в деньгах — а вот как раз в том самом инженерном времени, которые как вы сами заметили, дорогое.
Потому что кто-то теперь должен следить за изменениями в этом компоненте. И при обновлениях в нём — решать: затронут они ваш код или нет. И обновлять это всё кто-то должен.
Если вы берёте вещь, которая решает какую-то большую и сложную задачу — это нормально. Всё равно инженерное время экономится. А вот если вы берёте функцию в три строки (да даже и в сто строк) — то далеко не факт.
И, в долгосрочной перспективе, дешевле иметь такие простые вещи у вас, чем внезапно обнаружить, что новая версия
CHECK_EQ внезапно, обваливает вам билд на ботах (пример вполне реальный, кстати: можете посмотреть на историю вопроса).Это понятно. Но мне не нужно 99% всех задач (из которых 10% будут, всё-таки, сложные задачи, где можно запутаться). Мне нужно, чтобы быстро, качественно и безошибочно решались 90% простых, рутинных, тривиальных задач.
Но если у вас нет никого, кто мог бы решить эти 10%, то задачи останутся нерешенными
Но если у вас нет никого, кто мог бы решить эти 10%, то задачи останутся нерешеннымиНе видел с этим проблем. Никогда. Наоборот — все жалуются, что рутины много и очень малый процент задач оказываются такими, чтобы «мозги не затекали».
Спасает только понимание того, что если взять «месильщиков», то такие задачи, конечно, появятся, но будут, в большинстве случаев, упираться в том, что вы будете получать «чемодан без ручки» и не понимать что с ним, после этого делать — то ли выкинуть и всё с нуля переписать, то ли пытаться как-то всё-таки привести это в божеский вид.
А это, как бы, вовсе не тот вид творчества, который мог бы кому-нибудь понравится…
Мне временами нравится разгребать авгиевы конюшни кода. На год где-то хватает, если только этим заниматься. Главное, чтобы не было ощущения, что наваливают новые кучи быстрее чем они разгребаются
Главное, чтобы не было ощущения, что наваливают новые кучи быстрее чем они разгребаютсяДык для этого нужно как раз «месильщиков» не иметь. Ибо «намесить» что-то такое… «типа как вообще почти совсем работающее»… часто быстрее, чем разобраться и сделать грамотно.
P.S. Прекрасный (хотя и очень абстрактный) пример: покрытие графа. Это, как известно, очень сложная задача. NP-полная, всё такое. Но если чуть-чуть поменять формулировку — то она, вдруг, становится весьма простой. И если вы просто пишите программу «для прохождения тестов», то чуть-чуть подкрутить формулировку и сделать код, с которым непонятно что делать — легче лёгкого.
Не видел с этим проблем. Никогда. Наоборот — все жалуются, что рутины много и очень малый процент задач оказываются такими, чтобы «мозги не затекали».
Только когда такие задачи появляются на самом деле, люди начинают ныть "ой а чё так сложна", и полгода буксуют за задачей на которую планировали месяц.
Только когда такие задачи появляются на самом деле, люди начинают ныть «ой а чё так сложна», и полгода буксуют за задачей на которую планировали месяц.Бывает и так. Но это всё равно лучше, чем полгода «подчищать хвосты» за кодом, который должен был бы «просто работать».
Например недавно мы добавляли в продукт поддержку AArch64. Так вот: задачей, которая выбилась из графика больше всего и где было больше всего стонов «ой а чё так сложна» была задача тупо изменить систему сборки так, чтобы она поддерживала не две архитектуры (x86+x86_64 и x86+Arm до сих пор поддерживались), а четыре (x86+x86_64+Aarch32+Aarch64).
И что-то мне подсказывает, что если бы система сборки представляла из себя не кучу костылей, подпёртых другими костылями, а что-то с более-менее осмысленным дизайном — то мы бы нашли себе других, более интересных, задач над которым можно «побуксовать».
Обидно, что я сильно опоздал к статье и мой комментарий вряд ли увидят, но вот что я хочу сказать. Даже прочитав где-то половину книжки по Haskell, а также еще с десяток статей о "введении в функциональное программирование" и "введение в теорию категорий", имея за плечами 6 лет коммерческого опыта С++ программирования и периодически пописывая на Rust, и даже после прочтения этой статьи — я до сих НИХРЕНА НЕ ПОНЯЛ. СОВСЕМ.
Объясню почему я нихрена не понял (помимо полного отсутствия профильного образования), ведь это собственно самое важное.
1) Монада. Меня уже откровенно достали и бесят статьи в который "смотри MayBe/Option — это монада, классно ведь? А вот еще список — тоже монада.". И я такой да, классно. А потом следом каждый автор абсолютно каждой статьи пишет: "вот ты молодец, а теперь представь, что функция принимающая на вход монаду, может работать с любой монадой".
Мне хочется пример монады "покруче" (можно взять одну сложную монаду и показать её общность с MayBe), чтобы понять собственно весь цимес и почему я должен восторгаться этим невероятным фактом, что теперь функция может принимать на вход любую монаду. Я хочу хотя бы огрызок кода с построчным сравнением монадического и не очень решения.
2) Аппликативый функтор. Вы пишете, что вот на map мы бы не смогли написать без "извлечения значений", а вот с этим замечательным функтором можем. НО КАК? Ну, т.е. это же противоестественно! У вас есть список значений, и другой список значений, один хрен функция должна залеть в элемент одного списка, в элемент второго списка, проверить есть ли в обоих Option значение, а потом создать результат — Option[ (username, password) ].
Да, это может быть лениво сделано и всё прочее, но один хрен ведь она внутри так и работает — извлекает значения, проверяет и продолжает работу.
3) Просто функтор. "Функция над функциями" — это самое непонятное что я в жизни слышал. Что это вообще значит? Функция принимающая на входу другую функцию? Ну и в чём тут магия? Зачем из этого городить ХОТЬ ЧТО-ТО похожее на умное название "теория категорий". Что такого невероятного позволяет нам функтор, кроме небольшой абстракции вида "вот тебе то, что внутри — делай из этого всё что хочешь, если можешь". Это классно, и реально неплохо, но всё еще не тянет на все те умные слова, что тут про функтор пишут в комментариях :) Я прям чувствую себя пятиклассником, которому говорят "корни из отрицательных чисел извлекать нельзя и параллельные прямые не пересекаются", а потом влетает в класс взрослый дядя в очках и начинает обзывать моего учителя идиотом, ведь вообще-то существуют комплексные числа и вообще парралельные пересекаются в какой-нибудь другой геометрии))) Это я про вот этот комментарий, например.
4) Эффект — это вообще огонь. Более непонятного описания для моего императивного мозга я так и не смог придумать. "Эффекты до конца остаются монадическими" — это вообще что-то за гранью) Раз 6 перечитал абзац и ничего не понял :)
Функция main возвращает именно такую супер-монаду IO (а не void как в «сях»), которая собрала в себя всю логику программы, и все эффекты ввода-вывода в консоль. Только внутренний boot-код, сгенерированный компилятором, запустит исполнение Эффекта (извлечение контейнера IO) – откроет ящик Пандоры, из которого выскочат все реальные строки, вычисленные тут же «на лету» цепочками различных преобразований.
Сейчас я из прочитанного, стал воспринимать функциональную программу как некое описание графа всех возможных вычислений. В узлах этого графа — типы данных, на ребрах преобразования (морфизмы). Всё что делает функциональная программа — "подключается" к источнику данных и ждёт пока внешняя система запросит данные (создаст эффект) из какого-либо узла этого графа после чего "строит" путь до "источника" и протаскивает данные через морфизмы. Чем это отличается от императивной программы — непонятно.
Я хочу хотя бы огрызок кода с построчным сравнением монадического и не очень решения.
Ну, этого все хотят. Я даже таскаю по форумам пример обычной императивной в стиле ООП программы — но никто не приводит пример этой же работающей программы с функторами и монадами. Максимум — предлагают передавать некие функции (в которых помещают ту логику что есть в императивной программе) как параметры в функцию, но почему это в данном случае круче чем ООП — не поясняют.
При этом — куда девать императивный код из методов объекта — вообще не отвечают.Не знают? Им неведомо что ООП — это методы и данные ВМЕСТЕ? Не знаю.
Про монады вообще молчат как… партизаны.
а потом влетает в класс взрослый дядя в очках и начинает обзывать моего учителя идиотом, ведь вообще-то существуют комплексные числа и вообще парралельные пересекаются в какой-нибудь другой геометрииЭто верная аналогия. Особенно меня впечатлило однажды, когда я нашёл геометрию (не Евклидову) где аксио́ма паралле́льности Евкли́да, или пя́тый постула́т — не принимается как данность (как аксиома), а выводится! — Математика иногда поражает. ;-)
Эффект — это вообще огонь.Понятие это очень сложное. Но его вынуждены понимать программисты использующие React.js
Как они его понимают? — Ну, на основании наверное только конкретных примеров — типа, если в функции обращаются в вводу или выводу, то есть эффект. Наверное, типа, того. Не более. Но это явно не вся суть эффекта. Иначе бы его было просто понять.
Сейчас я из прочитанного, стал воспринимать функциональную программу как некое описание графа всех возможных вычислений.Вполне похоже на то. Я думаю, ментально у многих. ;-)
Когда мне говорят — применяйте функции — это не проблема.
Когда мне говорят — не применяйте циклы for — это не проблема.
Когда мне говорят — не меняйте ничего, создавайте новое — это не проблема, но уже в реальности напрягает (если касается развесистых объектов).
Когда мне говорят — не используйте классы и this — это уже не проблема в React.js после изобретения хуков.
Но где монады? Где функторы? Где переписанная под них моя программа?
Я уже отмечал выше:
Вообще, книжка "Паттерны банды четырёх переписанные в функциональном стиле" была бы бестселлером, поди. Но никто не напишет. Почему?
1) некогда
2) незачем
3) некому
4) невозможно
Ответа нет. :-(
Я даже таскаю по форумам пример обычной императивной в стиле ООП программы — но никто не приводит пример этой же работающей программы с функторами и монадами.
Только вот в том сообщении (и в следующем по тому треду вашем сообщении) вообще ни слова про монады нет. Вы просили пример функциональной (и не ООП) реализации — я его там привёл.
Снова приведу кусок своего комментария оттуда:
Монада — это по сути всего лишь один из паттернов функционального программирования. Просить написать код на ФП «с монадами» — то же самое, что в ООП просить «с паттерном фабрика». Оба варианта возможны, но далеко не всегда являются самыми удобными.
Ну и про:
Вообще, книжка «Паттерны банды четырёх переписанные в функциональном стиле» была бы бестселлером, поди. Но никто не напишет. Почему?
1) некогда
2) незачем
3) некому
4) невозможно
Есть же книги про функциональные паттерны — там покрываются, в том числе (сюрприз-сюрприз!), монады и функторы.
Монада — это по сути всего лишь один из паттернов функционального программирования. Просить написать код на ФП «с монадами» — то же самое, что в ООП просить «с паттерном фабрика». Оба варианта возможны, но далеко не всегда являются самыми удобными.
Проблема в том, что увидев один раз фабрику, я сразу понял в чём собссно логика и теперь везде где есть фабрика — я её легко могу распознать, даже если на ней написано "я ромашка". С монадами не так. Я годами смотрю на код с монадами и мне кристально ясно, что делает этот код, но каждый раз если мне крупными буквами не напишут "ЭТО МОНАДА", я её не вижу. Точнее не понимаю, что я должен видеть и на что смотреть)
Если монада ненаблюдаема смертными, может быть её и нет вовсе)
do
a <- get_parameter_A
b = computeB(a)
c <- get_parameter_C
d = computeD(a, b, c)
return d
Этот код проводит какие-то (чистые) вычисления с поданными ему параметрами a, c. Откуда берутся параметры — вычислительному коду не важно, это решается при вызове.
Заданы конкретными значениями? Пожалуйста, берите монаду Identity.
Могут отсутствовать? Maybe.
Нужно вычислить для целого набора значений a и c? List. При этом лишних вычислений не будет, т.е. computeB выполнится столько раз, сколько значений параметра a, а не сколько пар (a, c).
Получаем значения из ввода пользователя? Берём IO.
Запрашиваем у сервера? Future.
Код вычислений при этом абсолютно не меняется. Здесь для удобства используется do-нотация, без неё всё то же самое конечно возможно.
Эффекты можно комбинировать, но тогда чуть посложнее будет.
Ну вот видите паттерн
Container<A> mycontainer = ...
Container<B> otherContainer = mycontainer.doSomething(a => {
Container<B> foo = a.DoSomthing();
return foo
});И понимаете, что монада.
Вы просили пример функциональной (и не ООП) реализации — я его там привёл.
Спасибо за пример. Не часто приводят хоть какой-то работающий пример.
P.S.
"Джек Франклин — разработчик Chrome Dev Tools — написал статью про важность простоты кода — «Keeping Code Simple».
Основная идея статьи. Число строк кода — это не очень адекватная метрика для оценки качества кода. Если одну задачу можно решить в несколько строк кода и если есть альтернативное решение в несколько раз больше, это не означает, что первый вариант лучше. Вполне возможно, что решение с меньшим числом строк будет менее читабельно и труднее в поддержке. Хороший код — это такой код, который прост в поддержке, лёгок в понимании и не требует больших сил для изменений."
И вот смотрю я на свой, вышеприведённый, код — он такой ясный (как слеза) и простой (как грабли) и зачем ему усложняться то?
"Нет ничего страшного в написании хитрого кода ради фана, но если с кодом работают другие программисты, то приоритет должен быть у простоты."
И вот смотрю я на свой, вышеприведённый, код — он такой ясный (как слеза) и простой (как грабли) и зачем ему усложняться то?
Мы точно про один и тот же ваш код говорим? В этом:
var getSallary = function (){
var sallary = this.sallary || 0;
if (this.consist) {
sallary = this.consist.reduce(function(sum, current) {
return sum + (current.getSallary? current.getSallary() : 0);
}, 0);
}
return sallary;
};
var getWeight = function (){
var weight = this.weight || 0;
if (this.consist) {
weight = this.consist.reduce(function(sum, current) {
return sum + (current.getWeight? current.getWeight() : 0);
}, 0);
}
return weight;
};
var getPower = function (){
var power = this.power || 0;
if (this.consist) {
power = this.consist.reduce(function(sum, current) {
return sum + (current.getPower? current.getPower() : 0);
}, 0);
}
return power;
};
var getNames = function (){
if (this.consist) {
this.consist.forEach(function(current) {
current.getNames();
});
} else if (this.sallary) {
console.log(' ' +this.name);
}
};явно стоит вынести обход дерева в функцию — тогда станет намного короче и понятнее, что происходит. Не говоря уже о функции getNames, которая на самом деле вовсе не возвращает имена а их печатает в консоль.
Мне хочется пример монады "покруче" (можно взять одну сложную монаду и показать её общность с MayBe)
Таски-обещания-футуры. Реактивные потоки (Observable). Ещё есть монада Identity, которая ничего не делает — с её помощью можно "выключать" лишние возможности.
Аппликативый функтор. Вы пишете, что вот на map мы бы не смогли написать без "извлечения значений", а вот с этим замечательным функтором можем. НО КАК? Ну, т.е. это же противоестественно! У вас есть список значений, и другой список значений, один хрен функция должна залеть в элемент одного списка
Два момента.
Нас не интересует что делает функция, нас интересует что делаем мы. Про инкапсуляцию и абстракцию слышали?
Если мы пишем обобщенный код, который работает с произвольными функторами — то у функции перед нами есть серьезное преимущество: она знает конкретный тип, а мы нет.
Просто функтор. "Функция над функциями" — это самое непонятное что я в жизни слышал. Что это вообще значит? Функция принимающая на входу другую функцию?
Это значит, что написана чушь. Видимо, потому и непонятно.
Функция, принимающая на вход другую функцию, называется функцией высшего порядка (High Order Function), и магии тут и правда немного. А функтор — это функция из типа в тип, т.е. шаблон (в понимании C++), обобщенный тип. Причём не любой, а обладающий конкретным свойством — возможностью определить для него функцию map.
Прежде всего — спасибо за ответ.
Таски-обещания-футуры. Реактивные потоки (Observable). Ещё есть монада Identity, которая ничего не делает — с её помощью можно "выключать" лишние возможности
Как я всё это понял:
Судя по примерам, монада — это просто способ организации последовательных вычислений в виде "цепочек". Если код выглядит как цепочка вызовов порождающая однотипные объекты — это монадично. Компилятору мы просто говорим "Возьми Х и сделай из этого Z используя цепочку преобзразований типа Т".
Что нас не интересует — как именно организованы эти преобразования, всё что мы знаем — когда выполнение T[X] закончится, на выходе будет X и у нас есть выбор — забрать X или передать это значение в другую функцию F, которая породит нам T[Z] из X, по завершению которой у нас на руках будет Z.
Нас не особо интересует ни то, что такое T, ни что такое X и Z. Есть только договоренность (концепт в С++20), что у T есть метод "bind" с конкретной сигнатурой. Вся логика по транформации из X в T[Z], где-то в другой (шаблонной) функции F, где-то там внутри себя знает что такое T на самом деле.
Тогдп в некотором смысле паттерн "Строитель" — это монада. Ведь:
Query query = QueryBuilder()
.addHeader("...")
.addBody("...")
.build();
В сущности можно переписать на цепочку (псеводкод)
do
builder <- makeBuilder(),
builderWithHeader <- addHeader(builder),
builderWithHeaderAndBody <- addBody(builderWithHeader),
query <- buildQuery(builderWithHeaderAndBody)Это не совсем "Строитель", это скорее Fluent syntax.
И да, это можно сделать монадой, такая монада называется State. Только вы как-то много стрелочек наставили, по-нормальному выглядеть оно будет вот так:
buildQuery do
addHeader ...
addBody ...Обратите внимание: то, что вы пытались обозначать стрелочками, на самом деле скрывается в самой монаде.
Но откуда у монад название вообще? Если монада — это просто способ организации вычислений? Для меня Option — это просто тип данных, а вот когда я пишу что-то вроде:
a()?.b()?.c()Это монада.
Монада — это семейство типов данных (оно же template, оно же обобщенный тип), используемое для организации вычислений. Уточнение: концепт семейства типов данных, каждое такое семейство имеет своё имя.
То, что вы приняли за монаду комментарием ранее — это "do-нотация", полезнейшая для монад вещь, но которая сама по себе не является ни монадой, ни даже чем-то обязательным для монады.
Что же до оператора ?. — то он разработан специально для чего-то Option-подобного, на произвольные монады не обобщается и никак с монадами не связан.
Есть у меня один знакомый паренек. Он начал обучаться программировать со Scala. Так вот он нихера не въахал, точно так же, как и я) В итоге свалил на Ruby, а потом уже вернулся к Scala.
С такими объяснениями, какие есть сейчас у ФП — оно обречено быть развлечением для избранных. Потому что если что-то нельзя объяснить в виде "вот это монада, а вот это не монада", то и как собственно её понять?)))
Начинать со Scala, конечно, умное решение. Я бы ещё понял haskell.
Если интересует что такое монада с точки зрения ЯП, то это легко выяснить. Для монад есть instance (type)класса Monad, куда уж проще?
Начинать со Scala, конечно, умное решение. Я бы ещё понял haskell.
А что плохого в Scala? У меня она первый кандидат, когда решу изучить таки "взрослое ФП", только не понял нужно ли предварительно Java изучать
Я не говорил, что скала плоха. Но это сложный язык. Начнем с того, что он мультипарадигменный, а не чисто ФП, как haskell. И многие возможности, нужные для ФП(те же type class) "эмулируются" с использованием других конструкций языка(неявных параметров в случае с type class).
Мне, например, после Java гораздо легче было учить hs чем scala. А уже с изучением hs стало понятно, зачем нужны все эти странные, на первый взгляд, конструкции в scala.
Вот этого комментария я ждал. Теперь я всё понял кажется. Спасибо.
Мы прератили его в Функтор, аппликатив и монаду.
А зачем? Ну вот как с паттернами пишут какую задачу паттерны решают, какие задачи они решают Не что это, не что можно с ними делать (те же паттерны пихают часто куда угодно не по месту), а зачем они нам вообще нужны в ФП?
Вон в соседнем топике https://habr.com/en/company/skillfactory/blog/508278/ доступно, по-моему, объяснено зачем берут ФП — чтобы не выбирать между производительностью, прежде всего на обходе коллекций, и простотой композиции (при условии что есть какая-то поддержка Optional и т. п. и ленивости).
Хотя продемонстрированные там подходы я без всякого ФП решал с помощью ООП, создавая парсеры декларативных конфигов различных workflow (в смысле как альтернативы BPMN). И даже без проверок типа if err != nil {return err} в начале каждой функции — это брал на себя движок, композитор
Монады можно и в ООП обычном использовать (и они обычно используются), просто они не так распространены — список/нуллябл-опшн/промис/иногда резалты вместо эксепшнов. А всякие ST/State/IO/… просто не используются, потому что люди грязно напрямую работают со всем этим. Конечно, потом изобретают фреймворки которые это под собой прячут: реакты, акки всякие, но в целом суть остается так же, а вместо специальных выделенных типов пишут километры документации, что можно делать, а чего не стоит.
Так резалт или промис — это монады? А списки же просто структура данных...
Монада — это всё, что имеет методы pure и flatMap определенной сигнатуры. У резалтов он есть (and_then/Then/...), у списков тоже есть (flatMap/FlatMap/SelectMany/...), у тасков есть (then/ContinueWith/...). Они все имеют сигнатуру
(T<A>, A -> T<B>) -> T<B>. Я тут подробно всё расписывал.
Самое важное забыли: для методов должны выполняться определённые свойства.
Честно пытался осилить статью, с почти нулевым знанием C#, паралельно делая свою реализацию на PHP, но где-то на аппликативных функторах сдался. Хотя бы потому что вот тут вы пишите "всё что имеет методы", а там в коде статические методы, то есть объект в классе которого статический метод map вроде как и не функтор, а функтор его класс.
А так на PHP стараясь руководствовать только текстом (без кода) вашей и ещё пары статей сделал что-то вроде.
/**
* @template T
*/
interface Functor
{
/**
* @template U
* @param callable(T): U $mapFunc
* @return self<U>
*/
public function map(callable $mapFunc): self;
}
/**
* @template T
* @template-implements Functor<T>
*/
interface Applicative extends Functor
{
/**
* @param Applicative<T> $applicative
* @return Applicative<T>
*/
public function apply(Applicative $applicative): self;
}
/**
* @template T
*/
class IdentityFunctor implements Functor
{
/**
* @var T $value
*/
private $value;
/**
* @param T $value
*/
protected function __construct($value)
{
$this->value = $value;
}
/**
* @return T
*/
public function get()
{
return $this->value;
}
public function map(callable $mapFunc): self
{
return new static($mapFunc($this->value));
}
}
/**
* @template T
* @template-extends IdentityFunctor<T>
*/
class IdentityApplicativeFunctors extends IdentityFunctor
{
/**
* @template TT
* @param TT $value
* @return self<TT>
*/
public static function pure($value): self {
return new self($value);
}
/**
* @param IdentityApplicativeFunctors<T> $f
* @return IdentityApplicativeFunctors<T>
*/
public function apply(IdentityApplicativeFunctors $f)
{
return $f->map($this->get());
}
}Что позволяет делать что-то вроде
$add = fn ($a) => fn ($b) => $a +$b;
$five = IdentityApplicativeFunctors::pure(5);
$ten = new IdentityApplicativeFunctors::pure(10);
$applicativeAdd = IdentityApplicativeFunctors::pure($add);
var_dump($applicativeAdd->apply($five)->apply($ten)->get() === 15); // true
Но понял, что пошло куда-то не туда...
то есть объект в классе которого статический метод map вроде как и не функтор, а функтор его класс
На самом деле, функтор — это семейство таких классов, с разными типами элементов "внутри". Но на PHP и Javascript разница не заметна.
Просто многие поколения разработчиков поломаны джавой, они думают, что функции это свойства объектов, как и реализация интефрейсов, тогда как это свойство типа.
Возьмем например тайпкласс Bounded из хаскелля. Это тайпкласс который задает две функции: MinValue и MaxValue. Какие типы в дотнете его реализуют? Ну, легко: int/double/decimal/DateTime/..., и так далее, любые типы, у которых задано минимально и максимальное значение. Ну и что что эти методы статические? То что в интерфейсах нельзя объявлять статические методы — это их недоработка, а не состояние объективной реальности. И как я в статье ссылался, в следующих версиях шарпа это планируют починить.
И если функтор ещё можно описать на обычных интерфейсах, там есть только инстансный map, то для аппликатива без статического pure — никуда.
То есть в PHP, где статические методы в интерфейсах давно можно описывать, апликативный функтор можно выразить через интерфейс типа
/**
* @template T
* @template-implements Functor<T>
*/
interface ApplicativeFunctor extends Functor
{
/**
* @template TT
* @param TT $value
* @return self<TT>
*/
public static function pure($value): self;
/**
* @param Applicative<T> $applicative
* @return Applicative<T>
*/
public function apply(Applicative $applicative): self;
}?
Похоже, но не совсем, потому что apply принимает не любой аппликатив, а только тот же самый, который реализует этот интерфейс. И кроме него, он принимает ещё функцию (A, B) => C. Причем this должен иметь форму self<A> а параметр $applicative: self<B>, а и pure возвращает не любой self, а параметризовыннй типаом $value. Без HKT нельзя написать self<A> или self<B> а только self, так что сильно ограничивает выразительную силу, вплоть до полной неюзабельности.
Ну, как я вижу из примеров, как раз self<B> написать можно. Только у apply надо параметры переставить местами (функция должна быть вторым), потому что наложить ограничение на this не так-то просто.
Получается как-то так:
/**
* @template T
* @template-implements Functor<T>
*/
interface ApplicativeFunctor extends Functor
{
/**
* @template TT
* @param TT $value
* @return self<TT>
*/
public static function pure($value): self;
/**
* @template U
* @param self<callable (T): U> $applicative
* @return self<S>
*/
public function applyOn(self $applicative): self;
}Только это всё равно работать не будет, потому что многие полезные на практике функторы типизируются не одним типом, а несколькими (и только по одному из типов-аргументов являются функторами).
Получается как-то так:
Спасибо. Где-то потерял момент, что аргумент совсем другого типа в контейнере
Только это всё равно работать не будет, потому что многие полезные на практике функторы типизируются не одним типом, а несколькими (и только по одному из типов-аргументов являются функторами).
Да мне бы понять, можно вообще без типизации.
Тут два синтаксиса типизации одновременно используется. Один для статической проверки сторонней тулзой (в док комментах), другой для рантайма, нативный, но без дженериков. Его убрать надо было, наверное, чтобы не смущать.
Да, вы правы, пригляделс внимательнее. Вроде, выше практически верно, нужно только дать соответствие между параметрами в applyOn:
/**
* @template T
* @template-implements Functor<T>
*/
interface ApplicativeFunctor extends Functor
{
/**
* @template TT
* @param TT $value
* @return self<TT>
*/
public static function pure($value);
/**
* @template U
* @param self<callable (T): U> $applicative
* @return self<U>
*/
public function applyOn($applicative);
}Так резалт или промис — это монады?Тут это уже много раз обсуждали. То, что вы наблюдаете, в «обычном программировании» это… «почти монады». Ну вот как со сложением, например. Есть законы арифметики, которые говорят, что если
x = y + 1, то, стало быть, и наоборот y = x - 1. И, как бы, иногда это полезно использовать.В потом вы берёте
double… и обнаруживаете, что это не так. И наступает печаль.Вот то же самое и с монадами: люди, которые про них не знают — часто их переизобретают. Вот только… они получаются «не совсем монадами».
Но это если глубоко копнуть, рассмотреть все хитрые краевые случаи. Но идеи — как раз примерно такие, да.
А зачем вы в сишарпе пишете class MySomething : ISomethingElse? Конечно же, чтобы вы могли использовать MySomething в контексте ISomethingElse. В частности, использовать с библиотеками которые умеют работать с ISomethingElse.
Мне хочется пример монады "покруче" (можно взять одну сложную монаду и показать её общность с MayBe), чтобы понять собственно весь цимес и почему я должен восторгаться этим невероятным фактом, что теперь функция может принимать на вход любую монаду. Я хочу хотя бы огрызок кода с построчным сравнением монадического и не очень решения.
Я писал статью на эту тему, понятнее вряд ли смогу объяснить, поэтому просто оставлю здесь. Если в двух словах, то монада — это интерфейс, который позволяет работать со значением внутри контейнера. Вот например реализация монады State на C#. А вот реализация IO на Rust.
2) Аппликативый функтор. Вы пишете, что вот на map мы бы не смогли написать без "извлечения значений", а вот с этим замечательным функтором можем. НО КАК? Ну, т.е. это же противоестественно! У вас есть список значений, и другой список значений, один хрен функция должна залеть в элемент одного списка, в элемент второго списка, проверить есть ли в обоих Option значение, а потом создать результат — Option[ (username, password) ].
Большинство полезных функторов являются аппликативами. Но навскидку функтор пары (,) не может быть аппликативом, потому что для него не получится определить pure.
3) Просто функтор. "Функция над функциями" — это самое непонятное что я в жизни слышал. Что это вообще значит?
Функтор — это просто интерфейс, который позволяет маппить MyContainer<A> в MyContainer<B>, если вам дали функцию A -> B. В плюсах эту роль выполняет функция transform, функтор же это интерфейс который позволяет такой трансформ определить. Если вы ещё не прочитали статью по ссылке выше — настоятельно рекомендую это сделать.
Эффект — это вообще огонь. Более непонятного описания для моего императивного мозга я так и не смог придумать.
Эффект — это всё, что не является результатом функции. Например, функция writeLine :: () была бы полностью бесполезной, она всегда возвращает юнит (или void в терминах С++), от которого пользы — никакой. Нас интересует эффект — в частности, вывод значения на экран.
Не советую делать никаких выводов из текста выше — только запутаетесь.
Функтор — это просто интерфейс, который позволяет маппить MyContainer<A> в MyContainer<B>, если вам дали функцию A -> B.
Вот есть что-то вроде (js)
class MyContainer
{
constructor(value) { this.value = value}
map(func) {
return new MyContainer(func(this.value))
}
}Это функтор? Ну и стандартный Array в js с методом map по сути тоже функтор?
Да, функтор. Array тоже функтор, да. Собственно, он ничем не отличается семантически от списка, про который известно, что он монада.
Кстати, ваш MyContainer имеет имя — это Id монада :)
Надо только проверить что закон функторов выполняется: obj.map(x => x) == obj.
Спасибо за подробный ответ. Умеешь заставить почувствовать себя тупым :) Думаю, пару дней у меня точно уйдет, чтобы раскурить этот комментарий :)
fun :: ToyMonad e s m => m (FunSig, FunDef)Ну вот, сразу видно, что энти ваши монадки только для игр и пригождаются, да чтобы радоваться
Как это написать не в монадическом стиле, я не знаю.
В мутабельном варианте и полностью в памяти — запросто. Просто делаем разделяемый указатель/индекс на следующий символ, и двигаем его при успешных операциях парсинга. При необходимости сохраняем этот указатель и в будущем возвращаем обратно. Разумеется, комбинаторы будут не библиотечные, а свои.
Если нужен потоковый парсинг с вводом-выводом — выходит чуть сложнее, тут нужен счётчик сохранений индекса, чтобы вовремя освобождать буфер.
Кстати, а как в Хаскеле делается потоковый парсер без "чита" с чтением файла в ленивый список?
Вариант с помощью conduit годится?
Почему функциональное программирование такое сложное