Эта тема не относится к IT напрямую, но все знают, что без нее никуда. К сожалению, далеко не у всех есть возможность изучать английский с преподавателями. Ну что ж, попробуем заняться этим дома и с максимальной отдачей!

dk @1000tour
Пользователь
17 простых советов для повышения продуктивности
3 min
Эти советы — не очередная компиляция из книг и блогов, посвященных продуктивности. Каждый совет основан на моём личном опыте. На каждый совет я мог бы дать гарантию, если бы гарантия на советы была возможна в принципе.
Вступление окончено, переходим к советам!
Вступление окончено, переходим к советам!
Дневник репатриантов часть 2: Как привлечь инвестиции в стартап, не имея связей и опыта
6 min
В прошлом посте мы писали о том, как Островок.ru привлёк инвестиции размером 1 млн долларов от лучших инвесторов всего за 6 недель, имея только идею.
Мы получили очень много положительных отзывов на тот пост. Но в нём был существенный недостаток: мы описывали процесс с точки зрения нашего предыдущего опыта и связей. Большинство из этих рекомендаций неприменимы к вопросу о том, как начать в России свой бизнес, не имея связей и опыта.
Мы очень хотим помогать развитию локальной предпринимательской экосистемы и этот пост — попытка рассказать о том, как запускать проекты не имея ничего, кроме желания.

Мы получили очень много положительных отзывов на тот пост. Но в нём был существенный недостаток: мы описывали процесс с точки зрения нашего предыдущего опыта и связей. Большинство из этих рекомендаций неприменимы к вопросу о том, как начать в России свой бизнес, не имея связей и опыта.
Мы очень хотим помогать развитию локальной предпринимательской экосистемы и этот пост — попытка рассказать о том, как запускать проекты не имея ничего, кроме желания.
Нормализация отношений. Первая и вторая нормальные формы
6 min
Предисловие
Нормализация отношений (таблиц) — одна из основополагающих частей теории реляционных баз данных. Нормализация имеет своей целью избавиться от избыточности в отношениях и модифицировать их структуру таким образом, чтобы процесс работы с ними не был обременён различными посторонними сложностями. При игнорировании такого подхода эффективность проектирования стремительно снижается, что вкупе с прочими подобными вольностями может привести к критическим последствиям.
Любому специалисту, по роду своей деятельности так или иначе связанному с проектированием реляционных баз данных, полезно понимать и уметь осуществить нормализацию отношений. И этим постом хотелось бы начать небольшую серию публикаций, посвящённых нормальным формам, имеющую целью дать тем читателям Хабрахабра, которые по различным обстоятельствам ещё не освоили эту тему, возможность легко заполнить этот пробел в знаниях.
Статья не имеет своей целью подробное и точное изложение принципов нормализациии, поскольку это, очевидно, невозможно в рамках блога в силу больших объёмов информации, необходимых для публикации при таком подходе. Кроме этого, для такой цели существует большое количество литературы, написанной прекрасными специалистами. Моя же задача, как я считаю, заключается в том, чтобы популярно продемонстрировать и объяснить основные принципы.
Организация памяти
7 min
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Свой инструмент нужно знать в лицо: обзор наиболее часто используемых структур данных
8 min
Некоторое время назад я сходил на собеседование в одну довольно большую и уважаемую компанию. Собеседование прошло хорошо и понравилось как мне, так и, надеюсь, людям его проводившим. Но на следующий день, в процессе разбора полетов, я обнаружил, что в ходе собеседования ответ на как минимум один вопрос был неверен.
Вопрос: Почему поиск в python dict на больших объемах данных быстрее чем итерация по индексированному массиву?
Ответ: В dict хранятся хэши от ключей. Каждый раз, когда мы ищем в dict значение по ключу, мы сначала вычисляем его хэш, а потом (внезапно), выполняем бинарный поиск. Таким образом, сложность составляет O(lg(N))!
На самом деле никакого бинарного поиска тут нет. И сложность алгоритма не O(lg(N)), а Amort. O(1) — так как в основе dict питона лежит структура под названием Hash Table.
Причиной неверного ответа было то, что я не удосужился досконально изучить те структуры, которые лежат в основе работы с коллекциями моего любимого языка. Правда, по результатам опроса нескольких знакомых разработчиков, оказалось что это не только моя проблема, очень многие вообще не задумываются, как работают коллекции в их любимых ЯП. А ведь используем мы их каждый день и не по разу. Так родилась идея этой статьи.
Праздничный биатлон
3 min
 С днем программиста, коллеги!
С днем программиста, коллеги!Предлагаю в честь праздника поразмять мозги и поучаствовать в биатлоне.
Виды спорта: алгоритмы, SQL. Для каждого из них будет две задачки: попроще и посложнее.
В качестве награды за усилия всем участникам гарантируется улучшение кровообращения в левом полушарии головного мозга (:
Алгоритмы. Задача №1, разминочная
Напишите код, который находит количество подчисел числа n, на которые это число делится без остатка.
Для числа n, подчисло — это такое число, запись которого является подстрокой записи числа n. К примеру, если n равняется 1938, то его подчислами будут являться: 1, 9, 3, 8, 19, 93, 38, 193 и 938. Без остатка 1938 делится на четыре из этих подчисел: 1, 3, 19 и 38. Соответственно, результатом работы программы должно быть число 4.
Если подчисла повторяются, каждое из них считается. Например, 101 делится без остатка на 1, 1 и 01, значит, ответ — 3.
Так как задача несложная, в решениях ценится краткость или нестандартный подход.
Преждевременное масштабирование — главная причина гибели стартапов?
2 min
Компания Startup Genome опубликовала приложение к майскому аналитическому отчёту по стартапам. Теперь собрана информация уже по 3200+ компаниям и подробно рассматривается главная причина, по которой стартапы разваливаются.
Изучив опыт тысяч стартапов, Startup Genome делает вывод: 70% неудач объясняются преждевременным масштабированием.
Изучив опыт тысяч стартапов, Startup Genome делает вывод: 70% неудач объясняются преждевременным масштабированием.
Монады с точки зрения теории категорий
9 min
Translation
Введение
Кажется, монады в программировании стали загадкой века. И для этого есть две причины:- недостаточное знание теории категорий;
- многие авторы стараюстся не упоминать категории вообще.
Мы начнём с простого введения в категории и функторы, затем дадим определение монады, приведём простые примеры монад в категориях и в конце приведём монадическую терминологию используемую в языках программирования.
Я уверен, что монады с точки зрения категорий почти элементарны.
Содержание
Конкурентный доступ к реляционным базам данных
13 min
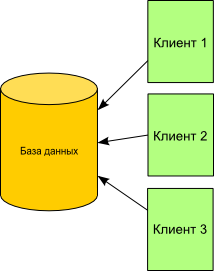 Вопросы параллелизма в компьютерных вычислениях очень сложны! Причинами большой сложности являются огромное количество деталей, которые нужно учитывать при разработке параллельных программ. В программирование и без того существует большое количество деталей, которые создают почву для ошибок, параллелизм же, добавляет ещё.
Вопросы параллелизма в компьютерных вычислениях очень сложны! Причинами большой сложности являются огромное количество деталей, которые нужно учитывать при разработке параллельных программ. В программирование и без того существует большое количество деталей, которые создают почву для ошибок, параллелизм же, добавляет ещё.Вопросы конкурентного доступа к реляционным базам данных встают практически перед любыми разработчиками прикладного программного обеспечения и не только перед ними. Результатом такой востребованности этой области является наличие большого количества созданных архитектурных паттернов. Это позволяет успешно справляться с большой сложностью разработки таких программ. Ниже пойдёт речь о таких рецептах, а также механизмах на которых базируется их реализация. Повествование будет иллюстрироваться примерами кода на Java, но большинство материала не привязано к языку. Цель статьи — описать проблемы конкурентного доступа к реляционным базам данных, в качестве введения в предмет, а не полноценного охвата темы.
IPO for dummies. Часть I: акции, мажоритарии, контроль над компанией
5 min
Во время недавнего обсуждения IPO Яндекса в комментариях прошла дискуссия на тему того, как торгуются акции на бирже, как проходит IPO, кто и какую от него получает пользу. По совету других участников обсуждения выношу в отдельную тему — а точнее, в серию тем — небольшой рассказ, который был рассредоточен по нескольким комментариям. Если вы тогда внимательно следили за темой, основная часть рассказа вам уже известна, но тем не менее… Если нет, вы наверняка найдете что-то интересное.
Disclaimer: эта и дальнейшие статьи серии написаны двумя хабраобитателями: honeyman — программистом стартапов, в свободное время экспериментирующим с торговлей на бирже и созданием аналитического софта для этого, в сотрудничестве с kaichik — журналистом и главредом автомобильных проектов. Если вы в предыдущем предложении не заметили слов «финансист», «лицензированные консультативные экономические услуги» и «богатый опыт» — то наверное, это потому, что их там не может быть.
Итак, часть I: акции, мажоритарии, контроль над компанией.
Что такое акции, и для чего они нужны?
Disclaimer: эта и дальнейшие статьи серии написаны двумя хабраобитателями: honeyman — программистом стартапов, в свободное время экспериментирующим с торговлей на бирже и созданием аналитического софта для этого, в сотрудничестве с kaichik — журналистом и главредом автомобильных проектов. Если вы в предыдущем предложении не заметили слов «финансист», «лицензированные консультативные экономические услуги» и «богатый опыт» — то наверное, это потому, что их там не может быть.
- Часть I: акции, мажоритарии, контроль над компанией.
- Часть II: стоимость акций, биржа, самый лучший способ торговать картошкой, и кого же можно встретить на
рынкебирже. - Часть III: процесс IPO, его польза для компании, основателей и владельцев, а также почему у руководства компании при открытии торгов такой замученный вид.
- Часть IV: влияние IPO на доход от адулт-партнёрок.
- Часть V: жизнь после IPO.
- Часть VI: сложности выбора — два Lamborghini Gallardo или один Aventador?
- Часть VII: про инсайд.
- Часть VIII: о мотивации.
Итак, часть I: акции, мажоритарии, контроль над компанией.
Что такое акции, и для чего они нужны?
Взаимодействие звеньев и их изоляция. Часть 2
4 min
Translation
Продолжение статьи «Взаимодействие звеньев и их изоляция.» часть 1
Хочу извиниться перед общественностью за то, что разбил статью на две части. Но в последнее время большие тексты перестали приниматься Хабром. Если кто-то подскажет как с этой напастью справиться: буду благодарен.
Хочу извиниться перед общественностью за то, что разбил статью на две части. Но в последнее время большие тексты перестали приниматься Хабром. Если кто-то подскажет как с этой напастью справиться: буду благодарен.
Архитектура и платформа проекта Одноклассники
10 min
Архитектура и платформа проекта Одноклассники
В этом посте расскажем о накопленном за 5 лет опыте по поддержанию высоконагруженного проекта. Надеемся, что коллегам-разработчикам будет интересно узнать, что и как мы делаем, какие проблемы и трудности у нас возникают и как мы справляемся с ними.
B-tree
6 min
Введение
Деревья представляют собой структуры данных, в которых реализованы операции над динамическими множествами. Из таких операций хотелось бы выделить — поиск элемента, поиск минимального (максимального) элемента, вставка, удаление, переход к родителю, переход к ребенку. Таким образом, дерево может использоваться и как обыкновенный словарь, и как очередь с приоритетами.
Основные операции в деревьях выполняются за время пропорциональное его высоте. Сбалансированные деревья минимизируют свою высоту (к примеру, высота бинарного сбалансированного дерева с n узлами равна log n). Большинство знакомо с такими сбалансированными деревьями, как «красно-черное дерево», «AVL-дерево», «Декартово дерево», поэтому не будем углубляться.
В чем же проблема этих стандартных деревьев поиска? Рассмотрим огромную базу данных, представленную в виде одного из упомянутых деревьев. Очевидно, что мы не можем хранить всё это дерево в оперативной памяти => в ней храним лишь часть информации, остальное же хранится на стороннем носителе (допустим, на жестком диске, скорость доступа к которому гораздо медленнее). Такие деревья как красно-черное или Декартово будут требовать от нас log n обращений к стороннему носителю. При больших n это очень много. Как раз эту проблему и призваны решить B-деревья!
B-деревья также представляют собой сбалансированные деревья, поэтому время выполнения стандартных операций в них пропорционально высоте. Но, в отличие от остальных деревьев, они созданы специально для эффективной работы с дисковой памятью (в предыдущем примере – сторонним носителем), а точнее — они минимизируют обращения типа ввода-вывода.
Как работают алгоритмы сортировки
1 min
Иногда для понимания того, как работает та или иная вещь, лучше один раз увидеть, чем сто раз услышать.
Замечательный сайт www.sorting-algorithms.com позволяет увидеть, как сортируются данные разными алгоритмами. Вы сможете посмотреть анимацию в зависимости от алгоритма, исходных данных.

Все это бегает и сортируется прямо на ваших глазах!
Работает на Google App Engine, видимо, поэтому и лежит от посетителей с «Хабра».
Замечательный сайт www.sorting-algorithms.com позволяет увидеть, как сортируются данные разными алгоритмами. Вы сможете посмотреть анимацию в зависимости от алгоритма, исходных данных.
Все это бегает и сортируется прямо на ваших глазах!
Работает на Google App Engine, видимо, поэтому и лежит от посетителей с «Хабра».
Декартово дерево: Часть 1. Описание, операции, применения
15 min
Оглавление (на данный момент)
Часть 1. Описание, операции, применения.
Часть 2. Ценная информация в дереве и множественные операции с ней.
Часть 3. Декартово дерево по неявному ключу.
To be continued...
Декартово дерево (cartesian tree, treap) — красивая и легко реализующаяся структура данных, которая с минимальными усилиями позволит вам производить многие скоростные операции над массивами ваших данных. Что характерно, на Хабрахабре единственное его упоминание я нашел в обзорном посте многоуважаемого winger, но тогда продолжение тому циклу так и не последовало. Обидно, кстати.
Я постараюсь покрыть все, что мне известно по теме — несмотря на то, что известно мне сравнительно не так уж много, материала вполне хватит поста на два, а то и на три. Все алгоритмы иллюстрируются исходниками на C# (а так как я любитель функционального программирования, то где-нибудь в послесловии речь зайдет и о F# — но это читать не обязательно :). Итак, приступим.
Введение
В качестве введения рекомендую прочесть пост про двоичные деревья поиска того же winger, поскольку без понимания того, что такое дерево, дерево поиска, а так же без знания оценок сложности алгоритма многое из материала данной статьи останется для вас китайской грамотой. Обидно, правда?
Следующий пункт нашей обязательной программы — куча (heap). Думаю, также многим известная структура данных, однако краткий обзор я все же приведу.
Представьте себе двоичное дерево с какими-то данными (ключами) в вершинах. И для каждой вершины мы в обязательном порядке требуем следующее: ее ключ строго больше, чем ключи ее непосредственных сыновей. Вот небольшой пример корректной кучи:
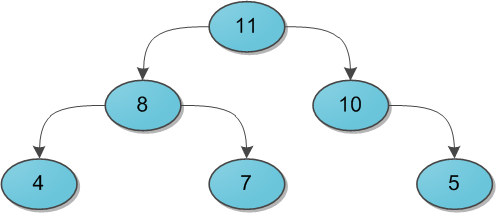
На заметку сразу скажу, что совершенно не обязательно думать про кучу исключительно как структуру, у которой родитель больше, чем его потомки. Никто не запрещает взять противоположный вариант и считать, что родитель меньше потомков — главное, выберите что-то одно для всего дерева. Для нужд этой статьи гораздо удобнее будет использовать вариант со знаком «больше».
Сейчас за кадром остается вопрос, каким образом в кучу можно добавлять и удалять из нее элементы. Во-первых, эти алгоритмы требуют отдельного места на осмотр, а во-вторых, нам они все равно не понадобятся.
Управление зависимостями в коде
1 min
Я рассмотрел, как эволюционировал подход к управлению зависимостями в коде. Какие проблемы возникали на каждом этапе и как эти проблемы решались. Возможно на каком-то этапе вы узнаете свой проект и поймете куда двигаться дальше.
Основные темы:
Исходники проекта
Основные темы:
- Design for testability
- Принцип инверсии зависимости
- Пассивная и активная инжекции зависимостей
- Принцип работы IoC-контейнера
- Composition versus Inheritance
- Convention over Configuration
Исходники проекта