Прочитав замечательную статью от @dalerank, я подумал, а чем собственно мы хуже: моя любимая индустрия тоже полна мифов и разочарований, особенно учитывая недавние "прорывы в AI" и хайп вокруг больших языковых моделей по типу ChatGPT.
Создается ощущение, что теперь каждая компания считает, что у ей непременно нужно прикрутить волшебную вундер-вафлю на машинном обучении к каждому своему продукту, добавить AI в рекламную кампанию, и дела пойдут в гору. Шутка ли, этот ваш пресловутый AI теперь даже в холодильниках есть.
Ну а если на рынке растет спрос, значит должно расти и предложение, в следствие чего я вижу все больше людей, которые приходят к нам в болото с горящими глазами и готовностью перевернуть этот мир, а в итоге разбиваются о скалу реальности.
Нет, скорее всего вы не будете создавать state of the art (SOTA) системы, которые будут рисовать, искать информацию и писать код лучше, чем эти бесполезные кожаные мешки. А даже если будете - это будет только 20% вашей работы. Так ли это грустно? - я постараюсь рассказать под катом.





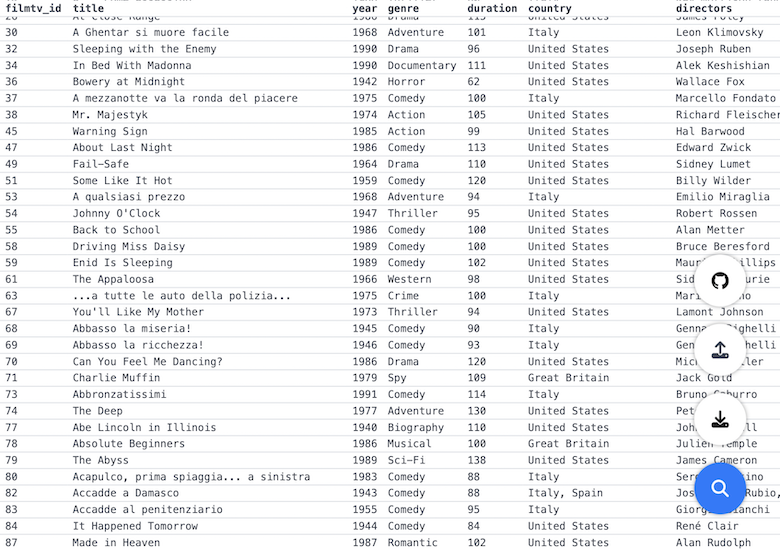







 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест 



