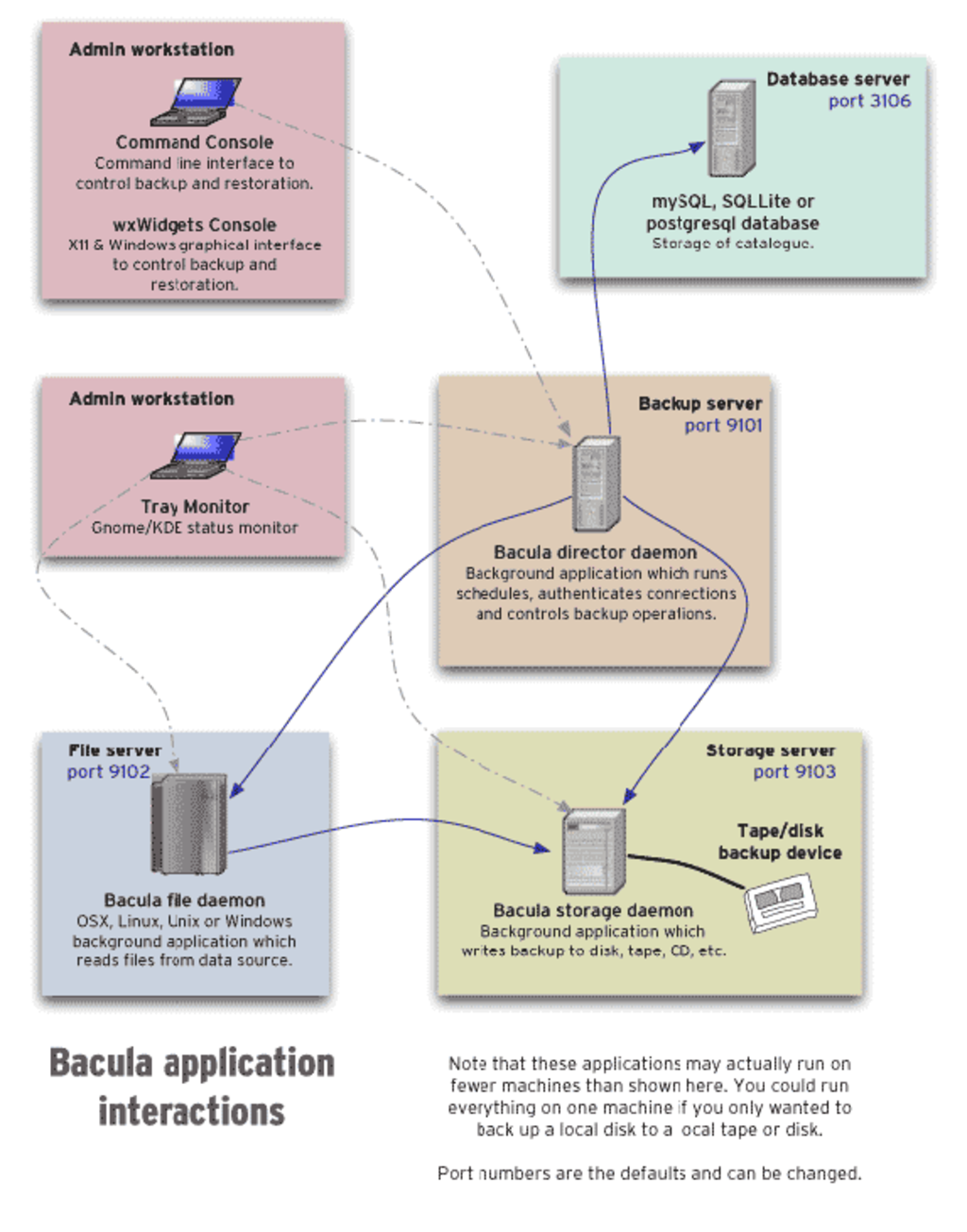
Сегодня я расскажу на абстрактном примере как правильно создать *.deb пакет для Ubuntu/Debian. Пакет мы будем делать бинарный. Пакеты, компилирующие бинарники из исходников здесь не рассматриваются: осилив изложенные ниже знания, в дальнейшем по готовым примерам можно понять суть и действовать по аналогии :)
В статье не будет никакой лишней возни «вручную»: формат пакета эволюционировал в достаточно простую, а главное — логичную структуру, и всё делается буквально на коленке, с применением пары специализированных утилит.
В качестве бонуса в конце статьи будет пример быстрого создания собственного локального репозитория: установка пакетов из репозитория позволяет автоматически отслеживать зависимости, и конечно же! — устанавливать всё одной консольной командой на нескольких машинах :)
Для тех, кто не хочет вдаваться в мощную систему установки софта в Linux, рекомендую посетить сайт проги CheckInstall: она автоматически создаёт deb-пакет из команды «make install» ;) А мы вместе с любопытными —
В статье не будет никакой лишней возни «вручную»: формат пакета эволюционировал в достаточно простую, а главное — логичную структуру, и всё делается буквально на коленке, с применением пары специализированных утилит.
В качестве бонуса в конце статьи будет пример быстрого создания собственного локального репозитория: установка пакетов из репозитория позволяет автоматически отслеживать зависимости, и конечно же! — устанавливать всё одной консольной командой на нескольких машинах :)
Для тех, кто не хочет вдаваться в мощную систему установки софта в Linux, рекомендую посетить сайт проги CheckInstall: она автоматически создаёт deb-пакет из команды «make install» ;) А мы вместе с любопытными —
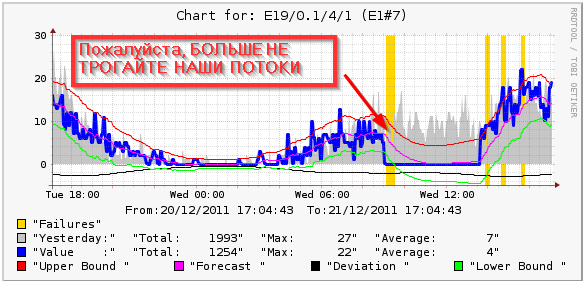
 В связи с кризисным состоянием рынка жестких дисков все чаще стал задумываться, что сейчас самое время купить диск объемом 3Тб. Волей случая мой выбор пал на модель ST3000DM001. Стоимость этого чуда получилась немаленькая, но я заранее для себя решил, что буду гнаться за объемом, закрыв глаза на цену.
В связи с кризисным состоянием рынка жестких дисков все чаще стал задумываться, что сейчас самое время купить диск объемом 3Тб. Волей случая мой выбор пал на модель ST3000DM001. Стоимость этого чуда получилась немаленькая, но я заранее для себя решил, что буду гнаться за объемом, закрыв глаза на цену.




 Ваш сайт обслуживается Apache Server. (Это условие выполнить нетрудно: сейчас Apache — один из наиболее популярных вебосерверов.)
Ваш сайт обслуживается Apache Server. (Это условие выполнить нетрудно: сейчас Apache — один из наиболее популярных вебосерверов.)