Сегодня мы открываем доступ к четвёртому поколению наших больших языковых моделей: более мощная YandexGPT 4 Pro и облегчённая YandexGPT 4 Lite уже доступны через API в Yandex Cloud. Постепенно пользователям платформы станут доступны все их возможности. А первым сервисом Яндекса, где появится YandexGPT 4, станет Алиса с опцией «Про».
Новое семейство моделей умеет обрабатывать более сложные запросы, работать с расширенным контекстом, поддерживает скрытые рассуждения и вызов функций для работы с внешними инструментами. Нашей команде удалось значительно улучшить качество ответов: YandexGPT 4 Pro в 70% случаев отвечает лучше своей прошлой версии, а YandexGPT 4 Lite в среднем отвечает не хуже, чем самая мощная модель предыдущего поколения.
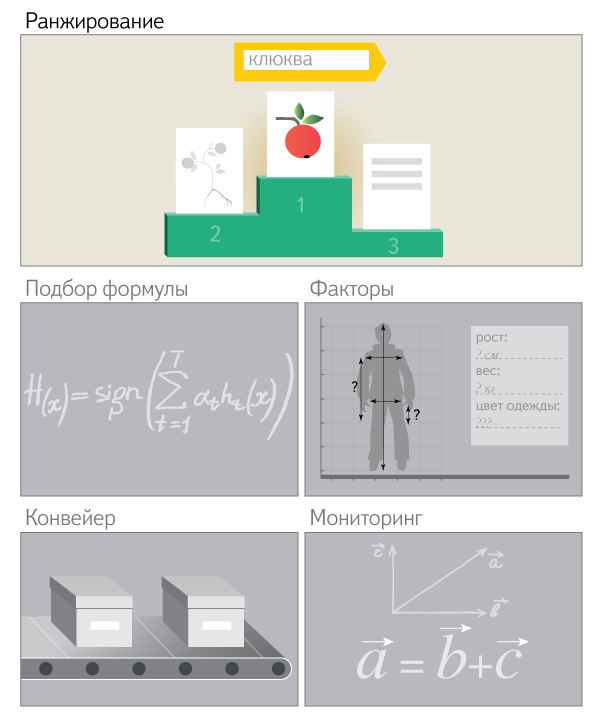
Вместе с Андреем Бутом @andbout, руководителем команды YandexGPT Alignment, кратко расскажем, что мы сделали для улучшения ответов и решения более сложных запросов, покажем результаты замеров качества и сравнения с другими моделями.