Начало нового проекта как правило сопровождается решением массы организационных вопросов: как будут взаимодействовать участники проекта, где будут храниться документы и как будет построено их согласование, как будут ставить задачи и выдавать поручения… В каждой компании, у каждого руководителя проектов, уже есть заготовки и предпочтения. Но всегда полезно посмотреть, как это делают другие. Поэтому предлагаю познакомиться с примером из практики, который вышел весьма удачным.

@Anna1407read-only
Пользователь
Оружие осторожного инвестора: считаем справедливую стоимость инвестиционных облигаций
6 мин
Привет, Хабр! Сегодня мы хотим поднять довольно нестандартную для блога тема — инвестиционные облигации. Почему мы решили об этом написать? Тема структурных финансовых продуктов, к которым относятся инвестиционные облигации, в последнее время становится все популярнее, а понятной информации о том, что это и как работает такой инструмент, крайне мало. Заинтересовались? Добро пожаловать под кат.

Java-сериализация: максимум скорости без жёсткой структуры данных
12 мин
Наша команда в Сбербанке занимается разработкой сервиса сессионных данных, который организует взаимообмен единым Java-контекстом сессии между распределёнными приложениями. Наш сервис крайне нуждается в очень быстрой сериализации Java-объектов, поскольку это часть нашей mission critical задачи. Изначально нам на ум приходили: Google Protocol Buffers, Apache Thrift, Apache Avro, CBOR и др. Первая тройка из перечисленных библиотек требует для сериализации объектов описания схемы их данных. CBOR такой низкоуровневый, что умеет сериализовывать только скалярные значения и их наборы. Нам же была нужна библиотека Java-сериализации, «не задающая лишних вопросов» и не заставляющая вручную разбирать сериализуемые объекты «на атомы». Мы хотели сериализовывать произвольные Java-объекты, не зная о них практически ничего, и хотели делать это максимально быстро. Поэтому мы устроили соревнование для имеющихся Open Source решений задачи Java-сериализации.
Sber.DS — платформа, которая позволяет создавать и внедрять модели даже без кода
5 мин
Идеи и встречи о том, какие ещё процессы можно автоматизировать, возникают в бизнесе разного масштаба ежедневно. Но помимо того, что много времени может уходить на создание модели, нужно потратить его на её оценку и проверку того, что получаемый результат не является случайным. После внедрения любую модель необходимо поставить на мониторинг и периодически проверять.
И это всё этапы, которые нужно пройти в любой компании, не зависимо от её размера. Если мы говорим о масштабе и legacy Сбербанка, количество тонких настроек возрастает в разы. К концу 2019 года в Сбере использовалось уже более 2000 моделей. Недостаточно просто разработать модель, необходимо интегрироваться с промышленными системами, разработать витрины данных для построения моделей, обеспечить контроль её работы на кластере.
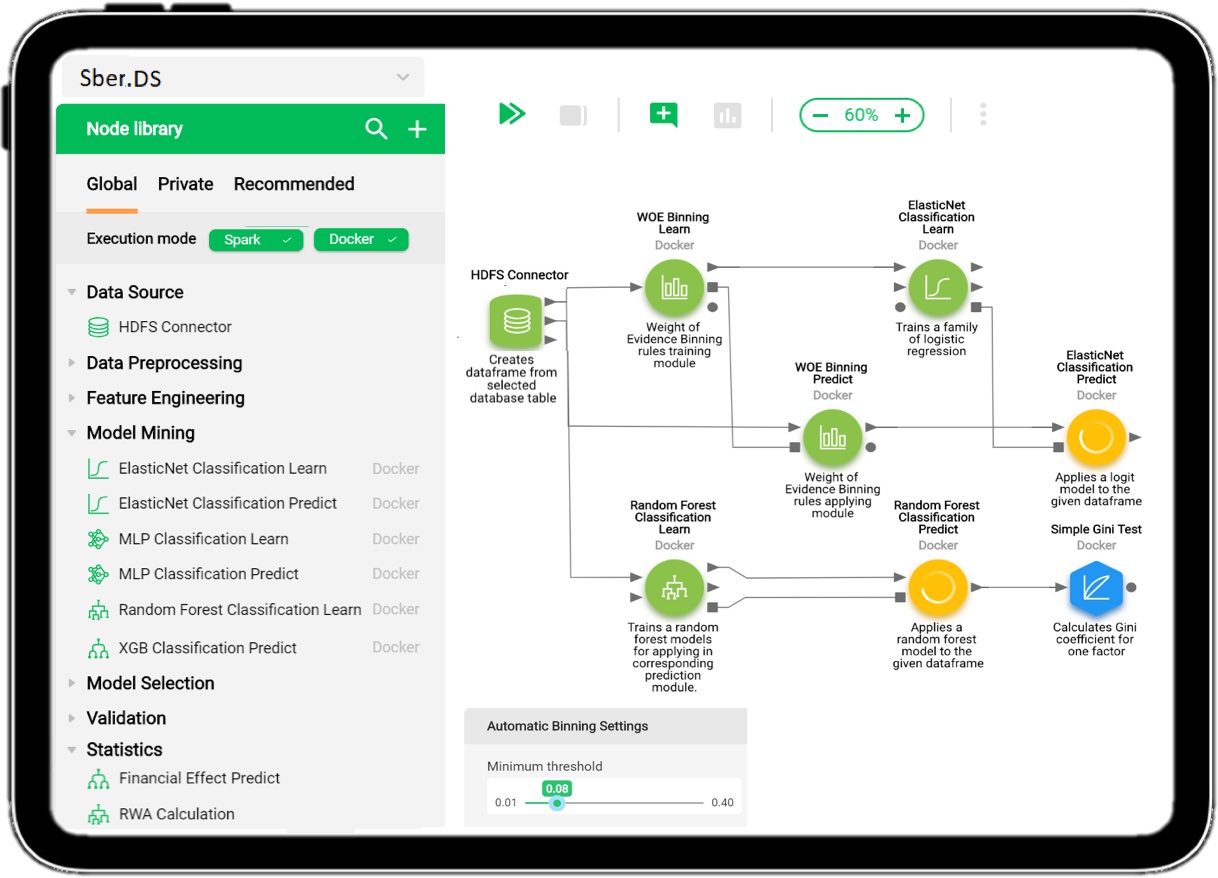
Наша команда разрабатывает платформу Sber.DS. Она позволяет решать задачи машинного обучения, ускоряет процесс проверки гипотез, в принципе упрощает процесс разработки и валидации моделей, а также контролирует результат работы модели в ПРОМ.
Чтобы не обмануть ваших ожиданий, хочу заранее сказать, что этот пост — вводный, и под катом для начала рассказано о том, что в принципе под капотом платформы Sber.DS. Историю о жизненном цикле модели от создания до внедрения мы расскажем отдельно.
Когда у вас сберовские масштабы. Использование Ab Initio при работе с Hive и GreenPlum
12 мин
Некоторое время назад перед нами встал вопрос выбора ETL-средства для работы с BigData. Ранее использовавшееся решение Informatica BDM не устраивало нас из-за ограниченной функциональности. Её использование свелось к фреймворку по запуску команд spark-submit. На рынке имелось не так много аналогов, в принципе способных работать с тем объёмом данных, с которым мы имеем дело каждый день. В итоге мы выбрали Ab Initio. В ходе пилотных демонстраций продукт показал очень высокую скорость обработки данных. Информации об Ab Initio на русском языке почти нет, поэтому мы решили рассказать о своём опыте на Хабре.
Ab Initio обладает множеством классических и необычных трансформаций, код которых может быть расширен с помощью собственного языка PDL. Для мелкого бизнеса такой мощный инструмент, вероятно, будет избыточным, и большинство его возможностей могут оказаться дорогими и невостребованными. Но если ваши масштабы приближаются к сберовским, то вам Ab Initio может быть интересен.
Он помогает бизнесу глобально копить знания и развивать экосистему, а разработчику — прокачивать свои навыки в ETL, подтягивать знания в shell, предоставляет возможность освоения языка PDL, даёт визуальную картину процессов загрузки, упрощает разработку благодаря обилию функциональных компонентов.
В посте я расскажу о возможностях Ab Initio и приведу сравнительные характеристики по его работе с Hive и GreenPlum.
Ab Initio обладает множеством классических и необычных трансформаций, код которых может быть расширен с помощью собственного языка PDL. Для мелкого бизнеса такой мощный инструмент, вероятно, будет избыточным, и большинство его возможностей могут оказаться дорогими и невостребованными. Но если ваши масштабы приближаются к сберовским, то вам Ab Initio может быть интересен.
Он помогает бизнесу глобально копить знания и развивать экосистему, а разработчику — прокачивать свои навыки в ETL, подтягивать знания в shell, предоставляет возможность освоения языка PDL, даёт визуальную картину процессов загрузки, упрощает разработку благодаря обилию функциональных компонентов.
В посте я расскажу о возможностях Ab Initio и приведу сравнительные характеристики по его работе с Hive и GreenPlum.
- Описание фреймворка MDW и работ по его донастройке под GreenPlum
- Сравнительные характеристики производительности Ab Initio по работе с Hive и GreenPlum
- Работа Ab Initio с GreenPlum в режиме Near Real Time
10 приёмов работы с Oracle
26 мин
В Сбере есть несколько практик Oracle, которые могут оказаться вам полезны. Думаю, часть вам знакома, но мы используем для загрузки не только ETL-средства, но и хранимые процедуры Oracle. На Oracle PL/SQL реализованы наиболее сложные алгоритмы загрузки данных в хранилища, где требуется «прочувствовать каждый байт».
- Автоматическое журналирование компиляций
- Как быть, если хочется сделать вьюшку с параметрами
- Использование динамической статистики в запросах
- Как сохранить план запроса при вставке данных через database link
- Запуск процедур в параллельных сессиях
- Протягивание остатков
- Объединение нескольких историй в одну
- Нормалайзер
- Визуализация в формате SVG
- Приложение поиска по метаданным Oracle
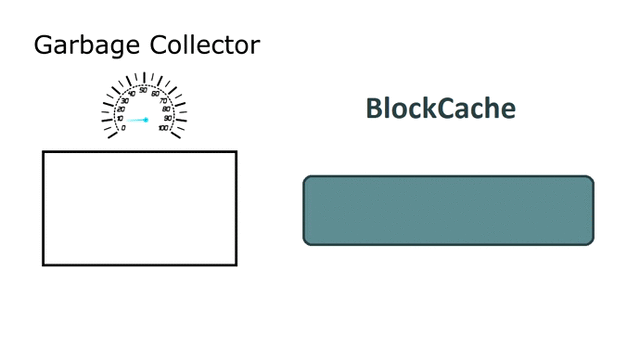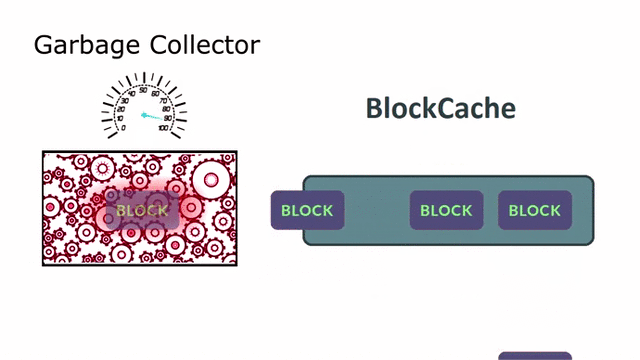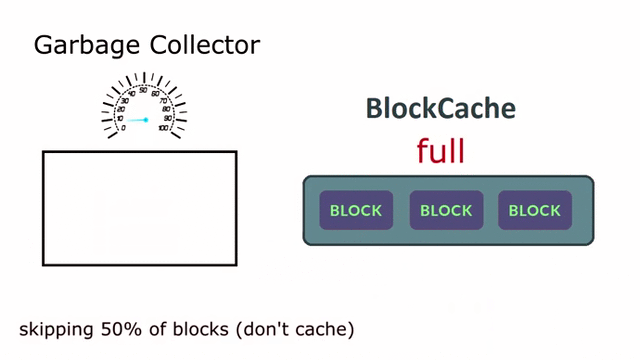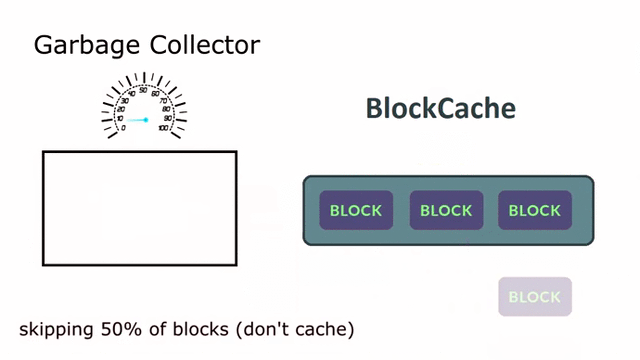
Как увеличить скорость чтения из HBase до 3 раз и с HDFS до 5 раз
19 мин
Высокая производительность — одно из ключевых требований при работе с большими данными. Мы в управлении загрузки данных в Сбере занимаемся прокачкой практически всех транзакций в наше Облако Данных на базе Hadoop и поэтому имеем дело с действительно большими потоками информации. Естественно, что мы все время ищем способы повысить производительность, и теперь хотим рассказать, как удалось пропатчить RegionServer HBase и HDFS-клиент, благодаря чему удалось значительно увеличить скорость операции чтения.
Что, если бы мысли могли унести нас к звездам?
Мы со Сбером подготовили тест специально ко Дню разработчика и Дню тестировщика. В нашей альтернативной реальности человечество ищет новые планеты для освоения, а топливо для кораблей — это продукт интеллектуальной деятельности. Чтобы топлива для исследований хватило, реши несколько задач под катом. Каждый правильный ответ даёт + 1 литр топлива.
В космос отправляются две команды: конструкторов (или разработчиков) и испытателей (то есть тестировщиков). Выбирай свою — и отправляйся на поиск новых планет.
Итак, миссия начинается. Но сперва определимся: за кого играем?
Техдолг — нельзя копить, закрывать
4 мин
Технический долг по аналитике — это любая отсутствующая документация на функционал, который поставлен в промышленную среду.
Давайте разберемся на простом жизненном примере, почему важно не копить техдолг?
Представьте, вы прошли ТО для машины, вам написали лист рекомендаций по ремонту, которые уберегут вас в будущем от проблем и сделают поездку на машине комфортной, но вы отложили эти работы на потом.
Однажды в летний жаркий день вы едете на машине в отпуск, и кондиционер не охлаждает, пошел ливень, а дворники не помогают, да еще порвался ремень ГРМ, и машина остановилась. Выглядит как самый худший день в жизни, остается только ждать эвакуатор.
Матрица компетенций аналитика для самурая в запасе
28 мин

Когда-то давно в дебрях Интернета я случайно нарвался на матрицу компетенций программиста от Джозефа Сиджина, которая помогла мне правильно оценить свою стоимость на рынке труда и выработать пути по дальнейшему самосовершенствованию. Шло время, проекты в которых я участвовал, росли. Росли, росли и выросли до такого состояния, что в этих проектах потребовалось участие не только программистов, но и аналитиков. Помня положительный эффект от матрицы Д. Сиджина, в какой-то момент я решил найти такую же шкалу компетенций, но уже для аналитиков. И, что неудивительно, нашел.
“Тайный клуб системной аналитики” или путь к идеалу
5 мин

Hello World!
Меня зовут Сергей Павлов, я тимлид по системной аналитике в банке "Открытие” на продукте МСБ “Бизнес-Портал”. Хочу рассказать, как я решал задачи по управлению командой, когда к ней присоединился.
Скажу сразу: тут я не буду описывать графики, капасити, велосити и любые инструменты, связанные с командными метриками. Речь пойдет именно об организации процессов для повышения качества взаимодействия при коллективной работе.
Итак, морозное утро, вежливый голос руководителя мне говорит: “Это команда системных аналитиков, начинай творить добро”. Я смог выдавить только “угу” и сел думать насчет того самого творить и того самого добра.
Как мы в Сбере формировали сообщество практики по автоматизации DevOps CI/CD
13 мин

Привет, Хабр! Сегодня мы расскажем о том, как подходили к созданию сообщества практики по автоматизации DevOps CI/CD в Сбере. Рассмотрим предпосылки, методологии и лучший мировой опыт, который использовали, а также ключевые проблемы и ошибки. В этой статье опытом делится Рашид Галиев – руководитель группы развития методологии DevOps и внедрения инженерных практик CI/CD, эксперт команды ядра сообщества DevOps в Сбере.
Начну с цифр и предпосылок: у нас порядка 16000 инженеров разных ролей и областей экспертизы, около 3000 продуктовых команд, большое количество систем со своим независимым релизным циклом и достаточно много внедрений в месяц.
Таблица в Atlassian Confluence на основе данных из REST запроса
5 мин
Туториал
Привет!
В этой статье я расскажу, как сделать страницу в Atlassian Confluence с таблицей, данные в которую будут приходить из REST запроса.
Мы сделаем страницу в Confluence с таблицей, которая будет содержать данные о проектах в Jira. Эти данные мы будем получать из Jira при помощи метода project из стандартного Jira REST API.
Вы можете посмотреть видео по этой статье вот здесь.
В этой статье я расскажу, как сделать страницу в Atlassian Confluence с таблицей, данные в которую будут приходить из REST запроса.
Мы сделаем страницу в Confluence с таблицей, которая будет содержать данные о проектах в Jira. Эти данные мы будем получать из Jira при помощи метода project из стандартного Jira REST API.
Вы можете посмотреть видео по этой статье вот здесь.