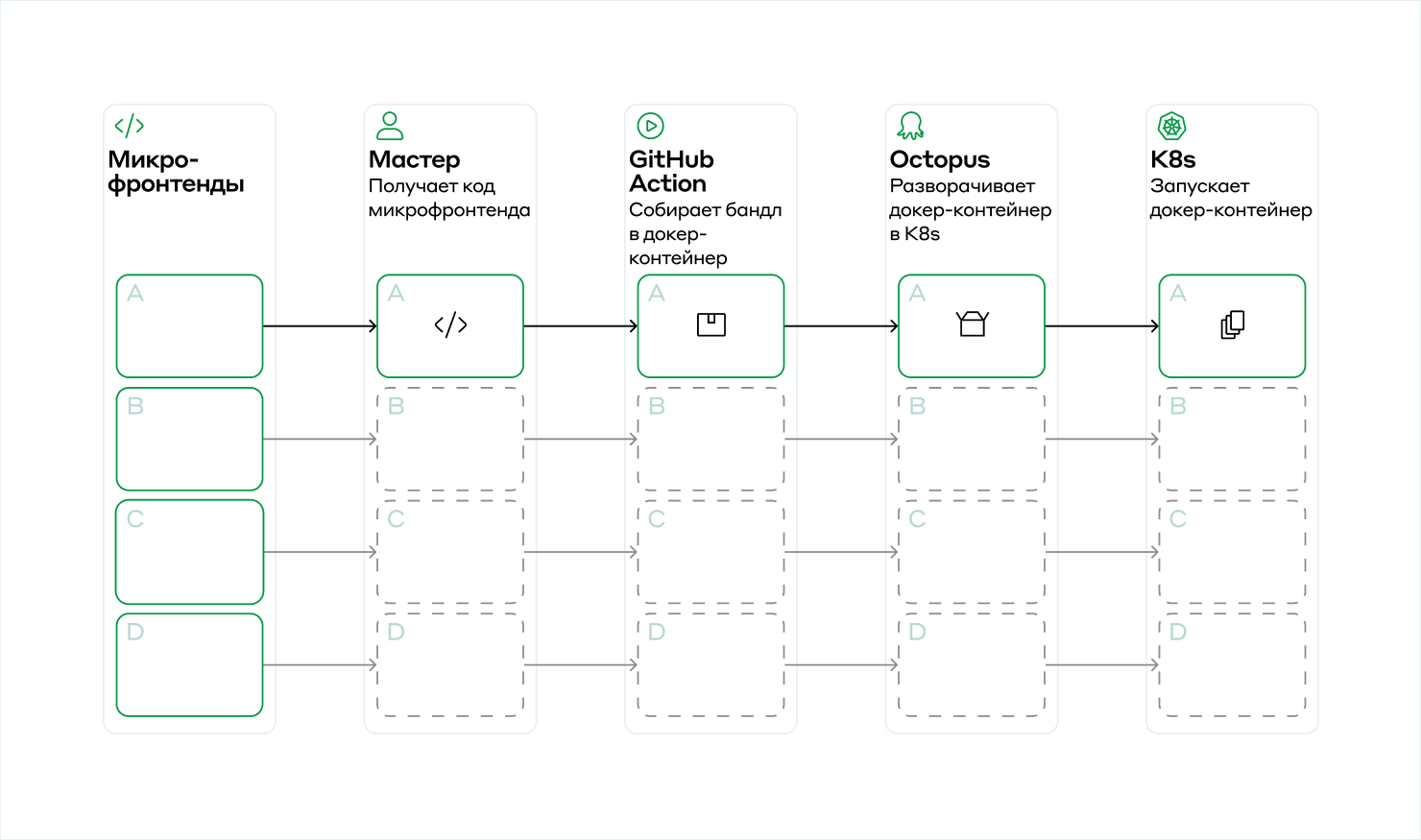
Всем доброго времени суток!
Сегодня речь пойдёт о таком страшном звере, как micro-frontend. Знаю: всем эта тема порядком надоела, но просмотрев полтора десятка выступлений осознал, что не все до конца понимают, что это такое и какие сложности следует решать при организации micro-frontend’а. В данной статье я дам универсальные советы, расскажу с чем не стоит связываться и, в целом, как не превратить проект в ад из callback’ов или непонятных интерфейсов. Итак, обо всем по порядку.
Что такое micro-frontend?
Точного определения днём с огнём не сыщешь. Суть в том, что термин micro-frontend подразумевает наличие множества изолированных приложений с интерфейсом, для взаимодействия с ними посредством API. Это позволяет использовать версионированность, не опираясь на рядом стоящие компоненты. Наглядным примером такой реализации являются различные npm-пакеты. Так же micro-frontend подразумевает под собой использование микро-сервисной архитектуры, что в совокупности даёт нам инкапсулированную логику не зависящую от окружения.
Чем был плох предыдущий подход - монолит?
Для того, чтобы понять преимущества micro-frontend’а нам следует разобраться чем именно он отличается от, так называемого, монолита.
Монолитное приложение характеризуется высокой связанностью частей системы. С одной стороны, уменьшает затраты на архитектуру и повышает скорость разработки, с другой - увеличивает стоимость разработки нового функционала, его изменения и поддержки. Из вышеизложенного следует, что логика может быть размазана по приложению и, как следствие, может свести к минимуму переиспользуемость компонентов.