Смазанные изображения — один из самых неприятных дефектов в фотографии, наравне с расфокусированными изображениями. Ранее я писал про алгоритмы деконволюции для восстановления смазанных и расфокусированных изображений. Эти, относительно простые, подходы позволяют восстановить исходное изображение, если известна точная траектория смаза (или форма пятна размытия).
В большинстве случаев траектория смаза предполагается прямой линией, параметры которой должен задавать сам пользователь — для этого требуется достаточно кропотливая работа по подбору ядра, кроме того, в реальных фотографиях траектория смаза далека от линии и представляет собой замысловатую кривую переменной плотности/яркости, форму которой крайне сложно подобрать вручную.

В последние несколько лет интенсивно развивается новое направлении в теории восстановления изображений — слепая обратная свертка (Blind Deconvolution). Появилось достаточно много работ по этой теме, и начинается активное коммерческое использование результатов.
Многие из вас помнят конференцию Adobe MAX 2011, на которой они как раз показали работу одного из алгоритмов Blind Deconvolution:
Исправление смазанных фотографий в новой версии Photoshop
В этой статье я хочу подробнее рассказать — как же работает эта удивительная технология, а также показать практическую реализацию SmartDeblur, который теперь тоже имеет в своем распоряжении этот алгоритм.
Внимание, под катом много картинок!



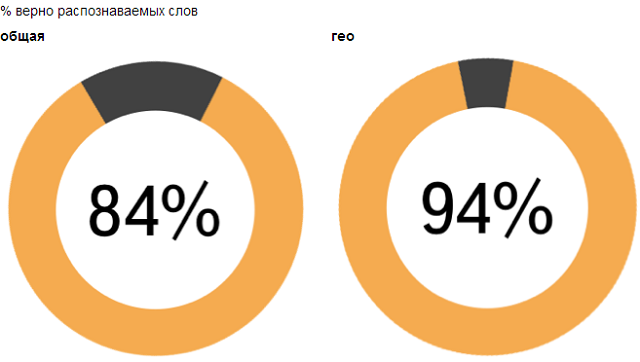
 На Yet another Conference 2013 мы представили разработчикам нашу новую библиотеку Yandex SpeechKit. Это публичный API для распознавания речи, который могут использовать разработчики под Android и iOS. Скачать SpeechKit, а также ознакомиться с документацией, можно здесь.
На Yet another Conference 2013 мы представили разработчикам нашу новую библиотеку Yandex SpeechKit. Это публичный API для распознавания речи, который могут использовать разработчики под Android и iOS. Скачать SpeechKit, а также ознакомиться с документацией, можно здесь.