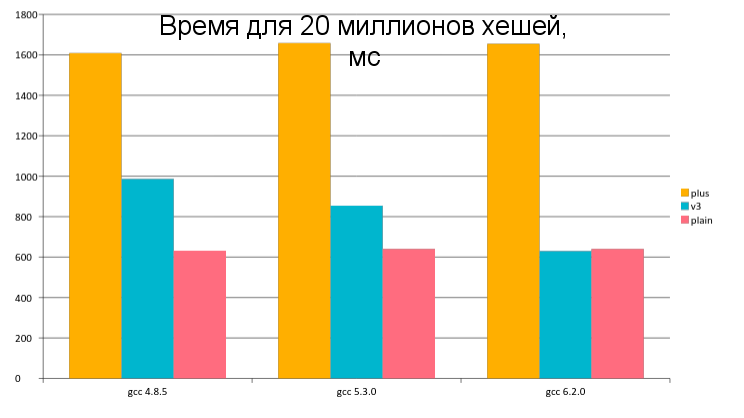
В настоящее время у системных программистов практически нет выбора какой язык использовать. По хорошему все варианты сводятся или к чистому Си или к Rust, хотя как показывает опыт далеко не всем нравится его синтаксис.
Благодаря усилиями команды разработчиков языка у D теперь появилось совместимое с чистым Си подмножество обладающее не только привычным для любого программиста Си синтаксисом, но и значительно расширяющее функционал языка. Новое подмножество называется «betterC». Это подмножество позволяет перевести написание Си приложение на новый уровень.
Благодаря усилиями команды разработчиков языка у D теперь появилось совместимое с чистым Си подмножество обладающее не только привычным для любого программиста Си синтаксисом, но и значительно расширяющее функционал языка. Новое подмножество называется «betterC». Это подмножество позволяет перевести написание Си приложение на новый уровень.



 Пробежался по хабам и не нашел ничего написанного одновременно в хабы "D" и "Ненормальное программирование". Может сложиться совершенно ложное представление что на D пишут исключительно нормальные люди, или еще хуже того — что знание D автоматически делает из любого программиста нормального человека. Спешу опровергнуть.
Пробежался по хабам и не нашел ничего написанного одновременно в хабы "D" и "Ненормальное программирование". Может сложиться совершенно ложное представление что на D пишут исключительно нормальные люди, или еще хуже того — что знание D автоматически делает из любого программиста нормального человека. Спешу опровергнуть.