Вчера я
задал вопрос в своем ХабраБлоге — интересно ли людям узнать, что такое Hadoop с точки зрения его реального применения? Оказалось, интересно. Дело недолгое — статью я написал довольно быстро (по крайней мере, ее первую часть) — как минимум, потому, что уже давно знал, о чем собираюсь написать (потому как еще неплохо помню как я сам тыкался в поиске информации, когда начинал пользоваться Hadoop). В первой статье речь пойдет об основах — но совсем не о тех, про которые обычно рассказывают :-)
Перед прочтением статьи я настоятельно рекомендую изучить как минимум первый и последний источники из списка для чтения — их понимание или хотя бы прочтение практически гарантирует, что статья будет понята без проблем. Ну что, поехали?
Что такое Hadoop?

Ну скажите, какой смысл об этом писать? Уже не раз это проговаривалось, неоднократно начинали писаться посты на тему Hadoop, HDFS и прочая. К сожалению, обычно все заканчивалось на довольно пространном введении и фразе “Продолжение следует”. Так вот: это — продолжение. Кому-то тема, затрагиваемая в этой статье может показаться совершенно тривиальной и неинтересной, однако же лиха беда начало — любые сложные задачи надо решать по частям. Это утверждение, в частности, мы и реализуем в ходе статьи. Сразу замечу, что я постараюсь избежать написания кода в рамках этой конкретной статьи — это может подождать, а понять принципы построения программ, работающих с Map/Reduce можно и “на кошках” (к тому же с текущей частотой кардинального изменения API Hadoop любой код становится obsolete примерно через месяц).
Когда я начинал разбираться с Хадупом, очень большой сложностью лично для меня стало первоначальное понимание идеологии Map/Reduce (я предпочитаю писать это словосочетание именно так, чтобы подчеркнуть, что речь идет не о продукте, а о принципе). Суть и ценность метода станет понятна в самом конце — после того, как мы решим несложную задачу.


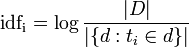


![[окошко свойств картинки-гиперссылки]](https://habrastorage.org/getpro/habr/post_images/c68/ac1/802/c68ac180236eed277c0c05201fa3bf3f.png)
