Приветствую.
Хочу рассказать, чем я баловался в свободное от работы в Qualys время. Так как в англоязычном интернете на удивление много шума про Slow Read DoS attack, и уверен что получу здесь много полезной критики и дельных предложений.
В августе 2011 года написал програмку slowhttptest, которая тестирует веб-серверы на наличие уязвимостей, связанных с обработкой медленных HTTP запросов, таких как slowloris и slow HTTP Post. Цель — создать конфигурируемый инструмент, облегчающий работу разработчиков и позволить им концентрироваться на создании эффективных защит, а не ковырянии в питоне, на котором написаны большинство proof-of-concept эксплоитов.
А потом решил попробовать, как реагируют серверы на медленное чтение клиентами HTTP респонсов. На удивление плохо реагируют. Дефолтные apache, nginx, lightpd, IIS отказывают в обслуживании на ура.
А суть такова:
Хочу рассказать, чем я баловался в свободное от работы в Qualys время. Так как в англоязычном интернете на удивление много шума про Slow Read DoS attack, и уверен что получу здесь много полезной критики и дельных предложений.
В августе 2011 года написал програмку slowhttptest, которая тестирует веб-серверы на наличие уязвимостей, связанных с обработкой медленных HTTP запросов, таких как slowloris и slow HTTP Post. Цель — создать конфигурируемый инструмент, облегчающий работу разработчиков и позволить им концентрироваться на создании эффективных защит, а не ковырянии в питоне, на котором написаны большинство proof-of-concept эксплоитов.
А потом решил попробовать, как реагируют серверы на медленное чтение клиентами HTTP респонсов. На удивление плохо реагируют. Дефолтные apache, nginx, lightpd, IIS отказывают в обслуживании на ура.
А суть такова:
 В современном мире трехмерные технологии стали очень популярны. 3D стремительно и разнообразно входит в жизнь даже обычного человека. Начиная от 3D телевизоров, 3D сканеров и даже принтеров. Хотя последние два устройства в большей степени пока доступны только специалистам. Но технологии не стоят на месте. Появляются трехмерные принтеры стоимостью около $2000, что уже приближает время, когда они появятся, если не у каждого школьника/студента на столе, то как минимум, у каждого инженера или дизайнера. Что касается методов получения трехмерной модели с реального физического объекта, то тут тоже не все однозначно. Требуются наличие либо дорогостоящего лазерного сканера, либо можно попытать счастье с помощью лазерного строительного уровня, веб-камеры и специального программного обеспечения. Наличием всех этих вещей тоже не может похвастаться абсолютно любой человек.
В современном мире трехмерные технологии стали очень популярны. 3D стремительно и разнообразно входит в жизнь даже обычного человека. Начиная от 3D телевизоров, 3D сканеров и даже принтеров. Хотя последние два устройства в большей степени пока доступны только специалистам. Но технологии не стоят на месте. Появляются трехмерные принтеры стоимостью около $2000, что уже приближает время, когда они появятся, если не у каждого школьника/студента на столе, то как минимум, у каждого инженера или дизайнера. Что касается методов получения трехмерной модели с реального физического объекта, то тут тоже не все однозначно. Требуются наличие либо дорогостоящего лазерного сканера, либо можно попытать счастье с помощью лазерного строительного уровня, веб-камеры и специального программного обеспечения. Наличием всех этих вещей тоже не может похвастаться абсолютно любой человек.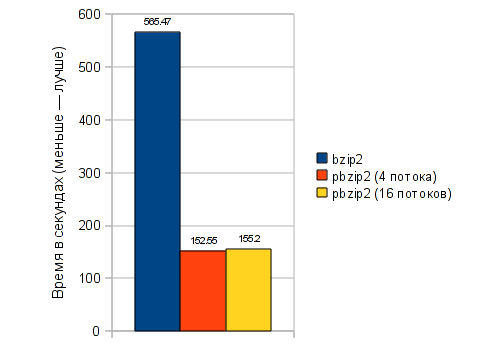
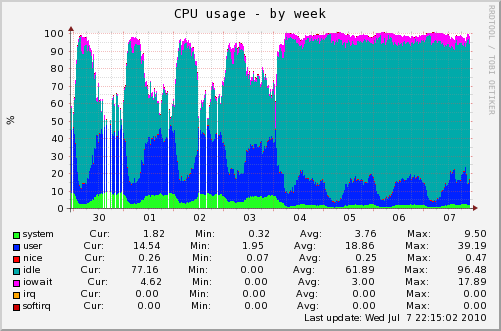 Пару дней назад обратился ко мне человек с достаточно рутинной просьбой: подкрутить настройки VPS для его ускорения — за последнее время на сайте был резкий рост посещаемости, и сервер в часы-пик стал совсем загибаться.
Пару дней назад обратился ко мне человек с достаточно рутинной просьбой: подкрутить настройки VPS для его ускорения — за последнее время на сайте был резкий рост посещаемости, и сервер в часы-пик стал совсем загибаться.