Обычно под музыкальным поиском понимают умение отвечать на текстовые запросы о музыке. Поиск должен понимать, например, что «пятница» – это не всегда день недели, или находить песню по словам «хочешь сладких апельсинов». Но этим задачи музыкального поиска не ограничиваются. Бывает, что нужно распознать песню, которую напел пользователь, или ту, которая играет в кафе. А ещё можно находить общее в композициях, чтобы рекомендовать пользователю музыку на его вкус. Как это делается и какие трудности при этом возникают студентам Малого ШАДа рассказали Елена Корнилина и Евгений Крофто.

DjOnline @DjOnlineread-only
User
Сложный и противоречивый мир синтаксиса микроразметки. Почему стандартов так много? Опыт Яндекса
7 min
Сегодня в продолжение наших рассказов о семантической разметке я хочу рассказать о её синтаксисе. То, почему он такой, а не иной, часто определяется историческими причинами, а иногда — ещё и комично. Поэтому мы попробовали здесь всё систематизировать и объяснить.
Сначала пару слов, чтобы все понимали, что есть что. Под микроразметкой в целом (или семантической разметкой) мы подразумеваем разметку страницы с дополнительными тегами и атрибутами в тегах, которые указывают поисковым роботам на то, о чем написано на странице.
Словарь — это своеобразный «язык», набор классов и их свойств, с помощью которых указывается суть содержимого на странице. О них мы писали в предыдущей статье. Синтаксис — это способ использования словаря. Он определяет, с помощью каких тегов и как будут указываться сущности и их свойства, например, на веб-страницах.

Стандартов синтаксиса, как и словарей, несколько. В этой статье мы и разберем на практических примерах наиболее распространенные:
Чтобы понять, почему для решения одной задачи было разработано много разных стандартов, обратимся к истории развития синтаксиса:
Once upon a time В 2004 году разработчики из W3C создали стандарт, который, по их мнению, подходил для «представления всего в мире». Так появился синтаксис RDFa (Resourse Description Framework in attributes), который позволяет однозначно транслировать HTML-разметку с семантическими данными в RDF.
Сначала пару слов, чтобы все понимали, что есть что. Под микроразметкой в целом (или семантической разметкой) мы подразумеваем разметку страницы с дополнительными тегами и атрибутами в тегах, которые указывают поисковым роботам на то, о чем написано на странице.
Словарь — это своеобразный «язык», набор классов и их свойств, с помощью которых указывается суть содержимого на странице. О них мы писали в предыдущей статье. Синтаксис — это способ использования словаря. Он определяет, с помощью каких тегов и как будут указываться сущности и их свойства, например, на веб-страницах.
Стандартов синтаксиса, как и словарей, несколько. В этой статье мы и разберем на практических примерах наиболее распространенные:
- Microdata — Микроданные (словарь Schema.org чаще всего встречается именно в этом синтаксисе);
- Microformats.org — Микроформаты (напоминаем, что это объединенный стандарт синтаксиса и словаря);
- RDFa и RDFa Lite (в упрощенном виде RDFa рекомендуется создателями словаря Open Graph. Также встречается с другими словарями, например, со словарем Dublin Core или Data Vocabulary);
- JSON-LD — расширение JSON.
Чтобы понять, почему для решения одной задачи было разработано много разных стандартов, обратимся к истории развития синтаксиса:
Замолвим слово об отладке и профилировании [PHP]
5 min
Tutorial
Все идет от лени. Вы получили чужой очень большой проект в котором нужно сделать небольшие правки, или же написали скрипт и сразу не очевидно, что в нем еще требует оптимизации. Как быть? Читать и анализировать код, выводить каждый шаг на экран или в файл (var_dump() и т.д.) не всегда эффективно, ведь можно воспользоваться средствами отладки, которых на сегодняшний день очень много. Кратко перечислю часто встречающиеся…
Что такое Томита-парсер, как Яндекс с его помощью понимает естественный язык, и как вы с его помощью сможете извлекать факты из текстов
6 min
Мечта о том, чтобы машина понимала человеческий язык, завладела умами еще когда компьютеры были большими, а их производительность – маленькой. Главная проблема на пути к этому заключается в том, что грамматика и семантика естественных языков слабо поддаются формализации. Кроме того, от языков программирования их отличает присутствие многозначности.
Конечно, мечта о полноценной коммуникации с компьютером на естественном языке пока еще далека от полноценной реализации примерно настолько же, как и мечта об искусственном интеллекте. Однако некоторые результаты есть уже сейчас: машину можно научить находить нужные объекты в тексте на естественном языке, находить между ними связи и представлять необходимые данные в формализованном виде для дальнейшей обработки. В Яндексе уже достаточно давно применяется такая технология. Например, если вам придет письмо с предложением о встрече в определенном месте и в определенное время, специальный алгоритм самостоятельно извлечет нужные данные и предложит внести ее в календарь.
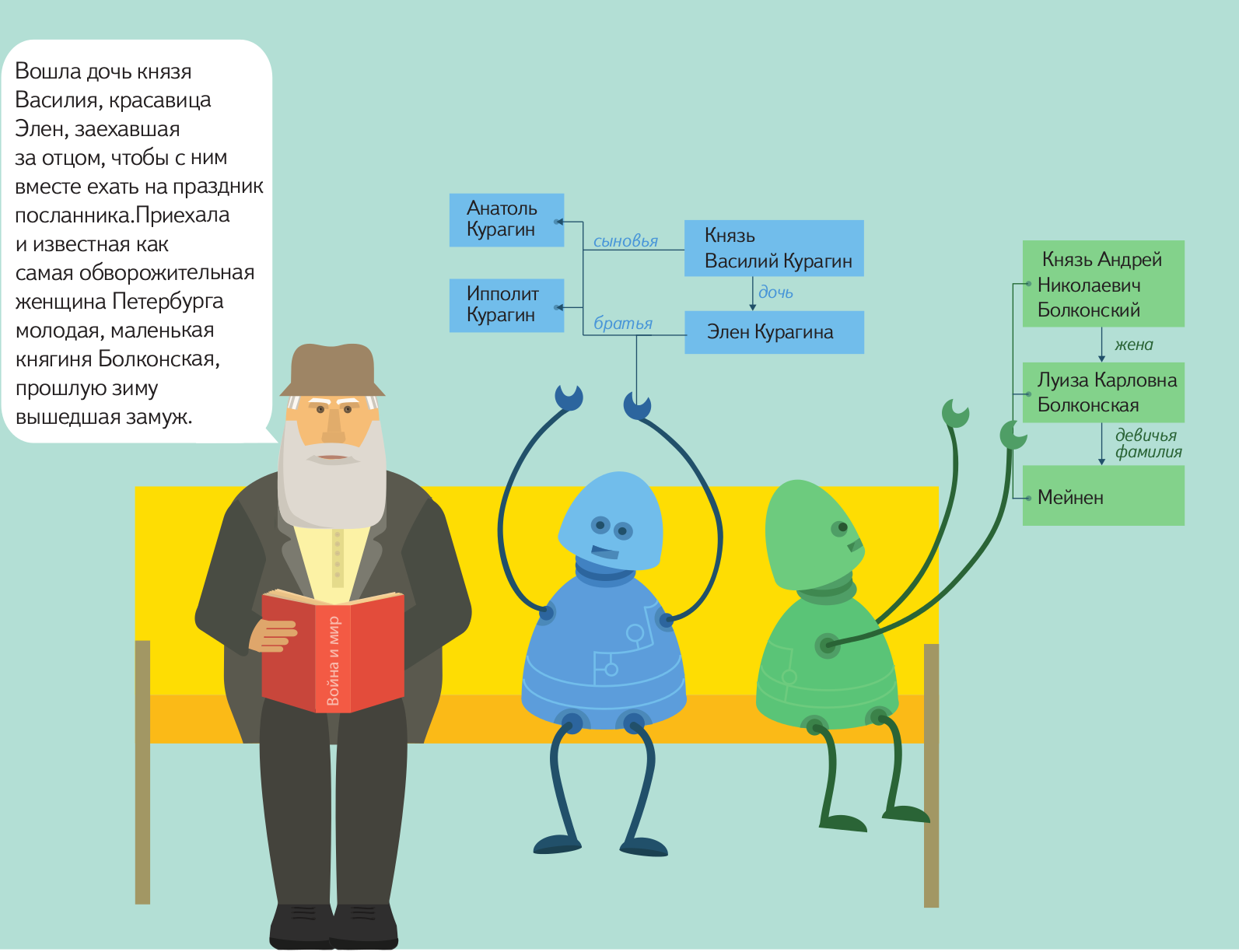
Вскоре мы планируем отдать эту технологию в open source, чтобы любой мог пользоваться ей и развивать ее, приближая тем самым светлое будущее свободного общения между человеком и компьютером. Подготовка к открытию исходных кодов уже началась, но процесс этот не такой быстрый, как нам бы хотелось, и, скорее всего, продлится до конца этого года. За это время мы постараемся как можно больше рассказать о своем продукте, для чего запускаем серию постов, в рамках которой расскажем об устройстве инструмента и принципах работы с ним.
Называется технология Томита-парсер, и по большому счету, любой желающий может воспользоваться ей уже сейчас: бинарные файлы доступны для скачивания. Однако прежде чем пользоваться технологией, нужно научиться ее правильно готовить.
Конечно, мечта о полноценной коммуникации с компьютером на естественном языке пока еще далека от полноценной реализации примерно настолько же, как и мечта об искусственном интеллекте. Однако некоторые результаты есть уже сейчас: машину можно научить находить нужные объекты в тексте на естественном языке, находить между ними связи и представлять необходимые данные в формализованном виде для дальнейшей обработки. В Яндексе уже достаточно давно применяется такая технология. Например, если вам придет письмо с предложением о встрече в определенном месте и в определенное время, специальный алгоритм самостоятельно извлечет нужные данные и предложит внести ее в календарь.
Вскоре мы планируем отдать эту технологию в open source, чтобы любой мог пользоваться ей и развивать ее, приближая тем самым светлое будущее свободного общения между человеком и компьютером. Подготовка к открытию исходных кодов уже началась, но процесс этот не такой быстрый, как нам бы хотелось, и, скорее всего, продлится до конца этого года. За это время мы постараемся как можно больше рассказать о своем продукте, для чего запускаем серию постов, в рамках которой расскажем об устройстве инструмента и принципах работы с ним.
Называется технология Томита-парсер, и по большому счету, любой желающий может воспользоваться ей уже сейчас: бинарные файлы доступны для скачивания. Однако прежде чем пользоваться технологией, нужно научиться ее правильно готовить.
Mozilla оптимизирует формат JPEG
2 min
 Mozilla анонсировала новый проект mozjpeg по созданию качественного кодера JPEG, который улучшит сжатие изображений при сохранении совместимости с существующими декодерами.
Mozilla анонсировала новый проект mozjpeg по созданию качественного кодера JPEG, который улучшит сжатие изображений при сохранении совместимости с существующими декодерами.На каждом сайте постоянно увеличивается и количество файлов JPEG, и их размер. Поскольку HTML, JS, и CSS относительно невелики, то при загрузке веб-страницы основной трафик зачастую приходится именно на JPEG. Так что уменьшение размера фотографий — вполне очевидная цель для оптимизации, считает Mozilla.
Существующие кодеры JPEG зачастую работают не очень эффективно. Логично перейти на более современные алгоритмы (например, JPEG2000 с вейвлет-преобразованием или свободный WebP), и такая тема неоднократно обсуждалась. Но разработчики Mozilla говорят, что популярность JPEG слишком велика. Созданный в 1992 году этот стандарт сжатия с потерями стал общепризнанным. Переход на новый формат займёт много лет, поскольку он не совместим с имеющимся программным обеспечением. «Мы (в Mozilla) не сомневаемся, что алгоритмические улучшения когда-нибудь подтолкнут к такому переходу, возможно, скоро. Но даже в этом случае JPEG ещё долго будет с нами».
Релиз KPHP и движков
6 min
Довольно часто, выступая на различных конференциях, мы делились желанием выпустить под открытой лицензией KittenPHP, согласно традиции, заложенной крупными IT-компаниями, такими как Google и Facebook.
Это событие несколько раз откладывалось в связи с опасением, что нам не хватит сил и времени на взаимодействие с opensource-сообществом, однако в конце концов заветный день настал, и код KPHP и некоторых других инструментов, используемых внутри проекта, был выложен в открытый доступ.
В связи с этим под катом вас ждет более подробный рассказ о внутреннем устройстве ВКонтакте и тех инструментах, которые сегодня стали доступны opensource-сообществу.

Это событие несколько раз откладывалось в связи с опасением, что нам не хватит сил и времени на взаимодействие с opensource-сообществом, однако в конце концов заветный день настал, и код KPHP и некоторых других инструментов, используемых внутри проекта, был выложен в открытый доступ.
В связи с этим под катом вас ждет более подробный рассказ о внутреннем устройстве ВКонтакте и тех инструментах, которые сегодня стали доступны opensource-сообществу.
Список оптимизаций рендеринга DOM, реализуемых на уровне Javascript фреймворка
13 min
С октября 2009 года я занимаюсь разработкой приложения для поиска и прослушивания музыки. Я стремлюсь организовать возможность быстрого взаимодействия пользователя с интерфейсом, и в качестве одного из средств ускорения взаимодействия использую различные способы для быстрой отрисовки страниц.
Предлагаю ознакомиться со способами, реализованными мной в приложении на системном уровне:
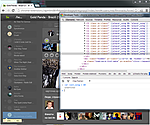
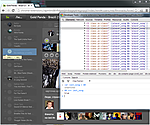
изображения из части с заголовком «Прикрепление частей изменяющихся коллекций единовременно...»
Предлагаю ознакомиться со способами, реализованными мной в приложении на системном уровне:
- Использование CSS и переключение классов вместо перестроения DOM дерева
- Повсемнестное кеширование выборок элементов ($('div.active_part span.highlighter')), атомарные операции по изменению (вместо всеобщей перерисовки, вместо переделывания больших участков DOM дерева)
- Минимизации чтений DOM во время записи изменений состояний
- Кеширование размеров и расположения элементов (это спасает от излишнего вычисления при считывании этих значений при наличии других изменений: чтение во время изменения множества частей дерева крайне негативно сказывается на производительности)
- Аккуратное, не затягивающееся накопление изменений, необходимых произвести в DOM
- Прикрепление частей изменяющихся коллекций единовременно (когда, например, в середину списка вставляется 3 новых элемента; createDocumentFragment) в конкретное место (after, before) вместо открепления всей коллекции от DOM и повторного прикрепления (и вместо того, чтобы перерисовывать весь список)
- Прогрессивный асинхронный рендеринг: картина прорисовывается сразу с небольшим количеством деталей, затем деталей появляется всё больше
- Клонирование нодов (как часть шаблонизации)
- Кеширование и использование кеша результатов парсинга DOM шаблонов
изображения из части с заголовком «Прикрепление частей изменяющихся коллекций единовременно...»
Ежемесячные расходы дизайн-студии на электроные сервисы
2 min
Поговорим о ежемесячных тратах на электронные сервисы, которые необходимы для работы небольшой студии с удалённой командой, занимающейся дизайном в интернете. Давайте посмотрим, какими платными сервисами мы пользуемся в Genue.
Простая и удобная система управления проектами от команды 37signals. Это основной инструмент взаимодействия как внутри студии, так и с заказчиками. Все задачи заводятся в виде простых списков и легко меняются местами друг с другом простым перетаскиванием. Каждая задача выглядит как публикация с комментариями. Любой может указывать, кто из команды получит уведомление на email о его комментарии. Можно ограничивать видимость некоторых задач для клиента.
50$. Basecamp
Простая и удобная система управления проектами от команды 37signals. Это основной инструмент взаимодействия как внутри студии, так и с заказчиками. Все задачи заводятся в виде простых списков и легко меняются местами друг с другом простым перетаскиванием. Каждая задача выглядит как публикация с комментариями. Любой может указывать, кто из команды получит уведомление на email о его комментарии. Можно ограничивать видимость некоторых задач для клиента.
Подборка трюков при анализе защищенности веб приложений
5 min
Всем привет! Этот топик посвящен разным трюкам при анализе защищенности (пентесте) веб приложений. Периодически сталкиваешься с ситуацией, когда надо обойти какую-нибудь защиту, выкрутиться в данных ограничениях или просто протестировать какое-то неочевидное место. И этот пост как раз об этом! Добро пожаловать под кат.
Война с дизайнером: откуда берётся хороший дизайн
5 min
Вы более 9000 раз заказывали дизайн, и ни разу не разочаровались? Творческие люди понимают вас с полуслова, а результат их работы непременно радует ваш глаз и кошелек? Может быть, вы дизайнер-профессионал, отточивший мастерство общения с закачиком до мастерского уровня?
Тогда этот пост не для вас. Вы и так все знаете.
Но если письма от дизайнера, который занимается вашим проектом, начинаются заголовком «правки ver_3_b_часть II», а общаться с каждым днем все сложнее — попробуйте почитать. Может быть, здесь найдется полезный совет, который облегчит вам жизнь и сэкономит деньги.
Я предлагаю вашему вниманию несколько заметок-соображений, которые накопились за время моей работы в этой области.
Тогда этот пост не для вас. Вы и так все знаете.
Но если письма от дизайнера, который занимается вашим проектом, начинаются заголовком «правки ver_3_b_часть II», а общаться с каждым днем все сложнее — попробуйте почитать. Может быть, здесь найдется полезный совет, который облегчит вам жизнь и сэкономит деньги.
Я предлагаю вашему вниманию несколько заметок-соображений, которые накопились за время моей работы в этой области.
Подсказки: API для ввода почтовых адресов и ФИО одной строкой
2 min
Если вам когда-нибудь приходилось разрабатывать форму регистрации или оформления заказа, то вы знаете, что для получения из формы качественных данных нужно прикрутить множество проверок для ФИО, почтовых адресов, e-mail, телефонов. При этом так уж исторически сложилось, что разработчики пишут код валидации информации каждый раз заново. Ну а потом эти проверки приходится еще и поддерживать, а на поддержку, как известно, приходится 80% усилий.
Кроме того, чем сложнее форма для ввода, и чем больше в ней валидируется информации, тем больше вероятность, что она будет глючить, и как результат — будет неудобна для пользователя.
Так не должно быть.
Кроме того, чем сложнее форма для ввода, и чем больше в ней валидируется информации, тем больше вероятность, что она будет глючить, и как результат — будет неудобна для пользователя.
Так не должно быть.
Делаем вебсокеты на PHP с нуля
18 min
Некоторое время назад я выбирал библиотеку для работы с вебсокетами. На просторах интернета я натыкался на статьи по интеграции node.js с yii, а почти все статьи о вебсокетах на хабре ограничивались инструкциями к тому, как использовать phpdaemon.
Я изучал библиотеки phpdaemon и ratchet, они достаточно монструозны (причём используя ratchet для отправки сообщения конкретному пользователю рекомендовано дополнительно использовать wamp). Мне не совсем было понятно для чего использовать таких монстров, которые требуют установку других монстров. Почитав исходники этих, а также других библиотек, я разобрался как всё устроено и мне захотелось написать простой вебсокет-сервер на php самостоятельно. Это помогло мне закрепить изученный материал и наткнуться на некоторые подводные камни, о которых я не имел представления.
Так я решил написать необходимый для меня функционал с нуля.
Получившийся код и ссылка на демонстрационный чат в конце статьи.
Я изучал библиотеки phpdaemon и ratchet, они достаточно монструозны (причём используя ratchet для отправки сообщения конкретному пользователю рекомендовано дополнительно использовать wamp). Мне не совсем было понятно для чего использовать таких монстров, которые требуют установку других монстров. Почитав исходники этих, а также других библиотек, я разобрался как всё устроено и мне захотелось написать простой вебсокет-сервер на php самостоятельно. Это помогло мне закрепить изученный материал и наткнуться на некоторые подводные камни, о которых я не имел представления.
Так я решил написать необходимый для меня функционал с нуля.
Получившийся код и ссылка на демонстрационный чат в конце статьи.
Создание превью изображений на клиенте: борьба с прожорливыми браузерами
8 min
Всем привет! Сегодня задача у нас следующая: необходимо создать интерфейс для загрузки картинок, который бы генерировал перед загрузкой превьюшки небольшого формата. На данный момент HTML5 вовсю шествует по планете, и, казалось бы, как это реализовать должно быть предельно ясно. Есть несколько русскоязычных статей на эту тему (вот, например). Но тут есть одно но. В рассматриваемом там подходе не уделено никакого внимания расходу памяти браузером. А расход может доходить до гигантских размеров. Разумеется, если загружать одновременно не более 5-10 картинок небольшого формата, то все остается в пределах нормы; но наш интерфейс должен позволять загружать сразу много изображений формата не меньше, чем у современных фотоаппаратов-мыльниц. И вот тогда-то свободная память начинает таять на глазах.
База GeoIP – страны и города, сентябрь 2013
2 min
Вышла в свет обновленная версия русскоязычной базы данных стран и городов.
База распространяется в двух модификациях: «Страны и города» (13Mb, после установки ~74Mb) и «Только страны» (2Mb, после установки ~9Mb). Также в архивах находится небольшой пример использования базы данных на php.
База распространяется в двух модификациях: «Страны и города» (13Mb, после установки ~74Mb) и «Только страны» (2Mb, после установки ~9Mb). Также в архивах находится небольшой пример использования базы данных на php.
Китайцы предлагают по 10Тб всем желающим
1 min
Гонка за объёмом предоставляемого облачного хранилища в Китае явно выходит на новый уровень: китайская компания Tencent предлагает всем зарегистрироваться и получить в итоге в своё распоряжение 10 Тб (терабайт) места на своём сервисе бесплатно. В этом смысле потуги Google или Dropbox действительно выглядят неважно — правда, всегда можно задаться вопросом о надёжности или приватности, хотя в этом смысле у Tencent вроде бы дела идут неплохо: она работает с 1998 года и её акции продаются на Гонконгской бирже…
Не обошлось без некоторых условий, которые, впрочем, действительно не трудно соблюсти — требуется зарегистрироваться с Tencent QQ-аккаунтом (получить его можно здесь) на странице акции и скачать мобильный клиент сервиса — доступны версии для Android и iOS. Сразу после этого в распоряжении пользователя оказывается 1 Тб облачного хранилища, который подходит для любых файлов (такой же объём на Flickr разрешают заполнять только фото и видео).
В дальнейшем по мере исчерпания свободного места сервис будет автоматически его увеличивать, пока верхняя планка не упрётся в заявленные 10 Тб в соответствии с приведённой ниже таблицей:
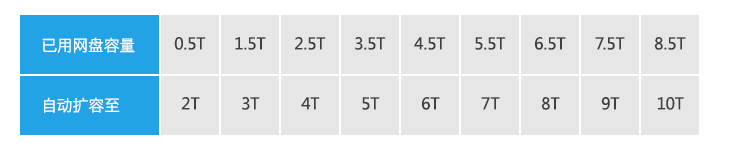
Насколько можно понять, что web-версии или десктопного клиента для сервиса нет, так что речь идёт именно о мобильном хранилище. Время акции также ограничено.
UPD:
Как подсказывают:
Не обошлось без некоторых условий, которые, впрочем, действительно не трудно соблюсти — требуется зарегистрироваться с Tencent QQ-аккаунтом (получить его можно здесь) на странице акции и скачать мобильный клиент сервиса — доступны версии для Android и iOS. Сразу после этого в распоряжении пользователя оказывается 1 Тб облачного хранилища, который подходит для любых файлов (такой же объём на Flickr разрешают заполнять только фото и видео).
В дальнейшем по мере исчерпания свободного места сервис будет автоматически его увеличивать, пока верхняя планка не упрётся в заявленные 10 Тб в соответствии с приведённой ниже таблицей:
UPD:
Как подсказывают:
- Есть десктопный клиент под Windows
- API сервиса
- Веб-версия (есть ограничения на закачку одного файла в 300 Мб, оно снимается, если позволить установить Webkit-плагин )
Оптимизация сайта для планшетов
3 min
Tutorial
Интернет меняется, появляется все больше устройств с отличными от десктопа размерами экранов. Продажи планшетов постоянно растут, а это значит, что сегодня нельзя пренебрегать пользователями, использующих эти девайсы, необходимо оптимизировать сайты для удобного просмотра на планшетах.
Можно менять дополнительные символы виртуальной клавиатуры на необходимые в каждом конкретном случае. Например при наборе обычного текста видим знаки препинания:
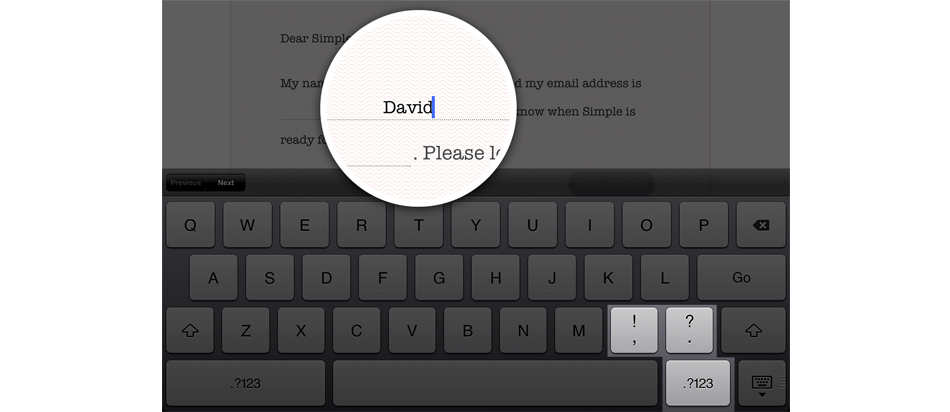
Ускорение набора текста с помощью добавления спецсимволов
Можно менять дополнительные символы виртуальной клавиатуры на необходимые в каждом конкретном случае. Например при наборе обычного текста видим знаки препинания:
Простая методика построения фильтров товаров с помощью MongoDb и MapReduce
8 min
Впервые столкнувшись с MapReduce, я продолжительное время искал реальные примеры применения. Пресловутый поиск слов в тексте, встречающийся в каждой второй статье о MapReduce, искомым примером считать не будем. Наконец, на двух курсах по Big Data на Coursera, я нашёл не только живые примеры, но теоретическую подоплёку для более глубокого понимания происходящего. Возможность применить полученный багаж знаний не заставила себя долго ждать.
В этой небольшой статье я хочу поделиться опытом реализации классической для большинства Интернет-магазинов системы фильтров товаров по критериям применительно к туристическому порталу, где появилась задача поиска и фильтрации по базе в десятки тысяч отелей, каждый из которых описывается рядом параметров и наличием нескольких десятков предоставляемых сервисов из сотен возможных.
В этой небольшой статье я хочу поделиться опытом реализации классической для большинства Интернет-магазинов системы фильтров товаров по критериям применительно к туристическому порталу, где появилась задача поиска и фильтрации по базе в десятки тысяч отелей, каждый из которых описывается рядом параметров и наличием нескольких десятков предоставляемых сервисов из сотен возможных.
Хранилище фотографий Topface теперь open source
3 min
У нас неплохо получается хранить фотографии, поэтому мы решили упростить жизнь и вам, если вы хотите соорудить свой tumblr, facebook или imgur. Дело на самом деле нехитрое, но есть тонкости, о которых лучше знать заранее. К тому же мы сделали всё на node.js, что не слишком характерно для хранилища с более чем 100 000 000 фотографий.

Yaxy — proxy-сервер для веб-разработчика
4 min
Yaxy — proxy-сервер, подменяющий различные части HTTP-запросов и ответов на указанные в config-файле значения. Я не буду здесь описывать, как поставить, настроить и запустить сервер, это всё описано в readme репозитория. Здесь я опишу различные случаи, в которых Yaxy очень помогает, а то и вовсе незаменим.
Grocery CRUD, или как я облегчил себе жизнь на неделю
2 min
Добрый день, ХабраСообщество!
Уже почти месяц веду разработку проекта на CodeIgniter 2.0 и к середине написания столкнулся с проблемой при написании администраторской части. Так сложилось что с «CI» знаком уже более 2-х лет, и еще не разу CodeIgniter меня не подвел в своих возможностях.
Сам проект у меня исчисляется 35 таблицами и писать администраторскую панель мне необходимо для «хомячков». Подсчитав приблизительные человеко-часы необходимые на разработку интерфейса + программной части, я пришел в дикий ужас. Энтузиазм немного поутих (проект мой личный). Вспоминая добрым словом хоть какой-то CRUD в старых версиях, я рискнул «спросить Гугл», авось повезет… И повезло!
Уже почти месяц веду разработку проекта на CodeIgniter 2.0 и к середине написания столкнулся с проблемой при написании администраторской части. Так сложилось что с «CI» знаком уже более 2-х лет, и еще не разу CodeIgniter меня не подвел в своих возможностях.
Сам проект у меня исчисляется 35 таблицами и писать администраторскую панель мне необходимо для «хомячков». Подсчитав приблизительные человеко-часы необходимые на разработку интерфейса + программной части, я пришел в дикий ужас. Энтузиазм немного поутих (проект мой личный). Вспоминая добрым словом хоть какой-то CRUD в старых версиях, я рискнул «спросить Гугл», авось повезет… И повезло!