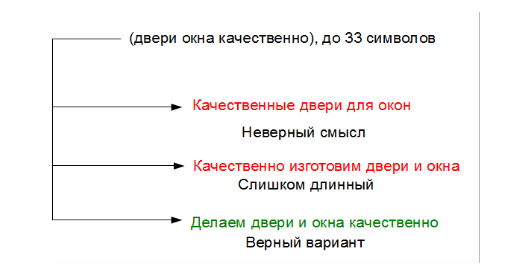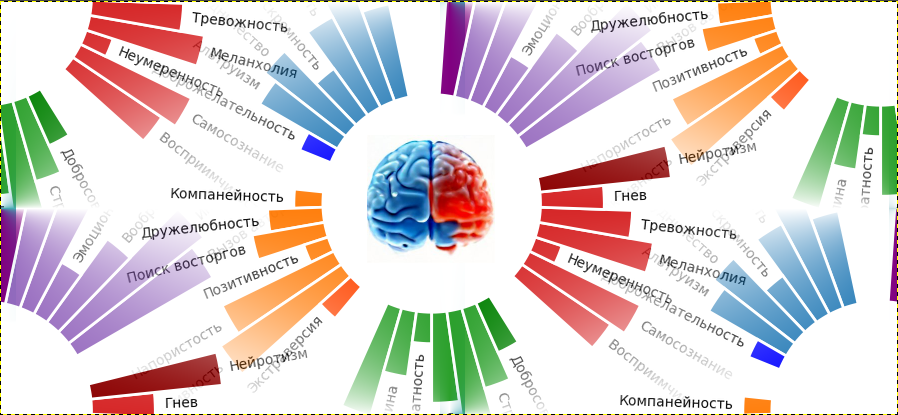
Некоторое время назад к нам обратился заказчик с не совсем обычной задачей — воспроизвести сервис IBM Watson Personality Insights, который анализировал текст, написанный человеком и определял по нему ряд личностных характеристик. Задача возникла по причине того, что бизнес заказчика основывался на этом сервисе, в то время как IBM объявила, что сервис вскоре станет недоступен. В этой статье расскажем, что делал этот сервис и чем закончилась задача воспроизведения его функционала.