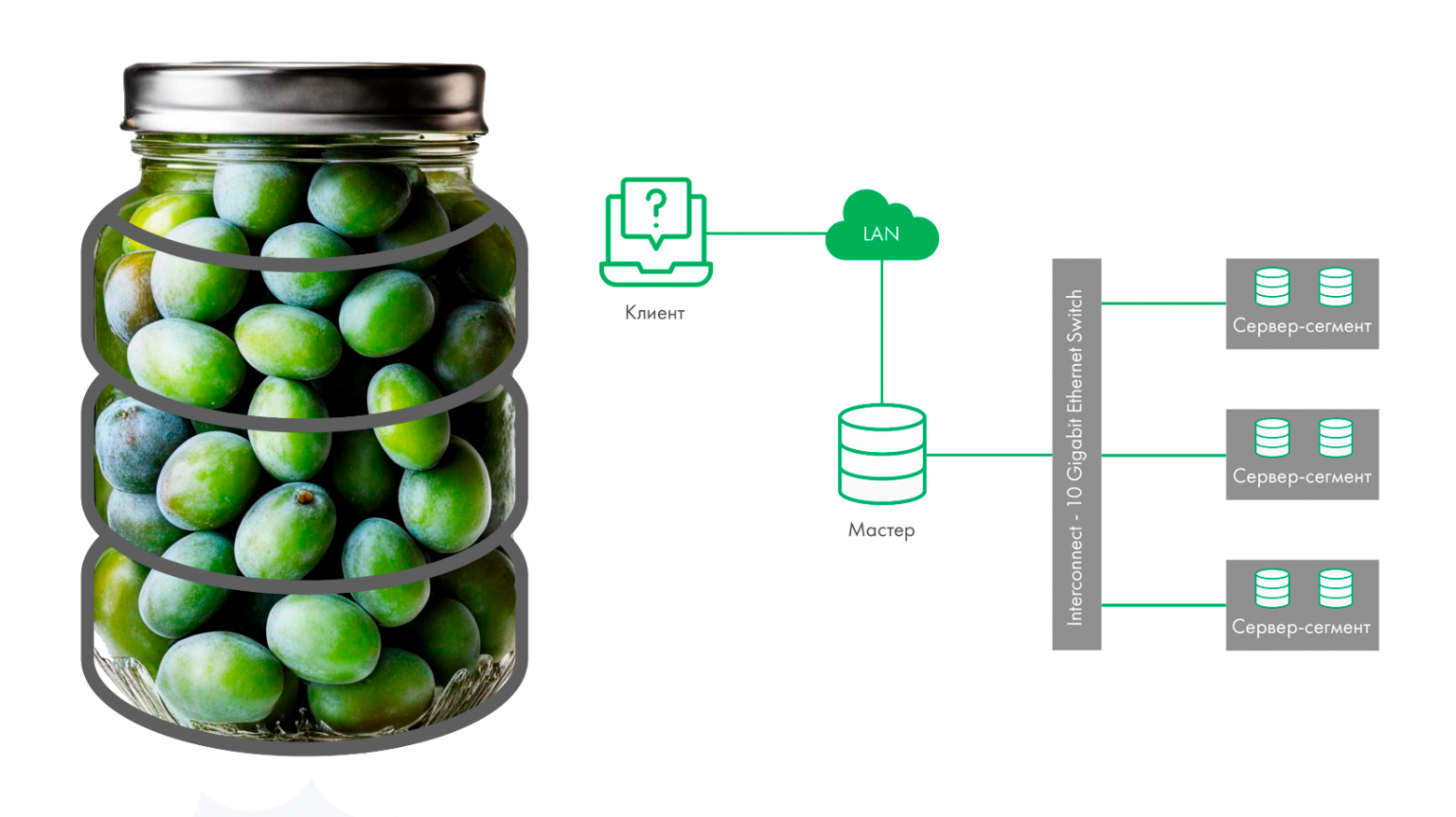
На сегодняшний день потоковая обработка и анализ данных стала неотъемлемой частью многих бизнес-процессов и технологических решений. Для эффективного управления большими объемами данных необходимы инструменты, которые не только обеспечивают надежность передачи сообщений, но и позволяют визуализировать их потоки, обеспечивая прозрачность и удобство мониторинга.
В моей предыдущей статье про симулятор одного из самых популярных брокеров сообщений — RabbitMQ (https://habr.com/ru/articles/859 982/) много читателей оставляли в личку разные вопросы, но одним из самых популярных и часто задаваемых стал: «Очень классный и удобный симулятор! А есть ли такой же для Kafka?» И тут я понял: действительно, несправедливо рассказывать и, так сказать, нести в массы симулятор одного типа брокеров, но совершенно забыть про другой. Ну что ж, Кафка, значит, Кафка!
На просторах всемирной паутины, к сожалению, стопроцентного аналога‑конструктора, такого как RabbitMQ Simulator, к сожалению, я не нашел. Но мы же знаем, что этой статьи не было бы, если бы я не нашел что‑то интересное.
И сегодня это будет Kafka Visualization от компании SoftwareMill.