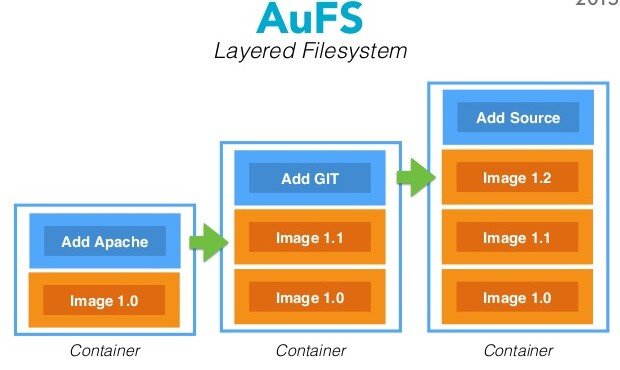
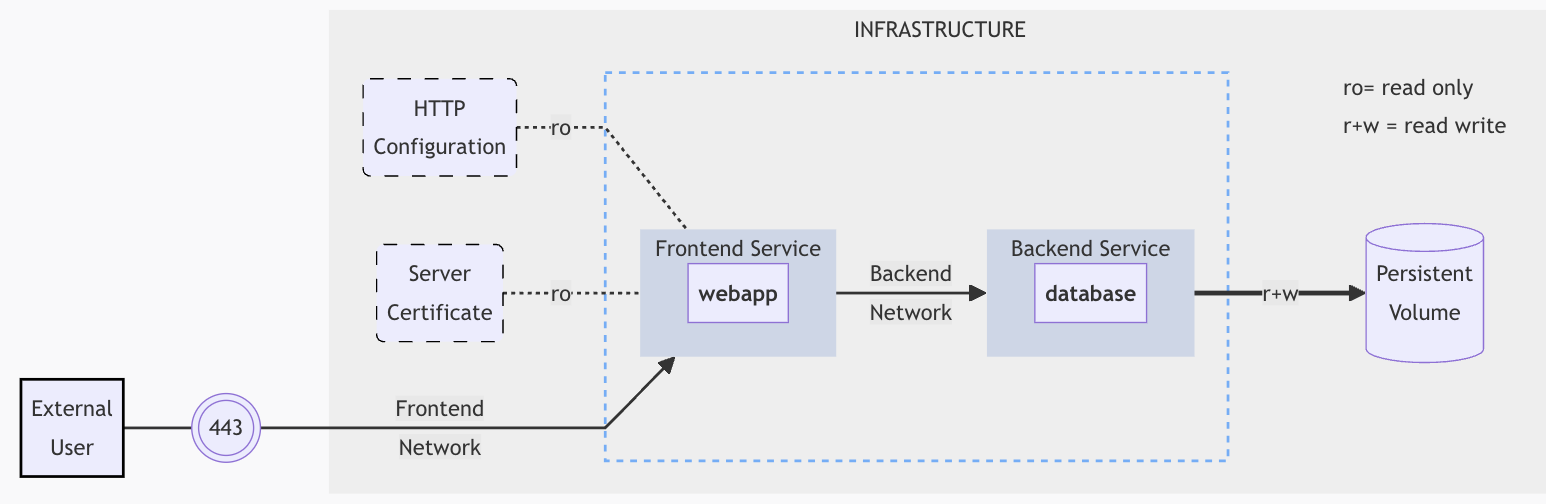
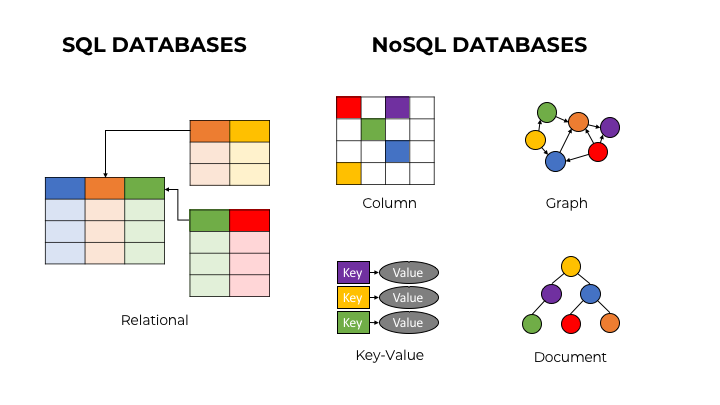
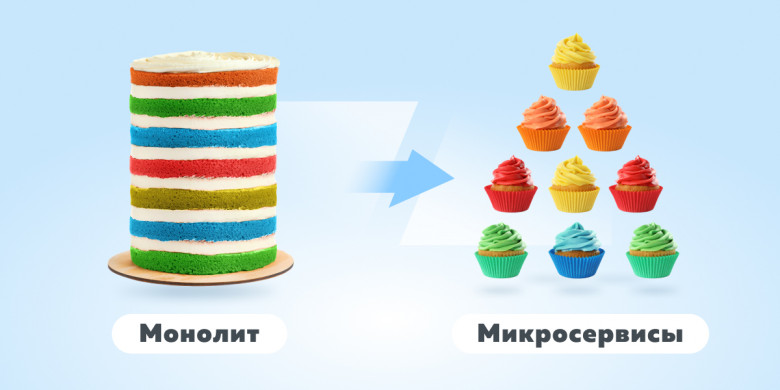
Из современного конструктора LEGO можно собрать только одну модель игрушки, например, самолет. Кастомизировать? Можете поменять местами кресла пилотов — вот и вся кастомизация. Лет 30 назад из конструктора можно было собрать примерно все, от самолета до грузовика, при том же количестве деталей как и в современных. Создатели большинства современных методологий в детстве играли в старое Лего. Те, кто сейчас пользуется методологиями — играли уже в современный. Разница в инженерных практиках огромна.

Под катом
Филипп Дельгядо (
dph) расскажет об инженерном подходе к формированию методологии. Все проекты и команды разные, а лидеры — неповторимы. Подогнать одну методологию под всех не получится — таких просто нет. Придется брать конструктор и строить из него что-то свое, уникальное. В расшифровке одного из лучших докладов
TeamLead Conf не будет секретных тайн шаолиньских монахов — только банальности, проверенные опытом. Нас ждет каталог деталей методологии разработки, на что обращать внимание при ее конструировании и внедрении, правила перестраивания методологий. Для всех идей приведены реальные примеры из опыта Филиппа. За свою карьеру он попробовал все — от Visual Basic до хардкорного SQL, разрабатывал крупнейший в России букмекерский движок и Яндекс.Деньги, а сейчас работает над нагруженными проектами на Java. Регулярно делает доклады на разных конференциях, в том числе и на HighLoad++.