Это моя первая статья по теме Машинное обучение. С недавнего времени я профессионально занимаюсь машинным обучением и компьютерным зрением. В этой и будущих статьях я буду делиться наблюдениями и решениями специфических проблем при использовании TensorFlow и Keras. В этой статье я расскажу об одном неочевидном вопросе при работе с TensorFlow и Keras — одновременная загрузка и выполнение нескольких моделей. Если вы не знакомы с тем как работают TensorFlow и Keras внутри, эта тема может стать проблемой для начинающих. Если вас заинтересовала тема, прошу под кат.

Владислав @Gers1972
Аналитик данных
Python + Keras + LSTM: делаем переводчик текстов за полчаса
8 мин
Привет, Хабр.
В предыдущей части я рассматривал создание несложной распознавалки текста, основанной на нейронной сети. Сегодня мы применим аналогичный подход, и напишем автоматический переводчик текстов с английского на немецкий.

Для тех, кому интересно как это работает, подробности под катом.
В предыдущей части я рассматривал создание несложной распознавалки текста, основанной на нейронной сети. Сегодня мы применим аналогичный подход, и напишем автоматический переводчик текстов с английского на немецкий.
Для тех, кому интересно как это работает, подробности под катом.
Подготовка данных в Data Science-проекте: рецепты для молодых хозяек
10 мин

В предыдущей статье я рассказывала про структуру Data Science-проекта по материалам методологии IBM: как он устроен, из каких этапов состоит, какие задачи решаются на каждой стадии. Теперь я бы хотела сделать обзор самой трудоемкой стадии, которая может занимать до 90% общего времени проекта: это этапы, связанные с подготовкой данных -сбор, анализ и очистка.
В оригинальном описании методологии Data Science-проект сравнивается с приготовлением блюда, а аналитик - с шеф поваром. Соответственно, этап подготовки данных сравнивается с подготовкой продуктов: после того, как на этапе анализа бизнес-задачи мы определились с рецептом блюда, которое будем готовить, необходимо найти, собрать в одном месте, очистить и нарезать ингредиенты. Соответственно, от того, насколько качественно был выполнен этот этап, будет зависеть вкус блюда (предположим, что с рецептом мы угадали, тем более рецептов в открытом доступе полно). Работа с ингредиентами, то есть подготовка данных - это всегда ювелирное, трудоемкое и ответственное дело: один испорченный или недомытый продукт - и весь труд впустую.
Как работает метод Левенберга-Марквардта
8 мин
Алгоритм Левенберга-Марквардта прост. Алгоритм Левенберга-Марквардта эффективен.
А еще о нем говорят, что он где-то посередине между градиентным спуском и методом Ньютона, что бы это ни значило. Ну, с методом Ньютона и его связью с градиентным спуском вроде как разобрались. Но что имеют в виду когда произносят эту глубокомысленную фразу? Попробуем слегка подразобраться.
А еще о нем говорят, что он где-то посередине между градиентным спуском и методом Ньютона, что бы это ни значило. Ну, с методом Ньютона и его связью с градиентным спуском вроде как разобрались. Но что имеют в виду когда произносят эту глубокомысленную фразу? Попробуем слегка подразобраться.
Крадущийся тигр, затаившийся SQLAlchemy. Основы
8 мин

Доброго дня.
Сегодня хочу рассказать про ORM SQLAlchemy. Поговорим о том, что это, про его возможности и гибкость, а также рассмотрим случаи, которые не всегда понятно описаны.
Данная ORM имеет порог вхождения выше среднего, поэтому я попытаюсь объяснить всё простым языком и с примерами. Статья будет полезна тем, кто уже работает с sqlalchemy и хочет прокачать свои навыки или только знакомится с этой библиотекой.
Как я проработала 3 месяца в Я.Маркете и уволилась
6 мин
Первая попытка
Все началось с того, что я люблю ходить по конференциям и частенько хожу на них в Яндекс, Mail.ru и другие крупные компании. Однажды мне написал HR из Яндекса и попросила сделать тестовое на стажера фронтенд-разработчика.
Я его сделала, вот оно. По условию оно должно было работать на айфонах и андроидах, поэтому я проверила его в Browser Stack и дописала пару префиксов и css-стилей.
Через какое-то время поняла, что не хочу быть стажером, имея несколько лет опыта за плечами и зааплаилась в Я.Маркет через форму на их сайте.
Мне позвонила HR и предложила пройти скайп-интервью с лайвкодингом. Перед собеседованием я повторила структуры данных, сложность алгоритмов, сортировки. Тогда я еще не знала, что этого недостаточно.
На интервью я не смогла решить алгоритмические задачки, не знала внутренности JS и меня сбрили.
Это задело мою самооценку и весь следующий год параллельно с работой я учила JS на глубоком уровне и решала задачки на codewars. Здесь можно оценить мой прогресс.
Композитор с долгой кратковременной памятью
14 мин
Перевод
Автоматическое сочинение музыки

Почти сразу после того, как я научился программированию, мне хотелось создать ПО, способное сочинять музыку.
Я в течение нескольких лет предпринимал примитивные попытки автоматического сочинения музыки для Visions of Chaos. В основном при этом использовались простые математические формулы или генетические мутации случайных последовательностей нот. Добившись недавно скромного успеха в изучении и применении TensorFlow и нейронных сетей для поиска клеточных автоматов, я решил попробовать использовать нейронные сети для создания музыки.
Как это работает
Композитор обучает нейросеть с долгой кратковременной памятью (Long short-term memory, LSTM). LSTM-сети хорошо подходят для предсказания того, «что встретится дальше» в последовательностях данных. Подробнее о LSTM можно прочитать здесь.

LSTM-сеть получает различные последовательности нот (в данном случае это одноканальные файлы midi). После достаточного обучения она получает возможность создавать музыку, схожую с обучающими материалами.
Первые три дня жизни поста на Хабре
3 мин
Каждый автор переживает за жизнь своей публикации, после опубликования смотрит статистику, ждет и беспокоится за комментарии, желает, чтобы публикация набрала хотя бы среднее число просмотров. У Хабра эти инструменты кумулятивные и поэтому достаточно сложно представить, как публикация автора начинает свою жизнь на фоне других публикаций.
Как известно, основная масса публикаций набирает просмотры в первые три дня. Чтобы представить, как живет публикация, я отследил статистику и представил механизм мониторинга и сравнения. Данный механизм будет применен к этой публикации и все смогут посмотреть, как это работает.
Первым этапом была собрана статистика о динамике публикаций за три первых дня жизни поста. Для этого анализировал потоки читателей, по публикациям за 28 сентября в период их жизни с 28 сентября по 1 октября 2019 г. путем фиксирования количества просмотров через различные промежутки времени в этот период. Первая диаграмма представлена на рисунке ниже, она получена в результате согласования динамики просмотров по времени.
Как можно посчитать из диаграммы, среднее число просмотров публикации через 72 часа при степенной функции аппроксимации составит ориентировочно 8380 просмотров.
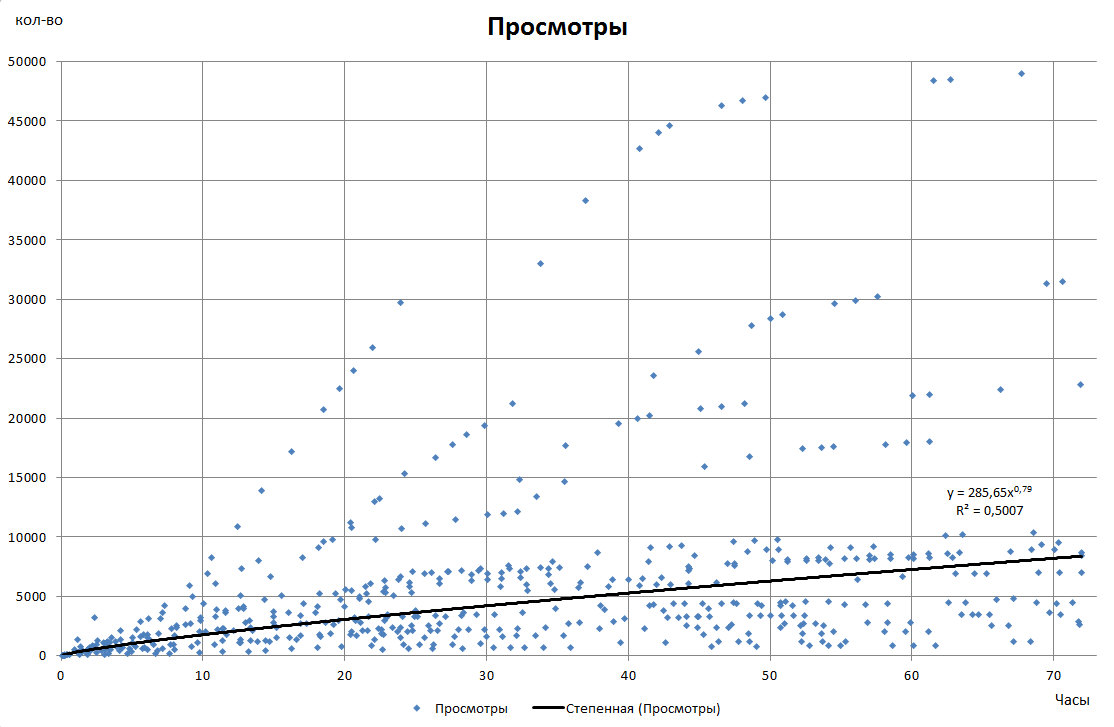
Рис. 1. Распределение просмотров по времени, для всех публикаций.
Как известно, основная масса публикаций набирает просмотры в первые три дня. Чтобы представить, как живет публикация, я отследил статистику и представил механизм мониторинга и сравнения. Данный механизм будет применен к этой публикации и все смогут посмотреть, как это работает.
Первым этапом была собрана статистика о динамике публикаций за три первых дня жизни поста. Для этого анализировал потоки читателей, по публикациям за 28 сентября в период их жизни с 28 сентября по 1 октября 2019 г. путем фиксирования количества просмотров через различные промежутки времени в этот период. Первая диаграмма представлена на рисунке ниже, она получена в результате согласования динамики просмотров по времени.
Как можно посчитать из диаграммы, среднее число просмотров публикации через 72 часа при степенной функции аппроксимации составит ориентировочно 8380 просмотров.
Рис. 1. Распределение просмотров по времени, для всех публикаций.
Дайджест новостей из мира PostgreSQL. Выпуск №17
10 мин

Мы продолжаем знакомить вас с самыми интересными новостями по PostgreSQL.
Главные новости
Релиз-кандидат PostgreSQL 12
В релизе-кандидате вся функциональность идентична грядущему официальному релизу. Если вновь выявленные и недоисправленные баги будут закрыты в срок, то официальный релиз выйдет 3 октября. По сравнению с PG 12 beta 4 исправлено несколько багов, в основном связанных с ECPG — SQL, встраиваемом в C. Релиз-кандидат доступен.
- Подробно о релизе здесь;
- а здесь изменения в PG относительно PG 11;
- нерешенные проблемы (Open Issues) PG 12;
- сообщить о найденном баге.
Погружение в свёрточные нейронные сети: передача обучения (transfer learning)
37 мин
Полный курс на русском языке можно найти по этой ссылке.
Оригинальный курс на английском доступен по этой ссылке.

Изменение климата: анализируем температуру в разных городах за последние 100 лет
4 мин
Туториал
Привет, Хабр.
Про изменение климата сейчас не говорит только ленивый. И случайно найдя неплохой сайт с историческими данными, стало интересно проверить — как же реально менялась температура с годами. Для теста мы возьмем данные с нескольких городов и проанализируем их с помощью Pandas и Matplotlib. Заодно выясним, действительно ли челябинские морозы настолько суровы, и где теплее, в Москве или Петербурге.

Также обнаружилось еще несколько любопытных закономерностей. Кому интересно узнать подробности, прошу под кат.
Про изменение климата сейчас не говорит только ленивый. И случайно найдя неплохой сайт с историческими данными, стало интересно проверить — как же реально менялась температура с годами. Для теста мы возьмем данные с нескольких городов и проанализируем их с помощью Pandas и Matplotlib. Заодно выясним, действительно ли челябинские морозы настолько суровы, и где теплее, в Москве или Петербурге.
Также обнаружилось еще несколько любопытных закономерностей. Кому интересно узнать подробности, прошу под кат.
Учим английский: как научиться разговаривать как носитель
4 мин
Перевод

Конечно, «прокачать» английский до уровня носителя языка очень нелегко, да и это просто не обязательно. Но никто не запрещает и стремиться к этому – например, с целью лучше адаптироваться после переезда в англоязычную страну или получения новых возможностей развития карьеры.
Но как это сделать? Я нашла интересный пост с описанием практических способов улучшения языка и подготовила его адаптированный перевод.
Типичные заблуждения об ООП
6 мин
Перевод
Привет, Хабр!
Сегодня вас ждет переводная публикация, в некоторой степени отражающая наши поиски, связанные с новыми книгами об ООП и ФП. Просим поучаствовать в голосовании.

Сегодня вас ждет переводная публикация, в некоторой степени отражающая наши поиски, связанные с новыми книгами об ООП и ФП. Просим поучаствовать в голосовании.
Нейросеть для классификации спутниковых снимков с помощью Tensorflow на Python
9 мин
Туториал
Перевод

Это пошаговая инструкция по классификации мультиспектральных снимков со спутника Landsat 5. Сегодня в ряде сфер глубокое обучение доминирует как инструмент для решения сложных проблем, в том числе геопространственных. Надеюсь, вы знакомы с датасетами спутниковых снимков, в частности, Landsat 5 TM. Если вы немного разбираетесь в работе алгоритмов машинного обучения, то это поможет вам быстро освоить это руководство. А для тех, кто не разбирается, будет достаточным знать, что, по сути, машинное обучение заключается в установлении взаимосвязей между несколькими характеристиками (набором признаков Х) объекта с другим его свойством (значением или меткой, — целевой переменной Y). Мы подаём на вход модели много объектов, для которых известны признаки и значение целевого показателя/класса объекта (размеченные данные) и обучаем ее так, чтобы она могла спрогнозировать значение целевой переменной Y для новых данных (неразмеченных).
Rutracker включил eSNI. Конец эпохи DPI и конец блокировок
4 мин
Несмотря на желтый заголовок, дальше будет не желтая статья. Всех нас (я надеюсь именно здесь я наконец-таки смогу сказать от всего сообщества) уже достали действия Роскомнадзора. А также его постоянное появление в рекомендованном на хабре. Поэтому эта новость вам понравится. Хоть что-то важное. Новость кстати еще от декабря 2018.
Git изнутри и на практике
11 мин
Умение работать внутри системы контроля версий — навык, который требуется каждому программисту. Зачастую может показаться, что закапываться в Git и разбираться в его внутренностях — лишняя потеря времени и основные задачи можно решить через базовый набор команд.
Команде AppsCast, конечно, захотелось узнать больше, и за консультацией по практическому применению всех возможностей Git ребята обратились к Егору Андреевичу из Square.
Команде AppsCast, конечно, захотелось узнать больше, и за консультацией по практическому применению всех возможностей Git ребята обратились к Егору Андреевичу из Square.
R пакет tidyr и его новые функции pivot_longer и pivot_wider
18 мин
Туториал
Пакет tidyr входит в ядро одной из наиболее популярных библиотек на языке R — tidyverse.
Основное назначение пакета — приведение данных к аккуратному виду.
На Хабре уже есть публикация посвящённая данному пакету, но датируюется она 2015 годом. А я хочу рассказать, о наиболее актуальных изменениях, о которых несколько дней назад сообщил его автор Хедли Викхем.
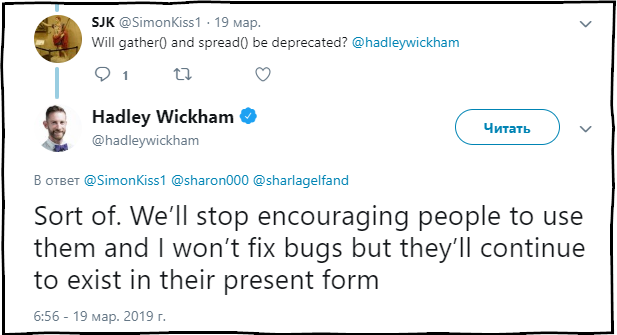
SJK: Функции gather() и spread() будут считаться устаревшими?
Hadley Wickham: В какой то мере. Мы перестанем рекомендовать использование данных функций, и исправлять в них ошибки, но они и далее буду присутствовать в пакете в текущем состоянии.
50 оттенков matplotlib — The Master Plots (с полным кодом на Python)
39 мин
Перевод
Те, кто работает с данными, отлично знают, что не в нейросетке счастье — а в том, как правильно обработать данные. Но чтобы их обработать, необходимо сначала проанализировать корреляции, выбрать нужные данные, выкинуть ненужные и так далее. Для подобных целей часто используется визуализация с помощью библиотеки matplotlib.

Встретимся «внутри»!
Встретимся «внутри»!
Must-have алгоритмы машинного обучения
5 мин
Перевод
Хабр, привет.
Меня зовут Рушан, и я автор Telegram‑канала Нейрон. Не забудьте поделиться с коллегами или просто с теми, кому интересны такие статьи. Этот пост — краткий обзор общих алгоритмов машинного обучения. К каждому прилагается краткое описание, гайды и полезные ссылки.
Это один из основных алгоритмов машинного обучения. Позволяет уменьшить размерность данных, потеряв наименьшее количество информации. Применяется во многих областях, таких как распознавание объектов, компьютерное зрение, сжатие данных и т. п. Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных или к сингулярному разложению матрицы данных.
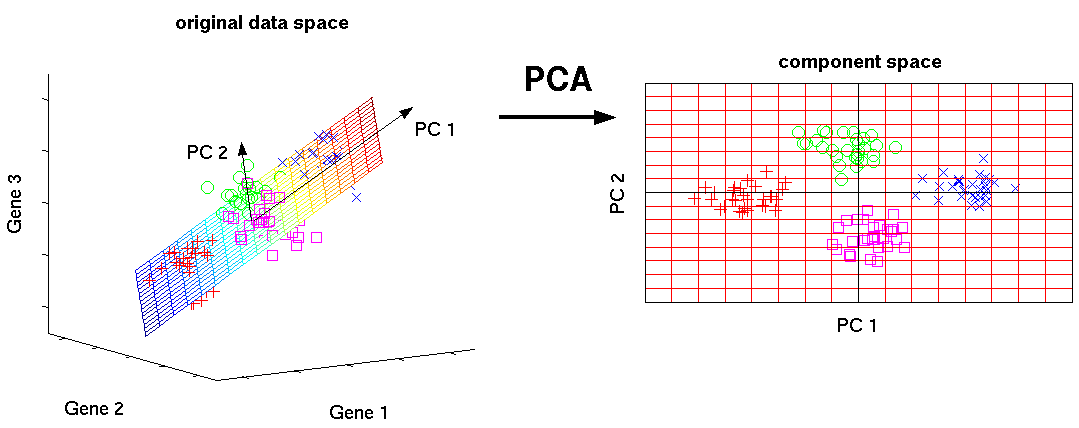
SVD — это способ вычисления упорядоченных компонентов.
Полезные ссылки:
Вводный гайд:
Меня зовут Рушан, и я автор Telegram‑канала Нейрон. Не забудьте поделиться с коллегами или просто с теми, кому интересны такие статьи. Этот пост — краткий обзор общих алгоритмов машинного обучения. К каждому прилагается краткое описание, гайды и полезные ссылки.
Метод главных компонент (PCA)/SVD
Это один из основных алгоритмов машинного обучения. Позволяет уменьшить размерность данных, потеряв наименьшее количество информации. Применяется во многих областях, таких как распознавание объектов, компьютерное зрение, сжатие данных и т. п. Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных или к сингулярному разложению матрицы данных.
SVD — это способ вычисления упорядоченных компонентов.
Полезные ссылки:
Вводный гайд:
Анализируем историю прослушивания в «Яндекс.Музыке»
3 мин
Вот уже почти год я пользуюсь сервисом Яндекс Музыка и меня все устраивает. Но есть в этом сервисе одна интересная страница — история. Она хранит все треки, которые были прослушаны, в хронологическом порядке. И мне, конечно, захотелось скачать ее и проанализировать, что я там наслушал за все время.
