
 Из всех известных мне технических и естественных наук, пожалуй, именно о биоинформатике представление у людей самое плохое. Оно либо в той или иной степени неверное, либо его нет совсем. Когда два года назад я начал заниматься бионформатикой, знаний об этой науке у меня самого не было ровным счетом никаких. Со временем я лучше стал представлять, какие задачи стоят перед биоинформатиками, чем они пользуются, и что может являться результатом их работы.
Из всех известных мне технических и естественных наук, пожалуй, именно о биоинформатике представление у людей самое плохое. Оно либо в той или иной степени неверное, либо его нет совсем. Когда два года назад я начал заниматься бионформатикой, знаний об этой науке у меня самого не было ровным счетом никаких. Со временем я лучше стал представлять, какие задачи стоят перед биоинформатиками, чем они пользуются, и что может являться результатом их работы.У биоинформатиков нет никаких пробирок, реагентов, бактерий, белых халатов. Главные инструменты у них – ноутбук, ручка с бумагой или белая доска с маркером – в общем, всё как у программистов. Да и сама работа очень сильно похожа на работу в IT компании, а лаборатория – на небольшой отдел разработки. А в чем же тогда отличия? Что ж, попробую ответить.


 Иногда возникает необходимость ускорить вычисления, причем желательно сразу в разы. При этом приходится отказываться от удобных, но медленных инструментов и прибегать к чему-то более низкоуровневому и быстрому. R имеет довольно развитые возможности для работы с динамическими бибиотеками, написанными на С/С++, Fortran или даже Java. Я по привычке предпочитаю С/С++.
Иногда возникает необходимость ускорить вычисления, причем желательно сразу в разы. При этом приходится отказываться от удобных, но медленных инструментов и прибегать к чему-то более низкоуровневому и быстрому. R имеет довольно развитые возможности для работы с динамическими бибиотеками, написанными на С/С++, Fortran или даже Java. Я по привычке предпочитаю С/С++.


 В последнее время на слуху феномен «муков» (MOOC) – массовых открытых онлайн курсов. Платформ для них создано большое множество.
В последнее время на слуху феномен «муков» (MOOC) – массовых открытых онлайн курсов. Платформ для них создано большое множество. 
 После завершения разработки под OS X может остаться ощущение незавершенности — для полного счастья хотелось бы видеть свое приложение в каталоге, тем более, что это, пожалуй, лучшая площадка для продажи десктопных приложений. На эту тему есть
После завершения разработки под OS X может остаться ощущение незавершенности — для полного счастья хотелось бы видеть свое приложение в каталоге, тем более, что это, пожалуй, лучшая площадка для продажи десктопных приложений. На эту тему есть 
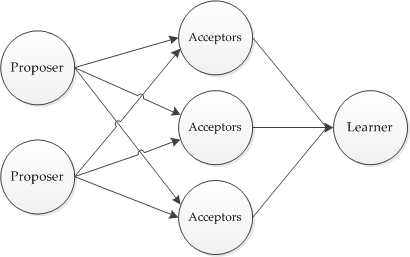
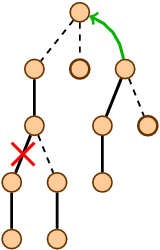 Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы.
Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы. 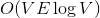 и
и 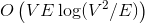 соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.
соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.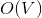 памяти и
памяти и 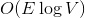 времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.
времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.