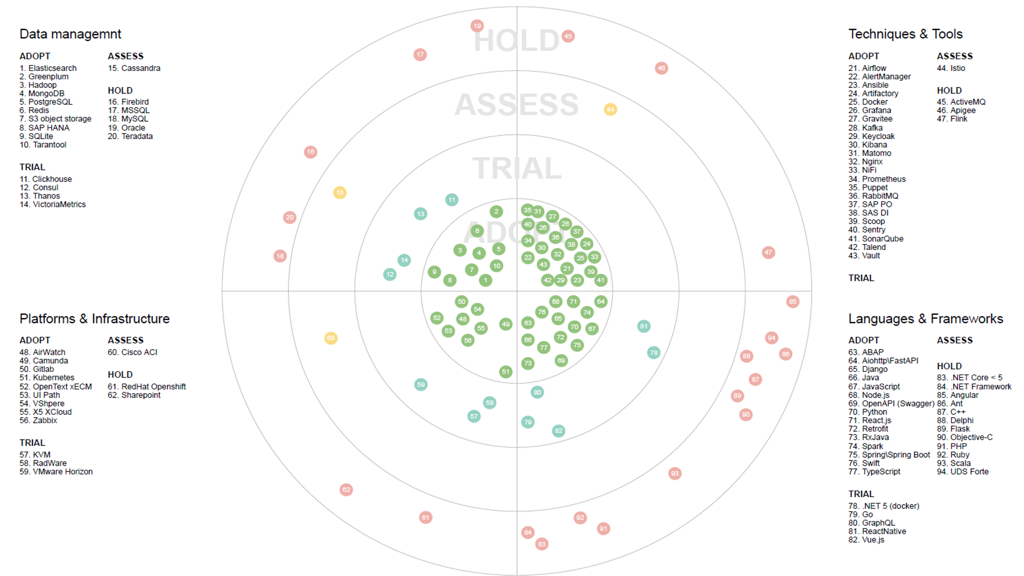
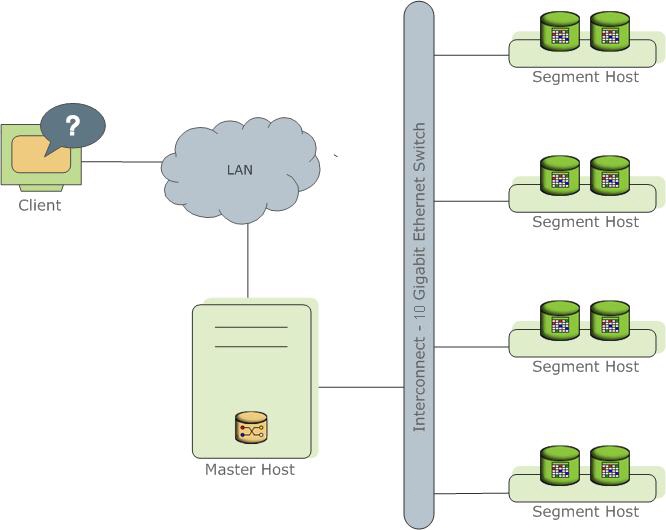
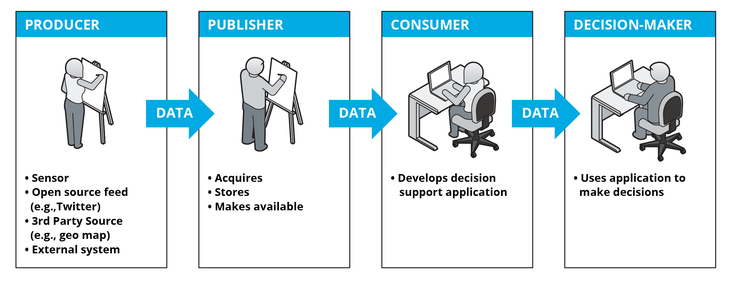
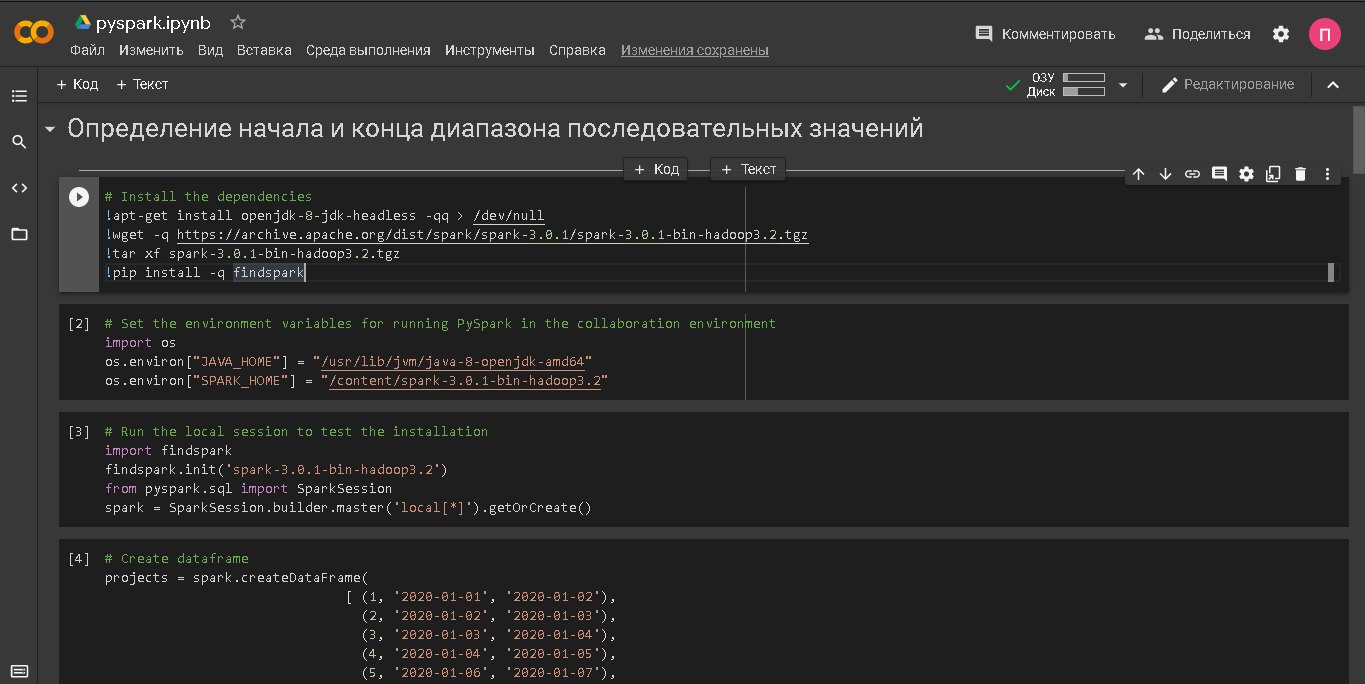
Всем привет! Сегодня хотим затронуть тему облачных технологий. Дмитрий Морозов, архитектор DWH в компании GlowByte, занимается хранилищами данных 6 лет, последние 2,5 года участвует в проектах, использующих облака. В этой статье он сделает обзор облачных решений, которые могут быть полезны для задач хранения больших данных, а также уделит внимание вопросам выбора облачного хранилища. Статья основана на личном опыте, может быть интересна как разработчикам, дата-инженерам, так и менеджерам, отвечающим за корпоративную Big Data-инфраструктуру и ищущим возможности ее масштабировать.