
TL;DR написал актуальную на момент августа 2023 года заметку про необходимых для нормального администрирования групп ботов. Желательно бесплатных.

User
TL;DR написал актуальную на момент августа 2023 года заметку про необходимых для нормального администрирования групп ботов. Желательно бесплатных.

Начало года – это время подводить финансовые итоги, планировать личный бюджет на следующий год и заранее предусмотреть все возможные дополнительные способы его пополнения. Один из таких способов – вернуть часть уплаченного НДФЛ за прошлые периоды.
Если за последние три года у вас были крупные (или не очень) траты на покупку недвижимости, образование, медицину, спорт или просто есть дети, пришла пора обращаться за вычетом.
Я Оксана, эксперт по расчетам с персоналом в IT-компании SimbirSoft, в этой статье постараюсь доказать, что получить налоговый вычет не так сложно, как кажется на первый взгляд, а суммы этих вычетов достаточно существенные, чтобы их упускать.

Привет, Хабр! Меня зовут Александр, я работаю frontend-разработчиком в Т-Банке. В этой статье я расскажу о UX (User Experience) на основе MUI (Material User Interface): исследую интересные практики и покажу, какие элементы UI можно использовать, чтобы улучшить UX.
Статья — выжимка из документации MUI по их принципам дизайна. Обратите внимание, что в статье нет акцента на особенностях UX, присущих MUI, но выделена полезная информация, которую можно использовать вне рамок MUI:
• поверхности;
• раскладка;
• сжатие;
• цвета;
• темная тема;
• показ ошибок.

Все уже слышали про новую модель deepseek r1, которая обогнала по бенчмаркам openai. Компания Deepseek выложила веса и дистилляты в открытый доступ, благодаря чему мы можем их запустить.
В статье поднимем дистилляты модели r1 используя llama.cpp - потребуются лишь базовые умения работы с bash, docker и python. Самостоятельный запуск проще простого.

Многие говорят о DeepSeek R-1 - новой языковой ИИ-модели с открытым исходным кодом, созданной китайской ИИ-компанией DeepSeek. Некоторые пользователи утверждают, что по возможностям рассуждения она не уступает или даже превосходит модель o1 от OpenAI.
В настоящее время DeepSeek можно использовать бесплатно, что является отличной новостью для пользователей, но вызывает некоторые вопросы. Как при таком резком росте числа пользователей они справляются с затратами на сервера?
Ведь эксплуатационные расходы на оборудование не могут быть дешевыми, верно?
Единственный логичный ответ здесь - данные. Данные - это жизненная сила ИИ-моделей. Вероятно, они собирают данные о пользователях, чтобы использовать их в своей модели квантовой торговли или для другой формы монетизации.
Поэтому, если вы беспокоитесь о конфиденциальности данных, но при этом хотите использовать R1, не предоставляя свои данные, лучший способ - запустить модель локально.



Всем привет, сегодня речь пойдет про Android TV. Мне обход именно на телевизоре показался самым проблемным и сложным. Так как дома имеется несколько лишенных ютуба телевизоров, а еще больше ожидают настройки у друзей и знакомых - решил собрать все найденные способы обхода блокировки.

О том, как сделать прозрачную синхронизацию заметок Obsidian между устройствами (Desktop, Android, iOS) через GitHub:
1. Без сторонних приложений (вроде iCloud, SyncThing, Termux и пр)
2. Бесплатно
3. Бонусом — резервная копия: как самих заметок, так и истории изменений.
В результате получается полноценная замена Notion: структурированные заметки с автоматической синхронизацией между устройствами.
В последнее время для потребителей контента YouTube настали тяжелые времена. Даже самые мелкие местечковые провайдеры уже внедрили то самое замедление видео. В некоторых случаях (как у меня) - это даже не замедление, а просто ограничение функционала. Видео попросту не грузятся.
Оставим в стороне сам факт блокировки - он небезоснователен. Но количество полезной информации, которой было накоплено на сайте за годы его, по сути, монопольного владения данной нишей - колоссальное. Поэтому, как бы там не было, приходится данную блокировку обходить.
Для этого есть несколько путей:
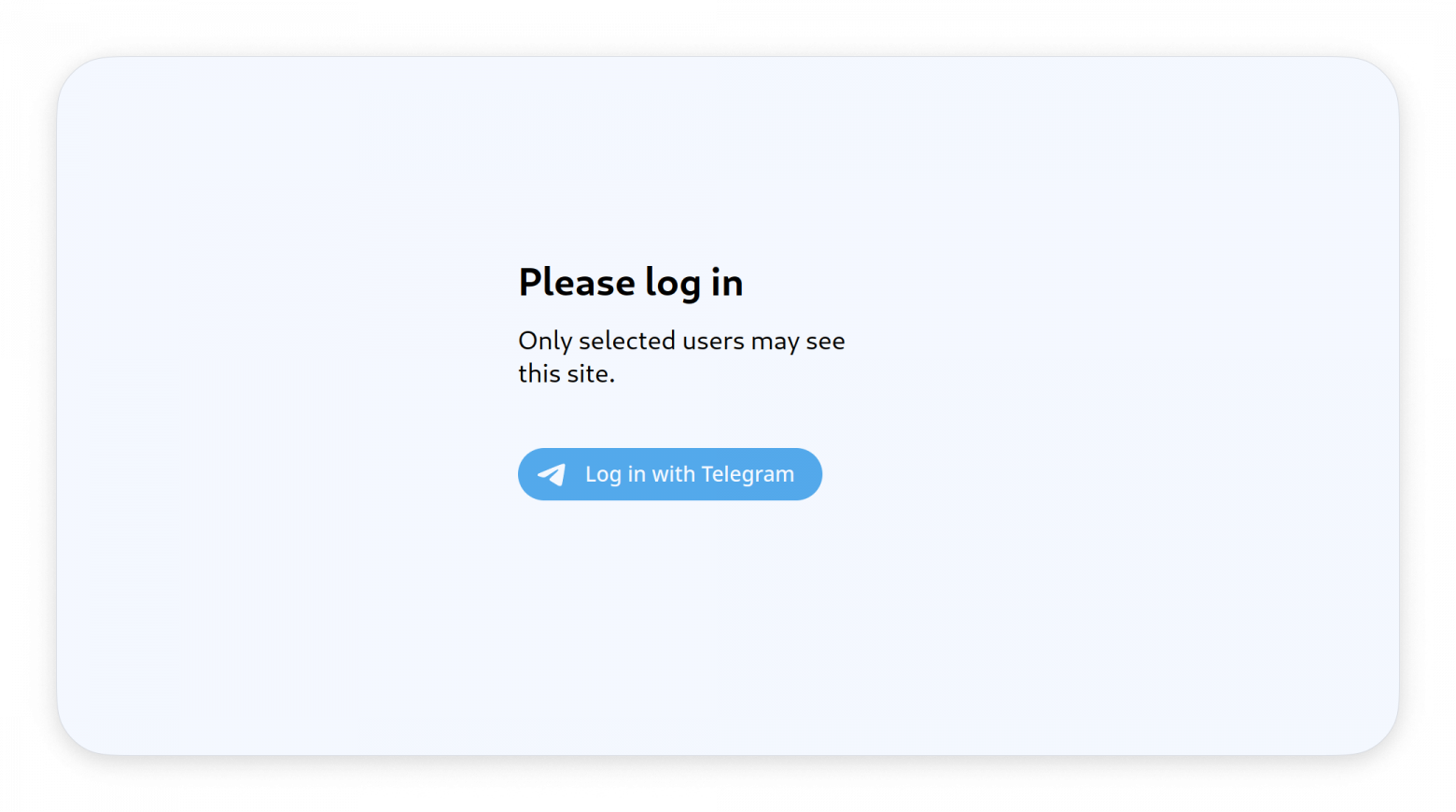
Как-то мне понадобилось ограничить доступ к статическому сайту. Я написал сервер, который просит пользователей войти через Телеграм и пропускает только людей из белого списка. Ничего сложного, но вдруг кому-то понадобится.

Определение понятия "рефлексия" из Википедии:
In computer science, reflective programming or reflection is the ability of a process to examine, introspect, and modify its own structure and behavior.
В последние годы разрабатываются варианты ввода рефлексии в стандарт C++.
В этой статье мы напишем код на C++ с рефлексией для решения разных задач, скомпилируем и запустим его на форке компилятора с рабочей реализацией рефлексии.

Многие из вас сталкивались со Stable Diffusion и знают, что с помощью этой нейросети можно генерировать разнообразные изображения. Однако не всем интересно создавать случайные картинки с кошкодевочками, пускай даже и красивыми, и всем прочим. Согласитесь, было бы гораздо интереснее, если бы можно было обучить нейросеть создавать изображения... нас самих? Или наших любимых актёров и музыкантов? Или наших почивших родственников? Конкретных людей, в общем, а не какие-то собирательные образы из того, что было заложено при обучении нейросети. И для достижения этой цели нам потребуется обучить некую модель. Этим мы и займёмся, пытаясь определить наиболее оптимальный воркфлоу и максимально его автоматизировать.
Библиотека Transformers предоставляет доступ к огромному кол-ву современных предобученных моделей глубокого обучения. В основном основаных на архитектуре трансформеров. Модели решают весьма разнообразный спектр задач: NLP, CV, Audio, Multimodal, Reinforcement Learning, Time Series.
В этой статье пройдемся по основным ее возможностям и попробуем их на практике.
ТК LLM is all you need | ТК Private Sharing | Курс: Алгоритмы Машинного обучения с нуля
 Иногда возникают такие ситуации, когда нужно прочитать QR код, а смартфона под рукой нет. Что же делать? В голову приходит лишь попробовать прочитать вручную. Если кто-нибудь сталкивался с такими ситуациями или кому просто интересно как же читается QR код машинами, то данная статья поможет вам разобраться в этой проблеме.
Иногда возникают такие ситуации, когда нужно прочитать QR код, а смартфона под рукой нет. Что же делать? В голову приходит лишь попробовать прочитать вручную. Если кто-нибудь сталкивался с такими ситуациями или кому просто интересно как же читается QR код машинами, то данная статья поможет вам разобраться в этой проблеме. 

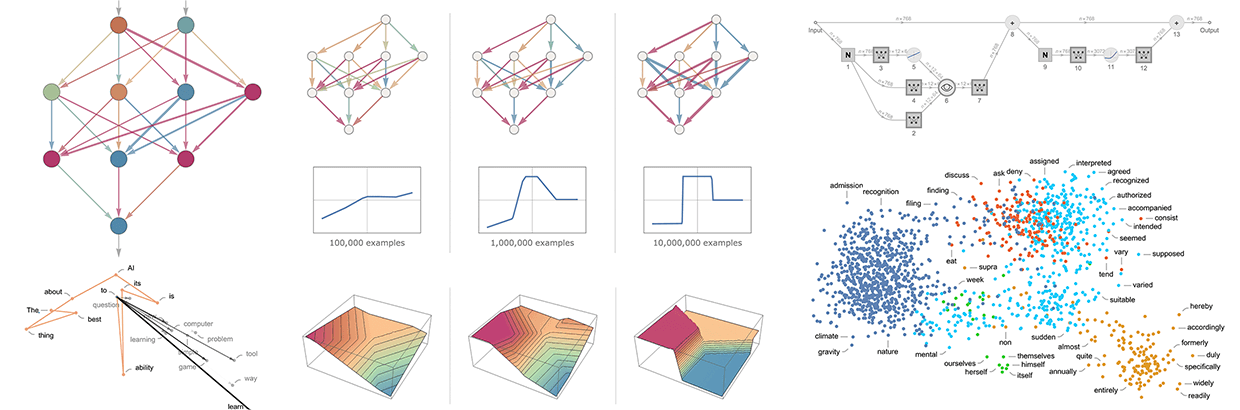
То, что ChatGPT может автоматически генерировать что-то, что хотя бы на первый взгляд похоже на написанный человеком текст, удивительно и неожиданно. Но как он это делает? И почему это работает? Цель этой статьи - дать приблизительное описание того, что происходит внутри ChatGPT, а затем исследовать, почему он может так хорошо справляться с созданием более-менее осмысленного текста. С самого начала я должен сказать, что собираюсь сосредоточиться на общей картине происходящего, и хотя я упомяну некоторые инженерные детали, но не буду глубоко в них вникать. (Примеры в статье применимы как к другим современным "большим языковым моделям" (LLM), так и к ChatGPT).

Участники открытого сообщества LAION-AI выпустили в открытый доступ первые обученные модели OA_SFT_Llama_30B и OA_SFT_Llama_13B. и запустили ИИ-чатбот OpenAssistant на их основе. На текущий момент доступны модели в 13 и 30 млрд параметров, дообученные на мультиязычных датасетах, собранных сообществом. В основе моделей лежит уже успевшая стать популярной LLaMA.
OpenAssistant - это диалоговый помощник на базе ИИ, который понимает задачи, может взаимодействовать со сторонними системами (подобно плагинам в ChatGPT) и динамически извлекать информацию из них. OpenAssistant позиционируется как открытая альтернатива ChatGPT.
"Мы хотим, чтобы OpenAssistant стал единой, объединяющей платформой, которую все другие системы используют для взаимодействия с людьми." - декларируют своё видение члены сообщества LAION.
Вы можете попробовать поговорить с OpenAssistant уже сейчаст тут.
Еще вы можете принять участие в формировании датасета на своём языке тут.

Идея этой статьи с сантехническим уклоном у меня возникла после просмотра в Ютубе видеоролика о монтаже нового секционного биметаллического радиатора при замене старого отопительного прибора типа «гармошка» в старой однотрубной системе отопления, которую с советских времён применяют в подавляющем количестве панельных домов.
В этом видосике сошлись в смертельной схватке два «блогера‑сантехника», каждый из которых считал, что только он прав.
По результатом этой баталии у меня возникли альтернативные решения, не совпадающие полностью ни с одним из дуэлянтов.
Своё видение решения я описал в комментариях к видеоролику, но ответа не получил. В итоге решил написать эту статью для прояснения сути проблемы широкой массе жителей панельных домов.
Особый интерес к этой теме у меня возник потому, что я сам лично как‑то собрался поменять такую старую облезлую «гармошку» (см.рис.1) на новый белый и красивы биметаллический радиатор (см.рис.2).