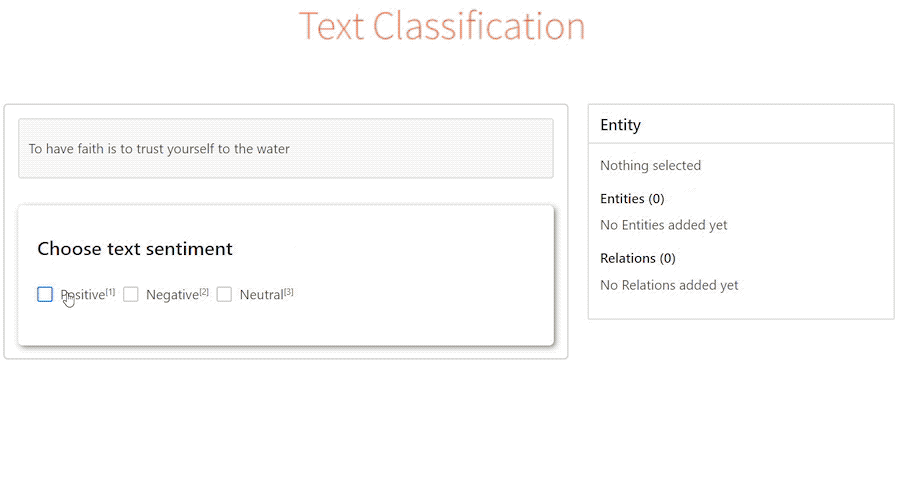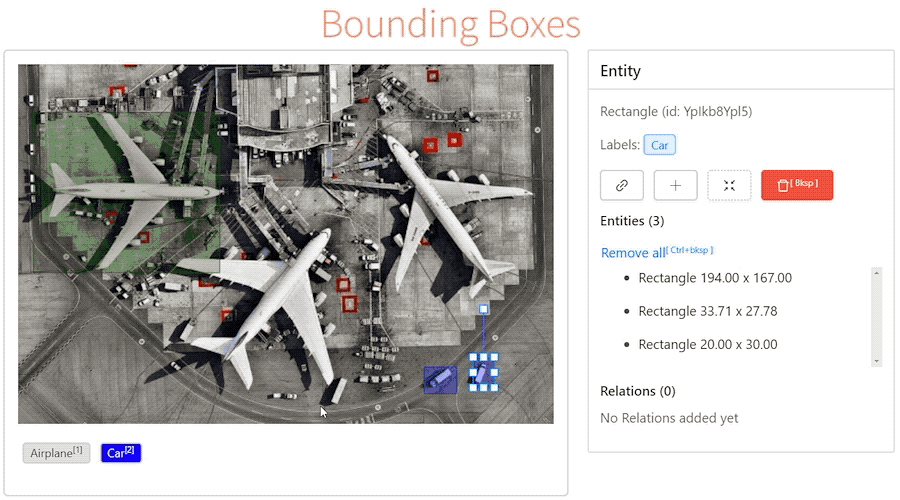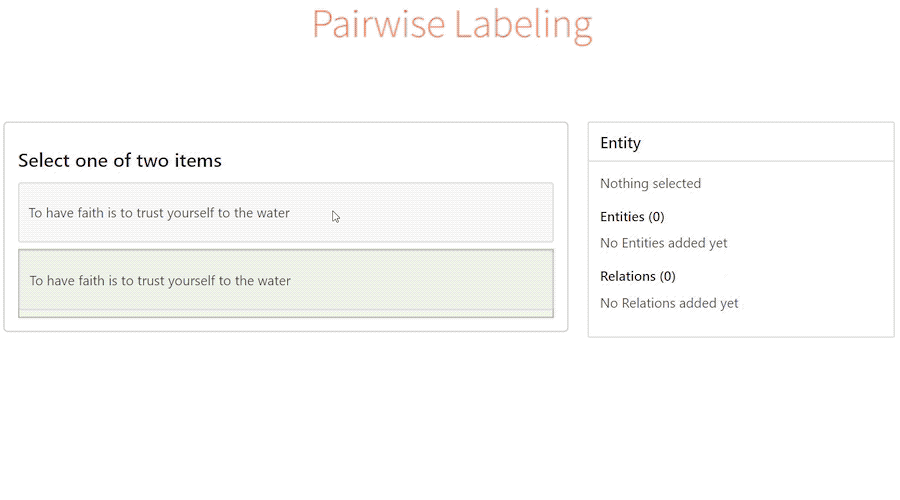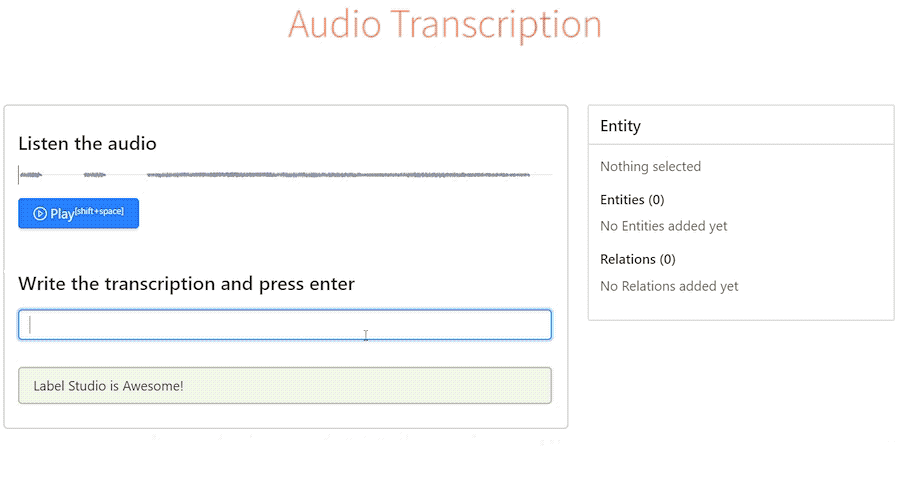
Рано или поздно перед любой компанией которая хочет внедрить системы машинного обучения в свою инфрастуктуру встает вопрос разметки данных. Чистые данные в достаточно большом количестве - залог хорошей модели, все мы прекрасно знаем правило "Garbage in - garbage out". Такой вопрос недавно встал и передо мной. В этом посте я поделюсь своим опытом поиска инструментов для разметки текста и звука под in-house разметчиков, постараюсь описать их плюсы и минусы, а в конце расскажу на чем мы в итоге остановились и что из этого вышло. Задачи на данном этапе относительно стандартные для NLP: классификация, NER, потенциально также может понадобиться entity-linking и разметка аудио под задачи ASR, но это пока менее приоритетно. Инструмент в идеале нужен open-source, но если будет приемлимый ценник за какие-то нужные фичи - мы готовы заплатить.
Заранее скажу, что этот пост никем не спонсировался, а все написанное ниже является сугубым ИМХО. Также имейте ввиду, что впечатления об использовании различных инструментов были составлены на момент написания статьи - осень-зима 2021-го года. Если вы смотрите на эти инструменты сильно позднее - возможно, информация будет уже не актуальной. Ну а теперь, поехали!
Сегодня я хотел бы рассказать про свой домашний сервер: какие ошибки допустил, на какой конфигурации сейчас остановился, да и вообще — зачем я это делал.
Как я пришел к покупке приточной вентиляции для квартиры с готовым ремонтом. Как купил ее за 150к и чуть не потратил деньги зря. Статья будет полезна тем, кто планирует купить очиститель воздуха, бризер или приточку.
В этой серии из двух статей говорится о том, как структура данных и памяти влияет на производительность. Предлагаются определенные действия для повышения производительности программного обеспечения. Даже простейшие действия, показанные в этих статьях, позволят добиться существенного прироста производительности. Многие статьи, посвященные оптимизации производительности программ, рассматривают распараллеливание нагрузки в следующих областях: распределенная память (например, MPI), общая память или набор команд SIMD (векторизация), но на самом деле распараллеливание необходимо применять во всех трех областях. Эти элементы очень важны, но память также важна, а про нее часто забывают. Изменения архитектуры программ и применение параллельной обработки влияют на память и на производительность.
Область, в которой мне повезло работать, называется вычислительная электрофизиология сердца. Физиология сердечной деятельности определяется электрическими процессами, происходящими на уровне отдельных клеток миокарда. Эти электрические процессы создают электрическое поле, которое достаточно легко измерить. Более того оно очень неплохо описывается в рамках математических моделей электростатики. Тут и возникает уникальная возможность строго математически описать работу сердца, а значит — и усовершенствовать методы лечения многих сердечных заболеваний.
За время работы в этой области у меня накопился некоторый опыт использования различных вычислительных технологий. На некоторые вопросы, которые могут быть интересны не только мне, я постараюсь отвечать в рамках этой публикации.