Каждый программист — проектировщик API. Хорошие программы состоят из модулей, а протокол взаимодействия модулей — это тоже API. Хорошие модули используются повторно.
API — это большая сила и большая ответственность. У хорошего API будут благодарные пользователи; поддержка плохого превратится в кошмар.
Публичный API — не воробей, опубликуешь — не уберешь. Есть только одна попытка сделать все правильно, поэтому постарайся.
API должно быть легко использовать, но сложно использовать неправильно. Сделать что-то простое с помощью такого API должно быть просто; сложное — возможно; сделать что-то неправильно должно быть невозможно, или, по крайней мере, трудно.
API должен описывать сам себя. Изучение кода на таком API не вызывает желания читать комментарии. Вообще, комментарии редко нужны.
Перед разработкой API собери требования с долей здорового скептицизма. Осознай общие задачи и реши их.
Оформляй требования как шаблоны использования API. Сверяйся с ними в процессе проектирования.
API — это большая сила и большая ответственность. У хорошего API будут благодарные пользователи; поддержка плохого превратится в кошмар.
Публичный API — не воробей, опубликуешь — не уберешь. Есть только одна попытка сделать все правильно, поэтому постарайся.
API должно быть легко использовать, но сложно использовать неправильно. Сделать что-то простое с помощью такого API должно быть просто; сложное — возможно; сделать что-то неправильно должно быть невозможно, или, по крайней мере, трудно.
API должен описывать сам себя. Изучение кода на таком API не вызывает желания читать комментарии. Вообще, комментарии редко нужны.
Перед разработкой API собери требования с долей здорового скептицизма. Осознай общие задачи и реши их.
Оформляй требования как шаблоны использования API. Сверяйся с ними в процессе проектирования.

 Частенько читаю Хабр и заметил что в последнее время появились Дайджесты новостей по многим тематикам, таким как веб-разработка на php, разработка на Python, мобильные приложения, но не встретил ни одного подборки по популярному сейчас направлению, а именно анализу данных и big data.
Частенько читаю Хабр и заметил что в последнее время появились Дайджесты новостей по многим тематикам, таким как веб-разработка на php, разработка на Python, мобильные приложения, но не встретил ни одного подборки по популярному сейчас направлению, а именно анализу данных и big data. 






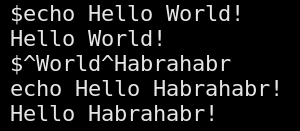 В данном посте я расскажу о наиболее интересных командах, которые могут быть очень полезны при работе в консоли. Однозначных критериев определения какая команда лучше другой — нет, каждый сам для своих условий выбирает лучшее. Я решил построить список команд на основе наиболее рейтинговых приемов работы с консолью от commandlinefu.com, кладовой консольных команд. Результат выполнения одной из таких команд под Linux приведен на картинке. Если заинтересовало, прошу под кат.
В данном посте я расскажу о наиболее интересных командах, которые могут быть очень полезны при работе в консоли. Однозначных критериев определения какая команда лучше другой — нет, каждый сам для своих условий выбирает лучшее. Я решил построить список команд на основе наиболее рейтинговых приемов работы с консолью от commandlinefu.com, кладовой консольных команд. Результат выполнения одной из таких команд под Linux приведен на картинке. Если заинтересовало, прошу под кат.