Несколько лет назад было опубликовано интервью, в котором говорят об искусственном интеллекте и, в частности, о чат-ботах. Респондент подчеркивает, что чат-боты не общаются, а имитирует общение.
В них заложено ядро разумных микродиалогов вполне человеческого уровня и построен коммуникативный алгоритм постоянного сведения разговора к этому ядру. Только и всего.На мой взгляд, в этом что-то есть…
Тем не менее, о чат-ботах много говорят на Хабре. Они могут быть самые разные. Популярностью пользуются боты на базе нейронных сетей прогнозирования, которые генерируют ответ пословно. Это очень интересно, но затратно с точки зрения реализации, особенно для русского языка из-за большого количества словоформ. Мной был выбран другой подход для реализации чат-бота Boltoon.


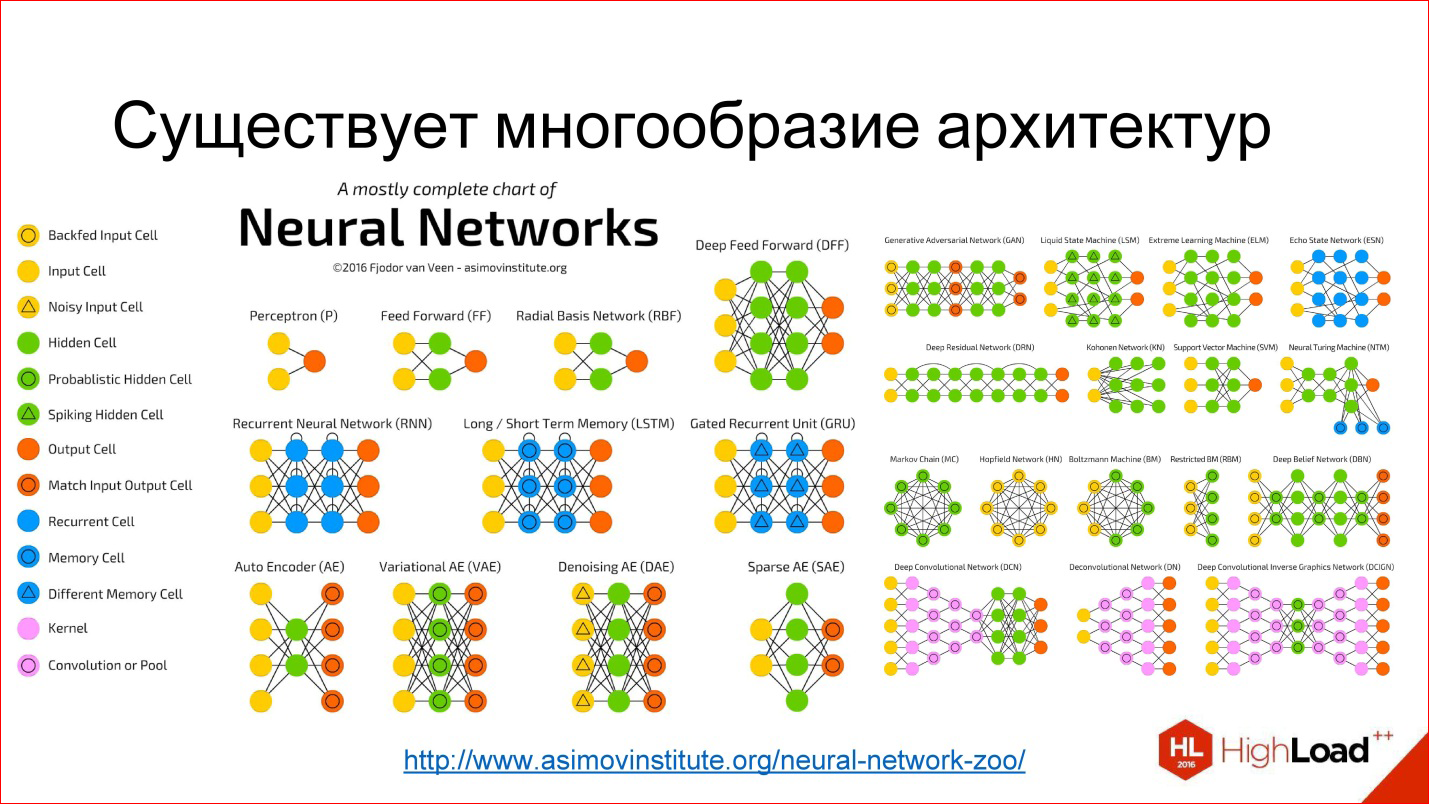






 Самая простая сеть нашлась в статье "
Самая простая сеть нашлась в статье "