Объекты, классы, конструкторы
ECMAScript, будучи высоко-абстрактным объектно-ориентированным языком программирования, оперирует объектами. Существуют также и примитивы, но и они, когда требуется, также преобразуются в объекты. Объект — это коллекция свойств, имеющая также связанный с ней объект-прототип. Прототипом является либо также объект, или же значение null.
В JavaScript нет привычных классов, но есть функции-конструкторы, порождающие объекты по определенным алгоритмам (см. Оператор new).
Прототипное делегирующее наследование
Классическое наследование очень похоже на то, как люди наследуют гены своих предков. Есть какие-то базовые особенности: люди могут ходить, говорить… И есть характерные черты для для каждого человека. Люди не в состоянии изменить себя — свой класс (но могут поменять собственные свойства) и бабушки, дедушки, мамы и папы не могут динамически повлиять на гены детей и внуков. Все очень по земному.
Теперь представим другую планету, на которой не такое как на Земле генное наследование. Там обитают мутанты с «телепатическим наследованием», которые способны изменять гены своих потомков.
Разберем пример. Отец наследует гены от Дедушки, а Сын наследует гены от Отца, который наследует от Дедушки. Каждый мутант может свободно мутировать, и может менять гены своих потомков. Например у Дедушки был зеленый цвет кожи, Отец цвет унаследовал, Сын тоже унаследовал цвет. И вдруг Дед решил: «надоело мне ходить зеленым — хочу стать сними», смутировал (изменил прототип своего класса) и «телепатически» распространил эту мутацию Отцу и Сыну, вобщем посинели все. Тут Отец подумал: «Дед на старости лет совсем двинулся» и поменял свой цвет в генах обратно на зеленый(изменил прототип своего класса), и распространил «телепатически» свой цвет сыну. Отец и Сын зеленые, Дед синий. Теперь как бы дед ни старался Отец и сын цвет не поменяют, т.к сейчас Отец в своем прототипе прописал цвет, а Сын в первую очередь унаследует от Прототипа Отца. Теперь Сын решает: «Поменяю ка я свой цвет на черный, а моё потомство пусть наследует цвет от Отца» и прописал собственное свойство, которое не влияет на потомство. И так далее.

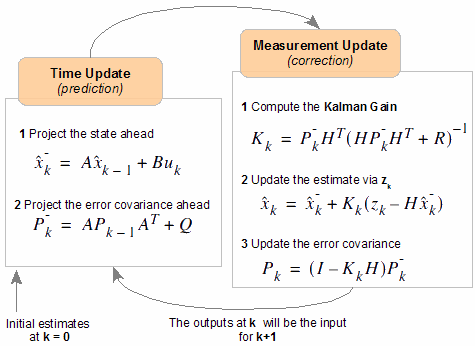 Недавно прочитал пост из «Дополненной реальности», в котором упоминается Фильтр Калмана в сравнении с более простым «альфа-бета» фильтром. Давно собирался сочинить нечто вроде сниппета по составлению ФК, и вот думаю самое время. В статье я вам расскажу как на практике можно составить расширенный ФК не особо утруждая себя высоконаучными размышлениями и глубокими теоретическими изысканиями.
Недавно прочитал пост из «Дополненной реальности», в котором упоминается Фильтр Калмана в сравнении с более простым «альфа-бета» фильтром. Давно собирался сочинить нечто вроде сниппета по составлению ФК, и вот думаю самое время. В статье я вам расскажу как на практике можно составить расширенный ФК не особо утруждая себя высоконаучными размышлениями и глубокими теоретическими изысканиями.

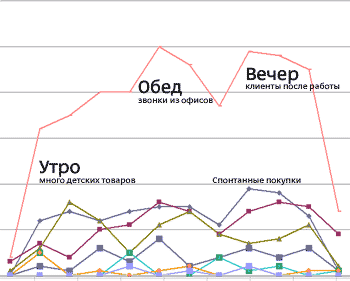 Интернет-магазин достаточно легко анализируется в плане статистки посещамости и действий пользователя. Чтобы посмотреть, что же делает клиент, всегда есть Яндекс.Метрика и Гугл-Аналитика, которые помогают выкопать подготную, есть сервисы мыштрекинга и айтрекинга, есть собственные скрипты, которые учитывают пути движения клиентов по сайту и вообще «держат их за руку».
Интернет-магазин достаточно легко анализируется в плане статистки посещамости и действий пользователя. Чтобы посмотреть, что же делает клиент, всегда есть Яндекс.Метрика и Гугл-Аналитика, которые помогают выкопать подготную, есть сервисы мыштрекинга и айтрекинга, есть собственные скрипты, которые учитывают пути движения клиентов по сайту и вообще «держат их за руку».