Пока пара новых статей на технические темы еще в процессе написания, я решил опубликовать небольшой лингвистический материал. Достаточно часто замечаю, что коллеги, у которых английский язык — не родной, неправильно произносят некоторые характерные для IT сферы слова. И дело здесь не в том, насколько аутентично произносятся отдельные звуки, а именно в транскрипции. Регулярно встречал ситуации при общении с носителями, когда неправильно произносимое слово приводило к недопониманиям.
Дальше я приведу несколько наборов слов, сгруппированных по типовым ошибкам. К каждому слову будет приложена транскрипция, приблизительная транскрипция на русском и ссылка на более детальную информацию в словаре. Так как большинство IT компаний все-таки работает с Северной Америкой, то транскрипции будут из US English.
Около года назад разработчики PyTorch представили сообществу TorchScript — инструмент, который позволяет с помощью пары строк кода и нескольких щелчков мыши сделать из пайплайна на питоне отчуждаемое решение, которое можно встроить в систему на C++. Ниже я делюсь опытом его использования и постараюсь описать встречающиеся на этом пути подводные камни. Особенное внимание уделю реализации проекта на Windows, поскольку, хотя исследования в ML обычно делаются на Ubuntu, конечное решение часто (внезапно!) требуется под "окошками".
Примеры кода для экспорта модели и проекта на C++, использующего модель, можно найти в репозиториии на GitHub.
Как в сравнительно короткие сроки написать компилятор какого-либо языка программирования. Для этого следует воспользоваться средствами разработки, автоматизирующие процесс. Я хотел бы рассказать о том, как я писал компилятор языка программирования MiniJava под платформу .NET Framework.
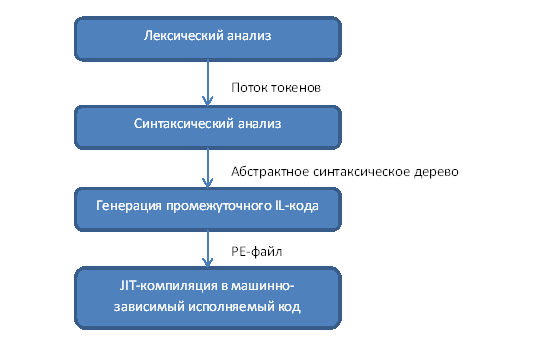
Весь процесс написания компилятора в целом отображён на следующем изображении. На вход подаётся файл с исходным кодом на языке программирования MiniJava. Выходом является PE-файл для выполнения средой CLR.
Далее я хотел бы сконцентрироваться на практической части описания.
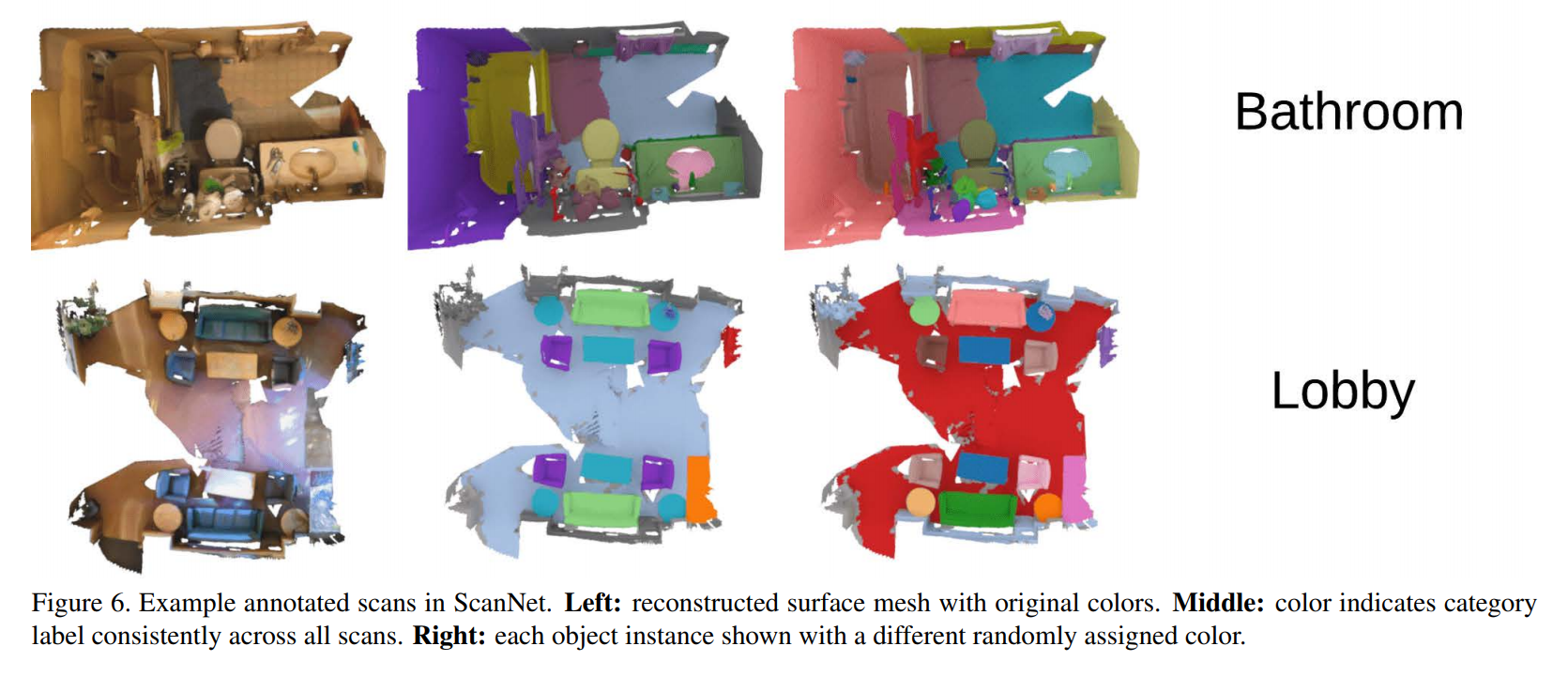
Некоторое время назад мне потребовалось решить задачу сегментации точек в Point Cloud (облака точек — данные, полученные с лидаров).
Пример данных и решаемой задачи:
Поиски общего обзора существующих методов оказались неуспешными, поэтому пришлось собирать информацию самостоятельно. Результат вы можете видеть: здесь собраны наиболее важные и интересные (по моему мнению) статьи за последние несколько лет. Все рассмотренные модели решают задачу сегментации облака точек (к какому классу принадлежит каждая точка).
Эта статья будет полезна тем, кто хорошо знаком с нейронными сетями и хочет понять, как применять их к неструктурированным данным (к примеру графам).
Меня зовут Рушан, и я автор Telegram‑канала Нейрон. Не забудьте поделиться с коллегами или просто с теми, кому интересны такие статьи.
Перед тобой статья-путеводитель по открытым наборам данных для машинного обучения. В ней я, для начала, соберу подборку интересных и свежих (относительно) датасетов. А бонусом, в конце статьи, прикреплю полезные ссылки по самостоятельному поиску датасетов.