
Сразу скажу, что сайт будет быстрее работать, если заменить Bootstrap на чистый CSS и JS. Эта статья про то, как быстро начать разрабатывать красивые web-приложения, а оптимизация это уже отдельный вопрос, выходящий за пределы этой статьи.
Для начала надо хотя бы немного разбираться в HTML, CSS, JavaScript, XML, DOM, ООП и уметь работать в терминале (командной строке).
В этой статье сделаю выжимку минимально необходимого для работы и сделаем такой таймер:
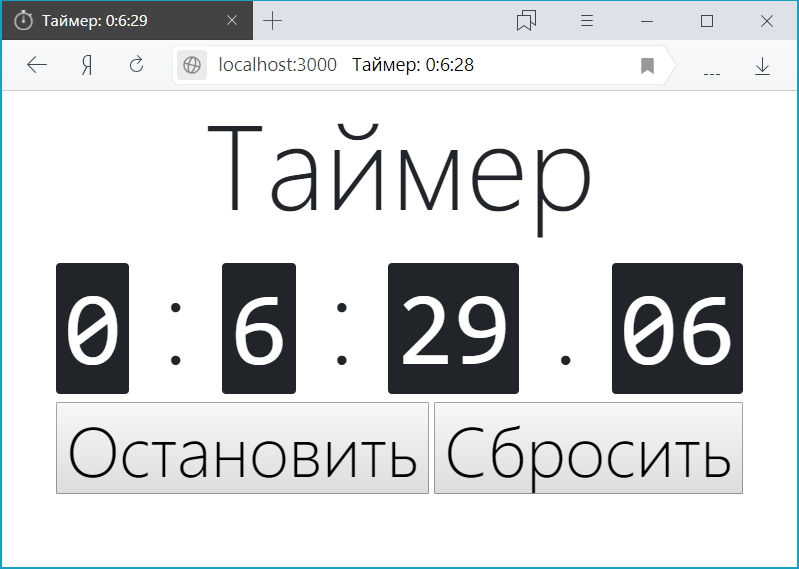
Для начала надо хотя бы немного разбираться в HTML, CSS, JavaScript, XML, DOM, ООП и уметь работать в терминале (командной строке).
Где брать материалы для изучения?
Для изучения HTML и CSS рекомендую htmlbook.ru
Для изучения JavaScript рекомендую learn.javascript.ru
Для изучения XML рекомендую msiter.ru/tutorials/uchebnik-xml-dlya-nachinayushchih
Про DOM можно почитать в уроке по JavaScript learn.javascript.ru/dom-nodes
Для изучения ООП рекомендую видеокурс proglib.io/p/oop-videocourse
Для изучения командной строки Windows рекомендую cmd.readthedocs.io/cmd.html
Для изучения терминала в Mac рекомендую ixrevo.me/mac-os-x-terminal
Если вы работаете в Linux, то bash и аналоги знаете, в крайнем случае man или help вам помогут.
Для изучения React использую learn-reactjs.ru (который является переводом официальной документации React: reactjs.org).
Для изучения Bootstrap использую bootstrap-4.ru (который является переводом официальной документации Bootstrap: getbootstrap.com).
Для того, чтобы подружить React и Bootstrap нашёл отличную статью webformyself.com/kak-ispolzovat-bootstrap-s-react
Для изучения JavaScript рекомендую learn.javascript.ru
Для изучения XML рекомендую msiter.ru/tutorials/uchebnik-xml-dlya-nachinayushchih
Про DOM можно почитать в уроке по JavaScript learn.javascript.ru/dom-nodes
Для изучения ООП рекомендую видеокурс proglib.io/p/oop-videocourse
Для изучения командной строки Windows рекомендую cmd.readthedocs.io/cmd.html
Для изучения терминала в Mac рекомендую ixrevo.me/mac-os-x-terminal
Если вы работаете в Linux, то bash и аналоги знаете, в крайнем случае man или help вам помогут.
Для изучения React использую learn-reactjs.ru (который является переводом официальной документации React: reactjs.org).
Для изучения Bootstrap использую bootstrap-4.ru (который является переводом официальной документации Bootstrap: getbootstrap.com).
Для того, чтобы подружить React и Bootstrap нашёл отличную статью webformyself.com/kak-ispolzovat-bootstrap-s-react
В этой статье сделаю выжимку минимально необходимого для работы и сделаем такой таймер:

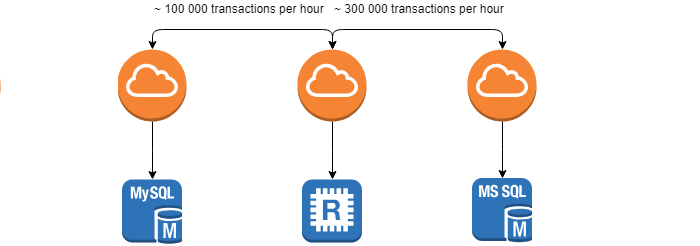




 Этой статьей я продолжаю публиковать целую серию статей, результатом которой будет книга по работе .NET CLR, и .NET в целом. За ссылками — добро пожаловать под кат.
Этой статьей я продолжаю публиковать целую серию статей, результатом которой будет книга по работе .NET CLR, и .NET в целом. За ссылками — добро пожаловать под кат. CLR Book:
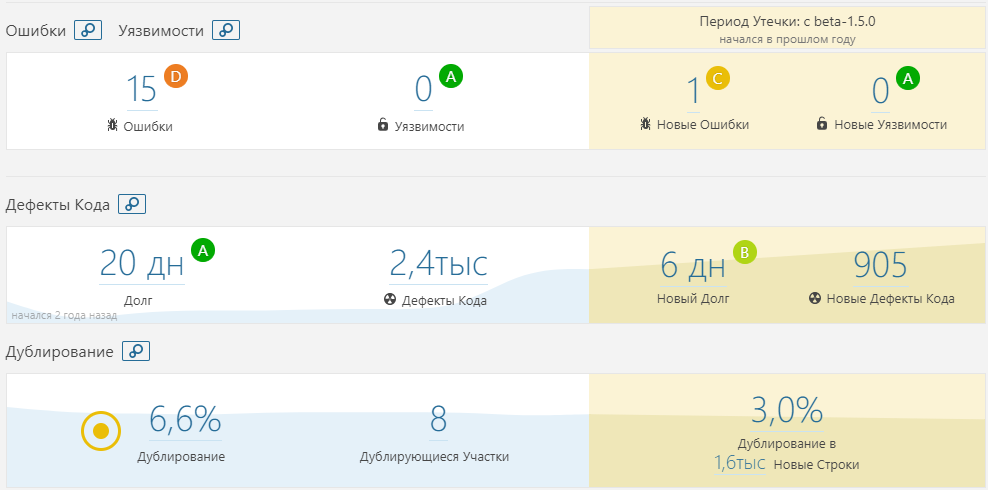
CLR Book:  Релиз 0.5.2 книги, PDF:
Релиз 0.5.2 книги, PDF: 



{kind=link}