Мы разработали дизайн сети дата-центров, который позволяет разворачивать вычислительные кластеры размером больше 100 тысяч серверов с полосой бисекции (bisection bandwidth) свыше одного петабита в секунду.
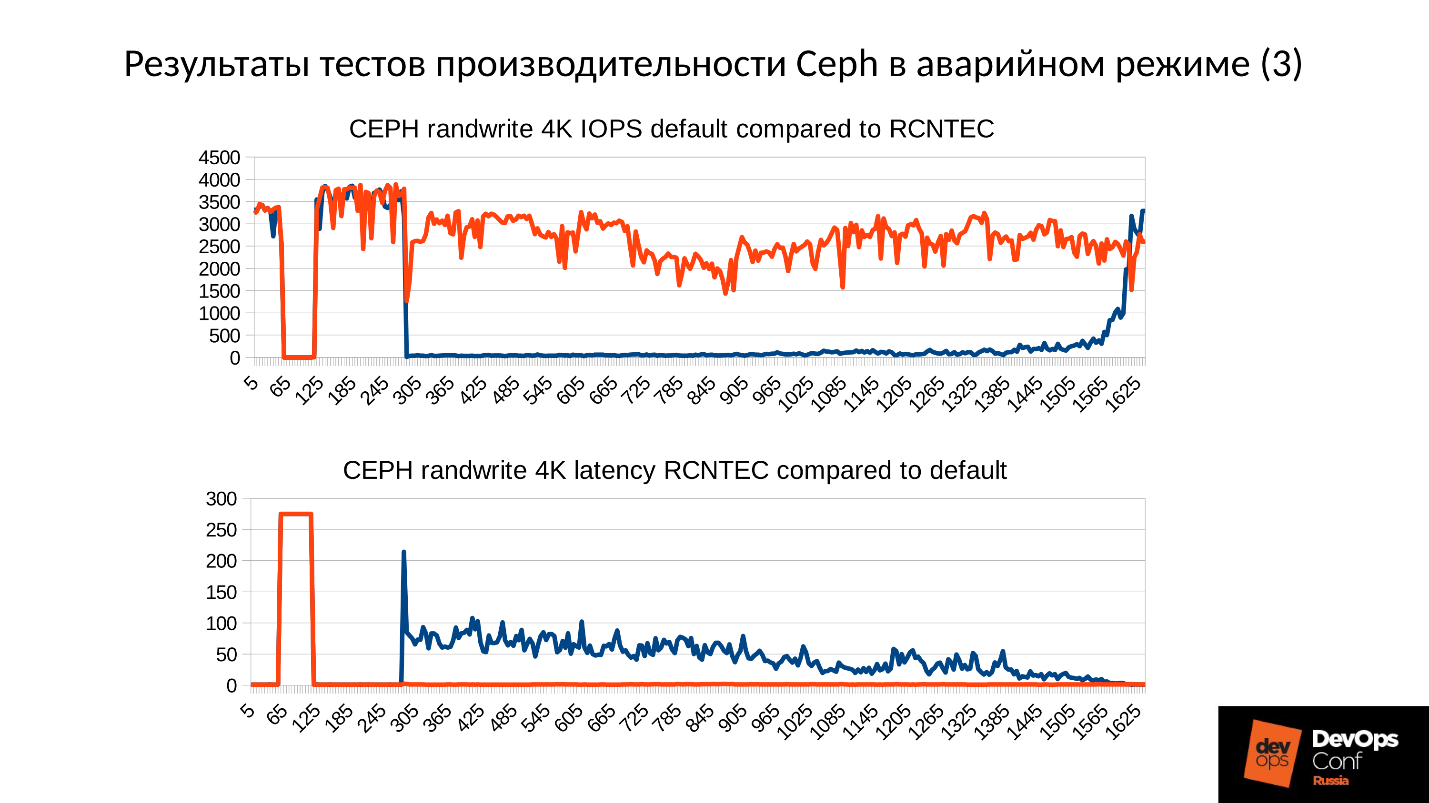
Из доклада Дмитрия Афанасьева вы узнаете об основных принципах нового дизайна, масштабировании топологий, возникающих при этом проблемах, вариантах их решения, об особенностях маршрутизации и масштабирования функций forwarding plane современных сетевых устройств в «плотных» (densely connected) топологиях с большим числом ECMP-маршрутов. Кроме того, Дима коротко рассказал об организации внешней связности, физическом уровне, кабельной системе и способах дальнейшего увеличения емкости.

— Всем добрый день! Меня зовут Дмитрий Афанасьев, я сетевой архитектор Яндекса и занимаюсь преимущественно дизайном сетей дата-центров.
Из доклада Дмитрия Афанасьева вы узнаете об основных принципах нового дизайна, масштабировании топологий, возникающих при этом проблемах, вариантах их решения, об особенностях маршрутизации и масштабирования функций forwarding plane современных сетевых устройств в «плотных» (densely connected) топологиях с большим числом ECMP-маршрутов. Кроме того, Дима коротко рассказал об организации внешней связности, физическом уровне, кабельной системе и способах дальнейшего увеличения емкости.
— Всем добрый день! Меня зовут Дмитрий Афанасьев, я сетевой архитектор Яндекса и занимаюсь преимущественно дизайном сетей дата-центров.



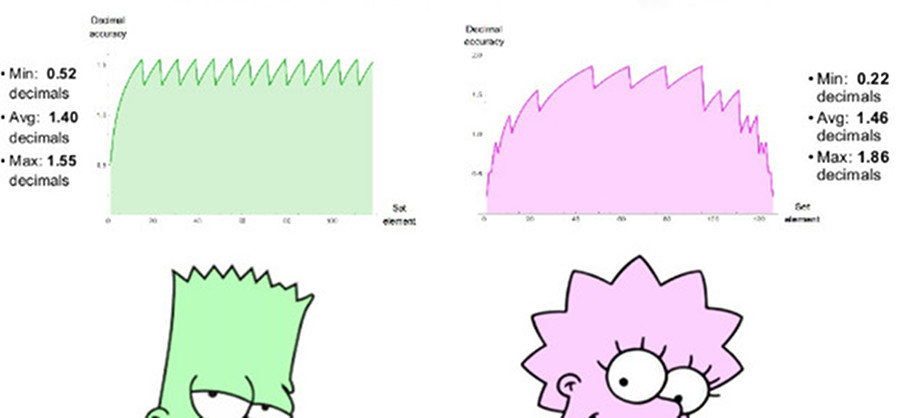
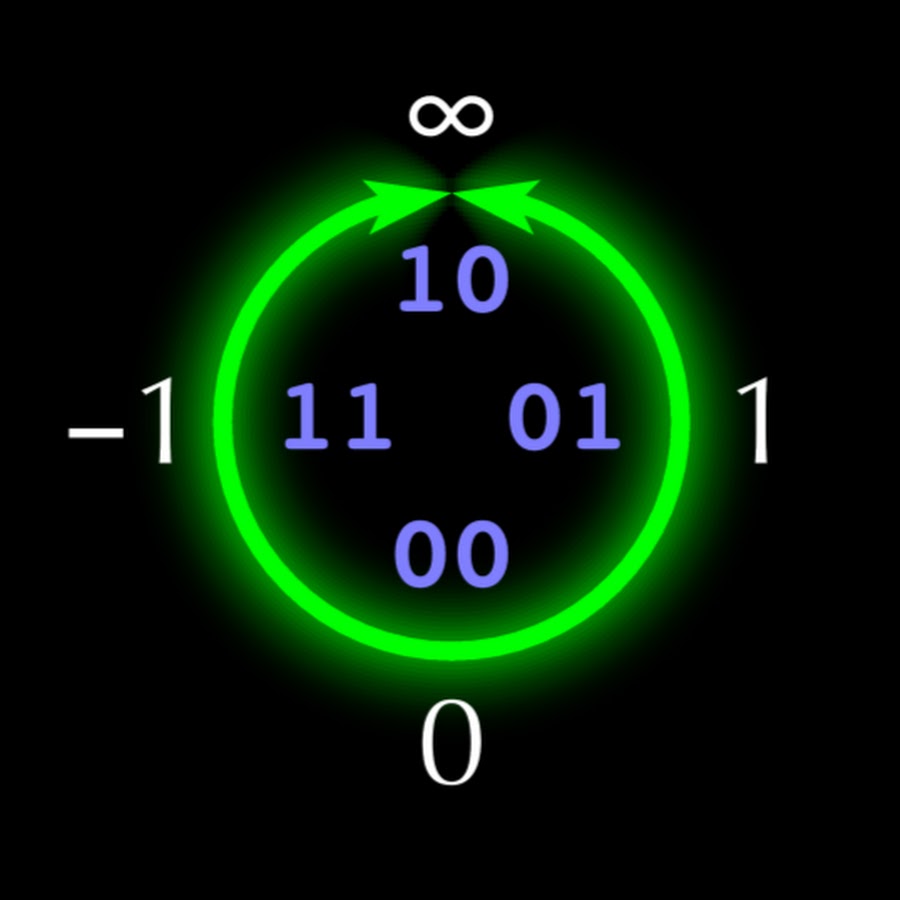
 Продолжаем разговор о безопасности UEFI.
Продолжаем разговор о безопасности UEFI.