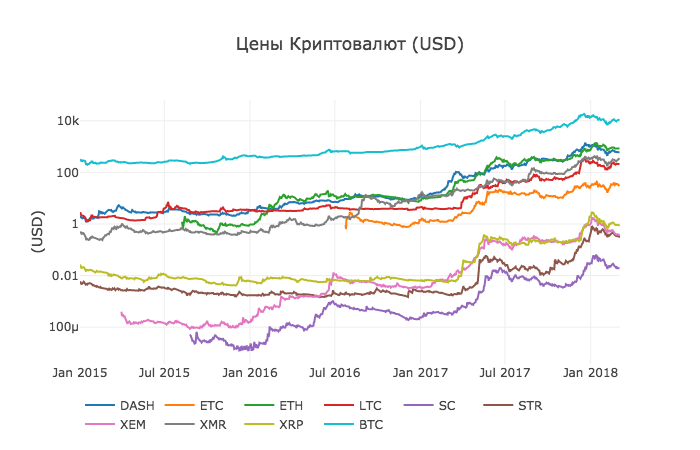
Цель этой статьи — предоставить легкое введение в анализ данных с использованием Anaconda. Мы пройдем через написание простого скрипта Python для извлечения, анализа и визуализации данных по различным криптовалютам.

User

Эта статья рассказывает о необходимом минимуме, который потребуется при анализе сайта. При написании, я ориентировался на тех у кого совсем нет представления о предмете, но все упрощения можно быстро проскролить и почитать сразу про прикладную часть.
Говорить мы будем в основном о визитах (ym:s:visits).

Тимлид команды аналитики и DS в Авито Александр Ледовский рассказал, как быть, когда нужно посчитать что-то на pySpark, чтобы потом выгрузить.
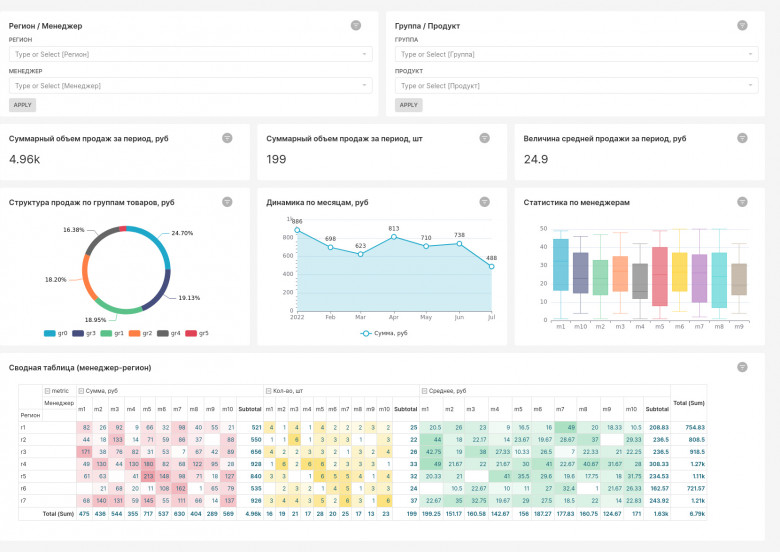
В последнее время изучая вакансии на сайтах по поиску работы, все чаще стал отмечать, что помимо платных инструментов BI от кандидатов требуется знание еще бесплатных платформ. Мой предыдущий опыт работы по построению графической отчетности был связан исключительно с коммерческими продуктами, поэтому я решил выделить время на ознакомление с альтернативными решениями. Выбор Superset был случайным, так как я обратил внимание на него лишь потому, что он входит в экосистему Apache. Сразу хочу оговориться, что в данной заметке не будет сравнения Superset с платными инструментами. Такое сопоставление функционала просто некорректно из-за разных “весовых категорий”. Также я не буду выделять плюсы и минусы решения по сравнению с бесплатными аналогами, так как это очень дискуссионный вопрос. Неизбежно найдутся адепты того или иного продукта, которые будут доказывать ошибочность моих суждений. Поэтому я построил публикацию в форме простого описания “нюансов”, которые я выделил для себя, начав знакомство с Superset. Читатели же сами смогут сделать свои выводы.




«Я тебя по IP вычислю!» – помните такую угрозу из интернета времен нулевых годов? Мы в Big Data МТС решили выяснить, можно ли составить хотя бы приблизительное представление о человеке, обладая информацией о сайтах, которые он посещает. Мы сгенерировали полусинтетические данные, чтобы понять, насколько смелыми можно быть в этих ваших интернетах.
Приглашаем вас попробовать составить портрет пользователя на основе этих данных и посмотреть, насколько точным он получится. Также под катом вы найдете наш baseline решения, написание которого займет около получаса.



Привет! Меня зовут Максим Бабенко, я руковожу отделом технологий распределённых вычислений в Яндексе. Сегодня мы выложили в опенсорс платформу YTsaurus — одну из основных инфраструктурных BigData-систем, разработанных в Яндексе.
YTsaurus — результат почти десятилетнего труда, которым нам хочется поделиться с миром. В этой статье мы расскажем историю возникновения YT, ответим на вопрос, зачем нужен YTsaurus, опишем ключевые возможности системы и обозначим область её применения.
В Github-репозитории находится серверный код YTsaurus, инфраструктура развёртывания с использованием k8s, а также веб-интерфейс системы и клиентский SDK для распространённых языков программирования — C++, Java, Go и Python. Всё это — под лицензией Apache 2.0, что позволяет всем желающим загрузить его на свои серверы, а также дорабатывать его под свои нужды.

Первая часть в серии статей про СУБД, в которых будут представлены простые и понятные критерии, на основе которых можно будет получить подсказку, какую СУБД выбрать для своего проекта.
В данной статье разберем типы СУБД, какие наиболее популярны, в чем их предназначение и уникальность. Подскажу при каких условиях нужно выбирать ту или иную СУБД, а когда не нужно.

При выполнении инженерно-геологических изысканий может возникнуть задача, связанная с сопоставлением данных полевых и лабораторных исследований на одних и тех же грунтах, с целью подтверждения корректной транспортировки проб от объекта изысканий до лаборатории (образцы не были деформированы и/или разрушены в ходе перевозки).
При данной постановке задачи можно применить методику A/B-тестирования.

Привет всем!
Сразу хочется отметить, что данная статья написана исключительно для людей, начинающих свое путь в изучении SQL и оконных функций. Здесь могут быть не разобраны сложные применения функций и могут не использоваться сложные формулировки определений - все написано максимально простым языком для базового понимания.
P.S. Если автор что-то не разобрал и не написал, значит он посчитал это не обязательным в рамках этой статьи)))
Для примеров будем использовать небольшую таблицу, которая показывает оценки учеников по разным предметам. В БД табличка выглядит следующим образом




 NLP. Основы. Техники. Саморазвитие. Часть 2: NER
NLP. Основы. Техники. Саморазвитие. Часть 2: NER