
Три дня назад Cisco заявила об очередном сокращении штата, в этот раз — на 6 500 сотрудников и намерении продать фабрику в городе Хуарез в Мексике гиганту Foxconn, что лишит работы на американскую компанию еще 5 000 человек. Все эти события следуют за решением компании остановить производство камеры Flip и свернуть разработку социальной/видео платформы Eos.
Прошло всего несколько лет с того момента, как Cisco расширяла свой бизнес в новые рынки, сжигая миллиарды долларов на слияниях и поглощениях, съев такие компании, как WebEx, Tandberg и Flip. Теперь движение резко сменило направление — что же случилось?
Слишком большой успех
Нынешнее положение Cisco — это классическая история, когда кто-то становится жертвой собственного успеха. В момент апогея пузыря дот-комов, Cisco по капитализации обошла Microsoft и стала самой дорогой компанией в мире. В конце-концов, это неудивительно, ведь Cisco продавала оборудование, за счет которого существовала всемирная сеть. Некоторый успех был достигнут и в области корпоративных VOIP продуктов, куда расширяла свое влияние компания, но к этой теме мы вернемся снова чуть ниже.
Взрыв пузыря сказался и на бизнесе Cisco. Всего через год после того, как капитализация компании превысила оную Microsoft, Cisco уволила 11% собственной рабочей силы. Проблема была двухсторонняя: во-первых, компания владела почти целым рынком, поэтому если рынок начинал падать, то же самое происходило и с Cisco; во-вторых, инвесторы хотели роста, а рынок корпоративного сетевого железа казался уже огромным, фактически — он вырос до максимальных размеров. По случаю, в марте 2007, Cisco прикупила WebEx и тогда же появилось первое сообщение о том, что гигант уже владеет долей от 70% до 90% на рынке свитчей и роутеров, но инвесторам, как это часто бывает, было мало и они требовали еще большего роста.


 Для начала, у меня просто возникла потребность сделать сайт с текстовой информацией. Сделать надо было что-то несложное, но не забывая про мобильные устройства, которых все больше ходит по сайтам.
Для начала, у меня просто возникла потребность сделать сайт с текстовой информацией. Сделать надо было что-то несложное, но не забывая про мобильные устройства, которых все больше ходит по сайтам.
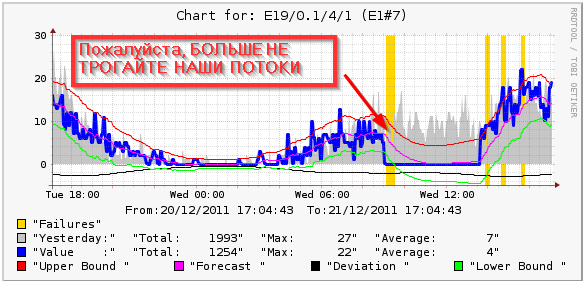

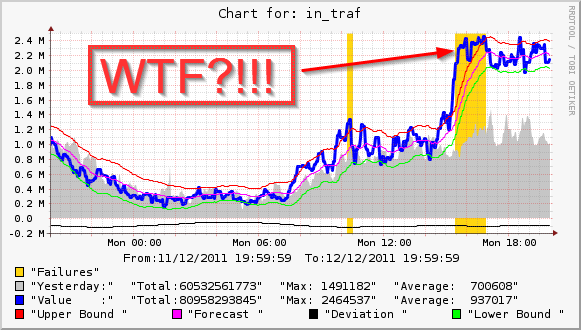


 Маленькие красные горбики — это "затупившие" на множественном обновлении кеша запросы. Эта статья будет описывать один из подходов к решению проблемы на примере(
Маленькие красные горбики — это "затупившие" на множественном обновлении кеша запросы. Эта статья будет описывать один из подходов к решению проблемы на примере( В ноябре HP рассказала о новой программе развития своей серверной линейки, получившей название
В ноябре HP рассказала о новой программе развития своей серверной линейки, получившей название 



 Недавно один из заказчиков
Недавно один из заказчиков 