Привет, Хабр! Представляю вам перевод статьи.
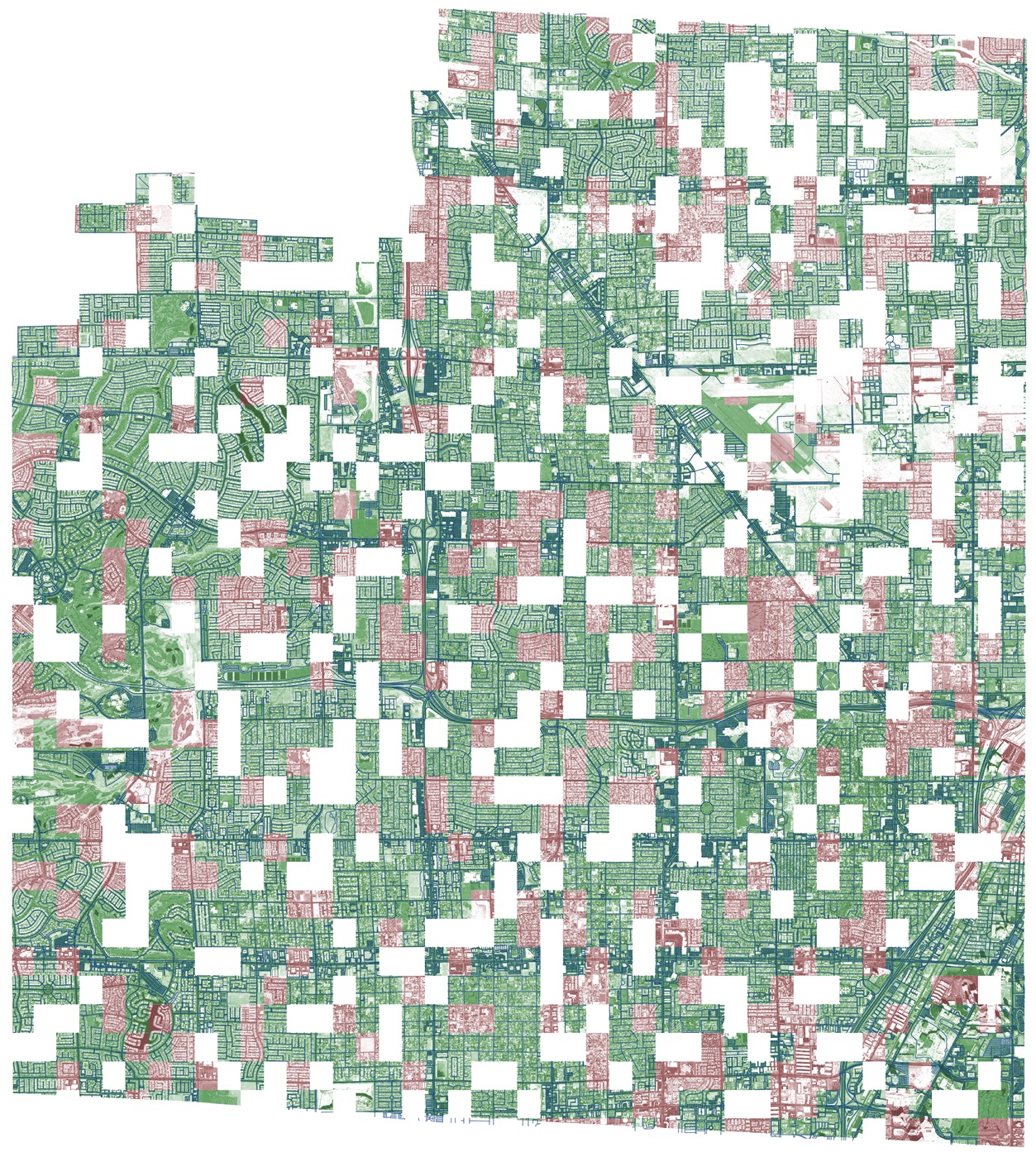
Это Вегас с предоставленной разметкой, тестовым датасетом и вероятно белые квадраты — это отложенная валидация (приват). Выглядит прикольно. Правда эта панорама лучшая из всех четырех городов, так вышло из-за данных, но об этом чуть ниже.
0. TLDR
Ссылка на соревнование и подробное описание.

Мы закончили предварительно на 9-м месте, но позиция может измениться после дополнительного тестирования сабмитов организаторами.
Также я потратил некоторое время на написание хорошего читаемого кода на PyTorch и генераторов данных. Его можно без застенчивости использовать для своих целей (только поставьте плюсик). Код максимально простой и модульный, плюс читайте дальше про best practices для семантической сегментации.
Кроме того, не исключено, что мы напишем пост про понимание и разбор Skeleton Network, которую в итоге использовали все финалисты в топе соревнования для преобразования маски изображения в граф.
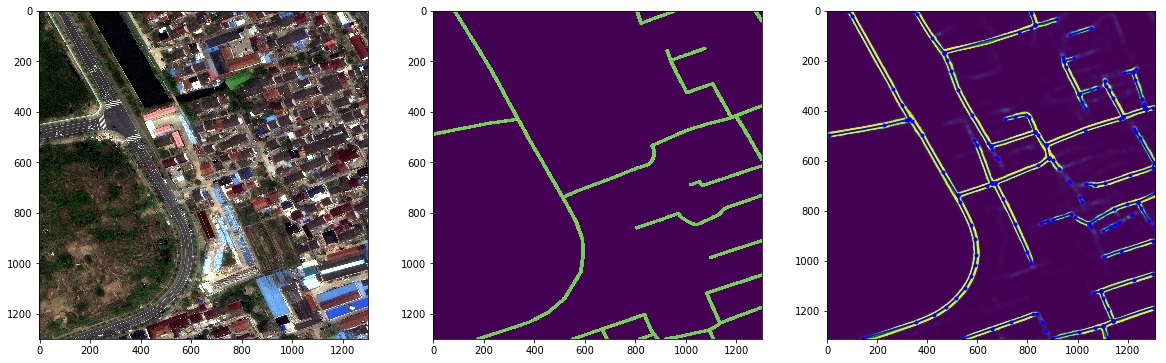
Суть соревнования на 1 картинке