Билл Гейтс на своём канале на Youtube предлагает несколько книг для чтения летом, что он делает последние пару лет. Список книг — под катом.

@apanasenkoread-only
Пользователь
Как я писал аудит запуска Docker-контейнеров на Go
10 мин
Туториал
Всеобщая контейнеризация захватывает мир. Не обошла эта эпидемия и меня стороной, и теперь, последние шесть месяцев, я занимаюсь тем, что сегодня принято называть модным словом DevOps. В проектах, которыми я занимаюсь, мы решили использовать Docker, ведь он делает процесс развёртывания приложений до неприличия простым, и буквально заставляет вас следовать другому не менее модному сегодня течению — микросервисной архитектуре, которая способствует бурному размножению этих самых контейнеров на его основе. В какой-то момент понимаешь, что было бы неплохо собрать статистику их жизни и смерти в отнюдь небезопасной среде обитания. А в качестве бонуса изучить инструменты, которые используешь в работе, понаписать что-то не на основном языке программирования, да и просто сделать что-то необязательное, но полезное.
В статье я расскажу как за три вечера и кусочек ночи был разработан проект для аудита и сбора статистики жизненного цикла контейнеров.
В статье я расскажу как за три вечера и кусочек ночи был разработан проект для аудита и сбора статистики жизненного цикла контейнеров.
Почему ваша первая реализация FizzBuzz на Rust может не работать
14 мин
Перевод
Полное оригинальное название статьи: «Why your first FizzBuzz implementation may not work: an exploration into some initially surprising but great parts of Rust (though you still might not like them)»
tl;dr;-версия: На первый взгляд некоторые аспекты Rust могут показаться странными и даже неудобными, однако, они оказываются весьма удачными для языка, который позиционируется как системный. Концепции владения (ownership) и времени жизни (lifetime) позволяют привнести в язык сильные статические гарантии и сделать программы на нём эффективными и безопасными, как по памяти, так и по времени.
Лицензия: CC-BY, автор Chris Morgan.
 FizzBuzz предполагается как простое задание для новичка, но в Rust присутствуют несколько подводных камней, о которых лучше знать. Эти подводные камни не являются проблемами Rust, а, скорее, отличиями от того, с чем знакомо большиство программистов, ограничениями, которые на первый взгляд могут показаться очень жёсткими, но в действительности дают громадные преимущества за малой ценой.
FizzBuzz предполагается как простое задание для новичка, но в Rust присутствуют несколько подводных камней, о которых лучше знать. Эти подводные камни не являются проблемами Rust, а, скорее, отличиями от того, с чем знакомо большиство программистов, ограничениями, которые на первый взгляд могут показаться очень жёсткими, но в действительности дают громадные преимущества за малой ценой.
Rust это «подвижная мишень», тем не менее, язык становится стабильней. Код из статьи работает с версией 0.12. Если что-то сломается, пожалуйста, свяжитесь со мной. Касательно кода на Python, он будет работать как в двойке, так и в тройке.
tl;dr;-версия: На первый взгляд некоторые аспекты Rust могут показаться странными и даже неудобными, однако, они оказываются весьма удачными для языка, который позиционируется как системный. Концепции владения (ownership) и времени жизни (lifetime) позволяют привнести в язык сильные статические гарантии и сделать программы на нём эффективными и безопасными, как по памяти, так и по времени.
Лицензия: CC-BY, автор Chris Morgan.
Почему ваша первая реализация FizzBuzz может не работать: исследование некоторых особенностей Rust, которые изначально шокируют, но в действительности являются его лучшими сторонами (хотя они всё равно могут вам не понравиться)
FizzBuzz предполагается как простое задание для новичка, но в Rust присутствуют несколько подводных камней, о которых лучше знать. Эти подводные камни не являются проблемами Rust, а, скорее, отличиями от того, с чем знакомо большиство программистов, ограничениями, которые на первый взгляд могут показаться очень жёсткими, но в действительности дают громадные преимущества за малой ценой. Rust это «подвижная мишень», тем не менее, язык становится стабильней. Код из статьи работает с версией 0.12. Если что-то сломается, пожалуйста, свяжитесь со мной. Касательно кода на Python, он будет работать как в двойке, так и в тройке.
Пиши на Rust — запускай везде. Взаимодействие Rust и C
8 мин
Предлагаю читателям «Хабрахабра» перевод поста «Rust Once, Run Everywhere» из блога Rust за авторством Alex Crichton. Сам я некоторое время уже интересуюсь этим языком, а в связи со скорым релизом версии 1.0 хотел бы продвигать его по своим скромным возможностям. Ничего своего, к сожалению, сейчас у меня написать не получается, но когда-то я занимался переводами, так что решил вспомнить давнее дело. Перевод этого поста на Хабре я не нашёл, так что решил сделать свой.
Некоторые термины, которые обозначают уникальные для Rust-а концепции (ownership, borrowing, lifetime parameter), я не знал, как лучше перевести на русский, так что постарался подобрать наиболее подходящие по смыслу и более-менее понятные для русскоязычной аудитории слова. Любые предложения-улучшения принимаются.
Никогда не было планов добиться мирового господства Rust-а за одну ночь, так что есть большая потребность в способности взаимодействовать с уже сущестующим кодом так же легко, как и с нативный кодом на самом Rust-е. Именно поэтому Rust даёт возможность очень просто использовать C API без накладных расходов, и при этом гарантирует строгую безопасность управления памятью, благодаря своей системе управления владением и заимствованием указателей.
Некоторые термины, которые обозначают уникальные для Rust-а концепции (ownership, borrowing, lifetime parameter), я не знал, как лучше перевести на русский, так что постарался подобрать наиболее подходящие по смыслу и более-менее понятные для русскоязычной аудитории слова. Любые предложения-улучшения принимаются.
Никогда не было планов добиться мирового господства Rust-а за одну ночь, так что есть большая потребность в способности взаимодействовать с уже сущестующим кодом так же легко, как и с нативный кодом на самом Rust-е. Именно поэтому Rust даёт возможность очень просто использовать C API без накладных расходов, и при этом гарантирует строгую безопасность управления памятью, благодаря своей системе управления владением и заимствованием указателей.
Обзор языка программирования Rust
10 мин
Rust — новый экспериментальный язык программирования, разрабатываемый Mozilla. Язык компилируемый и мультипарадигмальный, позиционируется как альтернатива С/С++, что уже само по себе интересно, так как даже претендентов на конкуренцию не так уж и много. Можно вспомнить D Вальтера Брайта или Go от Google.
В Rust поддерживаются функицональное, параллельное, процедурное и объектно-ориентированное программирование, т.е. почти весь спектр реально используемых в прикладном программировании парадигм.
Я не ставлю целью перевести документацию (к тому же она весьма скудная и постоянно изменяется, т.к. официального релиза языка еще не было), вместо этого хочется осветить наиболее интересные фичи языка. Информация собрана как из официальной документации, так и из крайне немногочисленных упоминаний языка на просторах Интернета.
В Rust поддерживаются функицональное, параллельное, процедурное и объектно-ориентированное программирование, т.е. почти весь спектр реально используемых в прикладном программировании парадигм.
Я не ставлю целью перевести документацию (к тому же она весьма скудная и постоянно изменяется, т.к. официального релиза языка еще не было), вместо этого хочется осветить наиболее интересные фичи языка. Информация собрана как из официальной документации, так и из крайне немногочисленных упоминаний языка на просторах Интернета.
Извлечение упоминаний сущностей и поиск в Textocat API
9 мин
Textocat API — это облачный SaaS анализа текстов. Качественное извлечение полезной информации из текстов — сложная задача и требует серьезной экспертизы. Миссия команды Textocat — сделать процесс обработки текстов настолько легким для использования, чтобы его мог включить в свой арсенал любой современный разработчик. Используя Textocat API, вы можете быстро прототипировать приложения на основе текстовой аналитики и превращать их в свой бизнес. В данной публикации мы покажем, насколько легко интегрировать в любое приложение возможности Textocat API по распознаванию упоминаний сущностей (объектов) и поиску документов на русском языке.
В начале апреля мы запустили бета-тестирование Textocat API. В этой версии мы предлагаем разработчикам бесплатно использовать часть функционала сервиса со следующими возможностями:

Возможности Textocat API Beta
В начале апреля мы запустили бета-тестирование Textocat API. В этой версии мы предлагаем разработчикам бесплатно использовать часть функционала сервиса со следующими возможностями:
- распознавание упоминаний сущностей (entity recognition) в коллекциях документов на русском языке;
- хранение обработанных коллекций;
- полнотекстовый поиск с учетом выделенных типов сущностей.
Альтернатива HLS для iOS Safari — потоковое видео через Websocket
8 мин

Apple HTTP Live Streaming — широко распространенная технология для доставки видео на мобильные устройства, которая делает ставку на простоту, универсальность и проходимость. В качестве протокола доставки используется самый простой, доступный и проверенный протокол Интернета HTTP, что позволяет доставить видео практически на любое устройство или ПО в сети.
Ниже под катом рассматривается альтернатива — Websocket Streaming для iOS Safari и подробно описывается процесс тестирования.
Открыто видео курса «Multicore programming in Java» на русском (30+30 часов)
2 мин
Добрый день.
Я занимаюсь IT-преподаванием. Читал Java Core (материалы тут).
Сейчас написал и продаю курс «Scala for Java Developers»
В этом посте решил открыть видео двух курсов (проходивших в режиме вебинаров) по многопоточности под JVM (это 16 + 16 двухчасовых лекций).
Больше о материалах (программа, полезные ссылки) можно прочитать в постах-объявлениях о вебинарах (Программа курса «Multicore programming in Java» (25 марта 2014), Программа и материалы курса «Multicore programming in Java» (31 июля)).
Курс рассчитан на слушателей, которые начинают изучать многопоточность с нуля (после крепкого курса Java Core, Middle Developer из чистого web-а или перешедшим из скриптовых/интерпретируемых языков программирования). Он не будет подходить тем, кто перешел из «суровых» С/С++ или ищет «академической высоты».
Детально рассматриваются темы Hardware, New Java memory Model, java.util.concurrent (atomics, blocking queues, thread pool, locks, synchronizers), message passing alternative, software transactional memory alternative, Java 7 Fork/Join, Java 8 Parallel Streams (+Lambdas, +Stream API), CSP/JCSP alternative
Я занимаюсь IT-преподаванием. Читал Java Core (материалы тут).
Сейчас написал и продаю курс «Scala for Java Developers»
В этом посте решил открыть видео двух курсов (проходивших в режиме вебинаров) по многопоточности под JVM (это 16 + 16 двухчасовых лекций).
Больше о материалах (программа, полезные ссылки) можно прочитать в постах-объявлениях о вебинарах (Программа курса «Multicore programming in Java» (25 марта 2014), Программа и материалы курса «Multicore programming in Java» (31 июля)).
Курс рассчитан на слушателей, которые начинают изучать многопоточность с нуля (после крепкого курса Java Core, Middle Developer из чистого web-а или перешедшим из скриптовых/интерпретируемых языков программирования). Он не будет подходить тем, кто перешел из «суровых» С/С++ или ищет «академической высоты».
Детально рассматриваются темы Hardware, New Java memory Model, java.util.concurrent (atomics, blocking queues, thread pool, locks, synchronizers), message passing alternative, software transactional memory alternative, Java 7 Fork/Join, Java 8 Parallel Streams (+Lambdas, +Stream API), CSP/JCSP alternative
93 видео-лекции по Scala
4 мин
Туториал
В ходе подготовки спецкурса «Scala for Java Developers» под платформу онлайн-обучения UDEMY, я анализирую другие «лекционные» видео. В библиотеке накопилось какое-то количество ссылок на дельных учебные материалы по Scala (видео на английском).
Для большинства видео указано количество просмотров. Надо сделать несколько замечаний:
1. Количество просмотров не является главным критерием качества и полезности видео, но этот может служить каким-то указателем на ценность.
2. Здесь не все популярное видео, что я встречал, а лишь то, что ценно по моему личному мнению.
3. Если кто-то знает еще хорошее видео — пишите, добавлю в списки.
Для большинства видео указано количество просмотров. Надо сделать несколько замечаний:
1. Количество просмотров не является главным критерием качества и полезности видео, но этот может служить каким-то указателем на ценность.
2. Здесь не все популярное видео, что я встречал, а лишь то, что ценно по моему личному мнению.
3. Если кто-то знает еще хорошее видео — пишите, добавлю в списки.
- General
- Odersky about Scala
- Play
- Akka
- Spray
- Spark
- Slick (DB)
- SBT
- Scalaz
- Shapeless
- Spire (generic numeric programming)
- Functional/Reactive Programming
Разбор естественного языка: под капотом
4 мин

API синтаксического анализатора
Продолжаю свой предыдущий пост. Время сфокусироваться на деталях внутреннего устройства синтаксического анализатора. В качестве языка реализации я выбрал Go, поскольку хотел малой ценой получить параллельный (в смысле, использующий все доступные ядра CPU) производительный инструмент, без погружения в низкоуровневую пучину C++.
Полученный код предоставляет следующий API:
type Attribute struct {
Name string
Value string
}
type ParseMatch struct {
Text string
Nonterminal string
Rule string
Attributes []Attribute
Submatches []ParseMatch
Hypotheses []string
HypothesisCount uint
}
func Parse(text, nonterminal string, hypotheses_limit uint) []ParseMatch
Match ссылается на дочерние объекты того же типа, соотвествующие нетерминалам или лексическим терминалам подошедшего правила. В общем случае, из-за неоднозначности, присущей естественным языкам, тексту соответствует несколько разборов (например, из-за наличия омонимов). Поэтому функция Parse возвращает множество объектов Match. Вышеупомянутая неоднозначность синтаксического разбора должна устраняться на следующем (семантическом) уровне анализа текста.
Итак, функция Parse берёт text — текст для разбора, nonterminal — название нетерминала (например, «sentence»), а также максимальное число выдвигаемых гипотез hypotheses_limit (об этом чуть ниже). Параметр nonterminal может быть пустым. В этом случае тексту будет сопоставляться лексический терминал, найденный в морфологической базе.
В терминах данного анализатора гипотеза — это предположение того, что нарушенное ограничение значения атрибута вызвано случайной причиной. Если анализатор встречает несоответствие значения атрибута ограничению, заданному рассматриваемым в данный момент правилом, а число выдвинутых гипотез не достигло hypotheses_limit, то данное несоответствие игнорируется. В противном случае рассматриваемое правило отбрасывается. Данный механизм удобен для отладки правил, но должен избегаться в реальной работе, поскольку чудовищно замедляет процесс разбора.
Асинхронная работа с Tarantool на Python
12 мин
На Хабре уже есть статьи о NoSQL СУБД Tarantool и о том, как его используют в Mail.Ru Group (и не только). Однако нет рецептов того, как работать с Tarantool на Python. В своей статье я хочу рассказать о том, как мы готовим Tarantool Python в своих проектах, какие проблемы и сложности при этом возникают, плюсы, минусы, подводные камни и, конечно же, «в чем фишка». Итак, обо всем по порядку.

Tarantool представляет собой Application Server для Lua. Он умеет хранить данные на диске, обеспечивает быстрый доступ к ним. Tarantool используется в задачах с большими потоками данных в единицу времени. Если говорить о цифрах, то это десятки и сотни тысяч операций в секунду. Например, в одном из моих проектов генерируется более 80 000 запросов в секунду (выборка, вставка, обновление, удаление), при этом нагрузка равномерно распределяется по 4 серверам с 12 инстансами Tarantool. Не все современные СУБД готовы работать с такими нагрузками. Кроме того, при таком количестве данных, очень дорого ожидание выполнения запроса, поэтому сами программы должны быстро переключаться от одной задачи к другой. Для эффективной и равномерной загрузки CPU сервера (всех его ядер) как раз нужен Tarantool и асинхронные приемы в программировании.
Tarantool представляет собой Application Server для Lua. Он умеет хранить данные на диске, обеспечивает быстрый доступ к ним. Tarantool используется в задачах с большими потоками данных в единицу времени. Если говорить о цифрах, то это десятки и сотни тысяч операций в секунду. Например, в одном из моих проектов генерируется более 80 000 запросов в секунду (выборка, вставка, обновление, удаление), при этом нагрузка равномерно распределяется по 4 серверам с 12 инстансами Tarantool. Не все современные СУБД готовы работать с такими нагрузками. Кроме того, при таком количестве данных, очень дорого ожидание выполнения запроса, поэтому сами программы должны быстро переключаться от одной задачи к другой. Для эффективной и равномерной загрузки CPU сервера (всех его ядер) как раз нужен Tarantool и асинхронные приемы в программировании.
Антифрод. Архитектура сервиса (часть 3)
6 мин
Это третья часть эксперимента по созданию системы распознания мошеннических платежей (antifraud-система). Целью является создание доступного (в плане стоимости разработки и владения) antifraud-сервиса, который позволит сразу нескольким участникам проведения online-платежей – мерчантам, агрегаторам, платежным системам, банкам – снизить риски проведения мошеннических платежей (fraud) через их площадки.
В прошлой части мы сфокусировали внимание на функциональных и нефункциональных требованиях к антифрод-сервису. В этой части статьи рассмотрим программную архитектуру сервиса, его модульную структуру и ключевые детали реализации такого сервиса.
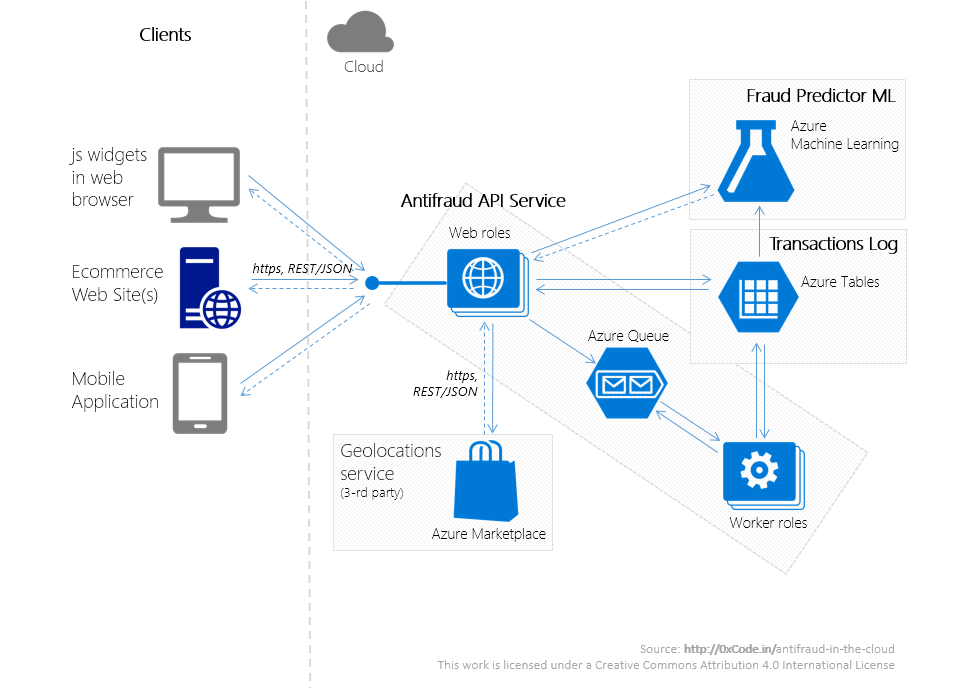
В прошлой части мы сфокусировали внимание на функциональных и нефункциональных требованиях к антифрод-сервису. В этой части статьи рассмотрим программную архитектуру сервиса, его модульную структуру и ключевые детали реализации такого сервиса.
«Идеальный» кластер. Часть 3.1 Внедрение MySQL Multi-Master кластера
16 мин
Туториал
В продолжение цикла статей об «Идеальном» кластере хочу поделиться моим опытом развертывания и настройки Multi-Master кластеров MySQL.

Антифрод. Быстро, дешево… отлично (часть 1)
6 мин
Эта статья представляет собой описание эксперимента по созданию системы обнаружения мошеннических платежей по банковским картам.
В первой части статьи я расскажу почему вопрос мошеннических платежей (fraud) стоит так остро для всех участников рынка электронных платежей – от интернет-магазинов до банков – и в чем основные сложности, из-за которых стоимость разработки таких систем подчас является слишком высокой для многих участников ecommerce-рынка.
Во второй части будут описаны требования технического и нетехнического характера, которые предъявляются к таким системам, и то, как я собираюсь снизить стоимость разработки и владения antifraud-системы на порядок(и).
В третьей части будет рассмотрена программная архитектура сервиса, его модульная структура и ключевые детали реализации.
В четвертой части статьи подробно обсудим наиболее сложную с технической точки зрения и наиболее интеллектуальную часть системы – аналитическую систему распознания мошеннических платежей.
Get Started!
Стремительный рост количества операций с пластиковыми картами, совершаемых через интернет, ставит перед разработчиками систем приема online-платежей все новые и новые вызовы, связанные с ростом масштаба таких систем и усложнением подходов к обеспечению их надежности и безопасности.
Не менее интенсивно растет количество мошеннических операций и разнообразие видов мошенничества. Россия, наряду с Англией, Францией, Германией, Испанией, входит в топ-5 европейский стран по годовому объему мошеннических операций с банковским картами. Общий объем потерь от мошенничества по картам в 2013 году в Европе превысило 1 млрд. евро. На Россию приходится 110 млн. евро, из них 2,4 млн. евро мошенничество при оплате через интернет.
Полная цепочка участников проведения online-платежа при покупке товара/услуги через интернет в общем случае выглядит приблизительно так:
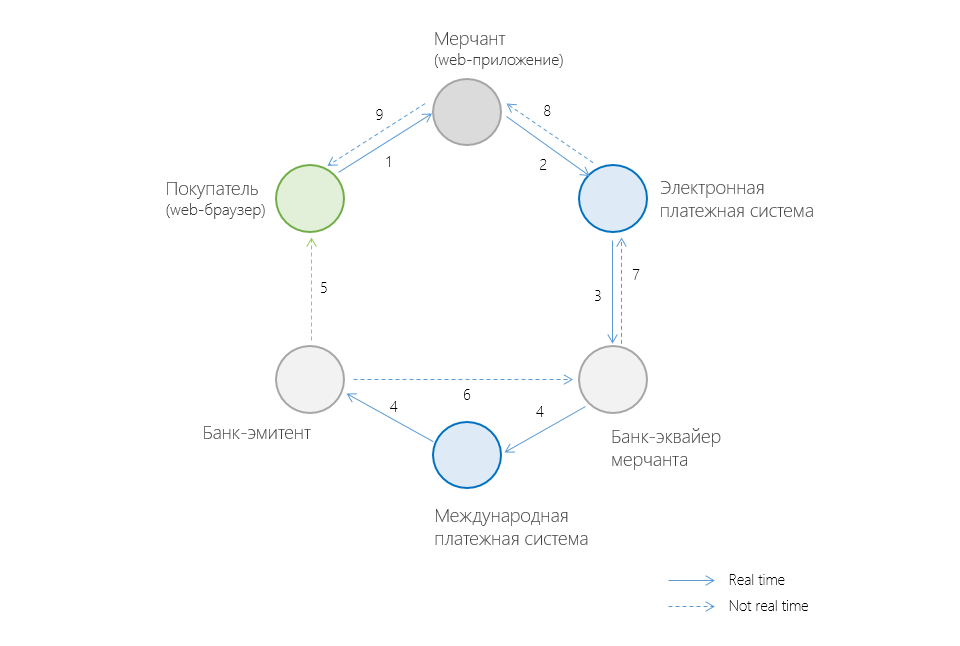
В первой части статьи я расскажу почему вопрос мошеннических платежей (fraud) стоит так остро для всех участников рынка электронных платежей – от интернет-магазинов до банков – и в чем основные сложности, из-за которых стоимость разработки таких систем подчас является слишком высокой для многих участников ecommerce-рынка.
Во второй части будут описаны требования технического и нетехнического характера, которые предъявляются к таким системам, и то, как я собираюсь снизить стоимость разработки и владения antifraud-системы на порядок(и).
В третьей части будет рассмотрена программная архитектура сервиса, его модульная структура и ключевые детали реализации.
В четвертой части статьи подробно обсудим наиболее сложную с технической точки зрения и наиболее интеллектуальную часть системы – аналитическую систему распознания мошеннических платежей.
Get Started!
Стремительный рост количества операций с пластиковыми картами, совершаемых через интернет, ставит перед разработчиками систем приема online-платежей все новые и новые вызовы, связанные с ростом масштаба таких систем и усложнением подходов к обеспечению их надежности и безопасности.
Не менее интенсивно растет количество мошеннических операций и разнообразие видов мошенничества. Россия, наряду с Англией, Францией, Германией, Испанией, входит в топ-5 европейский стран по годовому объему мошеннических операций с банковским картами. Общий объем потерь от мошенничества по картам в 2013 году в Европе превысило 1 млрд. евро. На Россию приходится 110 млн. евро, из них 2,4 млн. евро мошенничество при оплате через интернет.
Полная цепочка участников проведения online-платежа при покупке товара/услуги через интернет в общем случае выглядит приблизительно так:
Coursera открыла курсы эффективного обучения
2 мин
C 1 марта в Калифорнийском университете в Сан-Диего стартовал онлайн-курс, на котором расскажут, как учиться с высокой результативностью. Все ошибки учащихся, все приёмы и техники эффективной учебы будут рассмотрены на этом тренинге. Желающих участвовать — уже более 100 тысяч человек.
Lock-free структуры данных. Concurrent maps: rehash, no rebuild
6 мин
Пройдем по следам C++ 2015 Russia далее.
В предыдущей статье мы рассмотрели алгоритм для lock-free ordered list и на его основе сделали простейший lock-free hash map. У этого hash map есть недостаток: размер хеш-таблицы постоянен и не может быть изменен в процессе роста числа элементов в контейнере. Это не представляет проблемы, если мы заранее примерно представляем требуемый объем контейнера. А если нет?
Tarantool 1.6 от первого лица
3 мин
 Привет. Это пост о новой версии Тарантула «от автора». Интернет занятно устроен: если поискать про Тарантул, то найдётся статья от 2011 года, о версии 1.3. И ещё какой-то перфоратор, кажется. На форумах-бордах вообще стоит густой туман. Тарантул «ну это как Редис, только»…
Привет. Это пост о новой версии Тарантула «от автора». Интернет занятно устроен: если поискать про Тарантул, то найдётся статья от 2011 года, о версии 1.3. И ещё какой-то перфоратор, кажется. На форумах-бордах вообще стоит густой туман. Тарантул «ну это как Редис, только»… Или ещё, недавно сделал для себя открытие, на Тостере кто-то написал «София — это такое append-only хранилище по типу Тарантула». С такими постами я скоро стану фанатом сайта «сделано у нас», автомата Калашникова и Саяно-Шушенской ГЭС. Правда, мне сложно понять, почему мы восхищаемся западными инструментами, при этом представления не имеем о своих. Итак, Tarantool 1.6. В чём фишка?
Пишем поисковый плагин для Elasticsearch
7 мин
Туториал
Elaticsearch — популярный поисковый сервер и NoSQL база данных. Одной из интересных его особенностей является поддержка плагинов, которые могут расширить встроенный функционал и добавить немного бизнес-логики на уровень поиска. В этой статье я хочу рассказать о том, как написать такой плагин и тесты к нему.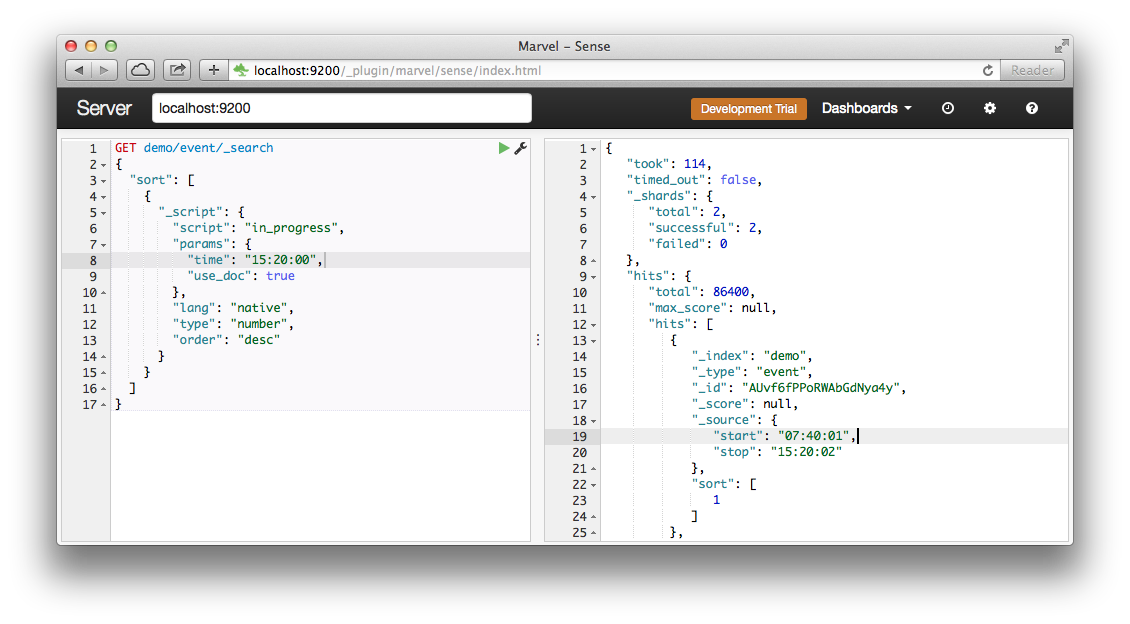
Сайт с нуля на полном стеке БЭМ-технологий. Методология Яндекса
29 мин
Туториал
На прошлой неделе BBC рассказала, что для новой версии главной страницы использовала методологию БЭМ, созданную в Яндексе. По такому случаю мы решили поднять материалы мастер-класса «Разрабатываем сайт с нуля на полном стеке БЭМ-технологий» и рассказать вам, как начать использовать полный стек БЭМ-технологий в своих проектах.
БЭМ упрощает разработку сайтов, которые нужно быстро создавать и долго поддерживать. Эту технологию используют во фронтенде почти всех сервисов Яндекса, и она уже успела обрасти множеством библиотек и инструментов, которыми мы хотим с вами поделиться.
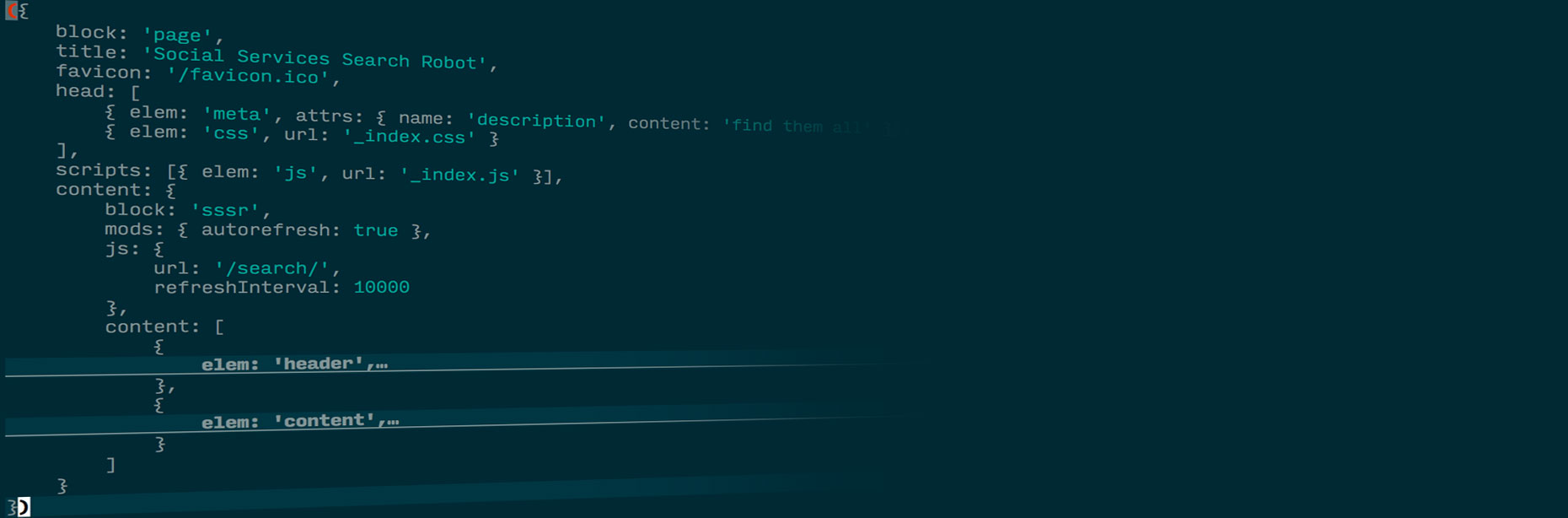
В статье мы расскажем, в чём преимущество вёрстки независимыми блоками и что такое уровни переопределения, познакомимся с готовыми библиотеками блоков и инструментами для автоматизации сборки. Покажем, как разные инструменты — например, autoprefixer, css-препроцессор Stylus или модульная система YModules — упрощают жизнь разработчика и создают по-настоящему удобную платформу, если встроить их в процесс разработки по БЭМ.
На живом примере мы объясним, в чём польза декларативного подхода, когда одни и те же идеи можно использовать как для CSS, так и для JavaScript. Отдельно остановимся на декларативных шаблонах BEMHTML и BEMTREE, которые позволяют преобразовывать данные в БЭМ-дерево, описанное в формате BEMJSON и, затем в HTML. Рассмотрим в деталях, как написать серверную часть приложения по БЭМ-методологии.
БЭМ упрощает разработку сайтов, которые нужно быстро создавать и долго поддерживать. Эту технологию используют во фронтенде почти всех сервисов Яндекса, и она уже успела обрасти множеством библиотек и инструментов, которыми мы хотим с вами поделиться.
В статье мы расскажем, в чём преимущество вёрстки независимыми блоками и что такое уровни переопределения, познакомимся с готовыми библиотеками блоков и инструментами для автоматизации сборки. Покажем, как разные инструменты — например, autoprefixer, css-препроцессор Stylus или модульная система YModules — упрощают жизнь разработчика и создают по-настоящему удобную платформу, если встроить их в процесс разработки по БЭМ.
На живом примере мы объясним, в чём польза декларативного подхода, когда одни и те же идеи можно использовать как для CSS, так и для JavaScript. Отдельно остановимся на декларативных шаблонах BEMHTML и BEMTREE, которые позволяют преобразовывать данные в БЭМ-дерево, описанное в формате BEMJSON и, затем в HTML. Рассмотрим в деталях, как написать серверную часть приложения по БЭМ-методологии.
Обработка логов с учётом предыдущих сообщений в logstash/elasticsearch
4 мин
Про отлов ядерных MCE (machine check error) и прочей гадости с помощью netconsole я писал недавно. Крайне полезная вещь. Одна проблема: throttling на CPU из-за локального перегрева (длительной нагрузки) фиксируется как MCE. Случается бэкап — и админам приходит страшное сообщение об MCE, которое на практике означает «чуть-чуть перегрелось» и точно не требует внимания к себе в 3 часа ночи.
Смехотворность проблемы ещё тем, что Linux фиксирует MCE после того, как throttling закончился. То есть режим 'normal', но вместо этого оно превращается MCE. Выглядит это так:
При этом мы точно хотим реагировать на нормальные MCE. Что делать?
В рамках logstash обработка сообщений предполагается stateless. Видишь сообщение — реагируешь. Внедрять же ради одного типа сообщений более сложную систему — оверкилл.
Казалось бы, есть фильтр (не путать с output) elasticsearch, который позволяет делать запросы. К сожалению, он не умеет делать 'if'ы, то есть remove_tag и add_tag будут отрабатывать вне зависимости от того, удался поиск или нет.
Грустно.
Смехотворность проблемы ещё тем, что Linux фиксирует MCE после того, как throttling закончился. То есть режим 'normal', но вместо этого оно превращается MCE. Выглядит это так:
CPU0: Core temperature above threshold, cpu clock throttled (total events = 40997) CPU4: Core temperature above threshold, cpu clock throttled (total events = 40997) CPU4: Core temperature/speed normal CPU0: Core temperature/speed normal mce: [Hardware Error]: Machine check events logged
При этом мы точно хотим реагировать на нормальные MCE. Что делать?
В рамках logstash обработка сообщений предполагается stateless. Видишь сообщение — реагируешь. Внедрять же ради одного типа сообщений более сложную систему — оверкилл.
Казалось бы, есть фильтр (не путать с output) elasticsearch, который позволяет делать запросы. К сожалению, он не умеет делать 'if'ы, то есть remove_tag и add_tag будут отрабатывать вне зависимости от того, удался поиск или нет.
Грустно.