
До сих пор Raspberry Pi остается одним из самых популярных технологических гаджетов.На эту плату Вы можете установить практически любую операционную систему. Но сегодня мы поговорим о том, как писать программы для этой платы без операционной системе, пользуясь лишь аппаратными средствами.
На первый взгляд задача кажется тривиальной: скачиваем keil, создаем проект… Но все не так просто. Все среды программирования(keil, IAR, Atolic) поддерживают максимум ARM9.У нас же ARM11. Это связано с негласным правилом, что на голом железе пишут до ARM9, а после на Линуксе. Но все-таки есть одна лазейка: arm-none-eabi-gcc поддерживает любой ARM.
Вторая проблема заключается в том, что под данный процессор(BCM2835) нет никаких конфигурационных файлов, header'ов и т.д. Здесь нам на помощь придет загрузчик Raspberry Pi. И ничего, что он пропритетарный. Он выполняет две функции: инициализирует процессор и его периферию, а также передает управление ядру kernel.img. Мы просто замаскируем свою программу под ядро и загрузчик её запустит.
В чем подвох?
На первый взгляд задача кажется тривиальной: скачиваем keil, создаем проект… Но все не так просто. Все среды программирования(keil, IAR, Atolic) поддерживают максимум ARM9.У нас же ARM11. Это связано с негласным правилом, что на голом железе пишут до ARM9, а после на Линуксе. Но все-таки есть одна лазейка: arm-none-eabi-gcc поддерживает любой ARM.
Вторая проблема заключается в том, что под данный процессор(BCM2835) нет никаких конфигурационных файлов, header'ов и т.д. Здесь нам на помощь придет загрузчик Raspberry Pi. И ничего, что он пропритетарный. Он выполняет две функции: инициализирует процессор и его периферию, а также передает управление ядру kernel.img. Мы просто замаскируем свою программу под ядро и загрузчик её запустит.

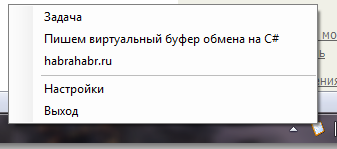 Очень много приходится работать с текстовыми данными, такими как код, статьи, посты и т.д. В то время когда жил под Linux — пользовался менеджерами истории буфера обмена, которые запоминали, то что попадало в виде текста в буфер и по клику в трее я мог вернуть нужное значение в буфер, не возвращаясь к источнику.
Очень много приходится работать с текстовыми данными, такими как код, статьи, посты и т.д. В то время когда жил под Linux — пользовался менеджерами истории буфера обмена, которые запоминали, то что попадало в виде текста в буфер и по клику в трее я мог вернуть нужное значение в буфер, не возвращаясь к источнику.
 Однажды я столкнулся с задачей генерации 128-битных случайных чисел для реализации генетического алгоритма. Из-за большой размерности задачи алгоритм гонялся долго, поэтому были повышенные требования к скорости работы. Я решил написать свой генератор специально для поставленной задачи.
Однажды я столкнулся с задачей генерации 128-битных случайных чисел для реализации генетического алгоритма. Из-за большой размерности задачи алгоритм гонялся долго, поэтому были повышенные требования к скорости работы. Я решил написать свой генератор специально для поставленной задачи.




{kind=link}