Вас интересуют игры? Хотите создать игру но не знаете с чего начать? Тогда вам сюда. В этой статье я рассмотрю простейший физический движок, с построения которого можно начать свой путь в GameDev'e. И да, движок будем писать с нуля.

ciiccii @ciiccii
User
Таблицы сопряженности и факторизация неотрицательных матриц
6 min
Факторизация неотрицательных матриц (NMF) — это представление матрицы V в виде произведения матриц W и H, в котором все элементы трех матриц неотрицательны. Это разложение используется в различных областях знаний, например, в биологии, компьютерном зрении, рекомендательных системах. В этой публикации пойдет речь о таблицах сопряженности социологических и маркетинговых данных, факторизация которых помогает понять структуру данных этих таблиц.

Введение в машинное обучение с помощью scikit-learn (перевод документации)
6 min
Данная статья представляет собой перевод введения в машинное обучение, представленное на официальном сайте scikit-learn.
В этой части мы поговорим о терминах машинного обучения, которые мы используем для работы с scikit-learn, и приведем простой пример обучения.
В общем, задача машинного обучения сводится к получению набора выборок данных и, в последствии, к попыткам предсказать свойства неизвестных данных. Если каждый набор данных — это не одиночное число, а например, многомерная сущность (multi-dimensional entry или multivariate data), то он должен иметь несколько признаков или фич.
Машинное обчение можно разделить на несколько больших категорий:
В этой части мы поговорим о терминах машинного обучения, которые мы используем для работы с scikit-learn, и приведем простой пример обучения.
Машинное обучение: постановка вопроса
В общем, задача машинного обучения сводится к получению набора выборок данных и, в последствии, к попыткам предсказать свойства неизвестных данных. Если каждый набор данных — это не одиночное число, а например, многомерная сущность (multi-dimensional entry или multivariate data), то он должен иметь несколько признаков или фич.
Машинное обчение можно разделить на несколько больших категорий:
- обучение с учителем (или управляемое обучение). Здесь данные представлены вместе с дополнительными признаками, которые мы хотим предсказать. (Нажмите сюда, чтобы перейти к странице Scikit-Learn обучение с учителем). Это может быть любая из следующих задач:
- классификация: выборки данных принадлежат к двум или более классам и мы хотим научиться на уже размеченных данных предсказывать класс неразмеченной выборки. Примером задачи классификации может стать распознавание рукописных чисел, цель которого — присвоить каждому входному набору данных одну из конечного числа дискретных категорий. Другой способ понимания классификации — это понимание ее в качестве дискретной (как противоположность непрерывной) формы управляемого обучения, где у нас есть ограниченное количество категорий, предоставленных для N выборок; и мы пытаемся их пометить правильной категорией или классом.
- регрессионный анализ: если желаемый выходной результат состоит из одного или более непрерывных переменных, тогда мы сталкиваемся с регрессионным анализом. Примером решения такой задачи может служить предсказание длинны лосося как результата функции от его возраста и веса.
- обучение без учителя (или самообучение). В данном случае обучающая выборка состоит из набора входных данных Х без каких-либо соответствующих им значений. Целью подобных задач может быть определение групп схожих элементов внутри данных. Это называется кластеризацией или кластерным анализом. Также задачей может быть установление распределения данных внутри пространства входов, называемое густотой ожидания (density estimation). Или это может быть выделение данных из высоко размерного пространства в двумерное или трехмерное с целью визуализации данных. (Нажмите сюда, чтобы перейти к странице Scikit-Learn обучение без учителя).
Топ-10 data mining-алгоритмов простым языком
24 min
Translation

Примечание переводчика: Мы довольно часто пишем об алгоритмической торговле (вот, например, список литературы по этой теме и соответствующие аналитические материалы) и API для создания торговых роботов, сегодня же речь пойдет непосредственно об алгоритмах, которые можно использовать для анализа различных данных (в том числе на финансовом рынке). Материал является адаптированным переводом статьи американского раработчика и аналитика Рэя Ли.
Сегодня я постараюсь объяснить простыми словами принципы работы 10 самых эффективных data mining-алгоритмов, которые описаны в этом докладе.
Когда вы узнаете, что они собой представляют, как работают, что делают и где применяются, я надеюсь, что вы используете эту статью в качестве отправной точки для дальнейшего изучения принципов data mining.
Анализ открытых данных в R, часть 1
5 min
Введение
На момент написания статьи большинство приложений на основе открытых данных (на официальных сайтах data.mos.ru/apps и data.gov.ru) представляют собой интерактивные справочники по инфраструктуре города или поселения с наглядной визуализацией и часто с опцией выбора оптимального маршрута. Цель этой и последующих публикаций состоит в том, чтобы привлечь внимание сообщества к обсуждению стратегий анализа открытых данных, в т.ч. направленных на прогнозирование, построение статистических моделей и извлечение информации, не представленной в явном виде. В качестве инструментария используется язык R и среда разработки RStudio.
Шифруем и перешифровываем LUKS без потери данных
3 min
Введение
Если вы когда-либо задумывались о шифровании данных на дисках уже после того, как у вас накопилось их приличное количество, вы, вероятно, расстраивались, прочитав о необходимости переноса данных перед созданием шифрованного раздела и после. Перенос 500 ГБ туда и обратно не представляет никакой особой трудности, такой объем можно временно загрузить даже в облако, но если речь идет о шифровании 6 винчестеров по 4 ТБ каждый, задача заметно усложняется. По какой-то причине, возможность шифрования и перешифровывания томов LUKS без потери данных (in-place re-encryption) слабо освещена в интернете, хотя для этого есть две утилиты: cryptsetup-reencrypt, входящая в состав cryptsetup с 2012 года, и сторонняя luksipc, появившаяся на год раньше. Обе утилиты выполняют, в общем-то, одно и то же — шифруют раздел, если он не был шифрован, либо перешифровывают уже существующий с другими параметрами. Для своих нужд я воспользовался первой, официальной.Как это работает?
Предположим, у вас типичная разметка диска: один раздел, начинается с 1 МиБ (выравнивание для 4КиБ-секторов), заканчивается в конце диска.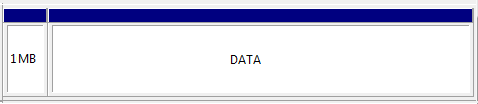
Заголовок LUKS располагается в начале, перед зашифрованными данными. Для заголовка требуется минимум 2056 512-байтных секторов, т.е. чуть больше 1МиБ. Места перед началом раздела нам явно недостаточно, поэтому сначала нужно уменьшить размер файловой системы с ее конца, чтобы cryptsetup-reencrypt перенес блоки правее, в конец диска, освободив таким образом место в начале раздела для LUKS-заголовка. Конечный размер заголовка зависит от длины ключа, количества слотов для парольных фраз и прочих параметров, поэтому я рекомендую быть рачительным и отвести под заголовок 4 МиБ.
Очередной умный дом, в трех частях. Часть третья, пользовательско-интерфейсная
4 min
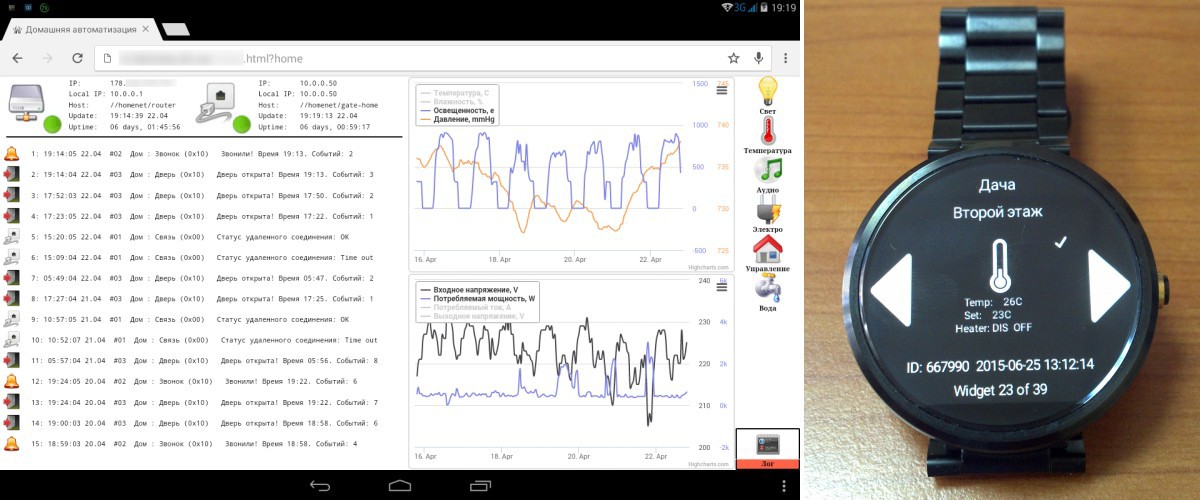
Итак, подошло время рассказать и показать как это все управляется. Как я уже говорил во второй части, после нескольких итераций — все остановилось на HTML + JS. Писать отдельное приложение под Android я не планировал, но жизнь, как обычно, внесла некоторые коррективы.
Ссылки на первые две части:
Ссылки на первые две части:
Детекция кожи в Wolfram Language (Mathematica)
5 min
Translation

Перевод поста Matthias Odisio "Seeing Skin with Mathematica".
Скачать файл, содержащий текст статьи, интерактивные модели и весь код, приведенный в статье, можно здесь.
Выражаю огромную благодарность Кириллу Гузенко за помощь в переводе.
Детекция кожи может быть довольно полезной — это один из основных шагов к более совершенным системам, нацеленным на обнаружение людей, распознавание жестов, лиц, фильтрации на основе содержания и прочего. Несмотря на всё вышеперечисленное, моя мотивация при создании приложения заключалась в другом. Отдел разработки и исследований в Wolfram Research, в котором я работаю, подвергся небольшой реорганизации. С моими коллегами, которые занимаются вероятностями и статистикой, которые стали находиться ко мне значительно ближе, я решил разработать небольшое приложение, которое использовало бы как функционал по обработке изображений в Mathematica, так и статистические функции. Детекция кожи — первое, что пришло мне в голову.
Оттенки кожи и внешность могут варьироваться, что усложняет задачу детекции. Детектор, который я хотел разработать, основывается на вероятностных моделях для цветов пикселей. Для каждого пикселя изображения, поданного на вход, детектор кожи выдаёт вероятность того, что этот пиксель принадлежит области кожи.

Визуализация результатов в R: первые шаги
5 min
В одном из предыдущих постов мы уже писали о центральном понятии в статистике — p-уровне значимости. И пока в научной среде не утихают споры об интерпретации p-value, значительная часть исследований проводится именно с использованием p-value для определения значимости полученных в исследовании различий. Сегодня же мы поговорим о самом творческом этапе обработки данных — как же значимые различия визуализировать.
Введение в магию шаблонов
5 min
Tutorial
Шаблоны в С++ являются средствами метапрограммирования и реализуют полиморфизм времени компиляции. Что это такое?
Это когда мы пишем код с полиморфным поведением, но само поведение определяется на этапе компиляции — т.е., в противовес полиморфизму виртуальных функций, полученный бинарный код уже будет иметь постоянное поведение.
Это когда мы пишем код с полиморфным поведением, но само поведение определяется на этапе компиляции — т.е., в противовес полиморфизму виртуальных функций, полученный бинарный код уже будет иметь постоянное поведение.
Автоматизированное создание диаграмм в xkcd-стиле: из серьёзного в забавное
5 min
Translation

Перевод поста Виталия Каурова "Automating xkcd Diagrams: Transforming Serious to Funny".
Скачать файл, содержащий текст статьи, интерактивные модели и весь код, приведенный в статье, можно здесь.
Выражаю огромную благодарность Кириллу Гузенко за помощь в переводе.
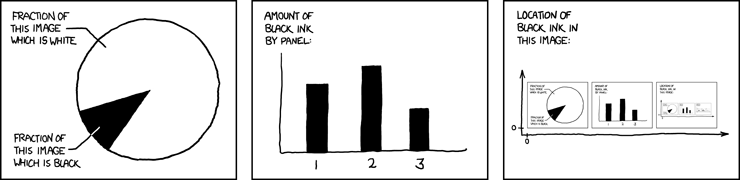
Утром в понедельник я наткнулся на интересный вопрос, опубликованный в Mathematica Stack Exchange, с нехитрым заголовком — "создание графиков в xkcd-стиле". Из-за популярности веб-комиксов xkcd Рэндалла Манро (Randall Munroe), я ожидал, что люди добавят себе несколько закладок этой страницы и с десяток up-vote. Тогда я ещё не знал, как всё обернётся. Сложно предсказать вирусность какого-то мема, однако если удалось создать такой, то весьма здорово наблюдать, как растёт его популярность и как он распространяется в интернете. Через два дня этот пост имел уже более 100 тысяч просмотров, двести up-vote и 150 закладок; стали возникать ответы и схожие посты в других разделах Stack Exchange, в Twitter разразился небольшой ураган по этому поводу, появлялись обсуждения в Hacker News и reddit. Тут я приведу оригинал поста Amatya с примером изображения в xkcd-стиле:
«Я получил электронное письмо, на которое я захотел ответить с графиком в xkcd-стиле, но я не мог справиться с этим. Всё, что я рисовал, выглядело как надо, однако я не мог придумать такой команды для Plot Legends, чтобы сделать фрагменты текста плавающими. Может, есть какие-то идеи, как можно было бы создать графики в xkcd-стиле? Когда всё выглядит рисованным от руки и неточным. Думаю, рисование таких странных кривых в Mathematica должно быть трудным в реализации.»

Автомат как реактивный двигатель: реальная физика нереального полёта
5 min
Translation

Перевод поста Malte Lenz "Machine Gun Jetpack: The Real Physics of Improbable Flight".
Скачать файл с моделями, рассмотренными в посте, можно здесь здесь.
Выражаю огромную благодарность Кириллу Гузенко за помощь в переводе.
Можно ли летать с помощью автомата, используя реактивную силу, возникающую при выстрелах? Этот вопрос был задан в статье What if? Рэндалла Манроу “Machine Gun Jetpack” (перевод поста на русский язык). Оказывается что можно, потому что некоторые автоматы создают достаточную силу для того, чтобы поднимать свой собственный вес, а может даже и немного больше. В этом посте я исследую динамику стреляющих вниз автоматов, а так же действующие при этом силы, порождаемые скорости и то, на какую высоту можно будет подняться таким способом. Я так же продублирую предупреждение из статьи: пожалуйста, не повторяйте этого дома. Для этого есть программные среды для моделирования.
Самодельный блок управления для дизельного двигателя
10 min

Автомобили уже давно обросли всякой электроникой, так обросли, что просто жуть: в дверях контроллер, в фарах контроллер, в тормозах контроллер, ну и в двигателе, как без него. Обычно, когда речь заходит о блоке управления двигателем (ECU) представляется бензиновый мотор, обвешанный датчиками, исполнительными элементами и жгутами проводов. Блок управления чутко считывает параметры датчиков, корректирует смесь и начало искрообразования. Сложно! Но энтузиасты создают свои блоки управления, пишут альтернативные прошивки чтобы выжать лишнюю «пони», обойти какую-то неисправность или просто для повышения навыков. Причем, как правило, на такой шаг авторов толкают обстоятельства, к примеру недовольство контактной системой зажигания у бензиновых моторов, легкий некомплект электрики и так далее.
Именно о таких обстоятельствах и о дизельном двигателе и пойдет речь.
Итак, постановка задачи:
Дано:
- Дизельный двигатель с механическим насосом DW8, производства концерна PSA, 2000 г.в. Насос издох от времени.
- Новый топливный насос, приобретенный по случаю, с электронным управлением опережения впрыска от модификации мотора DW8B (Те самые обстоятельства).
- Полное отсутствие проводки под электронное управление, самого блока управления.
- Желание разобраться с нехитрой электроникой насоса, поднять навык, поглубже изучить работу таких насосов.
Требуется: исправный двигатель после «сращения».
Андроиды в дельфинарии
6 min
Приветствую всех любителей тех устройств, что помещаются в карман, а также тех, кто держит свой карман шире 7". Сейчас мы займемся искусством программирования кросс-платформенных графических приложений, то есть таких приложений, которые работают на мобильной платформе (смартфоны и планшеты Android) и под Windows (стационарные PC, ноутбуки, нетбуки, планшеты). При этом наши приложения будут графическими, графика основана на OpenGL (OGL) и его мобильном варианте OpenGL ES (GLES). Я использую Embarcadero Delphi XE7. Важная особенность – в этом проекте я не использую платформу FM (FireMonkey), мы будем писать все сами и с нуля, как в старые добрые времена.

Vectorization Advisor, ещё один пример — разгоняем фрактал
6 min
Мы недавно уже писали о новом Vectorization Advisor. О том, что это такое и зачем нужно, читайте в первой статье. Этот же пост посвящён разбору конкретного примера оптимизации приложения с помощью этого инструмента.
Приложение взято из примеров библиотеки Intel Threading Building Blocks (Intel TBB). Оно рисует фрактал Мандельброта и распараллелено по потокам с помощью Intel TBB. Т.е. преимущества многоядерного процессора оно использует — посмотрим, как обстоят дела с векторными инструкциями.
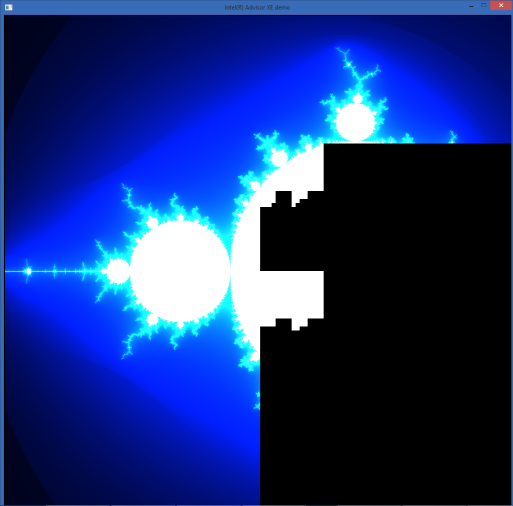
Приложение взято из примеров библиотеки Intel Threading Building Blocks (Intel TBB). Оно рисует фрактал Мандельброта и распараллелено по потокам с помощью Intel TBB. Т.е. преимущества многоядерного процессора оно использует — посмотрим, как обстоят дела с векторными инструкциями.
Виртуальный учебник Wolfram Language (Mathematica)
1 min
Translation

Скачать учебник на русском языке
Скачать учебник на украинском языке
В документацию системы Wolfram Mathematica встроен виртуальный учебник, который подробно рассказывает о базовых принципах языка Wolfram Language, а также на множестве примеров показывает то, как его можно применять в самых разных областях знаний.
Этот учебник содержит в себе 356 статей, общий объем которых составляет несколько тысяч печатных страниц.
Мне радостно сообщить, что этот учебник теперь переведен на украинский и русский языки.
Перевод учебника делался довольно длительное время Андреем Михайловичем Зеленицей (сотрудником официального дистрибьютора продукции компании Wolfram Research на Украине, компании "Бакотек").
Распознавание физической активности пользователей с примерами на R
8 min
Tutorial
Задача распознавания физической активности пользователей (Human activity Recognition или HAR) попадалась мне раньше только в качестве учебных заданий. Открыв для себя возможности Caret R Package, удобной обертки для более 100 алгоритмов машинного обучения, я решил попробовать его и для HAR. В UCI Machine Learning Repository есть несколько наборов данных для таких экспериментов. Так как тема с гантелями для меня не очень близка, я выбрал распознавание активности пользователей смартфонов.
Высокопроизводительное сжатие DEFLATE с оптимизацией для геномных наборов данных
7 min
Translation

igzip — высокопроизводительная библиотека для выполнения сжатия gzip или DEFLATE. Она была изначально описана в статье Высокопроизводительное сжатие DEFLATE для процессоров с архитектурой Intel. В этой статье описывается связанный выпуск исходного кода, содержащий необязательные (во время сборки) оптимизации для повышения степени сжатия геномных наборов данных в форматах BAM и SAM. igzip работает примерно в 4 раза быстрее, чем Zlib при настройке на максимальную скорость, и с примерно такой же степенью сжатия для геномных данных. Мы считаем, что igzip можно схожим образом оптимизировать для других областей применения, где наборы данных отличаются от обычных текстовых данных.
Дискретное преобразование Фурье фрактального броуновского движения
2 min
Фрактальное броуновское движение (ФБД) относится к классу рассматриваемых функций, заданные на конечном интервале и равные нулю вне его, которые включают кусочно непрерывные функции, удовлетворяющие условию роста:
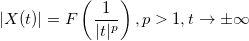 ,
,
где функция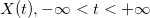 , удовлетворяет условию:
, удовлетворяет условию: 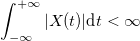
Преобразование Фурье
Для ФБД будем интерпретировать процесс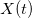 как временной процесс. Существует частотная область, в которой функция — сумма составляющих, имеющих определенную частоту. Функция может быть разложена как
как временной процесс. Существует частотная область, в которой функция — сумма составляющих, имеющих определенную частоту. Функция может быть разложена как 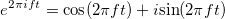 .
.
Составляющая с частотой 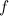 имеет вид:
имеет вид:
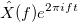 , где
, где 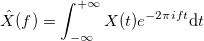 .
.
Функция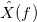 называется преобразованием Фурье.
называется преобразованием Фурье.
,где функция
, удовлетворяет условию: Преобразование Фурье
Для ФБД будем интерпретировать процесс
как временной процесс. Существует частотная область, в которой функция — сумма составляющих, имеющих определенную частоту. Функция может быть разложена как .Составляющая
с частотой имеет вид:, где .Функция
называется преобразованием Фурье.Анализ изображений и видео. Классификация изображений и распознавание объектов
1 min
Сегодня мы публикуем седьмую лекцию из курса «Анализ изображений и видео», прочитанного Натальей Васильевой в петербургском Computer Science Center, который создан по совместной инициативе Школы анализа данных Яндекса, JetBrains и CS-клуба.
Всего в программе девять лекций, из которых уже были опубликованы:
Под катом вы найдете план новой лекции и слайды.
Всего в программе девять лекций, из которых уже были опубликованы:
- Введение в курс «Анализ изображений и видео»;
- Основы пространственной и частотной обработки изображений;
- Морфологическая обработка изображений;
- Построение признаков и сравнение изображений: глобальные признаки;
- Построение признаков и сравнение изображений: локальные признаки;
- Поиск по подобию. Поиск нечетких дубликатов.
Под катом вы найдете план новой лекции и слайды.