Когда Пифагор плыл по реке Хуанхэ, он увидел у берега, в лодке, задремавшего рыбака, в конической шляпе и с бамбуковой удочкой в руках.

Владислав Марчевский @comratvlad
Lead Researcher at SpeechPro
Директор по здравому смыслу: как перестать все контролировать и начать работать в команде
7 min
Эта статья — вольный пересказ моего доклада на прошедшем Хайлоаде.
Я возглавляю компанию, в которой работает 75 человек, а начинали мы 10 лет назад впятером.
И я хотел бы рассказать как, со временем, и почему менялась система менеджмента, какие основные ошибки мы совершили, как их исправляли, и чему научились по этому поводу.

А вы еще не платите премию за вовремя сделанные проекты?
3 min
Беседовал я как-то с техническим директором одного из крупнейших банков России. В какой-то момент речь у нас зашла о премировании сотрудников. Тогда я ему говорю, что у нас в компании есть премирование сотрудников за вовремя сделанные проекты и задачи. Тут он завис секунд на пять, долгое молчание, недоумение в глазах:
– Кхм… Так за это же программистам зарплату платят! – говорит он.
– Да, платят. Но если изучить статистику успешных проектов в IT, становится грустно и хочется платить премию за выполненные в срок задачи.
Попрощались мы, так и не придя к общему мнению по этому вопросу. В этой статье я и предлагаю разобраться, следует ли платить премию программистам за вовремя сделанные задачи и проекты. И вообще, когда стоит платить премии.
– Кхм… Так за это же программистам зарплату платят! – говорит он.
– Да, платят. Но если изучить статистику успешных проектов в IT, становится грустно и хочется платить премию за выполненные в срок задачи.
Попрощались мы, так и не придя к общему мнению по этому вопросу. В этой статье я и предлагаю разобраться, следует ли платить премию программистам за вовремя сделанные задачи и проекты. И вообще, когда стоит платить премии.
Вы работаете не в том месте (если у вас офис открытого типа)
6 min
Translation
Что такое физическое пространство?
На последней работе всё самое лучшее я сделал дома. Я активно пытался избегать офиса насколько возможно. Дома у меня два стола и полный контроль над окружением. Альтернатива — отвлечения и помехи.

Мой домашний офис — крепость производительности
Когда я заходил в офис, окружение изменялось. Здесь постоянно всё отвлекало: другие сотрудники, лающие собаки (отмечу: маленькие собачонки не в счёт), импровизированные совещания и празднование дней рождения. Было очень сложно перейти в состояние потока и невероятно легко выйти из него. Среди всех мест, где я мог бы работать, стол в офисе, наверное, был худшим вариантом.
Когда я нахожусь в переполненном пространстве, мои мысли тоже переполняются. Я чувствую подавленность стимулами и неспособность их избежать. Для сравнения, когда есть пространство (ментальное и физическое), я способен разобраться и понять свои мысли и ментальные предпосылки. Качество мышления значительно возрастает.
Я осознал, что ненавижу офисы открытого типа.
Типичные проблемы IT-стартапов, которые мешают быстро развиваться, и как их избежать
10 min
На онлайн-конференции ФРИИ «Как построить бизнес на основе технологий» Звиад Кардава, ответственный за developer relations в Google, рассказал о проблемах технологических стартапов в разработке, развитии продукта и управлении процессами, и как их можно решить или избежать.

Как мы музицировали с нейронными сетями
5 min
В 2016 год Google Brain Group выпустил проект Magenta в открытый доступ. Magenta позиционируется как проект, который задает и отвечает на вопросы:«Можем ли мы использовать машинное обучение для создания музыки и искусства достойных внимания? Если да, то как? Если нет, то почему нет?». Вторая цель проекта — это построить сообщество художников, музыкантов и исследователей в области машинного обучения.
Интересные логические задачки на собеседованиях
2 min

Добрый день, Хабровчане!
Собеседование, особенно если ты его не прошёл :), вещь не очень приятная. Но мой папа — преподаватель математики часто говорил, что экзамен — это не только способ оценить знания, а и самый действенный метод обучения. Именно на экзамене (в данном случае собеседовании) человек как никогда мотивирован и его мозг работает на все 100%.
Кроме того на собеседовании иногда задают очень интересные логические задачки. Вот именно о них я и хочу написать.
Итак, самые интересные задачки которые мне задавали на собеседовании:
Задачка 1: Про бассейн, лодку и гирю
Есть маленький бассейн. В нём плавает лодка. На стенке бассейна отмечен текущий уровень воды.
Ещё есть чугунная гиря. В каком случае уровень воды в бассейне поднимется больше: если опустить гирю в воду, или если опустить гирю в лодку?
Code review по-человечески (часть 1)
14 min
Tutorial
Translation
 В последнее время я читал статьи о лучших практиках code review и заметил, что эти статьи фокусируются на поиске багов, практически игнорируя другие компоненты ревью. Конструктивное и профессиональное обсуждение обнаруженных проблем? Неважно! Просто найди все баги, а дальше само сложится.
В последнее время я читал статьи о лучших практиках code review и заметил, что эти статьи фокусируются на поиске багов, практически игнорируя другие компоненты ревью. Конструктивное и профессиональное обсуждение обнаруженных проблем? Неважно! Просто найди все баги, а дальше само сложится.Так что у меня случилось откровение: если это работает для кода, то почему не будет работать в романтичных отношениях? Итак, встречайте новую электронную книгу, которая поможет программистам в отношениях со своими возлюбленными (обложка на иллюстрации слева).
Моя революционная книга обучит вас проверенным техникам по выявлению максимального количества недостатков в своём партнёре. Книга не затрагивает следующие области:
• Обсуждение проблем с сочувствием и пониманием.
• Помощь партнёру в устранении недостатков.
Насколько я могу понять из чтения литературы по code review, эти части отношений настолько очевидны, что вообще не стоят обсуждения.
Как вам нравится такая книжка? Предполагаю, что она вам не очень по душе.
Code review по-человечески (часть 2)
11 min
Translation

Это вторая часть статьи о том, как правильно общаться и избежать ошибок в процессе код-ревью. Здесь мы поговорим о том, как довести ревью до конца и избежать неприятных конфликтов.
Основы изложены в первой части, так что рекомендую начать с неё. Но если не терпится, вот её краткое содержание: хороший рецензент не только ищет баги, но и обеспечивает добросовестную обратную связь, чтобы помочь коллеге повысить свой уровень.
Моё худшее код-ревью
Худшее код-ревью в моей жизни было для бывшей коллеги, назовём её Мэллори. Она начала работать в компании за несколько лет до меня, но только недавно перешла в мой отдел.
Как обнаружить миллион долларов на своём аккаунте AWS
15 min
Tutorial
Translation
Недавно мы рассказали о способах, с помощью которых сэкономили более миллиона долларов на годовом обслуживании AWS. Хотя мы подробно рассказывали о различных проблемах и решениях, всё равно самым популярным вопросом был: «Я знаю, что слишком много трачу на AWS, но как в реальности разбить эти траты на понятные части?»
На первый взгляд, проблема кажется довольно простой.
Вы можете легко разбить свои расходы AWS по месяцам и закончить на этом. Десять тысяч долларов на EC2, одна тысяча на S3, пятьсот долларов на сетевой трафик и т.д. Но здесь отсутствует кое-что важное — на сочетание каких именно продуктов и групп разработки приходится львиная доля расходов.
И учтите, что у вас могут меняться сотни инстансов и миллионы контейнеров. Вскоре то, что поначалу казалось простой аналитической проблемой, становится невообразимо сложным.
В этом продолжении статьи мы хотели бы поделиться информацией о наборе инструментов, который сами используем. Надеемся, что сумеем предложить несколько идей, как анализировать свои затраты AWS независимо от того, работает у вас парочка инстансов или десятки тысяч.
На первый взгляд, проблема кажется довольно простой.
Вы можете легко разбить свои расходы AWS по месяцам и закончить на этом. Десять тысяч долларов на EC2, одна тысяча на S3, пятьсот долларов на сетевой трафик и т.д. Но здесь отсутствует кое-что важное — на сочетание каких именно продуктов и групп разработки приходится львиная доля расходов.
И учтите, что у вас могут меняться сотни инстансов и миллионы контейнеров. Вскоре то, что поначалу казалось простой аналитической проблемой, становится невообразимо сложным.
В этом продолжении статьи мы хотели бы поделиться информацией о наборе инструментов, который сами используем. Надеемся, что сумеем предложить несколько идей, как анализировать свои затраты AWS независимо от того, работает у вас парочка инстансов или десятки тысяч.
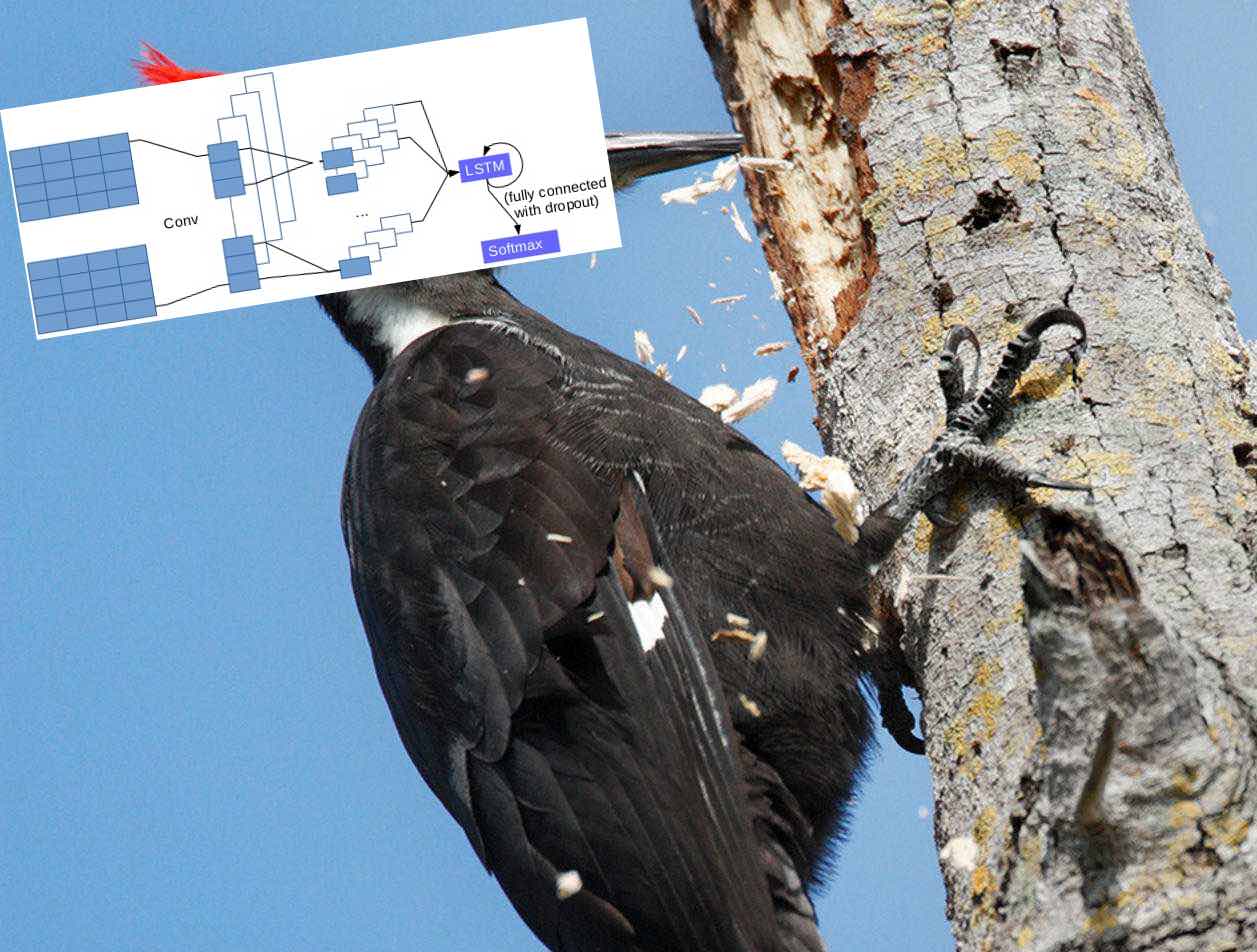
Как мозг бьет дерево, или как мы сделали рекомендательную систему с помощью нейронной сети
8 min
Как бы вы сделали рекомендательную систему? У многих в голове сразу появилась картина как они импортят и стакают XGBoost CatBoost. Изначально у нас в голове появилась та же картина, но мы решили на волне хайпа сделать это на нейронных сетях, благо времени было много. Опыт их создания, тестирование, результаты и наши мысли описаны далее.
Web Scraping с помощью python
7 min
Введение
Недавно заглянув на КиноПоиск, я обнаружила, что за долгие годы успела оставить более 1000 оценок и подумала, что было бы интересно поисследовать эти данные подробнее: менялись ли мои вкусы в кино с течением времени? есть ли годовая/недельная сезонность в активности? коррелируют ли мои оценки с рейтингом КиноПоиска, IMDb или кинокритиков?
Но прежде чем анализировать и строить красивые графики, нужно получить данные. К сожалению, многие сервисы (и КиноПоиск не исключение) не имеют публичного API, так что, приходится засучить рукава и парсить html-страницы. Именно о том, как скачать и распарсить web-cайт, я и хочу рассказать в этой статье.
В первую очередь статья предназначена для тех, кто всегда хотел разобраться с Web Scrapping, но не доходили руки или не знал с чего начать.
Off-topic: к слову, Новый Кинопоиск под капотом использует запросы, которые возвращают данные об оценках в виде JSON, так что, задача могла быть решена и другим путем.
Как правильно оформить Open Source проект
7 min
Tutorial
В свободное и не свободное время[1] я развиваю несколько своих проектов на github, а также, по мере сил, участвую в жизни интересных для меня, как программиста, проектах.
Недавно один из коллег попросил консультацию: как выложить разработанную им библиотеку на github. Библиотека никак не связана с бизнес-логикой приложения компании, по сути это адаптер к некоему API, реализующему определённый стандарт. Помогая ему, я понял что вещи, интуитивно понятные и давно очевидные для меня, в этой области, совершенно неизвестны человеку делающему это впервые и далёкому от Open Source.
Я провел небольшое исследование и обнаружил что большинство публикаций по этой теме на habrahabr освещают тему участия (contributing), либо просто мотивируют каким-нибудь образом примкнуть к Open Source, но не дают исчерпывающей инструкции как правильно оформить свой проект. В целом в рунете, если верить Яндекс, тема освещена со стороны мотивации, этикета контрибуции и основ пользования github. Но не с точки зрения конкретных шагов, которые следует предпринять.
Так что из себя представляет стильный, модный, молодёжный Open Source проект в 201* году?
Краткий курс машинного обучения или как создать нейронную сеть для решения скоринг задачи
28 min
Tutorial
Мы часто слышим такие словесные конструкции, как «машинное обучение», «нейронные сети». Эти выражения уже плотно вошли в общественное сознание и чаще всего ассоциируются с распознаванием образов и речи, с генерацией человекоподобного текста. На самом деле алгоритмы машинного обучения могут решать множество различных типов задач, в том числе помогать малому бизнесу, интернет-изданию, да чему угодно. В этой статье я расскажу как создать нейросеть, которая способна решить реальную бизнес-задачу по созданию скоринговой модели. Мы рассмотрим все этапы: от подготовки данных до создания модели и оценки ее качества.
Если тебе интересно машинное обучение, то приглашаю в «Мишин Лернинг» — мой субъективный телеграм-канал об искусстве глубокого обучения, нейронных сетях и новостях из мира искусственного интеллекта.
Вопросы, которые разобраны в статье:
• Как собрать и подготовить данные для построения модели?
• Что такое нейронная сеть и как она устроена?
• Как написать свою нейронную сеть с нуля?
• Как правильно обучить нейронную сеть на имеющихся данных?
• Как интерпретировать модель и ее результаты?
• Как корректно оценить качество модели?
PyTorch — ваш новый фреймворк глубокого обучения
22 min

PyTorch — современная библиотека глубокого обучения, развивающаяся под крылом Facebook. Она не похожа на другие популярные библиотеки, такие как Caffe, Theano и TensorFlow. Она позволяет исследователям воплощать в жизнь свои самые смелые фантазии, а инженерам с лёгкостью эти фантазии имплементировать.
Данная статья представляет собой лаконичное введение в PyTorch и предназначена для быстрого ознакомления с библиотекой и формирования понимания её основных особенностей и её местоположения среди остальных библиотек глубокого обучения.
Как понять, что ваша предсказательная модель бесполезна
15 min
При создании продуктов на основе машинного обучения возникают ситуации, которых хотелось бы избежать. В этом тексте я разбираю восемь проблем, с которыми сталкивался в своей работе.
Мой опыт связан с моделями кредитного скоринга и предсказательными системами для промышленных компаний. Текст поможет разработчиками и дата-сайнтистам строить полезные модели, а менеджерам не допускать грубых ошибок в проекте.

Этот текст не призван прорекламировать какую-нибудь компанию. Он основан на практике анализа данных в компании ООО "Ромашка", которая никогда не существовала и не будет существовать. Под "мы" я подразумеваю команду из себя и моих воображаемых друзей. Все сервисы, которые мы создавали, делались для конкретного клиента и не могут быть проданы или переданы иным лицам.
Какие модели и для чего?
Пусть предсказательная модель — это алгоритм, который строит прогнозы и позволяет автоматически принимать полезное для бизнеса решение на основе исторических данных.
Параллелизм против многопоточности против асинхронного программирования: разъяснение
4 min
Хочу представить вашему вниманию перевод статьи Concurrency vs Multi-threading vs Asynchronous Programming: Explained.
В последние время, я выступал на мероприятиях и отвечал на вопрос аудитории между моими выступлениями о Асинхронном программировании, я обнаружил что некоторые люди путали многопоточное и асинхронное программирование, а некоторые говорили, что это одно и тоже. Итак, я решил разъяснить эти термины и добавить еще одно понятие Параллелизм. Здесь есть две концепции и обе они совершенно разные, первая синхронное и асинхронное программирование и вторая – однопоточные и многопоточные приложения. Каждая программная модель (синхронная или асинхронная) может работать в однопоточной и многопоточной среде. Давайте обсудим их подробно.
В последние время, я выступал на мероприятиях и отвечал на вопрос аудитории между моими выступлениями о Асинхронном программировании, я обнаружил что некоторые люди путали многопоточное и асинхронное программирование, а некоторые говорили, что это одно и тоже. Итак, я решил разъяснить эти термины и добавить еще одно понятие Параллелизм. Здесь есть две концепции и обе они совершенно разные, первая синхронное и асинхронное программирование и вторая – однопоточные и многопоточные приложения. Каждая программная модель (синхронная или асинхронная) может работать в однопоточной и многопоточной среде. Давайте обсудим их подробно.
Машинное обучение руками «не программиста»: классификация клиентских заявок в тех.поддержку (часть 1)
19 min
Привет! Меня зовут Кирилл и я алкоголик более 10 лет был менеджером в сфере ИТ. Я не всегда был таким: во время учебы в МФТИ писал код, иногда за вознаграждение. Но столкнувшись с суровой реальностью (в которой необходимо зарабатывать деньги, желательно побольше) пошел по наклонной — в менеджеры.

Но не все так плохо! С недавнего времени мы с партнерами целиком и полностью ушли в развитие своего стартапа: системы учета клиентов и клиентских заявок Okdesk. С одной стороны — больше свободы в выборе направления движения. Но с другой — нельзя просто так взять и заложить в бюджет "3-х разработчиков на 6 месяцев для проведение исследований и разработки прототипа для…". Много приходится делать самим. В том числе — непрофильные эксперименты, связанные с разработкой (т.е. те эксперименты, что не относятся к основной функциональности продукта).
Одним из таких экспериментов стала разработка алгоритма классификации клиентских заявок по текстам для дальнейшей маршрутизации на группу исполнителей. В этой статье я хочу рассказать, как "не программист" может за 1,5 месяца в фоновом режиме освоить python и написать незамысловатый ML-алгоритм, имеющий прикладную пользу.
Это не статья — просто пища для размышлений о том, как её написать
31 min
Translation

Под катом перевод статьи Carsten Sørensen «This is not an article — just some food for thoughts on how to write one». В ней рассказывается на что нужно обращать внимание при написании научных статей. Если вы пишите диссертацию в области информационных технологий, то наверняка найдете что-то интересное для себя. Впрочем, и авторы популярных статей тоже могут найти что-то полезное.
В статье рассматриваются основные вопросы, которые необходимо себе задать при написании научной публикации. Разбираются интересные примеры статей. Наверное каждый слышал или использовал словосочетание «серебряная пуля» применительно к той или иной технологии. Но задумывались ли вы кто впервые использовал эту метафору в ИТ и почему она такая популярная? Также разбирается статья, в которой проводится аналогия между программистами и часовщиками. И те, и другие в своё время стояли у истоков новой технологии. С развитием часовой индустрии самих часовщиков практически не осталось. Интересно, что ждет программистов через 500 лет?
Kaggle: анализ местности Амазонки по спутниковым снимкам
6 min

Недавно на kaggle.com проходило соревнование Planet understanding the amazon from space
До этого распознаванием изображений не занимался, поэтому подумал, что это отличный шанс научиться работать с картинками. Тем более, что по заверениям людей в чатике, порог вхождения был очень низкий, кто-то даже прозвал датасет «MNIST на стероидах».