Исправляем опечатки в поисковых запросах
14 мин
Наверное, любой сервис, на котором вообще есть поиск, рано или поздно приходит к потребности научиться исправлять ошибки в пользовательских запросах. Errare humanum est; пользователи постоянно опечатываются и ошибаются, и качество поиска от этого неизбежно страдает — а с ним и пользовательский опыт.
При этом каждый сервис обладает своей спецификой, своим лексиконом, которым должен уметь оперировать исправитель опечаток, что в значительной мере затрудняет применение уже существующих решений. Например, такие запросы пришлось научиться править нашему опечаточнику:
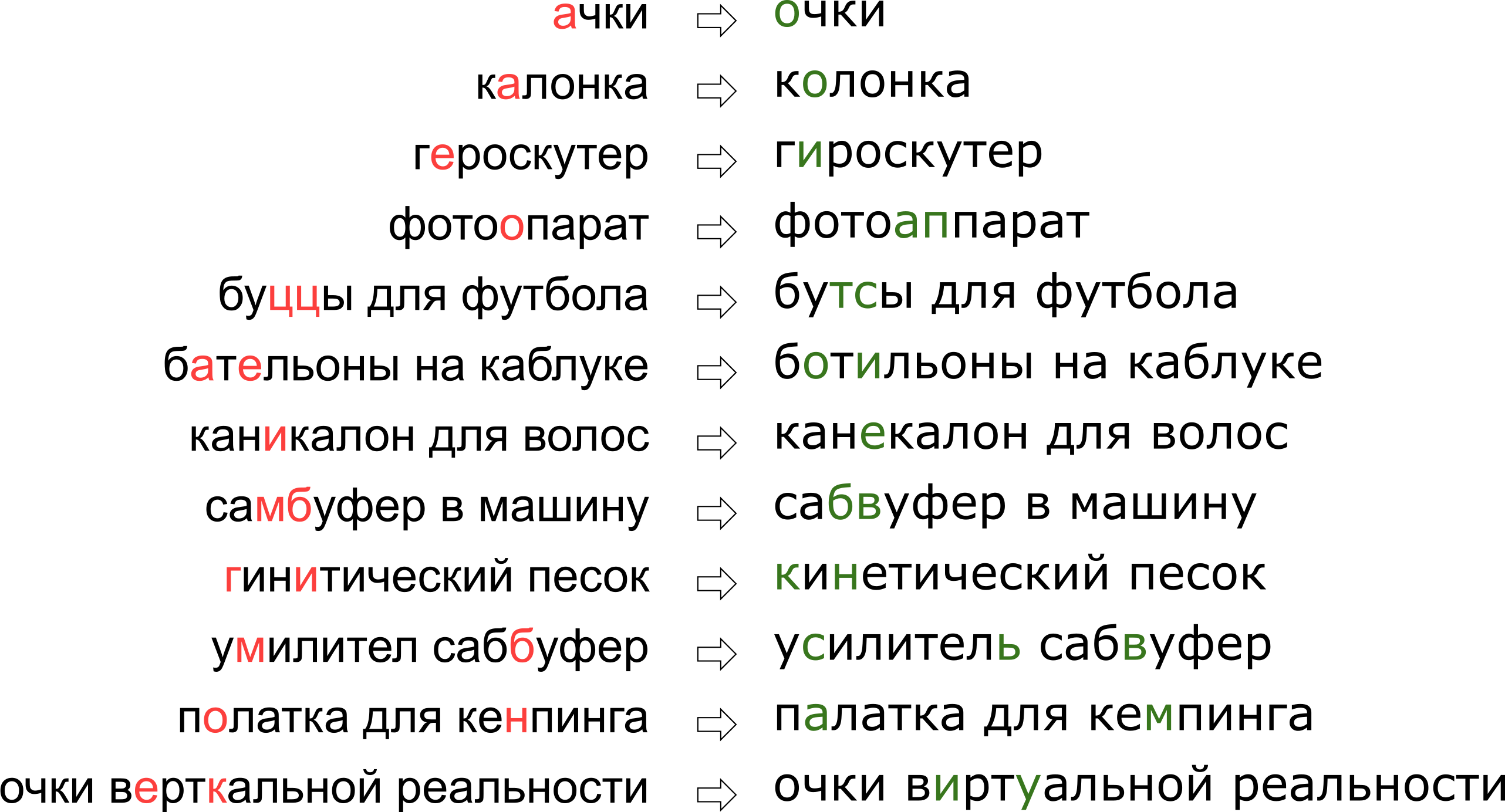
Может показаться, что мы отказали пользователю в его мечте о вертикальной реальности, но на самом деле буква К просто стоит на клавиатуре рядом с буквой У.
В этой статье мы разберём один из классических подходов к исправлению опечаток, от построения модели до написания кода на Python и Go. И в качестве бонуса — видео с моего доклада «”Очки верткальной реальности”: исправляем опечатки в поисковых запросах» на Highload++.
При этом каждый сервис обладает своей спецификой, своим лексиконом, которым должен уметь оперировать исправитель опечаток, что в значительной мере затрудняет применение уже существующих решений. Например, такие запросы пришлось научиться править нашему опечаточнику:
Может показаться, что мы отказали пользователю в его мечте о вертикальной реальности, но на самом деле буква К просто стоит на клавиатуре рядом с буквой У.
В этой статье мы разберём один из классических подходов к исправлению опечаток, от построения модели до написания кода на Python и Go. И в качестве бонуса — видео с моего доклада «”Очки верткальной реальности”: исправляем опечатки в поисковых запросах» на Highload++.